周志华机器学习——聚类算法。
聚类算法
聚类算法是一种经典的无监督学习方法,无监督学习的目标是通过对无标记训练样本的学习,发掘和揭示数据集本身的潜在结构与j规律,即不依赖于训练数据集的类标记信息。聚类则试图将数据集的样本划分为若干个互相相交的类簇,从而每个簇对应一个潜在的类别。
聚类直观上来说是将相似的样本聚集在一起,从而形成一个类簇,(Cluster), 那首先的问题是如何度量相似性,这便是距离度量,在生活中,我们说差别小则相似,对应多维样本,每个样本可以对应高维空间中的一个数据点,若它们的距离相近,我们便可以称其为相似,那接着如何来评价聚类结果的好坏呢?这便是性能度量,性能度量为评价聚类结果的好坏提供了一系列有效性指标。
距离度量
谈及距离度量,最熟悉的莫过于 欧式距离了,从年头一直用到年尾的距离计算公式,即对应属性之间相减的平方和在开根号,度量距离还有很多其他经典的度量方法,通常它们需要满足以下基本性质:
非负性 d i s t ( x i , x j ) > = 0 ; dist(x_i,x_j)>=0; dist(xi,xj)>=0;
同一性 d i s t ( x i , x j ) = 0 当且仅当 x i = x j dist(x_i,x_j) = 0当且仅当x_i = x_j dist(xi,xj)=0当且仅当xi=xj
对称性 d i s t ( x i , x j ) = d i s t ( x j , x i ) dist(x_i,x_j) = dist(x_j,x_i) dist(xi,xj)=dist(xj,xi)
直递性 d i s t ( x i , x j ) < = d i s t ( x i , x k ) + d i s t ( x k , x j ) dist(x_i,x_j)<=dist(x_i,x_k) + dist(x_k,x_j) dist(xi,xj)<=dist(xi,xk)+dist(xk,xj) 即三角不等式,两边之和大于第三边。
最常用的距离度量方法是闵可夫斯基距离:
d i s t m k ( x i , x j ) = ( ∑ u = 1 n ∣ x i u − x j u ∣ ) 1 p dist_{mk}(x_i,x_j) = (\sum^n_{u = 1}|x_{iu} - x_{ju}|)^{\frac{1}{p}} distmk(xi,xj)=(u=1∑n∣xiu−xju∣)p1
当 p = 1时,该距离公式可以变为曼哈顿距离:
d s i t m a n ( x i , x j ) = ∣ ∣ x i − x j ∣ ∣ 1 = ∑ u = 1 n ∣ x i u − x j u ∣ dsit_{man}(x_i,x_j) = ||x_i - x_j||_1 = \sum^n_{u = 1}|x_{iu} - x_{ju}| dsitman(xi,xj)=∣∣xi−xj∣∣1=u=1∑n∣xiu−xju∣
当p = 2时,该距离公式都是欧式距离公式,可以表示为:
d i s t e d ( x i , x j ) = ∣ ∣ x i − x j ∣ ∣ 2 = ∑ u = 1 n ∣ x i u − x j u ∣ 2 dist_{ed}(x_i,x_j) = ||x_i - x_j||_2 = \sqrt{\sum^n_{u =1}|x_{iu} - x_{ju}|^2} disted(xi,xj)=∣∣xi−xj∣∣2=u=1∑n∣xiu−xju∣2
我们清楚属性划分有两种连续属性和离散属性,(有限个取值),对于连续属性的取值,一般都可以被学习器取用,有时会根据具体的情形做相应的预处理,例如:归一化等,对于离散值的属性,需要做下一步处理:
若属性值之间存在序关系,可以将其转化为连续值:身高属性“高”“中等”“矮”,可转化为 1 , 0.5 , 0 {1, 0.5, 0} 1,0.5,0。
若属性间不存在序关系,可以将其转化为向量的形式,例如:性别属性男女:可转化为 ( 1 , 0 ),( 0 , 1 ) {(1,0),(0,1)} (1,0),(0,1)
在进行距离度量时,容易知道连续属性和存在序关系的离散属性都可以直接参与计算,因为它们都可以反应一种程度,我们称之为有序属性,而对于不存在序关系的离散属性,我们称之为无序属性,显然无序属性再使用闵可夫斯基距离就行不通了。
对于无序属性,我们一般采用VDM进行距离的计算,例如:对于离散属性的两个取值 a a a和 b b b,定义为:
V D M p ( a , b ) = ∑ i = 1 k ∣ m u , a , i m u , a − m u , b , i m u , b ∣ p VDM_p(a,b) = \sum^k_{i = 1}|\frac{m_{u,a,i}}{m_{u,a}} - \frac{m_{u,b,i}}{m_{u,b}}|^p VDMp(a,b)=i=1∑k∣mu,amu,a,i−mu,bmu,b,i∣p
于是在计算两个样本之间的距离时,我们可以将闵可夫斯基距离和VDM混合在一起进行计算:

