GAN论文精读 P2GAN: Posterior Promoted GAN 用鉴别器产生的后验分布来提升生成器
《Posterior Promoted GAN with Distribution Discriminator for Unsupervised
Image Synthesis》是大连理工学者发表的文章,被2021年CVPR收录。
文章地址:https://ieeexplore.ieee.org/document/9578672
本篇文章是阅读这篇论文的精读笔记。
一、原文摘要
生成器中足够的真实信息是GAN产生能力的关键点。然而,GAN及其变体缺乏这一点,导致训练过程脆弱。在本文中,我们提出了一种新的GAN变体,即后验提升GAN(P2GAN),它利用鉴别器产生的后验分布中的真实信息来提升生成器。在我们的框架中,与GAN的其他变体不同,鉴别器将图像映射到多元高斯分布并提取真实信息。该生成器使用AdaIN的真实信息和潜在代码正则化器。
此外,还应用了重新参数化技巧和预训练,以确保在实践中的稳定训练过程。从理论上证明了P2GAN的收敛性。在典型的高维多模态数据集上的实验结果表明,P2GAN在无监督图像合成方面取得了与最先进的GAN变体相当的结果。
二、为什么提出Posterior Promoted GAN?
生成器中足够的真实信息是GAN的关键。在原始GAN中,唯一有助于生成器的真实信息是从鉴别器传递的梯度,这对于生成器来说是间接的和空洞的,会导致脆弱的训练。GAN的一些监督变体以直接和强的方式使用标签等属性,并对属性进行一些约束,这为生成器提供了足够的真实信息。
对于GAN的无监督变体,有两种主要方法来改进真实信息:
- 一种方法是通过引入新的损失函数来从鉴别器提供更精细的梯度。但来自梯度的信息仍然是间接的和脆弱的,不能为发电机提供持续的支持;
- 另一种方法是通过向输入噪声中添加先验来丰富真实信息。然而,先验中的真实信息仅被添加到输入噪声中,通过逐渐堆叠卷积层,输入噪声可能会衰减。
为了解决上述缺乏真实信息的问题,在本文中,我们提出了一种新的GAN框架,称为Posterior Promoted GAN (P2GAN)
三、创新点
文章的创新点如下:
- 首先,与传统的鉴别器不能提供足够的真实信息不同,P2GAN通过鉴别器学习后验分布中丰富的真实信息,并以更直接和鲁棒的方式将信息应用于生成器。具体而言,鉴别器将图像映射到多元高斯分布,并将该分布与两个不同的给定先验分布进行匹配以进行区分。
- 生成器通过自适应实例归一化(AdaIN)和潜在代码正则化器将外部真实信息引入每个卷积层来提升。AdaIN直接影响卷积层中的特征比仅改变输入噪声的先验更强。大。
- 将最小二乘生成对抗网络(LSGAN)的损失改为分布版本,并为其收敛提供了理论保证。
贡献总结如下:
- 提出了一种新的GAN框架,称为P2GAN。鉴别器输出后验分布以进行区分真假,同时提取大量的真实信息。生成器通过AdaIN层利用真实信息来提高其生成能力。
- 将LSGAN的损失修改为分布形式,并通过皮尔逊X散度从理论上证明了其收敛性。
- 提出了一种新的潜在正则化器作为生成器的鲁棒约束,它可以防止后验分布中丰富的真实信息在训练过程中消失。
- 我们介绍了两种在实践中保证模型稳定性的方法:重新参数化技巧训练和预训练步骤
四、概念介绍
4.1、LSGAN
P2GAN使用LSGAN的损失作为基础,与原始GAN不同,LSGAN采用最小平方作为损失函数。它惩罚那些远离决策边界的样本,这可以执行更稳定的学习过程,其损失为:
min D V L S G A N ( D ) = 1 2 E x ∼ p data ( x ) [ ( D ( x ) − b ) 2 ] + 1 2 E x ∼ p g ( x ) [ ( D ( x ) − a ) 2 ] min G V L S G A N ( G ) = 1 2 E x ∼ p g ( x ) [ ( D ( x ) − c ) 2 ] \begin{aligned} \min _{D} V_{L S G A N}(D)=& \frac{1}{2} \mathbb{E}_{\mathbf{x} \sim p_{\text {data }}(\mathbf{x})}\left[(D(\mathbf{x})-b)^{2}\right]+\\ & \frac{1}{2} \mathbb{E}_{\mathbf{x} \sim p_{g}(\mathbf{x})}\left[(D(\mathbf{x})-a)^{2}\right] \\ \min _{G} V_{L S G A N}(G)=& \frac{1}{2} \mathbb{E}_{\mathbf{x} \sim p_{g}(\mathbf{x})}\left[(D(\mathbf{x})-c)^{2}\right] \end{aligned} DminVLSGAN(D)=GminVLSGAN(G)=21Ex∼pdata (x)[(D(x)−b)2]+21Ex∼pg(x)[(D(x)−a)2]21Ex∼pg(x)[(D(x)−c)2]
p d a t a ( x ) p_{data}(x) pdata(x)是真实图像的分布, p g ( x ) p_g(x) pg(x)是生成图像的分布。a和b分别是假数据和真实数据的标签,而c表示G希望D相信假数据的值。
4.2、AdaIN
AdaIN是针对风格传递提出的,它可以将外部风格图像信息融合到归一化中。AdaIN使用实例归一化(Instance Normalization)对 m i m_i mi进行归一化,然后使用IN在样式特征si上提供的相应均值和方差对其进行缩放和偏置:
AdaIN ( m i , s i ) = σ I N ( s i ) m i − μ I N ( m i ) σ I N ( m i ) + μ I N ( s i ) \operatorname{AdaIN}\left(\mathbf{m}_{i}, \mathbf{s}_{i}\right)=\sigma_{I N}\left(\mathbf{s}_{i}\right) \frac{\mathbf{m}_{i}-\mu_{I N}\left(\mathbf{m}_{i}\right)}{\sigma_{I N}\left(\mathbf{m}_{i}\right)}+\mu_{I N}\left(\mathbf{s}_{i}\right) AdaIN(mi,si)=σIN(si)σIN(mi)mi−μIN(mi)+μIN(si)
4.3、重参数化技巧
重参数化技巧的通常解释是——通过得到多元高斯分布的因子,就可以通过参数化技巧生成该分布的样本。如此分离随机变量的不确定性,使得原先无法求导/梯度传播的中间节点可以求导。
VAE中使用了重新参数化技巧,用于在变分推理中应用梯度下降。一旦我们得到了多元高斯分布的因子,就可以通过重新参数化技巧生成分布的样本。
详细来说,作者首先对随机噪声进行采样,然后根据标准高斯N(0,1),则来自特定多元高斯分布的样本可以是:
z = ϵ ⊙ σ + μ \mathbf{z}=\epsilon \odot \boldsymbol{\sigma}+\boldsymbol{\mu} z=ϵ⊙σ+μ
五、Posterior Promoted GAN
整个网络架构如下图所示
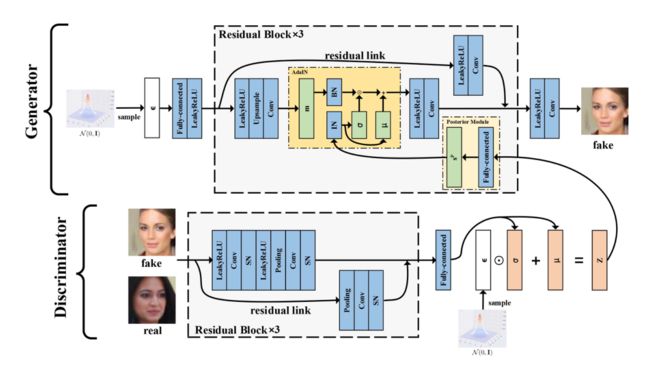
与 GAN 的其他变体不同,Posterior Promoted GAN在判别器中做了许多工作。
判别器将图像作为输入,其将图像映射到多元高斯分布得到并提取真实信息(提取后验分布),生成器在训练过程中借助后验模块和 AdaIN 的真实信息和潜码。
5.1、分布差异
假设a1和a2通过重新参数化技巧从两个不同的一维高斯分布 P 1 = N ( μ 1 , σ 2 2 ) P_1=N(μ_1,σ_2^2) P1=N(μ1,σ22)和 P 2 = N ( µ 2 , σ 2 2 ) P_2=N(µ_2,σ_2^2) P2=N(µ2,σ22)中采样,两个高斯分布之间的差异定义为: Dis = 1 2 ( P 1 − P 2 ) 2 \text { Dis }=\frac{1}{2}\left(P_{1}-P_{2}\right)^{2} Dis =21(P1−P2)2
根据重参数化技巧,可以得到:
