Tensorflow2.0
-
Tensorflow 简介
-
Tensorflow是什么
-
Google开源软件库
- 采用数据流图,用于数值计算
- 支持多平台 GPU CPU 移动设备
- 最初用于深度学习,变得通用
-
数据流图
- 节点---处理数据
- 线---节点之间的输入输出关系
- 线上运输张量
- 节点被分配到各种计算设备上运行
-
特性
- 高度的灵活性
- 真正的可移植性
- 产品与科研结合
- 自动求微分
- 多语言支持
- 性能最优化
-
-
历史
-
历史版本
- 2015年11月:首次发布
- 2015年12月:支持GPU python3.3(v0.6)
- 2016年4月:分布式tensorflow(v0.8)
- 2016年11月:支持windows(v0.11)
- 2017年2月:性能改进,API稳定性(v1.0)
- 2017年4月:Keras集成(v1.1)
- 2017年8月:高级API,预算估计器,更多模型,初始TPU支持(v1.3)
- 2017年11月:Eager execution和Tensorflow Lite(v1.5)
- 2018年3月:TF hub(与训练的库),Tensorflow.js Tensorflow Extended(TFX)
- 2018年5月:新入门内容 Cloud TPU模块与管道(v1.6)
- 2018年6月:新的分布式策略API:概率编程工具,Tensorflow Probability(v1.8)
- 2018年8月:Cloud Big Table 集成(v1.10)
- 2018年10月:侧重可用性的API改进(v1.12)
- 2019年:tensorflow2.0
-
Tensorflow1.0--------------主要特性
- XLA:Accelerate Linear Algebra
- 提升速度58倍
- 可以在移动设备运行
- 引入更高级的API-------tf.layers/tf.metrics/tf.losses/tf.keras
- Tensorflow 调试器
- 支持docker,引入tensorflow serving服务
- XLA:Accelerate Linear Algebra
-
Tensorflow1.0---------------------架构
Kears,Estimator,Datasets,Layers,Distribution engine

-
Tensorflow2.0----------------------主要特性
- 使用tf.keras和eager mode进行更加简单的模型构建
- 鲁棒的跨平台部署
- 强大的研究实验
- 清除了不推荐使用的API和减少了重复来简化PI
-
Tensorflow2.0------------------------架构

-
Tensorflow2.0--------简化的模型开发流程
- 使用tf.data加载数据
- 使用tf.keras构建模型,也可以使用premade estimator来验证模型
- 使用tensorflow hub 进行迁移学习
- 使用eager mode 进行运行和调试
- 使用分发策略进行分布式训练
- 导出到SavedModel
- 使用Tensorflow Serve,Tensorflow Lite,Tensorflow.js部署模型
-
Tensorflow2.0-----------强大的跨平台能力
- Tensorflow服务
- 直接通过Http/REST或GRPC/协议缓冲区
- Tensorflow Lite----------可部署在Android ios和其他嵌入式设备
- Tensorflow.js------可在javascript中部署模型
- 其他语言
- c,java,go,c#等
- Tensorflow服务
-
Tensorflow2.0------------强大的研究实现
- keras功能和子类API,允许创建一些复杂的拓扑结构
- 自定义训练逻辑,使用tf.GradientTape和tf.custom_gradient进行更细力度的控制
- 低层API自始至终可以与高层结合使用,完全的可定制
- 高级扩展:Ragged Tensors,Tensor2Tensor等
-
-
Tensorflow vs Pytorch
-
入门时间
-
Tensorflow 1.*
- 静态图
- 学习额外概念
- 图,会话,变量,占位符等
- 写样板代码
-
Tensorflow 2.*
- 动态图
- Eager mode避免1.0缺点,直接集成在python中
-
Pytorch
- 动态图
- Numpy的扩展,直接集成在python中
-
静态图效率高,动态图容易调试
-
代码示例 1+\(\frac{1}{2}\)+ \(\frac{1}{2^2}\)+.....+\(\frac{1}{2^{50}}\)
-
# python x = 0 y = 1 for iteration in range(50): x = x + y y = y / 2 print(x) -
# Pytorch import torch x = tf.constant(0.) y = tf.constant(1.) for iteration in range(50): x = x + y y = y / 2 print(x) -
# tensorflow1.* import tensorflow as tf x = tf.constant(0.) y = tf.constant(1.) add_op = x.assgin(x+y) div_op = y.assgin(y/2) with tf.Session() as sess: sess.run(tf.golbal_variables_initializers()) for iteration in range(50): sess.run(add_op) sess.run(dic_op) print(x.eval()) # sess.eval(x) -
# tensorflow2.* import tensorflow as tf x = tf.constant(0.) y = tf.constant(1.) for iteration in range(50) x = x + y y = y / 2 print(x.numpy())
-
-
-
图创建和调试
- Tensorflow 1.*
- 静态图,难以调试,学习tfdbg调试
- Tensorflow 2.*与pytorch
- 动态图,python自带的调试工具
- Tensorflow 1.*
-
全面性
- Pythorch缺少
- 沿维翻转张量(np.flip,np.flipud,np.fliplr)
- 检查无穷与非数值张量(np.is_nan,np.is_inf)
- 快速傅里叶变换(np.fft)
- 随着时间变化,越来越接近
- Pythorch缺少
-
序列化和部署
- Tensorflow支持更加广泛
- 图保存为protocol buffer
- 跨语言
- 跨平台
- Pytorch支持比较简单
-
-
环境配置
-
本地配置
- Virtualenv 安装或anaconda3
- GPU环境配置
-
云端配置
-
为什么在云端配置
- 规格统一,节省自己的机器
- 有直接配置好的镜像
-
云环境
-
Google Cloud,Amazon
-
实战
-
从0配置
# ubuntu 18.04 sudo apt-get install python3 # 安装python3 sudo apt-get install python # 安装python3 sudo apt-get install software-properties-common sudo apt-add-repository universe # 奖pip所在源加入ubuntu sudo apt-get update sudo apt-get install python-pip sudo apt-get install python3-pip sudo pip3 install -U virtualenv # 或使用anaconda3 # 创建虚拟环境 mkdir environment && cd environment virtualenv --system-site-packages -p python3 ./tf_py3 source tf_py3/bin/activate # 激活环境 pip install tensorflow # pip install tensorflow==2.0.0 pip install numpy pandas matplotlib sklearn jupyter # 配置jupyter # 修改为静态ip配置,端口 jupyter notebook --generate-config # 家目录生成配置文件 .jupyter c = get_config() c.NotebookApp.ip = "*" c.NotebookAPP.open_borwser = False c.NotebookAPP.post = 6006 c.NotebookApp.allow_remote_access = True # 可使用token设置密码 供以后使用 deactivate # 退出环境 # 配置gpu环境 # https://tensorflow.google.cn/install/gpu # 找到ubuntu18.04 复制为安装脚本执行即可 # 可能会出现版本号不对应错误 libnvinfer-dev 将脚本中最后一条命令修改后运行libnvinfer-dev-5.1.5-1+cuda10.1 即可成功 nvidia-smi # 查看GPU信息 # tensorflow-gpu安装与cpu版类似
-
-
-
tf.test.is_gpu_available() # 判断gpu可用与否
```2. 从镜像配置 ```shell # 云端的系统镜像直接有开发环境 # 升级tensorflow 版本 pip install --upgrade tensorflow-gpu==2.0.0 pip3 install --upgrade tensorflow-gpu==2.0.0 ``` -
-
-
Tensorflow keras 实战
-
keras是什么
- 基于python的高级神经网络API
- Francois Chollet2014-2015编写
- 以Tensorflow CNTK,或Theano为后端运行,keras必须有后端才可以
- 后端可以切换,现在多用tensorflow
- 及方便用于快速试验
-
tf.keras是什么
- Tensorflow 对kerasAPI规范的实现
- 相对于tensorflow为后端的keras,Tensorflow-keras与tensorflow结合更紧密
- 实现在tf.keras下
-
Tf-keras与keras的
-
联系
- 基于同一套API
- keras程序可转化为tf.keras
- 反之可能不成立,tf.keras有其它特性
- 相同的JSON与hdf5模型序列化格式和语义
- 基于同一套API
-
区别
- Tf.keras全面支持eager mode
- 只使用keras.Sequential和keras.Model时没影响
- 自定义Model内部运算逻辑时会有影响
- T低层API可以使用keras的model.fit等抽象法
- 适用于研究人员
- Tf.keras支持基于tf.data的模型训练
- Tf.keras支持TPU训练
- Tf.keras支持tf.distribution中的分布式策略
- 其他特性
- Tf.keras可以与Tensorflow中的estimator集成
- Tf.keras可以保存为SavedModel
- Tf.keras全面支持eager mode
-
-
知识点
-
分类问题与回归问题
- 分类问题:输出类型是概率分布
- 回归问题:输出是一个是数值
-
目标函数
-
参数逐步调整
-
目标函数帮助衡量模型好坏
-
分类问题
-
要衡量目标类别与当前预测的差距
- 三分类问题输出:[0.2,0.7,0.1]
- 真是类别:2->ont_hot->[0,0,1]
-
One_hot编码,把正整数变为向量表达
- 生成一个长度不小于正整数的向量,只有正整数的位置处为1,其余位置都为0
-
平方差损失
\[\frac{1}{n} \sum_{x,y}\frac{1}{2}(y-Model(x))^2 \] -
交叉熵损失
\[\frac{1}{n}\sum_{x,y}yln(Model(x)) \]
-
-
回归问题
- 预测值与真实值的差距
- 平方差损失
- 绝对值损失
-
-
-
Tf框架:keras,回调函数
-
keras搭建模型
-
# coding:utf-8 # file: tf_keras_classification_model.py # author: Dean # contact: [email protected] # time: 2019/12/17 11:47 # desc: keras模型搭建 import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os,sys,time import tensorflow as tf from tensorflow import keras # import keras def showVersion(): print((tf.__version__)) print(sys.version_info) for module in mpl, np, pd, sklearn, tf, keras: print(module.__name__,module.__version__) class_names = ['T-shirt','Trouser','Pullover','Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot' ] fashion_mnist = keras.datasets.fashion_mnist (x_train_all,y_train_all),(x_test,y_test) = fashion_mnist.load_data() x_valid, x_train = x_train_all[:5000], x_train_all[5000:] y_valid, y_train = y_train_all[:5000], y_train_all[5000:] def showDataShape(): print(x_valid.shape, y_valid.shape) print(x_train.shape, y_train.shape) print(x_test.shape, y_test.shape) def show_single_image(img_arr): plt.imshow(img_arr,cmap="binary") plt.show() def show_images(n_rows, n_cols, x_data, y_data, class_names): assert len(x_data) == len(y_data) assert n_rows * n_cols < len(x_data) plt.figure(figsize = (n_cols * 1.4, n_rows * 1.6)) for row in range(n_rows): for col in range(n_cols): index = n_cols * row + col plt.subplot(n_rows, n_cols, index+1) plt.imshow(x_data[index], cmap="binary",interpolation="nearest") plt.axis("off") plt.title(class_names[y_data[index]]) plt.show() def nn(): model = keras.models.Sequential() # keras.Sequential() 好像与此一样 model.add(keras.layers.Flatten(input_shape=[28,28])) model.add(keras.layers.Dense(300,activation="relu")) model.add(keras.layers.Dense(100,activation="relu")) # relu : y = max(0,x) model.add(keras.layers.Dense(10,activation="softmax")) """ 或 model = keras.models.Sequential([ keras.layers.Flatten(input_shape=[28,28]), keras.layers.Dense(300,activation="relu"), keras.layers.Dense(100,activation="relu"), keras.layers.Dense(10,activation="softmax") ]) """ # softmax : x = [x1, x2, x3], # y = [e^x1/sum, e^x2/sum,e^x3/sum] sum = e^x1+e^x2+e^x3 model.compile(loss="sparse_categorical_crossentropy", optimizer = "adam", # 若loss太低,可能是算法的问题,换用优化过的梯度下降算法 metrics = ['accuracy']) # model.summary() # 显示模型信息 history = model.fit(x_train,y_train,epochs=10,validation_data=(x_valid,y_valid)) # history.history # 中间结果 json return history def plot_learning_curves(history): pd.DataFrame(history.history).plot(figsize=(8,5)) plt.grid(True) plt.gca().set_ylim(0,1) plt.show() if __name__ =="__main__": pass # show_single_image(x_train[0]) # showVersion() # show_images(3,5,x_train,y_train,class_names) history = nn() plot_learning_curves(history) -
# coding:utf-8 # file: tf_keras_classification_model_normalizer.py # author: Dean # contact: [email protected] # time: 2019/12/17 11:47 # desc: 归一化提高准确率 import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os,sys,time import tensorflow as tf from tensorflow import keras def showVersion(): print((tf.