mySQL增删改查进阶
数据库的约束
-
NOT NULL - 指示某列不能存储 NULL 值。
-
UNIQUE - 保证某列的每行必须有唯一的值。
-
DEFAULT - 规定没有给列赋值时的默认值。
-
PRIMARY KEY 主键- NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标
识,有助于更容易更快速地找到表中的一个特定的记录。 -
FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
-
CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略
CHECK子句
主键自增
对于整数类型的主键,常配搭自增长auto_increment来使用。插入数据对应字段不给值时,使用最大
值+1
注意,自增主键只能保证在单机上的不重复,如果数据是分布式存储则无法保证主键的唯一性.
此时需要我们自己写自增算法,一般我们是用时间戳(越精确越强) + 机号 + 随机因子 来保证数据的唯一性,
即使这样也不能保证在数学上绝对的唯一性,但在工程中我们往往忽视这0.00000…1的概率
**FOREIGN KEY **
foreign key(列名) references 主表(列名);
引用的外部键必须在外部表为主键!
外部键用来保证该表与另一个表的联系,一般保证表中的数据是确实存在的,如班级名等等…如果把该表作为子表,另一个表作为父表,要注意不仅是子表受到父表的约束,同时父表也要受到子表的约束,父表不能删除子表中正在联系的数据
有时我们确实需要删除外部键,对此我们一般采用逻辑删除的方法,即表中加一个列,以1和0表示这行数据是否有效。但在时间积累下数据会越来越多,浪费空间,但即使这样我们也只要在没空间时加几个硬盘就行了,因为硬件的成本很低(1000左右就能买一个1T的SSD优质硬盘),而程序员工资往往一个月就1~2w,相比来说这种方法是最有效的办法。
表的设计
在实际工程中,对于一个对象的数据存储往往需要多个表来共同维护,表与表之间的关系有一对多、多对一和多对多三种关系
一对多
一对多是比较常见的情况,例如一个用户就有姓名、性别、账号等多种属性,而账号又可细化为用户名、密码、注册时间等等用另一个表存储
-- user表
name gender age accountID
'张三' 男 8 1
'李四' 女 12 2
'王五' 男 18 3
-- account表
username password time accountID
XXXXXXXX XXXXXXXX XXXX 1
XXXXXXXX XXXXXXXX XXXX 2
XXXXXXXX XXXXXXXX XXXX 3
-- 通过accountID建立外部键就建立起了两表之间的联系
多对一
例如很多学生在一个班级中就是多对一的关系,由于SQL没有数组,我们没办法用 班级 人数 学生列表 形式存储数据,只能让每个学生多一个班级序号属性
-- student表
name gender age class
'张三' 男 8 1
'李四' 女 12 1
'王五' 男 18 1
-- class表
XXXX class
XXXX 1
多对多
一个学生有多种课程,同时每个课程又对应多个学生,这种情况就是多对多的情况。多对多较上面两种情况较为麻烦一点,由于没有数组,我们必须用单独的表来存储他们之间的联系,如下:
-- student表
name gender age studentID
'张三' 男 8 1
'李四' 女 12 2
'王五' 男 18 3
-- subject表
name score subjectID
chinese 100 1
math 100 2
english 100 3
-- stu_subject表
studentID subjectID
1 2
1 3
2 1
-- 上面就表示张三有数学和英语课 李四有语文课
查询插入
查询插入类似于复制粘贴,就是把一个表中的数据查询出来插入到另一个表
例如在学校招生时会有一个报名表,确认录取以后就要把报名表中录取人的数据存入学生总表中,我们就可以使用查询插入
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...
如果要把录取的人存入学生表,可以按下面的代码写:
insert into student(name,age,gender) select name,age,gender from application where admission = true;
注意: 查询出来的数据 类型和数量 必须和插入的表一致(名字不用相同)
聚合查询
在之前我们知道了可以在查询时用表达式计算列与列之间的值,聚合查询就给了我们计算行与行之间的方法
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量,即行数 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
-- 如果我们要查询所有学生的语文成绩平均数
select avg(chinese) from student;
-- 如果我们要查询学生人数
select count(*) from student;
注意: 在使用count时,如果所有数据都为空,数据并不会被记录为一行!