a Δ = a 1 − a 2 = ϵ ( σ 1 − σ 2 ) + ( μ 1 − μ 2 ) a_{\Delta}=a_{1}-a_{2}=\epsilon\left(\sigma_{1}-\sigma_{2}\right)+\left(\mu_{1}-\mu_{2}\right) aΔ=a1−a2=ϵ(σ1−σ2)+(μ1−μ2)
则两个分布的差异可以进一步写为:
2 D i s = E [ a Δ 2 ] = E [ ( a Δ − μ Δ + μ Δ ) 2 ] = E [ ( a Δ − μ Δ ) 2 ] + 2 E [ ( a Δ − μ Δ ) μ Δ ] + E [ μ Δ 2 ] = σ Δ 2 + 2 μ Δ ( E [ a Δ ] − μ Δ ) + μ Δ 2 = σ Δ 2 + μ Δ 2 \begin{aligned} 2 D i s &=\mathbb{E}\left[a_{\Delta}^{2}\right] \\ &=\mathbb{E}\left[\left(a_{\Delta}-\mu_{\Delta}+\mu_{\Delta}\right)^{2}\right] \\ &=\mathbb{E}\left[\left(a_{\Delta}-\mu_{\Delta}\right)^{2}\right]+2 \mathbb{E}\left[\left(a_{\Delta}-\mu_{\Delta}\right) \mu_{\Delta}\right]+\mathbb{E}\left[\mu_{\Delta}^{2}\right] \\ &=\sigma_{\Delta}^{2}+2 \mu_{\Delta}\left(\mathbb{E}\left[a_{\Delta}\right]-\mu_{\Delta}\right)+\mu_{\Delta}^{2} \\ &=\sigma_{\Delta}^{2}+\mu_{\Delta}^{2} \end{aligned} 2Dis=E[aΔ2]=E[(aΔ−μΔ+μΔ)2]=E[(aΔ−μΔ)2]+2E[(aΔ−μΔ)μΔ]+E[μΔ2]=σΔ2+2μΔ(E[aΔ]−μΔ)+μΔ2=σΔ2+μΔ2
如果 2 Dis = σ Δ 2 + μ Δ 2 = ( σ 1 − σ 2 ) 2 + ( μ 1 − μ 2 ) 2 = 0 2 \text { Dis }=\sigma_{\Delta}^{2}+\mu_{\Delta}^{2}=\left(\sigma_{1}-\sigma_{2}\right)^{2}+\left(\mu_{1}-\mu_{2}\right)^{2}=0 2 Dis =σΔ2+μΔ2=(σ1−σ2)2+(μ1−μ2)2=0,那就意味着方差σ和均值μ相等,进而意味着两个高斯分布相等。以上证明是模型结构的基础之一。
5.2、后验分布鉴别器
鉴别器输出潜在向量z的后验分布。其使用两个没有激活函数的全连接层输出多元高斯分布的两个因子,每个维度通过重新参数化技巧相互独立。频谱归一化(Spectral Normalization )应用于鉴别器的每一层,用于稳定训练。
已知 μ ∈ R b × d \mathbf{μ} \in \mathbb{R}^{b \times d} μ∈Rb×d、 σ ∈ R b × d \mathbf{σ} \in \mathbb{R}^{b \times d} σ∈Rb×d,b表示batchsize,d是高斯分布的维数。
给定一批图像 x ∈ R b × h × w × c \mathbf{x} \in \mathbb{R}^{b \times h \times w \times c} x∈Rb×h×w×c,鉴别器同时输出μ和σ,而 Z ∈ R b × d \mathbf{Z} \in \mathbb{R}^{b \times d} Z∈Rb×d,后验分布可以表示为 D ( x ) = N ( z ; μ , σ 2 I ) D(\mathbf{x})=\mathcal{N}\left(\mathbf{z} ; \boldsymbol{\mu}, \sigma^{2} \mathbf{I}\right) D(x)=N(z;μ,σ2I),其中x可以表示真实图像分布或者生成的图像分布。构造两个先验分布 P a = N ( μ a , σ a 2 I ) P_{a}=\mathcal{N}\left(\boldsymbol{\mu}_{\boldsymbol{a}}, \sigma_{a}^{2} \mathbf{I}\right) Pa=N(μa,σa2I) 和 P b = N ( μ b , σ b 2 I ) P_{b}=\mathcal{N}\left(\boldsymbol{\mu}_{\boldsymbol{b}}, \sigma_{b}^{2} \mathbf{I}\right) Pb=N(μb,σb2I),将LSGAN的损失推广到分布版本,鉴别器的损失可以描述如下:
