12.PyTorch深度学习实践——循环神经网络(基础)
循环神经网(RNN)络被大量运用于NLP领域,但是实际上,只要是时序信号比如轴承振动信号等交由RNN处理都有不错的效果。本节就来熟悉RNN的使用。

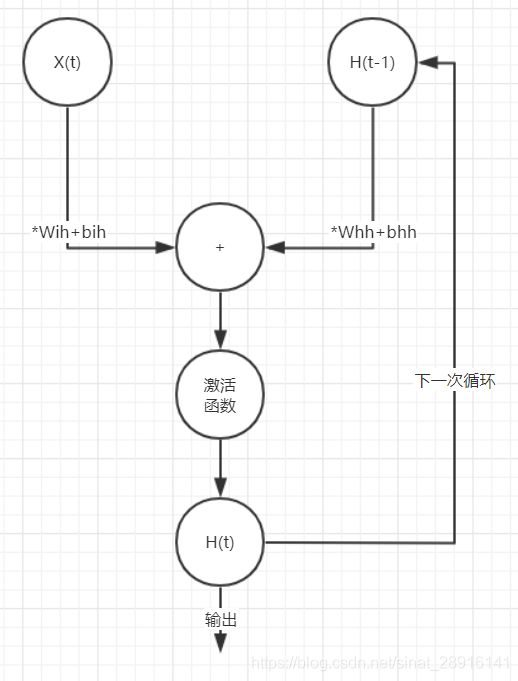
如上图所示,RNN由同一循环单元重复运算构成,它的参数会随着每次运算改变。单个循环单元解释如下:
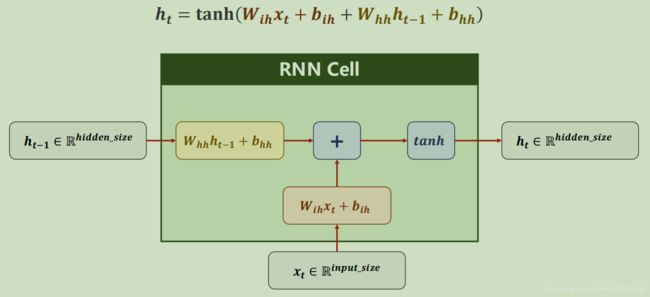
从这里可以看到,循环单元本质就是一个线性层,它通过将输入x线性变换成和隐层h维度相同而进行运算,所以通过输入x维度和隐层h维度即可确认循环单元,可得公式如下:
![]()
这里即是构造了一个循环单元,只需将循环单元循环使用即可构造RNN网络。画成网络的形式大概如下所示:
使用RNN Cell构造网络
在构造之前我们需要数据维度,网络运输就是一个维度变换的过程,写代码的过程中构造网络不麻烦,提前计算数据所需维度才麻烦。
我们需要用到以下参数:
• ℎ = 1 # batch尺寸
• = 3 # 时间序列长度(注意不是输入维度)
• = 4 # 输入维度
• ℎ = 2 # 输出维度
由此来构造维度
• . ℎ = (ℎ, )
• . ℎ = (ℎ, ℎ)
• . ℎ = (, ,)
上代码
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
# (seq, batch, features)
dataset = torch.randn(seq_len, batch_size, input_size)
#初始化h0
hidden = torch.zeros(batch_size, hidden_size)
for idx, input in enumerate(dataset):
print('=' * 20, idx, '=' * 20)
print('Input size: ', input.shape)
hidden = cell(input, hidden)
print('outputs size: ', hidden.shape)
print(hidden)
使用RNN构造网络
实际使用中更常使用的是RNN,它比RNN Cell更加的方便,会自动构建循环,并且可以指定网络层数。
接下来使用RNN构造网络,依然是先确定维度。

需要用到:
- batchSize # batch尺寸
- seqLen # 时间序列长度(注意不是输入维度)
- inputSize, hiddenSize, # 输入维度,输出维度(隐层即是单个神经元输出)
- numLayers # (层数)
由此可确定数据维度:
- . ℎ = (, ℎ, e)
- ℎ_0. ℎ = (, ℎ, ℎe)
- . ℎ = (, , e)
- ℎ_. ℎ = (, , e)
网络形状:
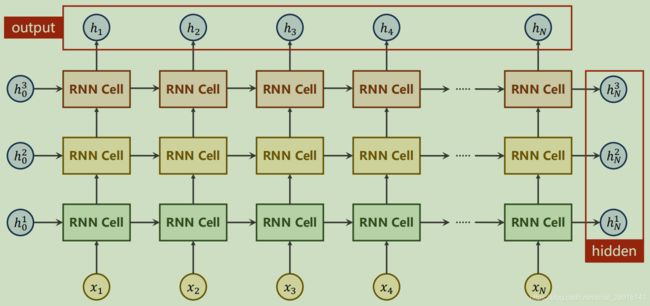
上代码:
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers)
# (seqLen, batchSize, inputSize)
inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
# 使用RNN免去了循环的编写
out, hidden = cell(inputs, hidden)
print('Output size:', out.shape)
print('Output:', out)
print('Hidden size: ', hidden.shape)
print('Hidden: ', hidden)
实例
举一个石粒
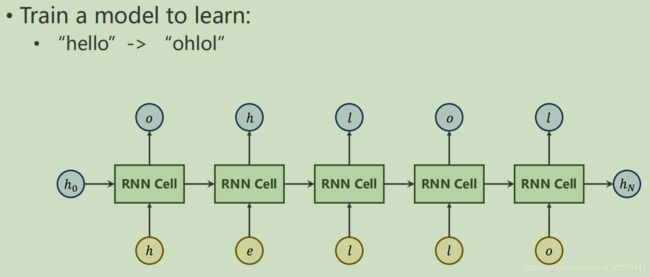
一般会把单词映射为向量,常用的是One-Hot Vectors(独热向量,即独热编码)
独热码,在英文文献中称做 one-hot code, 直观来说就是有多少个状态就有多少比特,而且只有一个比特为1,其他全为0的一种码制。
输入