分组查询
使用group by进行分组查询,如果要找学生表中男生和女生的个数可以用下面的代码
select gender,count(*) from student group by gender;
注意 如果进行分组,那么显示的数据必然会重合, 如果不对重合的数据进行聚合运算, 显示的数据为第一条数据
有时我们不仅要在分组前进行筛选, 分组后还要对数据进行筛选, 此时需要使用having语句。即分组前用where分组后用having
联合查询
联合查询用于将多个表的数据归并到一起。
SQL使用笛卡尔积的方式将所有的数据排列组合形成一个临时表,因此联合查询会有很多无效数据,因此效率较低
由于有无效数据,我们需要筛选出有效数据,而筛选有效数据的条件被称为连接条件
联合查询 = 笛卡尔积 + 连接条件 + 其它条件 + 列精简
如果列名相同可以使用 表名.列名 表示
内联接与外联接
内联接与外联接在连接的两表数据是一一对应时是一样的,一一对应即在A表中的数据,在B表中都能找到数据与之对应,反过来也一样。如下:

那么如果数据不是一一对应,如下所示:

其中左表王五在右表中没有对应,右表的4号学生在左表没有对应,如果使用内联接,即
select id,name,score from student,score where id = studentid;
查询出来的数据就会剔除掉左右两边没有对应的数据,如果要保留它们则需要外联接,即使用关键字left join 和right join
-- 如果要左表数据全部保留
select id,name,score from student left join score on id = studentid;
-- 如果要右表数据全部保留
select id,name,score from student right join score on id = studentid;
那么是否可以两表数据全部保留呢?
全部保留数据的操作被称为全外连接,但是全外连接在mySQL不支持,在oracle等数据库软件中才支持,因此不再多言
自连接
自连接,如它字面意思即自己和自己连接。这个操作看似很无厘头,但是存在即合理,自连接是为了比较行与行之间的数据而存在的。
SQL中很难直接比较行之间的数据,唯一的办法就是使用SQL中的自带的max,avg,sum等方法。但是自连接可以让行与行的关系转变为列与列的关系,这样就能直接比较了。
如果我们有下面这样的数据:
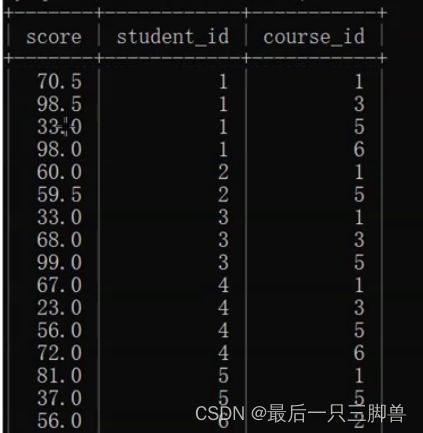
如果我们想找到course_id为1的分数大于course_id为3的分数的学生,我们使用常规方法是做不到的,因此可以直接使用自连接
select * from score as s1,score as s2 where s1.student_id = s2.student_id;
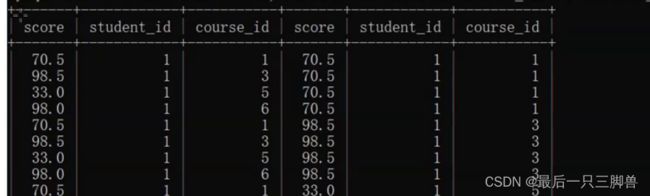
到了这里我们就可以直接使用列操作来完成了。
子查询
子查询通俗一点说就是嵌套查询,有= in 和 exists三种方法
= 用于查询出一个数据的情况给
in 用于查询出数据集合的情况
exists和in用法相同,但是只能在极端情况下使用,即内存放不下数据的时候,其他情况可读性和效率都不如in
select ... from 表1 where 字段1 = (select ... from ...);
select ... from 表1 where 字段1 in (select ... from ...);
select ... from 表1 where exists (select ... from ... where 条件);
合并查询
合并查询使用union关键字,可以把查询的数据放在一起。
如果要查询性别为男或者大于12岁的所有学生信息可以用下面的写法:
select * from student where gender = '男'
union
select * from student where age > 12;
事实上此处完全可以使用or来替换。
还有union all的方法,即把合并的数据直接放在一起,不会去重,即union的数据只有‘张三’ 男 16一个数据,而union all会有两个’张三’