深度学习入门--02 初识神经网络
-
1、神经网络的结构
-
神经网络的结构类似与上一章所讲的两层感知机。具体分为输入层、隐藏层和输出层。分别称为第0、1、2层。首先与感知机不同的是,神经网络引入了激活函数,激活函数可用h(a)来表示,a为加权输入信号与偏置的总和。
-
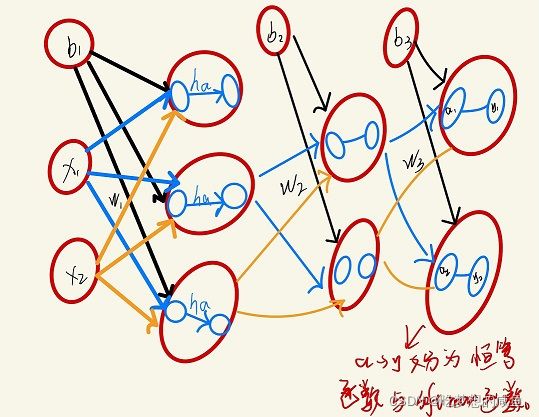
-
2、输入层到隐藏层、隐藏层到输出层的信号传递设计:
-
(1)、引入激活函数:将输入信号的总和转化为输出信号,这种函数称为激活函数。
-
(2)、感知机中使用的激活函数:感知机中的一旦输入加权超过临界值就会切换输出0或1,这样的函数称为阶跃函数,可以用一下代码表示:
def step_function(x):
y = x > 0
return y.astype(np.int32)
x = np.array([-1.0, 1.0, 2.0])
res = step_function(x)
print(res)
"""
[0 1 1]
"""
图:由pycharm 中 matplotlib实现
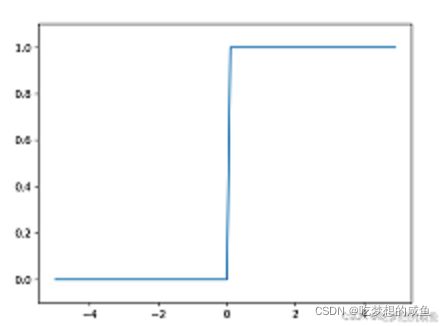
这个函数与之前感知机的函数不一样,这样解决了之前不支持输入numpy数组的问题。
- (3)神经网络中常用的激活函数:sigmoid函数与ReLU函数。
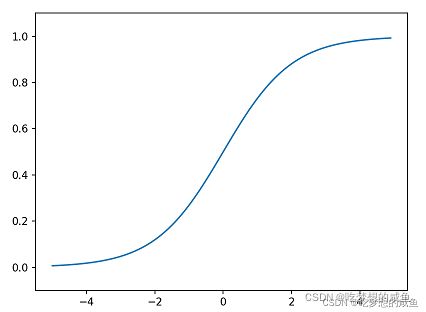
- sigmoid 函数相对与阶跃函数显得更平滑,此函数可以返回连续的值,如0.88等,而阶跃函数只能返回0或1,神经网络中流动的是连续的实数值信号,所以sigmoid函数的平滑性更适于神经网络。
- sigmoid函数的代码展现:
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.array([-1.0, 1.0, 2.0])
res2 = sigmoid(x)
print(res2)
"""
[0.26894142 0.73105858 0.88079708]
"""
图:
- ReLU函数:现在使用最多的激活函数,在函数大于零时输出该值,在函数小于等于零时输出零。
代码实现:
def ReLU(x):
return np.maximum(0, x)
s = np.array([-1.0, 1.0, 2.0])
res3 = ReLU(s)
print(res3)
"""
[0. 1. 2.]
"""
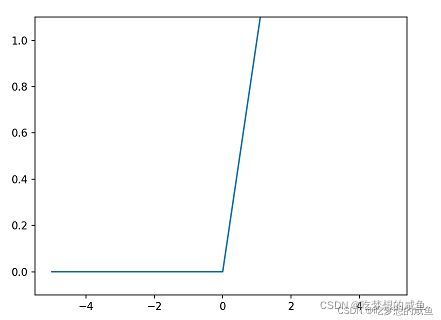
-
(3)、激活函数的共同点:必须为非线性函数。线性函数是指输出值是输入值的倍数,是一条笔直的线,选择线性函数作为激活函数时,无论加深多少层都只是倍数的累加,如之前的叠加感知机,在叠加之后会出现更多不是原来倍数的输出信号,若为线性函数则失去了叠加感知机或者说加深神经网络的优势。所以必须使用非线性函数。
-
3、输出层的设计:
-
输出层的激活函数一般使用恒等函数和softmax函数,神经网络一般用于分类问题和回归问题,回归问题用恒等函数,分类问题用softmax函数,回归问题值的是根据输入预测一个数值的问题,如输入某人的图像预测这个人的体重,而分类问题指的是数据属于哪一类别的问题,如辨别图像中的人是女性还是男性。
-
(1)恒等函数:
-
对于输入的值不加任何改变的直接输出,y1 = a1,该输出值只受对应神经元的影响。
-
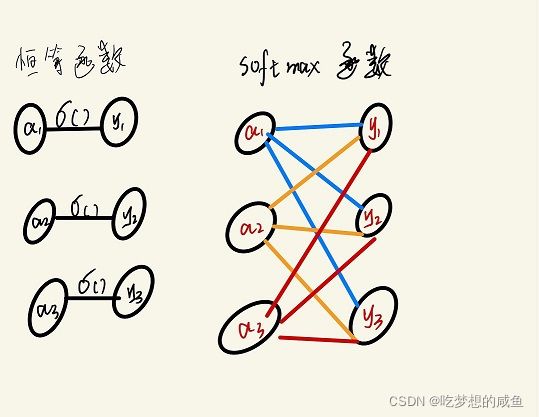
-
(2)softmax函数:
-
输出层的各个神经元都受到所有输入信号的影响。
-
输出的总和总为1,所以我们可以根据输出值的大小确定某一情况出现的概率大小,进而解决前面提到的分类问题。
-
需要说明的是,softmax函数并不会改变各个元素之间的大小关系,所以在实际的分类问题中,输出层的softmax函数是可以省略的。
-
softmax函数的公式及代码实现:
def softmax(a):
c = np.max(a) #为了解决溢出问题,引入一个常数
exp_a = np.exp(a - c)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
- 注:求解机器学习的学习步骤可以分为学习和推理两个阶段,在学习阶段进行模型的学习,然后在推理阶段,用学到的模型对未知数据的进行推理分类。
- 4、代码小节–实现一个简单的神经网络框架。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
def step_function(x):
y = x > 0
return y.astype(np.int32)
x = np.array([-1.0, 1.0, 2.0])
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def ReLU(x):
return np.maximum(0, x)
def softmax(x):
c = np.max(x) # 为了解决溢出问题,引入一个常数
exp_x = np.exp(x - c)
sum_exp_x = np.sum(exp_x)
y = exp_x / sum_exp_x
return y
def init_NetWork():
network = {}
network['w1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['w2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['w3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def net_forward(network, x):
w1, w2, w3 = network['w1'], network['w2'], network['w3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, w1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, w2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, w3) + b3
y = softmax(a3)
return y
NetWork = init_NetWork()
x = np.array([1.0, 0.5])
y = net_forward(NetWork, x)
print(y)
"""
[0.40625907 0.59374093]
"""