__version__)) print(sys.version_info) for module in mpl, np, pd, sklearn, tf, keras: print(module.__name__,module.__version__) class_names = ['T-shirt','Trouser','Pullover','Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot' ] fashion_mnist = keras.datasets.fashion_mnist (x_train_all,y_train_all),(x_test,y_test) = fashion_mnist.load_data() x_valid, x_train = x_train_all[:5000], x_train_all[5000:] y_valid, y_train = y_train_all[:5000], y_train_all[5000:] # 归一化处理 x = (x-u) / std x-减去均值/方差 : 均值是0方差是1的正态分布 from sklearn.preprocessing import StandardScaler scaler = StandardScaler() # x_train:[None,28,28] ---->[None, 784] ------>[None, 28, 28] x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1,1)).reshape(-1,28,28) x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1,1)).reshape(-1,28,28) # 使用训练集的均值,方差 x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1,1)).reshape(-1,28,28) def nn(): model = keras.models.Sequential() # keras.Sequential() 好像与此一样 model.add(keras.layers.Flatten(input_shape=[28,28])) model.add(keras.layers.Dense(300,activation="relu")) model.add(keras.layers.Dense(100,activation="relu")) # relu : y = max(0,x) model.add(keras.layers.Dense(10,activation="softmax")) model.compile(loss="sparse_categorical_crossentropy", optimizer = "adam", # 若loss太低,可能是算法的问题,换用优化过的梯度下降算法 metrics = ['accuracy']) history = model.fit(x_train_scaled,y_train,epochs=10,validation_data=(x_valid_scaled,y_valid)) model.evaluate(x_test_scaled,y_test) # 验证集验证 return history def plot_learning_curves(history): pd.DataFrame(history.history).plot(figsize=(8,5)) plt.grid(True) plt.gca().set_ylim(0,1) plt.show() if __name__ =="__main__": pass history = nn() plot_learning_curves(history)
-
-
回调函数
-
module: tf.keras.callbacks(本文中只有重要的几个)
-
EarlyStopping:提起终止训练
-
ModelCheckpoint:每隔一段时间保存模型
-
TensorBoard:可在训练过程中图形化显示
# coding:utf-8 # file: tf_keras_classification_model_callbacks.py # author: Dean # contact: [email protected] # time: 2019/12/17 11:47 # desc: 回调函数 import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os,sys,time import tensorflow as tf from tensorflow import keras def showVersion(): print((tf.__version__)) print(sys.version_info) for module in mpl, np, pd, sklearn, tf, keras: print(module.__name__,module.__version__) class_names = ['T-shirt','Trouser','Pullover','Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot' ] fashion_mnist = keras.datasets.fashion_mnist (x_train_all,y_train_all),(x_test,y_test) = fashion_mnist.load_data() x_valid, x_train = x_train_all[:5000], x_train_all[5000:] y_valid, y_train = y_train_all[:5000], y_train_all[5000:] from sklearn.preprocessing import StandardScaler scaler = StandardScaler() x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1,1)).reshape(-1,28,28) x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1,1)).reshape(-1,28,28) # 使用训练集的均值,方差 x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1,1)).reshape(-1,28,28) def nn(): model = keras.models.Sequential() # keras.Sequential() 好像与此一样 model.add(keras.layers.Flatten(input_shape=[28,28])) model.add(keras.layers.Dense(300,activation="relu")) model.add(keras.layers.Dense(100,activation="relu")) # relu : y = max(0,x) model.add(keras.layers.Dense(10,activation="softmax")) model.compile(loss="sparse_categorical_crossentropy", optimizer = "adam", # 若loss太低,可能是算法的问题,换用优化过的梯度下降算法 metrics = ['accuracy']) # Tensorboard,EarlyStopping,ModelCheckpoint # 相对路径可能会报错,另外注意tf2.0以上版本,使用tensorboard时命令行路径不能有中文,最好是进入事件文件所在文件夹 --logdir=. 报错可能小,一般报错都是因为中文路径问题,还有就是--logdir的问题,相对,绝对路径问题(好像是这样,出错时多试试即可,宗旨,少使用中文,logdir=.) logdir = r"D:\desktop\Workspace\PythonWorkSpace\Tensorflow2.0\Tensorflow2.0_谷歌\callbacks" if not os.path.exists(logdir): os.mkdir(logdir) output_model_file = os.path.join(logdir,"fashion_mnist_model.h5") callbacks = [ keras.callbacks.TensorBoard(logdir), keras.callbacks.ModelCheckpoint(output_model_file,save_best_only = True), # 默认保存最近一次训练,True表示保存效果最好的 keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3) # 提前结束 当阈值低于1e-3时记录一次,5次后停止 ] history = model.fit(x_train_scaled,y_train,epochs=10, validation_data=(x_valid_scaled,y_valid), callbacks = callbacks) model.evaluate(x_test_scaled,y_test) # 验证集验证 return history def plot_learning_curves(history): pd.DataFrame(history.history).plot(figsize=(8,5)) plt.grid(True) plt.gca().set_ylim(0,1) plt.show() if __name__ =="__main__": history = nn() plot_learning_curves(history)
-
-
-
-
图像分类,房价预测
-
知识点总结
-
分类问题,回归问题,损失函数
-
神经网络,激活函数,批量归一化,Dropout
-
Min-max 归一化: \(x*=\frac{x-min}{max-min}\)
-
Z-score归一化: \(x*= \frac{x-\mu}{\sigma}\)
-
批归一化:将输入的归一化扩展到每层激活值上,每层的输出是下一层的输入,都做归一化
-
归一化可以加速训练,一定程度上缓解梯度消失
# coding:utf-8 # file: tf_keras_classification_model_dnn.py # author: Dean # contact: [email protected] # time: 2019/12/17 11:47 # desc: 深度神经网络 import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os,sys,time import tensorflow as tf from tensorflow import keras def showVersion(): print((tf.__version__)) print(sys.version_info) for module in mpl, np, pd, sklearn, tf, keras: print(module.__name__,module.__version__) class_names = ['T-shirt','Trouser','Pullover','Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot' ] fashion_mnist = keras.datasets.fashion_mnist (x_train_all,y_train_all),(x_test,y_test) = fashion_mnist.load_data() x_valid, x_train = x_train_all[:5000], x_train_all[5000:] y_valid, y_train = y_train_all[:5000], y_train_all[5000:] from sklearn.preprocessing import StandardScaler scaler = StandardScaler() x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1,1)).reshape(-1,28,28) x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1,1)).reshape(-1,28,28) # 使用训练集的均值,方差 x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1,1)).reshape(-1,28,28) def nn(): model = keras.models.Sequential() model.add(keras.layers.Flatten(input_shape=[28,28])) for _ in range(20): # 循环生成网络 model.add(keras.layers.Dense(100,activation="relu")) # 若使用"selu" 是一个自带归一化的激活函数,使用它不用自己归一化 model.add(keras.layers.BatchNormalization()) """ 对于先激活还是先归一化,不确定,好像都可以,因此下边写法也对 model.add(keras.layers.Dense(100)) model.add(keras.layers.BatchNormalization()) model.add(keras.layers.Activation('relu')) """ model.add(keras.layers.AlphaDropout(rate=0.5)) # dropout层,更强大的dropout,drop后均值,方差不变,归一化性质不变 因此可与selu一起使用 # model.add(keras.layers.Dropout(rate=0.5)) model.add(keras.layers.Dense(10,activation="softmax")) model.compile(loss="sparse_categorical_crossentropy", optimizer = "adam", metrics = ['accuracy']) logdir = r"D:\desktop\Workspace\PythonWorkSpace\Tensorflow2.0\Tensorflow2.0_谷歌\dnn-callbacks" if not os.path.exists(logdir): os.mkdir(logdir) output_model_file = os.path.join(logdir,"fashion_mnist_model.h5") callbacks = [ keras.callbacks.TensorBoard(logdir), keras.callbacks.ModelCheckpoint(output_model_file,save_best_only = True), keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3) ] history = model.fit(x_train_scaled,y_train,epochs=10, validation_data=(x_valid_scaled,y_valid), callbacks = callbacks) model.evaluate(x_test_scaled,y_test) # 验证集验证 return history def plot_learning_curves(history): pd.DataFrame(history.history).plot(figsize=(8,5)) plt.grid(True) plt.gca().set_ylim(0,3) plt.show() if __name__ =="__main__": history = nn() plot_learning_curves(history)
-
-
Wide,deep模型 超参数搜索
-
稀疏特征
- 离散值特征
- One-hot表示,则是稀疏特征
- Eg: 词表={'你好','你',....} 你={0,1,0,0,0,0...}
- 可以叉乘
- 优点:有效,应用于工业界
- 缺点:
- 需要人工设计
- 可能过拟合
-
密集特征
- 向量表达
- Eg: 词表={人工智能,他,你,慕课网}
- 他=[0.3,0.5,0.3,(维向量)]
- Word2vec工具
- 优点:
- 带有语义信息,不同向量之间有相关性
- 兼容没有出现过的特征组合
- 更少的人工参与
- 绝点:过度泛化
- 向量表达
-


-
子类API
-
功能API(函数式API)
-
多输入与多输出