我们定义的距离度量方式是用来计算相似性的,例如下面将要讨论聚类问题,即距离越小,相似性越大,反之,距离越大,相似性越小。这时的距离度量方法并不一定需要满足前面所说的四个基本性质。这种方法称为非度量距离。
性能度量
由于聚类方法不依赖于样本的真实类标,就不能像监督学习的分类那般,通过计算分对错(即精确度和错误率)来评价学习器的好坏或者做为学习过程的优化目标,一般聚类有两类性能优化目标,外部指标和内部指标。
外部指标
即将聚类的结果与单个参考模型的结果进行比较,以参考模型的输出作为标准,来评价聚类好坏,假设聚类给出的结果为 λ \lambda λ 参考模型给出的结果为 λ ∗ \lambda^* λ∗,则我们将样本进行两两配对,定义为:

虽然 a a a和 b b b代表着聚类结果好坏的正能量, b b b和 c c c则表示参考结果和聚类结果相矛盾,基于这四个值可以导出以下常用的外R部指标:
- Jaccard系数
J C = a a + b + c JC = \frac{a}{a + b + c} JC=a+b+ca - FM指数
F M I = a a + b × a a + c FMI = \sqrt{\frac{a}{a + b}\times\frac{a}{a+c}} FMI=a+ba×a+ca - Rand指数
R I = 2 ( a + d ) m ( m − 1 ) RI = \frac{2(a+d)}{m(m - 1)} RI=m(m−1)2(a+d)
内部指标
内部指标即不依赖于任何外部模型,直接对聚类结果进行评估,聚类的目的是想将那些相似的样本尽可能聚在一起,不相似的样本尽可能的分开,直观来说:簇内高内聚紧紧抱团,簇间低耦合老死不相往来。定义:

基于上面这四个距离,可以导出上面常用的评价指标:

原型聚类
原型聚类即基于原型的聚类,原型表示模板的意思,就是通过参考一个模板向量或模板分布的方式,来完成聚类的过程。常见的K-means聚类便是基于簇中心实现的聚类。
K-means聚类
思想十分简单,首先随机指定类中心,根据样本与类中心的远近划分类簇,接着重新计算类中心,迭代直至收敛。但是其中迭代的过程并不是主观想象得出的,事实上,若将样本的类别看作是隐变量,类中心看作样本的分布参数,这一过程正是通过EM算法的两步骤策略而计算出的,其根本目的是为了最小化平方误差函数E:
E = ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − μ i ∣ ∣ 2 2 E = \sum^k_{i = 1}\sum_{x\in C_i}||x - \mu_i||^2_2 E=i=1∑kx∈Ci∑∣∣x−μi∣∣22
K-means算法的流程如下:

学习向量量化(LVQ)
LVQ也是基于原型的聚类算法,与K-means不同的是,LVQ使用样本真实类标记辅助聚类,首先LVQ根据样本的类标记,从各类中分别随机选出一个样本作为该类簇的原型,从而组成了一个原型向量组,接着从样本集中随机挑选出一个样本,计算其与原型向量组中每个向量的距离,并选取距离最小的原型向量所在的类簇作为其的划分结果,在与真实类标比较:
- 若划分结果正确,则对应原型向量向这个样本靠近一些。
- 若划分结果不正确,则对应原型向量向这个样本远离一些。
LVQ算法流程如下:

