深度学习(总结)
1、人工智能三个层面:计算智能、感知智能,认知智能。
2、特征处理:数据预处理、特征提取、特征转换。
3、分布式表征优点:①存储效率高;②鲁棒性好。
4、BP算法:①纠错运算量下降到和神经元数目本身成正比;②神经网络增加一个隐藏层解决XOR难题。
5、卷积神经网络由Yann LeCun提出,并用于银行支票数字识别。
6、神经网络第三次兴起的标志性事件:①AlphaGo战胜李世⽯;②ImageNet 准确率⼤幅提⾼;③逐层预训练⽅法的提出。
7、期望风险:全局概念。经验风险:局部概念。
8、线性回归优化的目标:凸函数。神经网络的优化目标是非凸函数。
9、机器学习的三要素:模型、学习准则、优化算法。
10、GD(梯度下降算法)算法用于求解无约束最优化问题。学习率是十分重要的超参数。
11、三种梯度下降算法的比较:①批量梯度下降:利于寻找全局 最优解,梯度方差小;但样本 数目很多时,训练过程会很慢。(一次迭代选择全部样本)②随机梯度下降:训练速度快; 准确度下降,并不是全局最优, 梯度方差大。(一次迭代选择一个样本)③小批量梯度下降法:同时兼顾两种方法的优点。
12、欠拟合:模型能力不足。过拟合:训练数据少和噪声以及模型能力强。
13、泛化错误:表现为一个模型在训练集和测试集的错误率。机器学习的目标减少泛华错误。正则化:限制模型能力使其不要过度地最小化经验风险:机器学习,评估——风险函数 - 西伯尔 - 博客园
(备注:最小化期望错误等价与最小化偏差)
14、所有损害优化的方法都是正则化:一、增加优化约束:①L1、L2优化;②数据增强。二、干扰优化过程:①权重衰减;②SGD(随机梯度下降);③提前终止。最小化偏差和方差之和。
15、自信息:![]() 熵:随机事件的不确定性,熵越高,随机变量信息越多,反之成立。
熵:随机事件的不确定性,熵越高,随机变量信息越多,反之成立。
16、感知机的缺点:①不能保证其泛化能力。②对样本顺序比较敏感。
17、感知机的收敛性:①训练集线性可分:有限迭代后收敛;②训练集线性不可分,一定不会收敛。
18、Roseballt最初的感知器用的激励函数是:阶跃函数。
19、计算图是一种特殊的有向无环图。
20、根据计算图的搭建方式:动态图和静态图
| 静态图 | 动态图 |
| 先搭建后运算,高效但不灵活 | 搭建和运算同时进行,容易调节 |
| 程序运行不能改变 | 运行时动态构建计算法 |
| 构建时可进行优化,并行能力强 | 不易优化,难以并行 |
| 灵活性差 | 灵活性好 |
| Theano、TensorFlow等 | PyNet、Pytorch、TensorFlow2.0 |
21、人工神经网络的三大要素:节点、连边、连接方式。
22、更深层的网络具有更好的泛化能力,模型性能随着深度的增加而不断提升(备注:参数数量增加,未必一定会带来模型效果的提升)
23、前馈神经网络(FNN):全连接前馈神经网络和卷积神经网络。
24、记忆网络:RNN(循环神经网络)、Hopfield网络、玻尔兹曼机和受限玻尔兹曼机。
25、最早发明简单人工神经网络:FNN->多层感知器。
26、激活函数的性质要求:①连续并可导的非线性函数。②激活函数及其导数要尽可能的简单。③导函数的值域在一个合适的区间内。
27、RELU激活函数可以缓解梯度消失问题。
28、计算机实现参数的自动梯度计算,其方法可分为:数值微分、符号微分、自动微分。
29、神经网络参数优化的主要问题:①非凸优化问题。②梯度消失。
30、梯度消失问题是否可以通过增加学习率来缓解?
答:在一定程度上可以缓解。适当增大学习率,可以使学习率与导数相乘结果变大缓解梯度消失。然而过大的学习率可能使梯度巨大导致爆炸。
31、网络优化目标:最小化服从真实数据分布的损失函数的期望。经验风险最小化用训练集上的经验分布替代真实分布。
32、非凸优化问题:一、低维空间:非凸优化主要难点:①如何选择初始化参数;②如何逃离局部最优点。二、高维空间:如何逃离鞍点。
33、小批量梯度下降关键因素:①小批量样本的数量;②学习率(过大:不收敛;过小:收敛慢);③:梯度
(备注:批量大小不影响随机梯度的期望,但会影响随机梯度的方差)
34、动量法:①在迭代初期,梯度方向比较一致,动量法会起到加速作用,可以更快地到达最优点;②在迭代后期,梯度方向会不一致,动量法利用之前迭代时的梯度值,减小震荡;(减速作用,增加稳定性)③动量法虽然不能保证收敛到全局最优,但有一定可能跳出局部极值点。
35、梯度截断:发生梯度爆炸,当梯度的模大于一定阈值时,对梯度进行截断。
36、参数初始化:①全为0:出现对称权重问题?????②太小:梯度消失,使得Sigmoid型函数丢失非线性的能力。③太大:梯度爆炸,使得Sigmoid型函数变得饱和。
37、初始化方法:①预训练初始化:Fine-Tuning;②固定值初始化:b = 0(偏置);③随机初始化方法:固定方差、方差缩放(备注:初始化一个深度网络时,为了缓解梯度消失或者梯度爆炸问题,我们尽可能保持每个神经元的输入和输出的方差一致,根据神经元的连接数量来自适应)、正交初始化方法。
38、数据预处理:①数据归一化:(简单缩放、逐样本均值消减、特征标准化)②白化:降低输入冗余性,降低特征之间相关性。使得所有的特征具有相同的方差。
39、逐层归一化的目的:①解决内部协变量便宜问题。②解决梯度消失,梯度爆炸问题。③更平滑的优化地形。
40、归一化方法:①批量归一化->行;②层归一化->列(当样本数量少的时候选择);③权重归一化
41、超参数优化:
一、神经网络中的超参数:①网络机构;②优化参数;③正则化系数
二、优化方法:网格搜索,随机搜索、贝叶斯优化、动态资源分配、神经架构搜索。
42、如何提高神经网络泛化能力:①L1和L2正则化;②提前终止;③Dropout;④数据增强。(备注:数据增强方法:旋转、翻转、缩放、平移、噪声)
43、使用一个验证集来测试每一次迭代的参数在验证集上是否最优:如果验证集的错误率不在下降则停止迭代。