# coding:utf-8 # file: tf_keras_regression_wide_deep.py # author: Dean # contact: [email protected] # time: 2019/12/17 11:47 # desc: wide && deep import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os,sys,time import tensorflow as tf from tensorflow import keras def showVersion(): print((tf.__version__)) print(sys.version_info) for module in mpl, np, pd, sklearn, tf, keras: print(module.__name__,module.__version__) from sklearn.datasets import fetch_california_housing housing = fetch_california_housing() from sklearn.model_selection import train_test_split (x_train_all,x_test,y_train_all,y_test) = train_test_split( housing.data,housing.target,random_state=7 ) x_train, x_valid,y_train, y_valid = train_test_split( x_train_all,y_train_all,random_state=11 ) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() x_train_scaled = scaler.fit_transform(x_train) x_valid_scaled = scaler.transform(x_valid) x_test_scaled = scaler.transform(x_test) def nn(): pass """ # 函数式API input = keras.layers.Input(shape=x_train.shape[1:]) hidden1 = keras.layers.Dense(30,activation="relu")(input) hidden2 = keras.layers.Dense(30,activation="relu")(hidden1) concat = keras.layers.concatenate([input,hidden2]) # 拼接 input 直接到输出,input经过hidden后输出 此时input 是相同的 output = keras.layers.Dense(1)(concat) model = keras.models.Model(inputs=[input],outputs=[output]) """ """ # 子类API class WideDeepModel(keras.models.Model): def __init__(self): super(WideDeepModel,self).__init__() # 定义模型的层次 self.hidden1_layer = keras.layers.Dense(30,activation="relu") self.hidden2_layer = keras.layers.Dense(30,activation="relu") self.output_layer = keras.layers.Dense(1) def call(self,input): # 完成模型的正向计算 hidden1 = self.hidden1_layer(input) hidden2 = self.hidden2_layer(hidden1) concat = keras.layers.concatenate([input,hidden2]) output = self.output_layer(concat) return output model = WideDeepModel() # model = keras.models.Sequential([WideDeepModel(),]) model.build(input_shape=(None,8)) """ """ # 多输入 input_wide = keras.layers.Input(shape=[5]) input_deep = keras.layers.Input(shape=[6]) hidden1 = keras.layers.Dense(30,activation="relu")(input_deep) hidden2 = keras.layers.Dense(30,activation="relu")(hidden1) concat = keras.layers.concatenate([input_wide,hidden2]) # 拼接input是不同的 output = keras.layers.Dense(1)(concat) model = keras.models.Model(inputs=[input_deep,input_wide], outputs=[output]) x_train_scaled_wide = x_train_scaled[:, :5] x_train_scaled_deep = x_train_scaled[:, 2:] x_valid_scaled_wide = x_valid_scaled[:, :5] x_valid_scaled_deep = x_valid_scaled[:, 2:] x_test_scaled_wide = x_test_scaled[:, :5] x_test_scaled_deep = x_test_scaled[:, 2:] # fit ,evaluate 中换对应数据即可 实现多输入x_train_scaled --->[x_train_scaled_wide,x_train_scaled_deep] 还要验证输入,测试输入 """ # 多输出 input_wide = keras.layers.Input(shape=[5]) input_deep = keras.layers.Input(shape=[6]) hidden1 = keras.layers.Dense(30, activation="relu")(input_deep) hidden2 = keras.layers.Dense(30, activation="relu")(hidden1) concat = keras.layers.concatenate([input_wide, hidden2]) # 拼接input是不同的 output = keras.layers.Dense(1)(concat) # 此时有两个输出 output2 = keras.layers.Dense(1)(hidden2) model = keras.models.Model(inputs=[input_deep, input_wide], outputs=[output,output2]) # deep,wide 同上进行分割,注意此时fit时 y_train----->[y_train,y_train] 还有验证y_valid y_test # =================================================== model.summary() model.compile(loss="mean_squared_error", optimizer="adam") # 若出现梯度爆炸 可换用梯度下降算法 callbacks = [keras.callbacks.EarlyStopping(patience=5, min_delta=1e-4)] history = model.fit(x_train_scaled,y_train,epochs=100, validation_data=(x_valid_scaled,y_valid), callbacks=callbacks) model.evaluate(x_test_scaled,y_test) # 验证集验证 return history def plot_learning_curves(history): pd.DataFrame(history.history).plot(figsize=(8,5)) plt.grid(True) plt.gca().set_ylim(0,1) plt.show() if __name__ =="__main__": history = nn() plot_learning_curves(history) -
超参数搜索
- 神经网络训练过程不变的参数
- 网络结构参数:几层,每层宽度,每层激活函数等
- 训练参数:batch_size,学习率,学习衰减算法等
- 手工试耗费人力
- 搜索策略
- 网格搜索
- 定义n维方格
- 每个方格对应一组超参数
- 一组一组尝试
- 例如,学习率定义m个,dropout n个,交叉m*n 次运算
- 随机搜索
- 在网格搜索的网格中,随机搜索,次数变多,
- 遗传算法搜索
- 对自然界模拟
- A,初始化参数集合->训练->得到模型指标作为生存概率
- B,选择->交叉->变异->产生下一代集合
- C,重新到A
- 启发式搜索
- 研究热点-AutoML
- 使用循环神经网络生成参数
- 使用强化学习来进行反馈,使用模型来训练生成参数
- 网格搜索
# coding:utf-8 # file: tf_keras_regression_hp_search.py # author: Dean # contact: [email protected] # time: 2019/12/17 11:47 # desc: 超参数搜索 import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os,sys,time import tensorflow as tf from tensorflow import keras def showVersion(): print((tf.__version__)) print(sys.version_info) for module in mpl, np, pd, sklearn, tf, keras: print(module.__name__,module.__version__) from sklearn.datasets import fetch_california_housing housing = fetch_california_housing() from sklearn.model_selection import train_test_split (x_train_all,x_test,y_train_all,y_test) = train_test_split( housing.data,housing.target,random_state=7 ) x_train, x_valid,y_train, y_valid = train_test_split( x_train_all,y_train_all,random_state=11 ) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() x_train_scaled = scaler.fit_transform(x_train) x_valid_scaled = scaler.transform(x_valid) x_test_scaled = scaler.transform(x_test) def nn(): # 超参数搜索 """ # 自实现超参数搜索,本例简单,顺序运行,参数单一 # learning_rate:[1e-3,3e-4,1e-4,3e-3,1e-2,3e-2] learning_rate = [1e-3,3e-4,1e-4,3e-3,1e-2,3e-2] # w = w + learning_rate * grad historys =[] for lr in learning_rate: model = keras.models.Sequential([ keras.layers.Dense(30,activation="relu",input_shape=x_train.shape[1:]), keras.layers.Dense(1) ]) optimizer = keras.optimizers.Adam(lr) # lr应该是根据不同的策略会逐渐衰减的 model.compile(loss="mean_squared_error", optimizer=optimizer) callbacks = [keras.callbacks.EarlyStopping(patience=5, min_delta=1e-2)] history = model.fit(x_train_scaled,y_train,epochs=100, validation_data=(x_valid_scaled,y_valid), callbacks=callbacks) historys.append(history) """ # RandomizedSearchCV # 1,转化为sklear的model # tf.keras.wrappers.scikit_learn.KerasRegressor # tf.keras.wrappers.scikit_learn.KerasClassifier # 2,定义参数集合 # 3,搜索参数 def build_model(hidden_layers = 1,layer_size = 30, learning_rate = 3e-3): model = keras.models.Sequential() model.add(keras.layers.Dense(layer_size,activation="relu",input_shape=x_train.shape[1:])) for _ in range(hidden_layers - 1): model.add(keras.layers.Dense(layer_size,activation="relu")) model.add(keras.layers.Dense(1)) optimizer = keras.optimizers.Adam(learning_rate) model.compile(loss="mean_squared_error", optimizer=optimizer) return model sklearn_model = keras.wrappers.scikit_learn.KerasRegressor(build_model) # 传入函数名 from scipy.stats import reciprocal # f(x) = 1/(x*log(b/a)) a<=x<=b param_distribution = { "hidden_layers": [1, 2, 3, 4], "layer_size": np.arange(1, 100), # [1,2,3....100] "learning_rate": reciprocal(1e-4, 1e-2) # 按照某种分布生成 } from sklearn.model_selection import RandomizedSearchCV random_search_cv = RandomizedSearchCV(sklearn_model, param_distribution, cv = 5, # 交叉验证 份数 n_iter=10, # 随机寻找参数组合的数量,默认值为10。 n_jobs=1) # 并行计算时使用的计算机核心数量,默认值为1。当n_jobs的值设为-1时,则使用所有的处理器。 callbacks = [keras.callbacks.EarlyStopping(patience=5, min_delta=1e-2)] history = random_search_cv.fit(x_train_scaled, y_train, epochs=100, # 还使用fit validation_data=(x_valid_scaled, y_valid), callbacks=callbacks) # cross_validation:交叉验证 ,训练集分为n份 n-1份训练,1份测试 random_search_cv.best_params_ # 最好的参数 random_search_cv.best_score_ # 最好的参数对应的分数 model = random_search_cv.best_estimator_.model # 最好的模型 model.evaluate(x_test_scaled,y_test) # 测试 return historys def plot_learning_curves(history): pd.DataFrame(history.history).plot(figsize=(8,5)) plt.grid(True) plt.gca().set_ylim(0,1) plt.show() if __name__ =="__main__": historys = nn() for history in historys: print() plot_learning_curves(history) - 神经网络训练过程不变的参数
-
-
-
-
Tensorflow基础API使用
-
概要
- Tf框架:基础数据类型,自定义模型与损失函数,自定义求导,tf.function,图结构\
- 项目:图像分类,房价预测
-
知识点
- 基础API
- 基础API与keras的集成
- 自定义损失函数
- 自定义层次
- @tf.function的使用(2.0专有:将python转化为图结构)
- 自定义求导
-
@tf.function
- 将python函数编译为图
- 易于将模型导出为GraphDef+checkpoint 或者SavedModel
- 使得eager execution可以默认打开
- 1.0的代码可以通过tf.function在2.0继续使用
- 代替session
-
API
-
基础数据类型