高斯混合聚类
现在可以看出K-Means与LVQ都试图以类中心作为原型指导聚类,高斯混合聚类则采用高斯分布来描述原型。现假设每个类簇中的样本都服从一个多维高斯分布,那么空间中的样本可以看作由 k k k个多维高斯分布混合而成。
对于多维高斯分布函数,其概率密度函数如下所示:
p ( x ) = 1 ( 2 π ) n 2 ∣ ∑ ∣ 1 2 e − 1 2 ( x − μ ) T ∑ − 1 ( x − μ ) p(x) = \frac{1}{(2\pi)^\frac{n}{2}|\sum|^\frac{1}{2}}e^-\frac{1}{2}(x - \mu)^T\sum^{-1}(x - \mu) p(x)=(2π)2n∣∑∣211e−21(x−μ)T∑−1(x−μ)
其中 μ \mu μ为高斯分布, ∑ \sum ∑ 表示协方差矩阵。可以看出一个多维高斯分布完全有这两个参数所决定,接着定义高斯混合分布为:
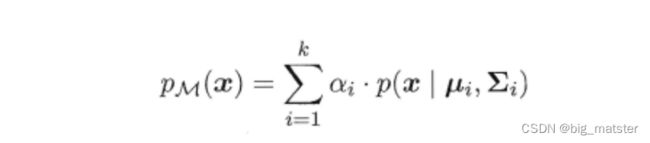
α \alpha α称为混合系数,这样空间中样本采集过程可以抽象为:先选择一个类簇(高斯分布),在根据对应的高斯分布的密度函数进行采样,这时候贝叶斯公式,又能大展伸手了:

此时只需要选择PM最大时的类簇,并将该样本划分到其中,看到这里,很容易发现,这和那个传说中的贝叶斯分类很相似,都是通过贝叶斯公式展开的,然后计算类先验概率和类条件概率,但遗憾的是,这里没有真实的类标信息,对于类条件概率,并不能像贝叶斯分类那样通过最大似然法美好的计算出来,这里的样本可能属于所有类簇,这里的似然函数变为:
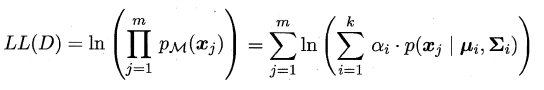
可以看出,简单的最大似然法根本无法求出所有参数,这样PM也就没噶法计算啦,这里就要召唤出之前的EM大算法,首先对高斯分布的参数及混合系数进行随机初始化,计算出各个PM(即γji,第i个样本属于j类),再最大化似然函数(即LL(D)分别对α、u和∑求偏导 ),对参数进行迭代更新

高斯混合聚类的算法流程如下:

密度聚类
密度聚类则是基于密度的聚类,它从样本分布的角度来考察样本之间的可连接性,并基于可连接性(密度可达)不断拓展疆域(类簇)。其中最著名的便是DBSCAN算法,首先定义以下概念:


简单来理解DBSCAN便是:找出一个核心对象所有密度可达的样本集合形成簇。首先从数据集中任选一个核心对象A,找出所有A密度可达的样本集合,将这些样本形成一个密度相连的类簇,直到所有的核心对象都遍历完。DBSCAN算法的流程如下图所示:

层次聚类
层次聚类是一种基于树形结构的聚类方法,常用的是自底向上的结合策略(AGNES算法)。假设有 N N N个待聚类的样本,其基本步骤是:
初始化->把每个样本归为一类,计算每两个了类之间的距离,也就是样本与样本之间的相似度。
寻找各个类之间的最近两个类,把它们归为一类(这样类的总数就少了一个)
重新计算新生成的这个类与各个旧类之间的相似度。
重复2到3直至所有样本点都归为一类,结束。
可以看出,其中最关键的一步就是计算两个类簇的相似度,这里有多种度量方法:
-
单链接:取类间最小距离。
最小距离: d m i n ( C i , C j ) = m i n x ∈ C i , z ∈ C j d i s t ( x , z ) 最小距离:d_{min}(C_i,C_j) = min_{x\in C_i,z\in C_j}dist(x,z) 最小距离:dmin(Ci,Cj)=minx∈Ci,z∈Cjdist(x,z) -
全链接:取类间最大距离
最大距离: d m a x ( C i , C j ) = m a x x ∈ C i , z ∈ C j d i s t ( x , z ) 最大距离:d_{max}(C_i,C_j) = max_{x\in C_i,z\in C_j}dist(x,z) 最大距离:dmax(Ci,Cj)=maxx∈Ci,z∈Cjdist(x,z) -
均链接:取类间两两的平均距离。

很容易,看出,单链接包容性极强,稍微有点暧昧都当做是自己人啦,全连接则是坚持到底,只要存在缺点都坚决不合并,均连接则是从全局出发顾全大局,层次聚类法算法流程如下所示:

学习心得
会自己根据项目,将各种聚类算法学一学,全部将其搞定都行啦的理由与打算。
慢慢地将各种聚类算法,各种聚类度量都给其搞定,全部都给其研究透彻都行啦的理由与打算,慢慢地自己琢磨,自己斟酌好好都行啦的样子与度量。全部将其搞定。