43、Dropout为什么会提升网络优化效果:
答:1、简化网络,防止过拟合;2、与集成学习取得的效果类似;3、Dropout可解释为一种贝叶斯学习的近似。
44、卷积神经网络(CNN)

45、卷积的运算:(过滤器/卷积核需要翻转在进行计算)
①一维卷积:


②二维卷积:

③计算公式

46、互相关和卷积的区别仅仅在于卷积核是否进行翻转,互相关也可称为不翻转卷积。
47、在神经网络中使用卷积是为了进行特征抽取,卷积核是否进行翻转和其特征抽取的能力无关。
48、卷积的动机:稀疏交互、参数共享、平移不变性
相关计算题:


49、卷积层虽然可以显著减少网络中连接的数量,但特征映射组中的神经元个数并没有显著减少。如果后面接一个分类器,分类器的输入维数依然很高,

相关计算题


53、如果训练参数设置不合理会导致过拟合或者欠拟合!!
( 备注:空洞卷积通过给卷积核插入“空洞”来变相地增加其大小。)
答:①增加卷积核的大小;(备注:参数量增加)
| 网络类型 | 相关内容 | 网络结构图 |
|
LeNet 1998
|
LeNet提供了利用卷积层堆叠进行特征提取的框架,开启 了深度卷积神经网络的发展。
|
 |
|
AlexNet
|
1、使用ReLU解决梯度弥散问题提高了网络的训练速率
2、使用 Dropout ,避免 过拟合 。
3、 使用重叠的 最大池化 (max pooling)。最大池化可以避免平均
池化的 模糊化效果 ,而采用重叠技巧可以提升特征的丰富性。
4、提出了LRN层,增强了模型的泛化能力。 5、利用GPU强大的并行计算能力加速网络训练过程 6、数据增强。降低过拟合 |
 |
|
Inception
|
优点一:减少网络参数,降低运算量(备注:因此,1×1卷积的作用之一是通过降维减少网络开销) 优点二:多尺度、多层次滤波(因此,1×1卷积的另一作用是对低层滤波结果进行有效的组合 ) |
 |
| ResNet(残差网络) |
1、非常深的残差网络能够很容易的优化。 2、深度残差网络能够容易地从增加的深度中得到精 度收益,同时比先前的网络产生了更好的效果。 优点: ➢ 没有 带来 额外的参数 和 计算 开销。
➢ 便于和具有相同结构的“平常”网络进行比。
|
|