-
Tf.constant,tf.string
-
# 0维 一个数 shape=() # 1维 列表 shape=(n) # 2维 二维数组 shape=(m,n) t = tf.constant([ [1,2,3], [4,5,6] ]) # 2.0中可以直接获取值 print(t) print(t[:,1:]) print(t[...,2]) # 一维向量 tf.Tensor([3 6], shape=(2,), dtype=int32) print(t+10) # 都加上10 print(tf.square(t)) # 每个数平方 print(t @ tf.transpose(t)) # 返回t与它转置的乘积 2*2 print(t.numpy()) # 直接转化为numpy对象 2*3矩阵 -
t = tf.constant("tensorflow") print(t) # tf.Tensor(b'tensorflow', shape=(), dtype=string) print(tf.strings.length(t)) # tf.Tensor(10, shape=(), dtype=int32) print(tf.strings.length(t,unit="UTF8_CHAR")) # tf.Tensor(10, shape=(), dtype=int32) print(tf.strings.unicode_decode(t,"utf8")) # tf.Tensor([116 101 110 115 111 114 102 108 111 119], shape=(10,), dtype=int32) t = tf.constant(['cafe','coffee','咖啡']) # print(tf.strings.length(t,unit="UTF8_CHAR")) # tf.Tensor([4 6 2], shape=(3,), dtype=int32) print(tf.strings.unicode_decode(t,"utf8")) #
-
-
tf.ragged.constant,tfSpareTensor
-
v = tf.Variable([[1,2,3,4],[5,6,7,8]]) print(v) # Variable 对象 print(v.value()) # tensor print(v.numpy()) # numpy矩阵 # 重新赋值,不能用等于号 v.assign(2*v) v[0,1].assign(42) v[1].assign([9,10,11,12]) -
t = tf.ragged.constant([[11,12],[13,14,15]]) print(t) #print(t[1]) # tf.Tensor([13 14 15], shape=(3,), dtype=int32) print(t[1:2]) # print(tf.concat([t,t],axis=0)) # 按照行拼接变为4行 print(tf.concat([t,t],axis=1)) # 若要按照列拼接,首先行数要相同 print(t.to_tensor()) # 变为普通tensor 空的位置补为0,0都在正常值后边 -
t = tf.SparseTensor(indices=[[0,1],[1,0],[2,3]], # 注意必须先[0,1] 再[0,2] 否则to_dense 会报错,若必须不按顺序 tf.sparse.reorder(t) 即可使用 values=[1,2,3], dense_shape=[3,4]) print(t) # 存储稀疏矩阵,指定值位置,数值,shape即可 print(tf.sparse.to_dense(t)) # 转换为普通tensor # 不能加法 t2 = tf.constant("..") # 普通的4*3 Tensor tf.sparse.sparse_dense_matmul(t,t2) # 得到的是3*3普通Tensor
-
-
-
自定义损失函数------Tf.reduce_mean
def customized_mse(y_true, y_pred): return tf.reduce_mean(tf.square(y_pred - y_true)) model.compile(loss=customized_mse, optimizer="adam",metrics=["mean_squared_error"]) -
自定义层次-----Keras.layers.Lambda和继承法
-
layer = tf.keras.layers.Dense(100,input_shape=[None,5]) layer(tf.zero([10,5])) # 输出[10,100] 二维 # [10,5] * w +b = [10,100] # w [5:100] layer.trainable_variables # 获得kernel 与bias 可以查看 # --------------------------------------------- class CustomizedDenseLayer(keras.layers.Layer): def __init__(self,units,activation=None,**kwargs): self.units = units self.activation = keras.layers.Activation(activation) super(CustomizedDenseLayer, self).__init__(**kwargs) def build(self,input_shape): """构建需要的参数""" # x * w +b [None,a] w[a,b] [None,b] self.kernel = self.add_weight(name="kernel", shape=(input_shape[1],self.units), initilizer="uniform", # 定义随机初始化kernel的方法:此处使用均匀分布 trainable=True) self.bias = self.add_weight(name="bias", shape=(self.units,), initilizer="zeros", trainable=True) super(CustomizedDenseLayer,self).build(input_shape) def call(self,x): """完整的正向计算""" return self.activation(x @ self.kernel + self.bias) # @ 表示矩阵乘法 model = keras.models.Sequential([ CustomizedDenseLayer(30, activation="relu", input_shape=x_train.shape[1:]), CustomizedDenseLayer(1) ]) -
# 定义简单的层次,激活函数层,dropout层等 # eg:tf.nn.softplus: log(1+e^x) # customized_softplus = keras.layers.Dense(1,activation="softplus") = keras.layers.Dense(1),keras.layers.Activation("softplus") customized_softplus = keras.layers.Lambda(lambda x:tf.nn.softplus(x))
-
-
Tf.function
-
Tf.fucntion,tf.autograph.to_code,
-
# python ----->图 # 法一 def scaled_elu(z,scale=1.0,alpha=1.0): # python函数 # z>=0?scale *z :scale * alpha * tf.nn.elu(z) is_positive = tf.greater_equal(z,0.0) return scale * tf.where(is_positive,z,alpha * tf.nn.elu(z)) print(scaled_elu(tf.constant(-3))) # 常量 print(scaled_elu(tf.constant([-3,-2.5]))) # 列表向量 都何以全部接受并处理 scaled_elu_tf = tf.function(scaled_elu) scaled_elu_tf.python_function # 返回原来的python函数 print(scaled_elu(tf.constant(-3))) print(scaled_elu(tf.constant([-3,-2.5]))) # 与上边结果相同,转换的作用是速度加快 # 法二 # 1+1/2+....1/2^n @tf.function def converge_to(n_iters): total = tf.constant(0.) increment = tf.constant(1.) for _ in range(n_iters): total += increment increment /= 2.0 return total print(converge_to(20)) -
def display_tf_code(func): # 中间代码 # python代码转为tf代码, 图就是通过此转换的 code = tf.autograph.to_code(func) # 还有to_graph 是将代码转为图的 from IPython.display import display,Markdown display(Markdown('```python\n{}\n```'.format(code))) display_tf_code(scaled_elu) -
var = tf.Variable(0.) @tf.function def add_21(): return var.assign_add(21) print(add_21()) # 结果返回21的tensor ,若var在内部会报错, 神经网络中大多是变量,需要在外边初始化 @tf.function(input_signature=[tf.TensorSpec([None],tf.int32,name='x')]) def cube(z): # 可接收浮点数,整数 使用输入签名后会限制只能输入int32 return tf.pow(z,3) print(cube(tf.constant([1.2,2.6]))) print(cube(tf.constant([1,2]))) -
# 只有经过输入签名的才能保存为Saved_Model,在这个过程中使用get_concrete_function,把tf.function标注的转换为有图建议的函数 cube_func_int32 = cube.get_concrete_function(tf.TensorSpec([None],tf.int32)) print(cube_func_int32 is cube.get_concerte_function(tf.TensorSpec([2],tf.int32)))
-
-
-
GraphDef
-
get_operations,get_operation_by_name
-
get_tensorf_by_name,as_graph_def
cube_func_int32.graph # 图 cube_func_int32.graph.get_operations() # 获取操作 cube_func_int32.graph.get_operations()[2] # 获取某一个操作 cube_func_int32.graph.get_operations()[2].xxx # 获取某一个操作中的某个属性 cube_func_int32.graph.get_operation_by_name("operationName") # 通过operation名字获取 cube_func_int32.graph.get_tensor_by_name("x:0") # 通过tensor名字获取 cube_func_int32.graph.as_graph_def() # 显示图的结构信息 # 主要用来保存图结构,模型,恢复图结构,模型
-
-
自动求导
-
普通求导方法
def f(x): return 3. * x ** 2 + 2. * x -1 def approximae_derivative(f,x,eps= 1e-3): # 求函数 f 在 x 点的导数 # x点向右eps, 向左eps 中间直线的斜率近似导数, eps足够小,导数足够接近 return (f(x+eps)-f(x-eps))/(2*eps) # print(approximae_derivative(f,1)) def g(x1,x2): return (x1 + 5)*(x2 ** 2) def approximae_gredient(g,x1,x2,eps=1e-3): dg_x1 = approximae_derivative(lambda x:g(x,x2),x1,eps) dg_x2 = approximae_derivative(lambda x:g(x1,x),x2,eps) return dg_x1,dg_x2 # print(approximae_gredient(g,2,3)) -
Tf.GrandientTape
-
x1 = tf.Variable(2.0) x2 = tf.Variable(3.0) with tf.GradientTape(persistent = True) as tape: z = g(x1,x2) dz_x1 = tape.gradient(z,x1) # 9.0 dz_x2 = tape.gradient(z,x2) # tape 只能使用一次,本次会报错 GradientTape(persistent=Ture) 表示不释放tape就可以多次使用,但使用完毕后需要手动释放那个资源 print(dz_x1,dz_x2) del tape -
with tf.GradientTape(persistent = True) as tape: # 不用persistent z = g(x1,x2) dz_x1,dz_x2 = tape.gradient(z,[x1,x2]) # 也可以这样一次求出两个 -
# 当x1,x2 为tf.constant()时,返回值为None with tf.GradientTape(persistent = True) as tape: # 这样修改即可 tape.watch(x1) tape.watch(x2) z = g(x1,x2) -
x = tf.Variable(5.0) with tf.GradientTape() as tape: z1 = 3 * x z2 = x **2 tape.gradient([z1,z2],x) # z1对于x的导数加上z2对于x的导数 -
# 二阶导数 x1 = tf.Variable(2.0) x2 = tf.Variable(3.0) with tf.GradientTape(persistent=True) as outer_tape: with tf.GradientTape(persistent=True) as inner_tape: z = g(x1,x2) inner_grads = inner_tape.gradient(z,[x1,x2]) outer_grads = [outer_tape.gradient(inner_grad,[x1,x2]) for inner_grad in inner_grads] print(outer_grads) del inner_tape del outer_tape -
# 简单梯度下降 learning_rate = 0.1 x = tf.Variable(0.0) for _ in range(100): with tf.GradientTape() as tape: z = 3. * x ** 2 + 2. * x -1 dz_dx = tape.gradient(z,x) x.assign_sub(learning_rate*dz_dx) print(x) # -0.333333
-
-
Optimizer.apply_gradients
-
# 优化梯度下降 learning_rate = 0.1 x = tf.Variable(0.0) optimizer = keras.optimizers.SGD(lr = learning_rate) for _ in range(100): with tf.GradientTape() as tape: z = 3. * x ** 2 + 2. * x -1 dz_dx = tape.gradient(z,x) optimizer.apply_gradients([(dz_dx,x)]) # 与上边不同 print(x) # -0.333333 -
def test(): metric = keras.metrics.MeanSquaredError() # 第一个形参是真实值,第二个是预测值 返回的是平均 均方误差 print(metric([5],[2])) # 9 print(metric([0],[1])) # 5 print(metric.result()) # 5 metric.reset_statues() # 不再累加 print(metric([1],[3])) # 4 -
