CVPR 2021 | Coordinate Attention for Efficient Mobile Network Design注意力机制再下一城(Keras实现)

Coordinate Attention for Efficient Mobile Network Design
paper:https://arxiv.org/pdf/2103.02907.pdf
code:https://github.com/Andrew-Qibin/CoordAttention
摘要
通过将位置信息嵌入到信道注意中的移动网络注意机制,与SE通过二维全局池将特征张量转换为单一特征向量的通道注意不同,坐标注意将信道注意分解为两个一维特征编码过程,分别沿着两个空间方向(X、Y方向)聚合特征。这样,可以沿一个空间方向捕获长距离的依赖关系,同时可以沿另一个空间方向保持精确的位置信息。然后,得到的特征图被单独编码成一对方向感知和位置敏感的注意图,可以互补地应用到输入特征图上,以增强感兴趣对象的表示。该注意力机制很简单,可以灵活地插入经典的轻量级网络,如MobileNetV2、MobileNeXt和效率网络,而几乎没有计算开销。对于图像分类、目标检测和语义分割都很友好。
论文主要思想
分别沿X方向和Y方向使用注意力机制,一方面能够获取沿一个空间方向的长期依赖关系,又能够保存精确的位置信息,帮助网络更准确地定位感兴趣的对象。并且它能够有效地获取通道间的关系。
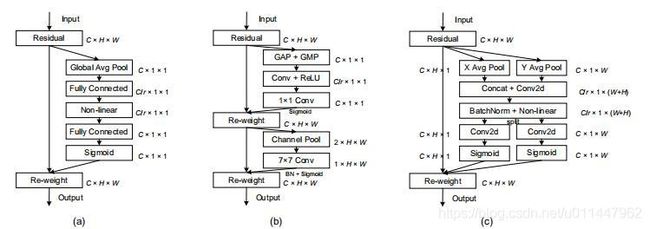
Keras实现
以下是根据论文和pytorch源码实现的keras版本(支持Tensorflow1.x)。特征通道必须channel last
def _CA(inputs, name, ratio=8):
w, h, out_dim = [int(x) for x in inputs.shape[1:]]
temp_dim = max(int(out_dim // ratio), ratio)
h_pool = Lambda(lambda x: tf.reduce_mean(x, axis=1))(inputs)
w_pool = Lambda(lambda x: tf.reduce_mean(x, axis=2))(inputs)
x = Concatenate(axis=1)([h_pool, w_pool])
x = Reshape((1, w + h, out_dim), name=name + '_Reshape')(x)
x = Conv2D(temp_dim, 1)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x_h, x_w = Lambda(lambda x: tf.split(x, [h, w], axis=2))(x)
x_w = Reshape((w, 1, temp_dim))(x_w)
x_w = Conv2D(out_dim, 1, activation='sigmoid')(x_w)
x_h = Conv2D(out_dim, 1, activation='sigmoid')(x_h)
x = Multiply()([inputs, x_h, x_w])
return x根据论文修改的3D Coordinate Attention,仅供大家参考:
def _CA(inputs, name, ratio=8):
w, h, d, out_dim = [int(x) for x in inputs.shape[1:]]
temp_dim = max(int(out_dim // ratio), ratio)
h_pool = Lambda(lambda x: tf.reduce_mean(x, axis=[1, 3]))(inputs)
w_pool = Lambda(lambda x: tf.reduce_mean(x, axis=[2, 3]))(inputs)
d_pool = Lambda(lambda x: tf.reduce_mean(x, axis=[1, 2]))(inputs)
x = Concatenate(axis=1)([w_pool, h_pool, d_pool])
x = Reshape((1, 1, w + h + d, out_dim), name=name + '_Reshape')(x)
x = Conv3D(temp_dim, 1)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x_w, x_h, x_d = Lambda(lambda x: tf.split(x, [w, h, d], axis=3))(x)
x_w = Reshape((w, 1, 1, temp_dim))(x_w)
x_d = Reshape((1, 1, d, temp_dim))(x_d)
x_h = Reshape((1, h, 1, temp_dim))(x_h)
x_w = Conv3D(out_dim, 1, activation='sigmoid')(x_w)
x_h = Conv3D(out_dim, 1, activation='sigmoid')(x_h)
x_d = Conv3D(out_dim, 1, activation='sigmoid')(x_d)
x = Multiply()([inputs, x_w, x_h, x_d])
return x声明:本内容来源网络,版权属于原作者,图片来源原论文。如有侵权,联系删除。
创作不易,欢迎大家点赞评论收藏关注!(想看更多最新的注意力机制文献欢迎关注浏览我的博客)