58、循环神经网络(RNN)
(备注:循环神经网络的训练需要基于时间反向传播误差)
| 网络模型 | 网络模型图 | 模型应用 |
| Many-to-One模型 |
|
1、文本分类 2、情感分析 |
| One-to-Many模型 |
|
1、输入一张图片,输出为图片的文字描述 2、编写诗歌 |
| Many-to-Many模型(同步) |
|
1、实体识别 2、词性标记 |
| Many-to-Many模型(异步) |
|
1、机器翻译 2、自动问答 |


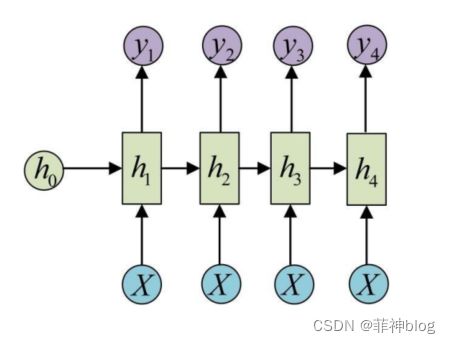
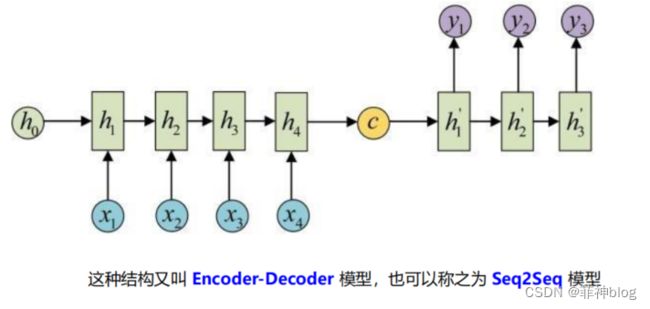
59、BPTT(随时间反向传播)
(备注:A. 前向计算 B. 误差项的计算 C. 权重梯度的计算 )
①BPTT 算法的核心思想和 BP 算法是相同的;②BPTT 算法与 BP 算法不同之处在于参数的寻优过程需要追溯历史数据;③
60、双向循环神经网络
| 网络名称 | 网络结构图 | 应用案例 |
| 双向循环神经网络 | 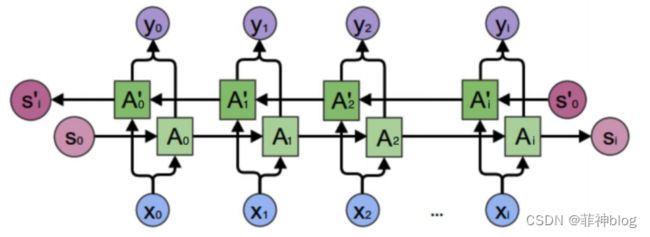 |
 |
|
注意: 正向计算和反向计算 不共享权重!!!
|
||
61、关于梯度消失和梯度爆炸的描述:
①梯度消失或者梯度爆炸会导致梯度为 0 或 NaN,无法继续训练更新参数;
②通常来说,梯度爆炸比梯度消失更容易处理一些;
③合理的参数初始化和使用 ReLU 函数可以用来解决梯度消失问题
62、关于 GRU 和 LSTM
| GRU(参数少,数据少) | LSTM |
| 更新门、重置门 | 输入门、遗忘门、输出门 |
|
1、GRU 是 LSTM 的一种变体,但是比 LSTM 结构更简单。
|
|
| 2、更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。 | |
| 3、重置门控制前一状态有多少信息被写入到当前的候选集上,重置门越小,前一状态的信息被写入的越少。 | |