def nn(): # fit 的内容 # 1,batch 遍历训练集 metric # 1.1,自动求导 # 2,epoch结束 验证集 metric epochs = 100 batch_size = 32 steps_per_epoch = len(x_train_scaled) // batch_size optimizer = keras.optimizers.SGD() metric = keras.metrics.MeanSquaredError() def random_batch(x,y,batch_size=32): idx = np.random.randint(0,len(x),size=batch_size) # 在0到 len(x) 中随机取batch_size个数 return x[idx],y[idx] model = keras.models.Sequential([ keras.layers.Dense(30,activation="relu",input_shape=x_train.shape[1:]), keras.layers.Dense(1), ]) for epoch in range(epochs): metric.reset_states() for step in range(steps_per_epoch): x_batch,y_batch = random_batch(x_train_scaled,y_train,batch_size) # 获取数据 with tf.GradientTape() as tape: y_pred = model(x_batch) # 计算预测 loss = tf.reduce_mean(keras.losses.mean_squared_error(y_batch,y_pred)) # 定义损失函数 metric(y_batch,y_pred) grads = tape.gradient(loss,model.variables) grads_and_vars = zip(grads,model.variables) # 每个参数对应他的梯度 optimizer.apply_gradients(grads_and_vars) # 将梯度的变化应用到变量上 print("\rEpoch",epoch,"train mse:",metric.result().numpy(),end="") y_valid_pred = model(x_valid_scaled) valid_loss = tf.reduce_mean( keras.losses.mean_squared_error(y_valid_pred,y_valid) ) print("\t","valid mse",valid_loss.numpy())
-
-
-
-
-
Tensorflow dataset使用
-
基础知识
-
Tf框架:
-
基础api
-
tf.data.Dateset.from_tensor_slics
dataset = tf.data.Dataset.from_tensor_slices((np.arange(10))) print(dataset) ## 里边的元素每一个为一组 -
repeat,batch,interleave,map,shuffle,list_files
for item in dataset.batch(2): # 还是10打个数,但此时每组2个,5组 print(item)dataset = dataset.repeat(3) # dataset 变为30个数,30组 dataset =dataset.batch(7) # 每组7个数 5组 for item in dataset: print(item)# interleave: 将dataset中的每一个数据处理后,合并返回 # case:dataset 中是一系列文件的名字,通过他,遍历名字读取内容,使用它合并 dataset2 = dataset.interleave( lambda v:tf.data.Dataset.from_tensor_slices(v), # map_fn:处理函数 cycle_length=5, # cycle_length:并行处理个数 block_length=5 # block_length: 从处理的元素中每次取多少个出来 [0,1,2,3,4,5,6] 只取[0,1,2,3,4] 最后不够的时候 从第一个中未取到的取 ) for item in dataset2: print(item)x = np.array([[1,2],[3,4],[5,6]]) y = np.array(['cat','dog','fox']) dataset3 = tf.data.Dataset.from_tensor_slices((x,y)) for item_x,item_y in dataset3: print(item_x.numpy(),item_y.numpy()) """ [1 2] b'cat' [3 4] b'dog' [5 6] b'fox' """ dataset4 = tf.data.Dataset.from_tensor_slices({'feature':x,"label":y}) for item in dataset4: print(item['feature'].numpy(),item['label'].numpy()) # 同上
-
-
csv文件,
-
生成csv
import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os,sys,time import tensorflow as tf from tensorflow import keras def showVersion(): print((tf.__version__)) print(sys.version_info) for module in mpl, np, pd, sklearn, tf, keras: print(module.__name__,module.__version__) from sklearn.datasets import fetch_california_housing housing = fetch_california_housing() from sklearn.model_selection import train_test_split (x_train_all,x_test,y_train_all,y_test) = train_test_split( housing.data,housing.target,random_state=7 ) x_train, x_valid,y_train, y_valid = train_test_split( x_train_all,y_train_all,random_state=11 ) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() x_train_scaled = scaler.fit_transform(x_train) x_valid_scaled = scaler.transform(x_valid) x_test_scaled = scaler.transform(x_test) output_dir = r"generate_csv" if not os.path.exists(output_dir): os.mkdir(output_dir) def save_to_csv(output_dir,data,name_prefix,header=None,n_parts=10): path_format = os.path.join(output_dir,"{}_{:02d}.csv") # 文件名格式:第一个表示是train还是test 第二个表示为2位的整数 filenames= [] for file_idx,row_indics in enumerate( # 将数据分为索引加数据 通过idx indics获取 np.array_split( # 将索引分为n_parts部分 [array(1,2,3,4,), array(5,6,7,8..)] np.arange(len(data)), # 生成和data一样长的数组,当索引 n_parts) # 将索引分为n_patrs ): """ file_idx row_indics 0 [0,1,2,3,4..] 1 [5,6,7,8,9..] 2 ... """ print(name_prefix,file_idx) part_csv = path_format.format(name_prefix,file_idx) filenames.append(part_csv) with open(part_csv,"wt",encoding="utf-8") as f: if header is not None: f.write(header+"\n") # 写入header for row_index in row_indics: f.write(",".join([repr(col) for col in data[row_index]])) f.write('\n') return filenames train_data = np.c_[x_train_scaled,y_train] # 将数据和标签合并 valid_data = np.c_[x_valid_scaled,y_valid] test_data = np.c_[x_test_scaled,y_test] header_cols = housing.feature_names + ['MidianHouseValue'] header_str = ','.join(header_cols) train_filenames = save_to_csv(output_dir,train_data,"train",header_str,n_parts=10) -
tf.data.TextLineDataset
-
tf.io.decode_csv
# 1. filename ---> dataset # 2. read file --> dataset -> datasets ->merge # 3, parse csv filename_dataset = tf.data.Dataset.list_files(train_filenames) n_readers =5 dataset = filename_dataset.interleave( lambda filename:tf.data.TextLineDataset(filename).skip(1), # 根据文件名按照行读取文件内容, 并跳过header cycle_length=n_readers ) for line in dataset.take(15): # 读取数据的前15行 print(line.numpy()) # 是一个整字符串 # tf.io.decode_csv(str,record_defaults) sample_str = '1,2,3,4,5' records_defaults = [tf.constant(0,dtype=tf.int32)]*5 # 要解析的类型 records_defaults = [tf.constant(0,dtype=tf.int32),0,np.nan,"hello",tf.constant([])] # 要解析的类型 parsed_fields = tf.io_csv(sample_str,records_defaults) print(parsed_fields) def parse_csv_line(line,n_fileds=9): defs = [tf.constant(np.nan)] * n_fileds parsed_fields = tf.io.decode_csv(line,record_defaults=defs) x = tf.stack(parsed_fields[0:-1]) y = tf.stack(parsed_fields[-1:]) return x,ydef csv_reader_dataset(filenames,n_readers=5, batch_size=32,n_parse_threads=5, # 解析时并行数 shuffle_buffer_size=10000): # buffer大小 dataset = tf.data.Dataset.list_files(filenames) dataset = dataset.repeat() # 重复无限次 dataset = dataset.interleave( lambda filename: tf.data.TextLineDataset(filename).skip(1), cycle_length= n_readers, ) dataset.shuffle(shuffle_buffer_size) # 混排 dataset = dataset.map(parse_csv_line,num_parallel_calls=n_parse_threads) # 将数据经过处理后返回 与interleave类似 dataset = dataset.batch(batch_size) return dataset train_set = csv_reader_dataset(train_filenames,batch_size=32) valid_set = csv_reader_dataset(train_filenames,batch_size=32) # 换位valid_filenames model = keras.models.Sequential([ keras.layers.Dense(30, activation="relu", input_shape=x_train.shape[8]), keras.layers.Dense(1) ]) model.compile(loss='mse', optimizer="adam") callbacks = [keras.callbacks.EarlyStopping(patience=5, min_delta=1e-4)] history = model.fit(train_set, epochs=100, steps_per_epoch = 1160//32, # 指定每个epoch 的次数 validation_steps =3870//32, validation_data=valid_set, callbacks=callbacks) # model.evaluate(test_set,steps = 5160//32)
-
-
tfrecord文件
-
tf.train.FloatList, tf.train.Int64List, tf.train.bytesList
# tfrecord 文件格式 # -> tf.train.Example # -> tf.train.Features ->{'key':tf.train.Feature}
->tf.train.Feature ->{tf.train.ByteList/FloatList/Int64List}
favorite_books = [name.encode("utf-8") for name in ["machine learning","cc150"]]
favorite_books_bytelist = tf.train.BytesList(value = favorite_books)
"""
value: "machine learning"
value: "cc150"
"""
hours_floatlist = tf.train.FloatList(value=[15.5,9.0,7.0,8.0])
age = tf.train.Int64List(value=[64])2. tf.train.Feature, tf.train.Features, tf.train.Example ```python features = tf.train.Features( feature = { "favorite_books":tf.train.Feature(bytes_list = favorite_books_bytelist), "hours":tf.train.Feature(float_list = hours_floatlist), "age":tf.train.Feature(int64_list = age) } ) print(features) # json格式,显示每个feature """ feature { key: "age" value { int64_list { value: 64 } } } faeture{....} """ example = tf.train.Example(features=features) # 与features 类似 featrues{feature{}...}-
exapmle.SerializeToString
serizlized_example = example.SerializeToString() # 压缩, -
tf.io.ParseSingleExample
output_dir = "tf_tfrecord_basic" if not os.path.exists(output_dir): os.mkdir(output_dir) filename = "test.tfrecords" filename_fullpath = os.path.join(output_dir,filename) # 写入文件 with tf.io.TFRecordWriter(filename_fullpath) as writer: # 打开文件 for i in range(3): # 写进去3次 writer.write(serizlized_example) # 读取 dataset = tf.data.TFRecordDataset([filename_fullpath]) for seralized_example in dataset: print(serizlized_example) # 与上边的serialized_example 类似 压缩过的 -
tf.io.VarLenFeature,tf.io.FixedLenFeature
expected_features = { "favorite_books": tf.io.VarLenFeature(dtype=tf.string), # 变长 一会解析后是sparsetensor "hours":tf.io.VarLenFeature(dtype=tf.float32), # 变长 "age":tf.io.FixedLenFeature([],dtype=tf.int64), # 定长,普通的tensor,[] 表示是0维的数,[8] 就表示8特特征 } -
tf.data.TFRecordDataset,tf.io.TFRecordOptions
