爬取json数据
任务概述
爬取知乎中的推荐内容,输出每条推荐文章的链接和标题
或许可以使用获取html的方式来完成这个任务,不过这次主要想练一下json文件的爬取。
数据的爬取
json数据格式简单,不需要像html那样需要构造选择器来定位数据位置,只需要根据json数据的格式一步步找到目标字段即可。
先在打开浏览器终端的network,通过观察找到推荐栏目对于的链接,为便于查找可勾选XHR选项进行过滤
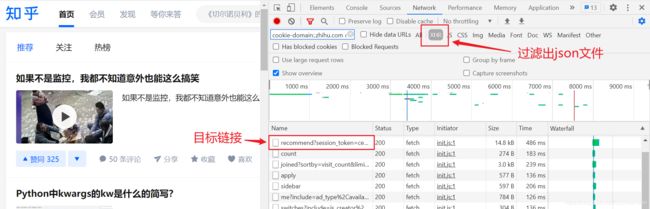
再观察链接的格式,上面图片中的目标链接为https://www.zhihu.com/api/v3/feed/topstory/recommend?session_token=ce014c22353196104dcbc81d8a5593df&desktop=true&page_number=2&limit=6&action=down&after_id=5&ad_interval=-1,可分解为两个部分:https://www.zhihu.com/api/v3/feed/topstory/recommend?和session_token=ce014c22353196104dcbc81d8a5593df&desktop=true&page_number=2&limit=6&action=down&after_id=5&ad_interval=-1,后面这一部分为请求参数,接下来就可以构造链接并请求数据了。
import requests
import json
base_url = 'https://www.zhihu.com/api/v3/feed/topstory/recommend?'
headers = {
'cookie':'...', # 你的cookie
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.3',
}
# page和after_id可根据需要进行调整
page = 0
after_id = 6
params = {
'session_token':'7ff1929781f57d1262b18480fe3011c2',
'desktop':'true',
'page_number':page,
'limit':'6',
'action':'down',
'after_id':after_id,
'ad_interval':'1'
}
# 获取对应页面的json数据
def get_page(params, base_url, headers):
# 附加参数
extra_url = '&'.join(['{key}={val}'.format(key=key,val=params[key]) for key in params])
# 合成url
url = base_url + extra_url
# 尝试获取json数据
try:
response = requests.get(url, headers = headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error',e.args)
return []
# 获取json数据
data = get_page(params, headers)
上面这段代码执行完后就获取到了推荐页面的json数据,这里需要的是每条推荐对应的链接。
数据的处理
先将获取到的json数据保存到文件中方便观察其数据格式
# 保存数据
with open('recommend.json', 'w', encoding='utf-8') as file:
str = json.dumps(data, indent = 2, ensure_ascii = False)
file.write(str)
观察后发现里面的链接不能访问后跳转到的页面都是一些json数据,也就是在数据中没有显式的给出每条推荐的链接,需要自己构造。
点开每条推荐,跳转到的页面如下:

观察地址栏的地址发现需要两个数据,一是question后面的question_id,还有一个每个answer对应的答主id,这些数据都可以在爬取到的json数据中找到。(需要花点时间进行观察才会发现)
通过观察又发现推荐中的内容有的是文章,有的是视频,两者的json数据格式不完全一样,如果是视频内容则其对应的json数据中没有question字段,为简化处理,将视频推荐内容直接舍去,只输出推荐文章的标题和链接。(视频标题和链接的提取大同小异)
然后就有了下面这段代码
with open('recommend.json', 'r', encoding='utf-8') as file:
str = file.read()
data = json.loads(str)['data']
num = len(data)
# 接下来就是提取其中的信息,这需要观察json数据的格式,了解你所需要的数据的位置,然后一步步定位
# 由于json中没有找到每条推荐对应的链接,所以需要自己根据json数据自己合成链接
# 链接形如:https://www.zhihu.com/question/377886499/answer/1849697584
for i in range(num):
# 获取target字段,里面包含主要的链接信息
target = data[i].get('target')
id = target.get('id')
# 尝试获取question字段,如果失败则该条推荐不是文章类型
question = target.get('question', -1)
if question != -1:
question_id = question.get('id')
# 合成推荐内容的链接
url = 'https://www.zhihu.com/question/{q_id}/answer/{id}'.format(q_id = question_id, id = id)
title = question.get('title')
print('{title}\n{url}\n'.format(title=title, url=url))
打印效果如下:

最后提取出来的数据可以存放到数据库中,这里偷个懒就不写了。