L D = 1 2 E x ∼ p data ( x ) [ ( D ( x ) − P b ) 2 ] + 1 2 E x ∼ p g ( x ) [ ( D ( x ) − P a ) 2 ] , \begin{aligned} \mathcal{L}_{D}=& \frac{1}{2} \mathbb{E}_{\mathbf{x} \sim p_{\text {data }}(\mathbf{x})}\left[\left(D(\mathbf{x})-P_{b}\right)^{2}\right]+ \frac{1}{2} \mathbb{E}_{\mathbf{x} \sim p_{g}(\mathbf{x})}\left[\left(D(\mathbf{x})-P_{a}\right)^{2}\right], \end{aligned} LD=21Ex∼pdata (x)[(D(x)−Pb)2]+21Ex∼pg(x)[(D(x)−Pa)2],
其中,第一项缩短了给定真实图像的后验D(x)与真实图像的虚拟实况真实先验Pb之间的距离。第二项缩短了后验给定生成图像与另一先前Pa之间的距离。
通过最小化LD,绘制后验给定的生成图像或真实图像,以匹配不同的先验,从而区分真实图像和伪图像。x中的真实信息∼ pdata(x)将用于促进生成过程。
5.3、使用后验分布提升生成器
发电机输入随机噪声ε从标准高斯采样以及来自后验给定真实图像的潜码z,输出生成的图像。
作者通过AdaIN与一些后验模块协调来重新指导发生器,同时,为了防止训练过程中真实信息的消失,引入了一个潜在的代码正则化器。
对抗损失定义为: L a d v = 1 2 E x ∼ p g ( x ) [ ( D ( x ) − P c ) 2 ] \mathcal{L}_{a d v}=\frac{1}{2} \mathbb{E}_{\mathbf{x} \sim p_{g}(\mathbf{x})}\left[\left(D(\mathbf{x})-P_{c}\right)^{2}\right] Ladv=21Ex∼pg(x)[(D(x)−Pc)2],其中, P c = P a + P b 2 = N ( μ a + μ b 2 , ( σ a + σ b 2 ) 2 I ) P_{c}=\frac{P_{a}+P_{b}}{2}=\mathcal{N}\left(\frac{\mu_{a}+\mu_{b}}{2},\left(\frac{\sigma_{a}+\sigma_{b}}{2}\right)^{2} \mathbf{I}\right) Pc=2Pa+Pb=N(2μa+μb,(2σa+σb)2I)。
传统上,生成器接收从标准高斯采样的随机噪声 ε ∈ R b × n ε∈ R^{b×n} ε∈Rb×n并用于产生图像,其中n是随机噪声的维数,基于这个设计,在给定 x ∼ p data ( x ) x \sim p_{\text {data }}(x) x∼pdata (x),引入一个来自于后验判别输出的后验向量 z ∼ D ( x ) z \sim D(x) z∼D(x),与AdaIN一起将包含在后验中的真实信息嵌入到生成器的每一层当中。
后验模块是相互独立的完全连接的层,没有任何激活功能,如模型结构图所示,它们用于将 映射到对应于不同卷积信道的不同维度的特征。除了在每一层应用真实信息之外,后验模块还提供了根据不同卷积层的需求调整信息: s i p = P i ( z ) \mathrm{s}_{i}^{p}=\mathrm{P}_{i}(z) sip=Pi(z)