dataset = tf.data.TFRecordDataset([filename_fullpath]) for serialized_example_tensor in dataset: example = tf.io.parse_single_example( serialized_example_tensor, expected_features ) books = tf.sparse.to_dense(example["favorite_books"],default_value=b"") # 解析sparsetensor 为tensor sparsetensor为0的地方 不能转为字符串 要制定default_value print(example) # 存为压缩格式 filename_fullpath_zip = filename_fullpath+ ".zip" options = tf.io.TFRecordOptions(compress_type = "GZIP") with tf.io.TFRecordWriter(filename_fullpath_zip,options) as writer: pass # 读取压缩格式 dataset = tf.data.TFRecordDataset([filename_fullpath_zip],compression_type="GZIP") # 其余不变即可
-
-
-
房价csv转record
# coding:utf-8 # file: tf_data_generate_tfrecord.py # author: Dean # contact: [email protected] # time: 2019/12/22 11:29 # desc: # coding:utf-8 # file: tf_keras_classification_model_dnn.py # author: Dean # contact: [email protected] # time: 2019/12/17 11:47 # desc: csv 文件转换为record import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os,sys,time import tensorflow as tf from tensorflow import keras source_dir = "generate_csv" def get_filenames_by_prefix(source_dir,prefix_name): # 按照文件名分类 all_files = os.listdir(source_dir) results=[] for filename in all_files: if filename.startswith(prefix_name): results.append(os.path.join(source_dir,filename)) return results train_filenames = get_filenames_by_prefix(source_dir,"train") import pprint # pprint.pprint(train_filenames) # 换行打印 def parse_csv_line(line,n_fileds=9): defs = [tf.constant(np.nan)] * n_fileds parsed_fields = tf.io.decode_csv(line,record_defaults=defs) x = tf.stack(parsed_fields[0:-1]) y = tf.stack(parsed_fields[-1:]) return x,y def csv_reader_dataset(filenames,n_readers=5, batch_size=32,n_parse_threads=5, # 解析时并行数 shuffle_buffer_size=10000): # buffer大小 dataset = tf.data.Dataset.list_files(filenames) dataset = dataset.repeat() # 重复无限次 dataset = dataset.interleave( lambda filename: tf.data.TextLineDataset(filename).skip(1), cycle_length= n_readers, ) dataset.shuffle(shuffle_buffer_size) # 混排 dataset = dataset.map(parse_csv_line,num_parallel_calls=n_parse_threads) # 将数据经过处理后返回 与interleave类似 dataset = dataset.batch(batch_size) return dataset train_set = csv_reader_dataset(train_filenames,batch_size=32) # 遍历数据写入文件 def serialize_example(x,y): """Converts x ,y to tf.train.FloatList and serialize""" input_features = tf.train.FloatList(value=x) label = tf.train.FloatList(value=y) features = tf.train.Features( feature={ "input_features":tf.train.Feature(float_list = input_features), "label":tf.train.Feature(float_list = label) } ) example = tf.train.Example(features = features) return example.SerializeToString() def csv_dataset_to_tfrecords(base_filename,dataset,n_shards,steps_per_shard,compression_type = None): """ n_shard:文件个数 steps_per_shard:每个小文件,走多少步 """ options = tf.io.TFRecordOptions(compression_type=compression_type) all_filenames=[] for shard_id in range(n_shards): filename_fullpath = '{}_{:05d}-of-{:05d}'.format( base_filename,shard_id,n_shards ) with tf.io.TFRecordWriter(filename_fullpath,options) as writer: for x_batch,y_batch in dataset.take(steps_per_shard): # 每个batch都是32个的 for x_example,y_example in zip(x_batch,y_batch): writer.write(serialize_example(x_example,y_example)) all_filenames.append(filename_fullpath) return all_filenames n_shards = 20 train_step_per_shard = 11610//32//n_shards output_dir = "generate_tfreocrds" # 先创建 train_basename = os.path.join(output_dir,"train") train_tfrecord_filename = csv_dataset_to_tfrecords( train_basename,train_set,n_shards,train_step_per_shard,None ) # 读取文件 expected_feature = { "input_ferature":tf.io.FixedLenFeature([8],dtype=tf.float32), "label":tf.io.FixedLenFeature([1],dtype=tf.float32) } def parse_example(serialized_example): example = tf.io.parse_single_example(serialize_example,expected_feature) return expected_feature["input_ferature"],expected_feature['label'] def tfrecord_reader_dataset(filenames,n_readers=5, batch_size=32,n_parse_threads=5, # 解析时并行数 shuffle_buffer_size=10000): # buffer大小 dataset = tf.data.Dataset.list_files(filenames) dataset = dataset.repeat() # 重复无限次 dataset = dataset.interleave( lambda filename: tf.data.TFRecordDataset(filename,compression_type=nONE), cycle_length= n_readers, ) dataset.shuffle(shuffle_buffer_size) # 混排 dataset = dataset.map(parse_example,num_parallel_calls=n_parse_threads) # 将数据经过处理后返回 与interleave类似 dataset = dataset.batch(batch_size) return dataset tfrecords_train = tfrecord_reader_dataset(train_tfrecord_filename, batch_size=3) for x_batch,y_batch in tfrecords_train: print(x_batch,y_batch)
-
-
-
Tensorflow Estimator使用与tf1.0
-
知识点
Tf框架:estimator使用,特征列使用,tf1.0基本使用
项目:泰坦尼克号生存
-
API
-
Tf.keras.estimator.to_estimator
-
Train,evaluate
# dataset 泰坦尼克号 # https://storage.googleapis.com/tf-datasets/titanic/train.csv # https://storage.googleapis.com/tf-datasets/titanic/eval.csv train_file = "csv/train.csv" eval_file = "csv/eval.csv" train_df = pd.read_csv(train_file) # (627,9) eval_df = pd.read_csv(eval_file) # (264.9) y_train = train_df.pop("survived") y_eval = eval_df.pop("survived") # print(train_df) # print(y_train.head()) # print(train_df.describe()) 非离散值的信息 # train_df.age.hist(bins = 20) 画出age的分布直方图 bin表示分为多少份 # train_df.sex.value_counts().plot(kind="barh") # 横向柱状图 "barv"纵向: 统计男性个数,女性个数 # train_df['class'].value_counts().plot(kind="barh") 不同舱位人数 # 男性,女性中获救比例, # pd.concat([train_df,y_train],axis=1).groupby('sex').survived.mean() # 离散值 categorical_columns = ["sex",'n_siblings_spouses','parch','class','deck','embark_town','alone'] # 连续纸 numeric_columns = ['age','fare'] feature_columns =[] for categorical_column in categorical_columns: vocab = train_df[categorical_column].unique() feature_columns.append( tf.feature_column.indicator_column( tf.feature_column.categorical_column_with_vocabulary_list( categorical_column,vocab))) for categorical_column in numeric_columns: feature_columns.append( tf.feature_column.numeric_column( categorical_column,dtype=tf.float32 ) ) # 构件dataset的函数 def make_dataset(data_df,label_df,epochs=10,shuffle=True,batch_size=32): dataset = tf.data.Dataset.from_tensor_slices( (dict(data_df),label_df) ) if shuffle: dataset =dataset.shuffle(10000) dataset = dataset.repeat(epochs).batch(batch_size) return dataset train_dataset = make_dataset(train_df,y_train,batch_size=5) # keras.layers.DenseFeature tf.keras.backend.set_floatx('float64') # for x,y in train_dataset.take(1): # age_column = feature_columns[7] # gender_column = feature_columns[0] # print(keras.layers.DenseFeatures(age_column)(x).numpy()) # 连续值不变 # print(keras.layers.DenseFeatures(gender_column)(x).numpy()) # 离散值变为one-hot # for x,y in train_dataset.take(1): # print(keras.layers.DenseFeatures(feature_columns)(x).numpy()) model = keras.models.Sequential([ keras.layers.DenseFeatures(feature_columns), keras.layers.Dense(100,activation="relu"), keras.layers.Dense(100,activation="relu"), keras.layers.Dense(2,activation="softmax") ]) model.compile(loss="sparse_categorical_crossentropy", optimizer=keras.optimizers.SGD(lr=0.01), metrics = ['accuracy']) # 1,model.fit # 2.model-->estimator ->train # 第一种 # train_dataset = make_dataset(train_df,y_train,epochs=100) # eval_dataset = make_dataset(eval_df,y_eval,epochs=1,shuffle=False) # model.fit(train_dataset, # validation_data = eval_dataset, # steps_per_epoch = 20, # validation_steps=8, # epochs=100) # 第二种 estimator = keras.estimator.model_to_estimator(model) # input_fn:函数或lambda return (feature,label) 或dataset--->(feature,label) estimator.train(input_fn = lambda :make_dataset(train_df,y_train,epochs=100)) # 会出现bug
-
-
Tf.estimator.BaselineClassifier
-
Tf.estimator.LinerClassifier
-
Tf.estimator.DNNClassifier
-
Tf.feature_column
- categorical_column_with_vocabulary_list
- numeric_column
- indicator_column
- cross_column
-
keras.layers.DenseFeatures
train_file = "csv/train.csv" eval_file = "csv/eval.csv" train_df = pd.read_csv(train_file) # (627,9) eval_df = pd.read_csv(eval_file) # (264.9) y_train = train_df.pop("survived") y_eval = eval_df.pop("survived") # 离散值 categorical_columns = ["sex",'n_siblings_spouses','parch','class','deck','embark_town','alone'] # 连续纸 numeric_columns = ['age','fare'] feature_columns =[] for categorical_column in categorical_columns: vocab = train_df[categorical_column].unique() feature_columns.append( tf.feature_column.indicator_column( tf.feature_column.categorical_column_with_vocabulary_list( categorical_column,vocab))) for categorical_column in numeric_columns: feature_columns.append( tf.feature_column.numeric_column( categorical_column,dtype=tf.float32 ) ) # 构件dataset的函数 def make_dataset(data_df,label_df,epochs=10,shuffle=True,batch_size=32): dataset = tf.data.Dataset.from_tensor_slices( (dict(data_df),label_df) ) if shuffle: dataset =dataset.shuffle(10000) dataset = dataset.repeat(epochs).batch(batch_size) return dataset # ================= # output_dir = "baseline_model" # if not os.path.exists(output_dir): # os.mkdir(output_dir) # baseline_estimator = tf.estimator.BaselineClassifier(model_dir=output_dir, # n_classes=2) # baseline_estimator.train(input_fn=lambda :make_dataset(train_df,y_train,epochs=100)) # baseline_estimator.evaluate(input_fn=lambda :make_dataset(eval_df,y_eval,epochs=1,shuffle=False,batch_size=20)) # ================= # linear_output_dir = "liner_model" # if not os.path.exists(linear_output_dir): # os.mkdir(linear_output_dir) # linear_estimator = tf.estimator.LinearClassifier( # model_dir=linear_output_dir, # n_classes=2, # feature_columns=feature_columns # ) # linear_estimator.train(input_fn=lambda :make_dataset( # train_df,y_train,epochs=100)) # ===================================== dnn_output_dir = "dnn_model" if not os.path.exists(dnn_output_dir): os.mkdir(dnn_output_dir) dnn_estimator = tf.estimator.DNNClass ifier( model_dir=dnn_output_dir, n_classes=2, feature_columns=feature_columns, hidden_units=[128,128], # 两层,都是128 activation_fn=tf.nn.relu, optimizer="Adam" ) dnn_estimator.train(input_fn= lambda :make_dataset(train_df,y_train,epochs=100)) dnn_estimator.evaluate(input_fn= lambda :make_dataset( eval_df,y_eval,epochs=1,shuffle=False))
-
-
-
卷积神经网络
-
知识点
-
Tf框架:卷积实现
卷积网络:卷积+池化---全连接 ------>分类任务
全卷积网络:去掉了最后的全连接层,变为反卷积层(是尺寸变大) ----->物体分割
-
项目:图像分类,kaggle 10monkeys,kaggle cifar10
-
理论:卷积,数据增强,迁移学习
-
卷积网问题:
- 参数太多
- 局部连接, 图像区域性
- 参数共享 图像特征与位置无关
- 池化时,剩余的数据会丢弃
- 参数太多
-
-
keras实现卷积神经网络
-
# coding:utf-8 # file: tf_keras_classification_model_cnn.py # author: Dean # contact: [email protected] # time: 2019/12/17 11:47 # desc: 深度神经网络 import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os,sys,time import tensorflow as tf from tensorflow import keras def showVersion(): print((tf.__version__)) print(sys.version_info) for module in mpl, np, pd, sklearn, tf, keras: print(module.__name__,module.__version__) # class_names = ['T-shirt','Trouser','Pullover','Dress', # 'Coat', 'Sandal', 'Shirt', 'Sneaker', # 'Bag', 'Ankle boot' # ] fashion_mnist = keras.datasets.fashion_mnist (x_train_all,y_train_all),(x_test,y_test) = fashion_mnist.load_data() x_valid, x_train = x_train_all[:5000], x_train_all[5000:] y_valid, y_train = y_train_all[:5000], y_train_all[5000:] from sklearn.preprocessing import StandardScaler scaler = StandardScaler() x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1,1)).reshape(-1,28,28,1) x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1,1)).reshape(-1,28,28,1) # 使用训练集的均值,方差 x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1,1)).reshape(-1,28,28,1) def nn(): model = keras.models.Sequential() model.add(keras.layers.Conv2D(filters=32, # 卷积核数量, kernel_size=3, # 大小 padding="same", # 是否填充是的输入输出大小一样 activation="relu", # 使用selu效果会更好 input_shape=(28,28,1) )) model.add(keras.layers.Conv2D(filters=32,kernel_size=3, padding="same", activation="relu")) model.add(keras.layers.MaxPool2D(pool_size=2)) # 一般步长与大小相同 pool 后的卷积层filter一般会翻倍 model.add(keras.layers.Conv2D(filters=64, kernel_size=3, padding="same", activation="relu")) model.add(keras.layers.Conv2D(filters=64, kernel_size=3, padding="same", activation="relu")) model.add(keras.layers.MaxPool2D(pool_size=2)) model.add(keras.layers.Conv2D(filters=128,kernel_size=3, padding="same", activation="relu")) model.add(keras.layers.Conv2D(filters=128, kernel_size=3, padding="same", activation="relu")) model.add(keras.layers.MaxPool2D(pool_size=2)) model.add(keras.layers.Flatten()) # 将输入一维化 model.add(keras.layers.Dense(128,activation="relu")) model.add(keras.layers.Dense(10,activation="softmax")) model.summary() model.compile(loss="sparse_categorical_crossentropy", optimizer = "adam", metrics = ['accuracy']) logdir = "cnn-callbacks" if not os.path.exists(logdir): os.mkdir(logdir) output_model_file = os.path.join(logdir,"fashion_mnist_model.h5") callbacks = [ keras.callbacks.TensorBoard(logdir), keras.callbacks.ModelCheckpoint(output_model_file,save_best_only = True), keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3) ] history = model.fit(x_train_scaled,y_train,epochs=10, validation_data=(x_valid_scaled,y_valid), callbacks = callbacks) model.evaluate(x_test_scaled,y_test) # 验证集验证 return history def plot_learning_curves(history): pd.DataFrame(history.history).plot(figsize=(8,5)) plt.grid(True) plt.gca().set_ylim(0,3) plt.show() if __name__ =="__main__": history = nn() plot_learning_curves(history)
-
-
keras实现深度可分离卷积
-
标准卷积
-
卷积核大小(\(D_k\))
-
卷积核输入通道数M
-
卷积核个数N,输出通道N
-
图像大小\((D_F)\)
\(D_k*D_k*M*N*D_F*D_F\)
-
深度可分离卷积
(此时的卷积核输入时原图n*n*3,卷积核为k*k*1,为了计算原图所有通道,该卷积核个数就是输入通道数M) \(D_k*D_k*1*M*D_F*D_F+1*1*M*N*D_F*D_F\)
参考:
https://blog.csdn.net/xiewenbo/article/details/84315560
https://blog.csdn.net/qq_21997625/article/details/87106152
-
# 代码同上 # 第一个Conv2D不变 # 其余的Conv2D修改为SeparableConv2D即可 # 计算量少 # 两层 3*3 视野域就是 一个5*5 # 计算量几乎缩小n倍 # 深度可分离卷积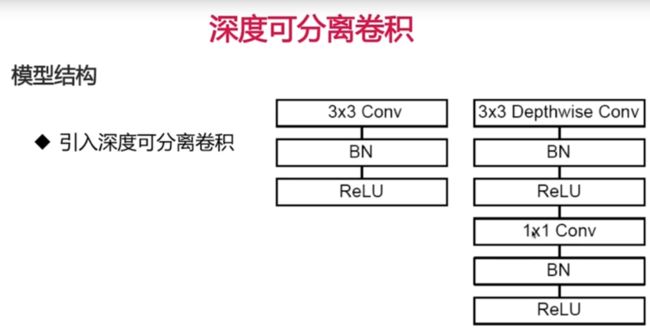
-
-
kera实战kaggle
-
10 monkey,cifar10
# coding:utf-8 # file: 1_10_monkey_model.py # author: Dean # contact: [email protected] # time: 2019/12/23 11:30 # desc: keras_generator 搭建模型 # model.fit 将数据放入内存训练 # model.fit_generator 处理大数据, 使用生成器的数据集 import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os,sys,time import tensorflow as tf from tensorflow import keras train_dir=r"I:\人工智能数据\10_monkey\training\training" valid_dir=r"I:\人工智能数据\10_monkey\validation\validation" label_txt=r"I:\人工智能数据\10_monkey\monkey_labels.txt" labels = pd.read_csv(label_txt,header=0) height = 128 # 缩放大小 width = 128 channels = 3 batch_size = 64 num_classes = 10 # keras中的数据集:读取数据,数据分享 train_datagen = keras.preprocessing.image.ImageDataGenerator( rescale = 1./255, # 像素点缩放到0-1 rotation_range = 40, # 图片增强方式,随机旋转40 width_shift_range = 0.2, # 偏移 height_shift_range = 0.2, # shear_range = 0.2, # 剪切强度 zoom_range = 0.2, # 缩放程度 horizontal_flip = True, # 水平翻转 fill_mode = "nearest", # 放大时填充像素,选择最近的填充 ) # 读取图片,按照上边方法进行处理 train_generator = train_datagen.flow_from_directory(train_dir, target_size=(height,width), batch_size=batch_size, seed=7, # 随机数 shuffle=True, class_mode="categorical") # label格式 one-hot valid_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1./255) valid_generator = valid_datagen.flow_from_directory(valid_dir, target_size=(height,width), batch_size=batch_size, seed=7, shuffle=False, # 不用训练不用打乱 class_mode="categorical") train_num = train_generator.samples valid_num = valid_generator.samples # print(train_num,valid_num) # 1098 272 # x,y = train_generator.next() # (64,128,128,3) (64,10) model = keras.models.Sequential([ keras.layers.Conv2D(filters=32,kernel_size=3,padding="same", activation="relu",input_shape=(width,height,channels)), keras.layers.Conv2D(filters=32,kernel_size=3,padding="same", activation="relu"), keras.layers.MaxPool2D(pool_size=2), keras.layers.Conv2D(filters=64,kernel_size=3,padding="same", activation="relu"), keras.layers.Conv2D(filters=64,kernel_size=3,padding="same", activation="relu"), keras.layers.MaxPool2D(pool_size=2), keras.layers.Conv2D(filters=128,kernel_size=3,padding="same", activation="relu"), keras.layers.Conv2D(filters=128,kernel_size=3,padding="same", activation="relu"), keras.layers.MaxPool2D(pool_size=2), keras.layers.Flatten(), keras.layers.Dense(128,activation="relu"), keras.layers.Dense(num_classes,activation="softmax") ]) model.compile(loss="categorical_crossentropy", optimizer="adam",metrics=['accuracy']) model.summary() epochs = 300 # 最后acc 97% 98% history = model.fit_generator(train_generator, steps_per_epoch= train_num//batch_size, epochs = epochs, validation_data=valid_generator, validation_steps= valid_num//batch_size) # history.history.keys() # loss,acc, val_loss,val_acc def plot_learning_curves(history,label,epochs,min_value,max_value): data={} data[label] = history.history[label] data["val_"+label]=history.history["val_"+label] pd.DataFrame(data).plot(figsize=(8.5)) plt.grid(True) plt.axis([0,epochs,min_value,max_value]) plt.show() plot_learning_curves(history,"acc",epochs,0,1) plot_learning_curves(history,"loss",epochs,1.5,2.5) -
数据增强(调整数据 提高准确率)与迁移学习