作者的方法使用后验特征作为AdaIN中的外部信息,生成器中使用的AdaIN层如下: AdaIN ( m i , s i p ) = σ I N ( s i p ) m i − μ B N ( m i ) σ B N ( m i ) + μ I N ( s i p ) \operatorname{AdaIN}\left(\mathbf{m}_{i}, \mathbf{s}_{i}^{p}\right) = \sigma_{I N}\left(\mathbf{s}_{i}^{p}\right) \frac{\mathbf{m}_{i}-\mu_{B N}\left(\mathbf{m}_{i}\right)}{\sigma_{B N}\left(\mathbf{m}_{i}\right)}+\mu_{I N}\left(\mathbf{s}_{i}^{p}\right) AdaIN(mi,sip)=σIN(sip)σBN(mi)mi−μBN(mi)+μIN(sip)
作者首先利用BN对 m i m_i mi进行归一化,使其具有零均值和单位方差,然后用具有真实信息的 s i p s_i^p sip的均值和方差对其进行偏置和缩放,最后将后验特征向量z和AdaIN加入到生成器,以真实图像为样式参考,对生成的图像进行“样式转换”。
因此AdaIN通过改变特征的统计信息将真实信息融合到每一层。为了在训练过程中保留真实信息,作者提出了一个正则化器 L z L_z Lz,用于最小化后验给定生成图像和真实图像之间的距离: L z = E x g ∼ p g ( x ) , x r ∼ p data ( x ) [ ∣ D ( x g ) − D ( x r ) ∣ ] \mathcal{L}_{z}=\mathbb{E}_{\mathbf{x}_{g} \sim p_{g}(\mathbf{x}), \mathbf{x}_{r} \sim p_{\text {data }}(\mathbf{x})}\left[\left|D\left(\mathbf{x}_{g}\right)-D\left(\mathbf{x}_{r}\right)\right|\right] Lz=Exg∼pg(x),xr∼pdata (x)[∣D(xg)−D(xr)∣]
综上所述,生成器总的损失为: L G = L a d v + λ L z \mathcal{L}_{G}=\mathcal{L}_{a d v}+\lambda \mathcal{L}_{z} LG=Ladv+λLz
5.4、理论分析
讨论P2GAN和f散度之间的关系:
给定固定参数的生成器G,我们可以导出基于LSGAN的最优鉴别器: D ∗ ( x ) = P b p d a t a ( x ) + P a p g ( x ) p data ( x ) + p g ( x ) D^{*}(\mathbf{x})=\frac{P_{b} p_{d a t a}(\mathbf{x})+P_{a} p_{g}(\mathbf{x})}{p_{\text {data }}(\mathbf{x})+p_{g}(\mathbf{x})} D∗(x)=pdata (x)+pg(x)Pbpdata(x)+Papg(x),当D最优时,正则化损失 L z L_z Lz为0,为了分析G的最佳值,将损失 L G L_G LG改写如下: C ( G ) = 1 2 E x ∼ p data ( x ) [ ( D ( x ) − P c ) 2 ] + 1 2 E x ∼ p g ( x ) [ ( D ( x ) − P c ) 2 ] \begin{aligned} C(G)=& \frac{1}{2} \mathbb{E}_{\mathbf{x} \sim p_{\text {data }}(\mathbf{x})}\left[\left(D(\mathbf{x})-P_{c}\right)^{2}\right]+ \frac{1}{2} \mathbb{E}_{\mathbf{x} \sim p_{g}(\mathbf{x})}\left[\left(D(\mathbf{x})-P_{c}\right)^{2}\right] \end{aligned} C(G)=21Ex∼pdata (x)[(D(x)−Pc)2]+21Ex∼pg(x)[(D(x)−Pc)2],通过变换(详细见原文),最终得到: 2 C ( G ) = ( P b − P a ) 2 4 ∫ [ 2 p g − ( p data + p g ) ] 2 p data + p g d x = ( P b − P a ) 2 4 X Pearson 2 ( ( p data + p g ) ∥ 2 p g ) \begin{aligned} 2 C(G) &=\frac{\left(P_{b}-P_{a}\right)^{2}}{4} \int \frac{\left[2 p_{g}-\left(p_{\text {data }}+p_{g}\right)\right]^{2}}{p_{\text {data }}+p_{g}} d x \\ &=\frac{\left(P_{b}-P_{a}\right)^{2}}{4} \mathcal{X}_{\text {Pearson }}^{2}\left(\left(p_{\text {data }}+p_{g}\right) \| 2 p_{g}\right) \end{aligned} 2C(G)=4(Pb−Pa)2∫pdata +pg[2pg−(pdata +pg)]2dx=4(Pb−Pa)2XPearson 2((pdata +pg)∥2pg)
D ∗ ( x ) = P b p data ( x ) + P a p g ( x ) p data ( x ) + p g ( x ) = P b + P a 2 = N ( μ a + μ b 2 , ( σ a + σ b 2 ) 2 I ) D^{*}(\mathbf{x})=\frac{P_{b} p_{\text {data }}(\mathbf{x})+P_{a} p_{g}(\mathbf{x})}{p_{\text {data }}(\mathbf{x})+p_{g}(\mathbf{x})}=\frac{P_{b}+P_{a}}{2}=\mathcal{N}\left(\frac{\boldsymbol{\mu}_{\boldsymbol{a}}+\boldsymbol{\mu}_{\boldsymbol{b}}}{2},\left(\frac{\sigma_{a}+\sigma_{b}}{2}\right)^{2} \mathbf{I}\right) D∗(x)=pdata (x)+pg(x)Pbpdata (x)+Papg(x)=2Pb+Pa=N(2μa+μb,(2σa+σb)2I)
六、实验
6.1、实验设置
- 数据集:
CIFAR10:10个类中的60000张32×32×3的图像,每个类有6000张图像;CelebA:由202599张名人照片组成,40种面部特征有很大差异。 - 实验细节:
Adam:β1=0.0,β2=0.999,batchsize b=32,λ=10,channel size c=64; - 评价指标:
Frechet Inception Distance :FID计算生成的图像和真实图像之间的Wasserstein-2距离,这是一个更为原则和全面的度量。FID越低表示图像质量越好。具体原理可以看:FID定量评价指标分析笔记
6.2、实验结果
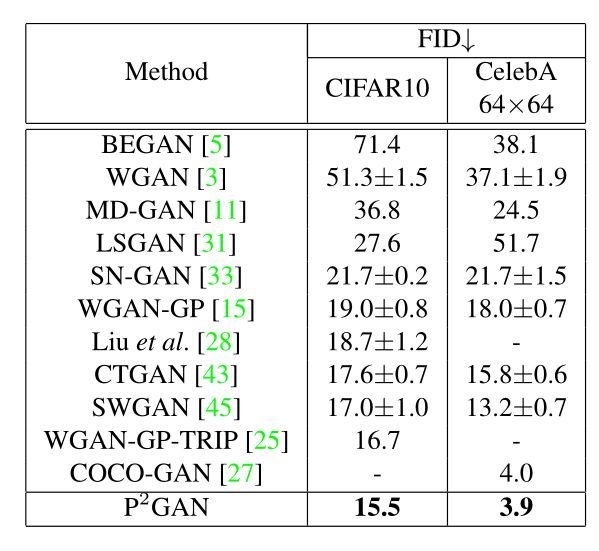
下表为CIFAR10和CelebA的FID分数,可以看到P2GAN的表现性能优越。
下面是部分生成的样本:


除此之外,作者还做了大量的分析实验和消融研究,详情可以看原文。
七、总结
文章提出了一种新的GAN变体,称为P2GAN,它通过将图像映射到多元高斯分布来修改鉴别器以产生丰富的真实信息,并通过AdaIN和真实信息增强生成器。
作者将LSGAN的损失修改为分布版本,并从理论上证明了收敛性。
实验中的收敛性分析表明了该训练方法的有效性,而插值结果表明模型已经学习到了一个鲁棒且充分的潜在流形结构,P2GAN在高维多模态数据集上取得了与最先进模型相当的结果。
最后
个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
关注我:中杯可乐多加冰
限时免费订阅:文本生成图像T2I专栏
支持我:点赞+收藏⭐️+留言