-
# model 部分修改即可 resnet50_fine_tune = keras.models.Sequential(); resnet50_fine_tune.add(keras.applications.ResNet50(include_top=False, # 不包含最后一层 pooling = 'avg', weights="imagenet")) # None 从头开始,imagenet接着 resnet50_fine_tune.add(keras.layers.Dense(num_classes,activation="softmax")) resnet50_fine_tune.layers[0].trainable= False # 设置第一层的参数不调整 """ resnet50 = keras.applications.ResNet50(include_top=False, pooling="avg", weights="imagenet") resnet50.summary() for layer in resnet50.layers[0:-5]: # 设置resnet50中后0--5层也不可训练,其余可训练 layer.trainable=False resnet50_new = keras.models.Sequential([ resnet50, keras.layers.Dense(num_classes,activation="softmax"), ]) """# coding:utf-8 # file: 1_cifar10_model.py # author: Dean # contact: [email protected] # time: 2019/12/23 11:30 # desc: import matplotlib as mpl import matplotlib.pyplot as plt import numpy as np import sklearn import pandas as pd import os,sys,time import tensorflow as tf from tensorflow import keras # data https://www.kaggle.com/c/cifar-10/data class_names = [ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck' ] train_lables_file = r'I:\人工智能数据\cifar10\trainLabels.csv' test_csv_file = r'I:\人工智能数据\cifar10\sampleSubmission.csv' train_folder = r'I:\人工智能数据\cifar10\train' test_floder = r'I:\人工智能数据\cifar10\test' def parse_csv_file(filepath,folder): """Paeses csv files into (filename(path),label) format (xxx.png,'cat')""" results =[] with open(filepath,"r") as f: lines = f.readlines()[1:] # 去掉header for line in lines: image_id,label_str = line.strip("\n").split(',') image_full_path = os.path.join(folder,image_id+".png") results.append((image_full_path,label_str)) return results train_lables_info = parse_csv_file(train_lables_file,train_folder) # 50000 test_csv_info = parse_csv_file(test_csv_file,test_floder) # 300000 # 制作dataframe # train_df = pd.DataFrame(train_lables_info) train_df = pd.DataFrame(train_lables_info[0:45000]) valid_df = pd.DataFrame(train_lables_info[45000:]) test_df = pd.DataFrame(test_csv_info) # 设置dataframe的列名 train_df.columns = ["filepath",'class'] valid_df.columns = ["filepath",'class'] test_df.columns = ["filepath",'class'] height = 32 # 缩放大小 width = 32 channels = 3 batch_size = 32 num_classes = 10 # keras中的数据集:读取数据,数据分享 train_datagen = keras.preprocessing.image.ImageDataGenerator( rescale = 1./255, # 像素点缩放到0-1 rotation_range = 40, # 图片增强方式,随机旋转40 width_shift_range = 0.2, # 偏移 height_shift_range = 0.2, # shear_range = 0.2, # 剪切强度 zoom_range = 0.2, # 缩放程度 horizontal_flip = True, # 水平翻转 fill_mode = "nearest", # 放大时填充像素,选择最近的填充 ) # 读取图片,按照上边方法进行处理 train_generator = train_datagen.flow_from_dataframe( train_df, directory="./", x_col="filepath", y_col="class", classes=class_names, target_size=(height, width), batch_size=batch_size, seed=7, shuffle=True, class_mode="sparse" ) valid_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1./255) valid_generator = valid_datagen.flow_from_dataframe(valid_df, directory="./", x_col="filepath", y_col="class", classes=class_names, target_size=(height,width), batch_size=batch_size, seed=7, shuffle=False, class_mode="sparse") train_num = train_generator.samples valid_num = valid_generator.samples # print(train_num,valid_num) # 1098 272 # x,y = train_generator.next() # (64,128,128,3) (64,10) model = keras.models.Sequential([ keras.layers.Conv2D(filters=128,kernel_size=3,padding="same", activation="relu",input_shape=(width,height,channels)), keras.layers.BatchNormalization(), keras.layers.Conv2D(filters=128,kernel_size=3,padding="same", activation="relu"), keras.layers.BatchNormalization(), keras.layers.MaxPool2D(pool_size=2), keras.layers.Conv2D(filters=256,kernel_size=3,padding="same", activation="relu"), keras.layers.BatchNormalization(), keras.layers.Conv2D(filters=256,kernel_size=3,padding="same", activation="relu"), keras.layers.BatchNormalization(), keras.layers.MaxPool2D(pool_size=2), keras.layers.Conv2D(filters=512,kernel_size=3,padding="same", activation="relu"), keras.layers.BatchNormalization(), keras.layers.Conv2D(filters=512,kernel_size=3,padding="same", activation="relu"), keras.layers.BatchNormalization(), keras.layers.MaxPool2D(pool_size=2), keras.layers.Flatten(), keras.layers.Dense(512,activation="relu"), keras.layers.Dense(num_classes,activation="softmax") ]) model.compile(loss="sparse_categorical_crossentropy", optimizer="adam",metrics=['accuracy']) model.summary() epochs = 1 history = model.fit_generator(train_generator, steps_per_epoch= train_num//batch_size, epochs = epochs, validation_data=valid_generator, validation_steps= valid_num//batch_size) def plot_learning_curves(history,label,epochs,min_value,max_value): data={} data[label] = history.history[label] data["val_"+label]=history.history["val_"+label] pd.DataFrame(data).plot(figsize=(8.5)) plt.grid(True) plt.axis([0,epochs,min_value,max_value]) plt.show() plot_learning_curves(history,"acc",epochs,0,1) plot_learning_curves(history,"loss",epochs,0,2)
-
-
-
-
循环神经网络
- Tf框架:LSTM实现
- 项目:文本分类,文本生成,Kaggle文本分类
- 理论:序列式问题,循环网络,LSTM,双向LSTM
-
Tensorflow分布式
-
理论部分
- GPU设置
- 默认用全部GPU并占满内存
- 如何不浪费内存和计算资源
- 内存增长
- 虚拟设备机制
- 多GPU
- 虚拟GPU&实际GPU
- 手工设置&分布式机制
- API
- tfdebugging.set_log_device_placement
- tf.config.experimental.set_visible_devices 设置可见设备
- tf.config.experimental.list_logical_devices 获取逻辑设备
- tf.config.experimental.list_physical_devices 获取物理设备
- tf.config.experimental.set_memory——growth 设置内存自增
- tf.config.experimental.VirtualDeviceConfiguration 建立逻辑设备
- tf.config.set_soft_device_placement 自动分配任务到设备
- 分布式策略
- GPU设置
-
实战部分
- GPU设置部分
- 分布式训练
-
-
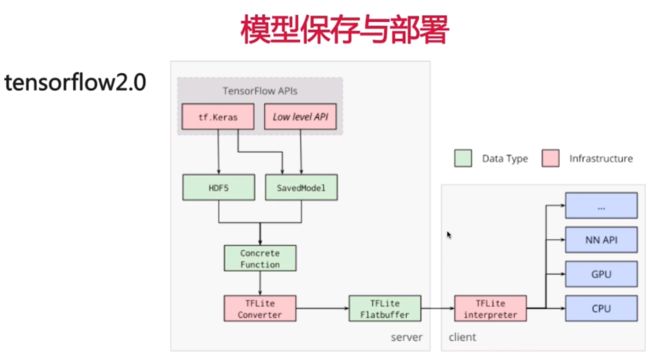
Tensorflow模型保存于部署
-
Tf框架:模型保存,导出tflite,部署
-
项目:图像分类

-
模型保存
-
文件格式
- Ckeckpoint与graphdef (tf1.0)
- keras(hdf5),SavedModel(tf2.0)(参数+网络结构)
-
保存的是什么
- 参数
- 参数+网络结构
-
TFLite
- TFLite Converter
- 模型转化 将上边的三种模型转化为tflite
- TFLite Interpreter
- 模型加载
- 支持android与ios
- 支持多种语言
- TFLite-FlatBuffer
- google开源的跨平台数据序列化库
- 优点
- 直接读取序列化数据
- 高效内存使用和速度
- 灵活,数据前后向兼容,灵活控制数据结构
- 代码少
- 强类型数据
- TFlite-量化
- 参数从float变为8bit整数
- 准确率损失
- 模型大小变为1/4
- 量化方法
- float=(int-归零点)*因子
- 参数从float变为8bit整数
- TFLite Converter
-
案例

-
keras-保存参数与保存模型+参数
keras.callbacks.ModelCheckpoint(out_put_dir, save_best_only=True, save_weights_only=False) # 为false表示只保存参数,True表示都保存 keras.models.load_model(out_put_dir) # 若都保存了,从新加载后和可直接使用# 定义模型之后,导入weights 可使用# 也可保存权重 model.save_weights("xxxx/xxx.h5")tf.saved_model.save(model,".../xxx_garph") # assets # variables checkpoint 信息 # saved_model.pb# 命令行工具查看model信息 !saved_model_cli show --dir "path" --all # 载入model model = tf.saved_model.load("path") inference = model.signatures["serving_default"] results = inference(tf.constant(x_test_scaled[0:1])) -
keras签名函数保存到SavedModel
tf_export =tf.Model() tf_export.cube = 签名函数 tf.saved_model.save(tf._export,dir) -
keras,SavedModel,签名函数到具体函数
load_saved_model=keras.models.load_model(".../...h5") load_saved_model(np.zeros([1,28,28])) run_model = tf.function(lambda x:load_saved_model(x)) keras_concrete_function = run_model.get_concrete_function( tf.TensorSpec( load_keras_model.inputs[0].shape, load_keras_model.inputs[0].dtype )) # 测试 keras_concrete_function(tf.constant(np.zeros(1,28,28,dtype=np.float32))) -
keras,SavedModel,具体函数到tflite
-
tflite量化
-
tensorflow js.android部署
-
-
-
-
机器翻译于tensorflow2tensor使用
- Tf框架:transformer实现,tensor2tensor使用
- 项目:机器翻译
- 理论:序列道序列模型.注意力机制,可缩放点积注意力,多头注意力