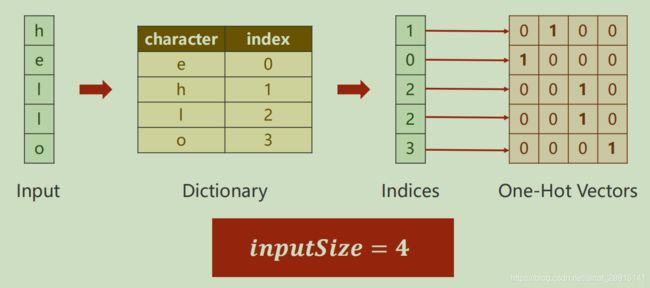
输出
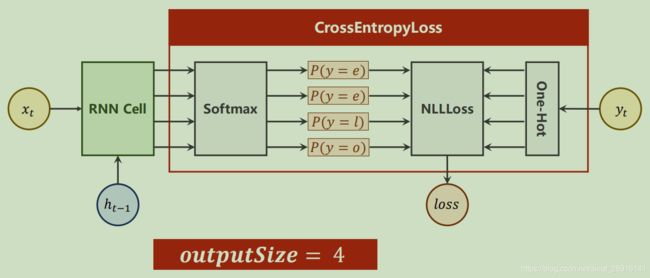
上代码(RNN Cell版):
import torch
input_size = 4
hidden_size = 4
# 每个batch样本数量
batch_size = 1
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
# 每个batch(batch_size, input_size)
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)
labels = torch.LongTensor(y_data).view(-1, 1)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size,
hidden_size=self.hidden_size)
# 网络一个来回执行多次forward
def forward(self, input, hidden):
hidden = self.rnncell(input, hidden)
return hidden
# 初始化h_0写在类外也可
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
# epoch = batch_size * iterations
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden()
print('Predicted string: ', end='')
for input, label in zip(inputs, labels):
hidden = net(input, hidden)
loss += criterion(hidden, label)
#dim按括号从外向内分别为0,1,2
_, idx = hidden.max(dim=1)
print(idx2char[idx.item()], end='')
loss.backward()
optimizer.step()
print(', Epoch [%d/15] loss=%.4f' % (epoch+1, loss.item()))
上代码(RNN版):
import torch
input_size = 4
hidden_size = 4
num_layers = 1
batch_size = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1):
super(Model, self).__init__()
self.num_layers = num_layers
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnn = torch.nn.RNN(input_size=self.input_size,
hidden_size=self.hidden_size,
num_layers=num_layers)
# 网络一个来回执行一次forward
def forward(self, input):
hidden = torch.zeros(self.num_layers,
self.batch_size,
self.hidden_size)
out, _ = self.rnn(input, hidden)
return out.view(-1, self.hidden_size)
net = Model(input_size, hidden_size, batch_size, num_layers)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='')
print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))
关于编码
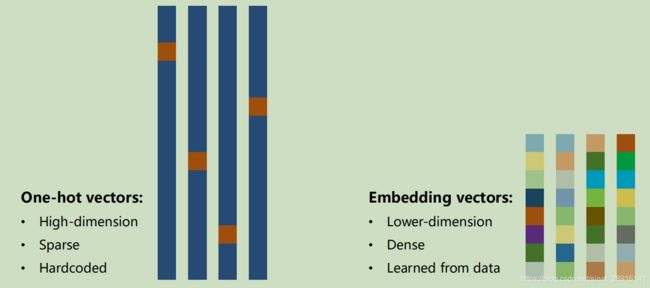
上面我们都是使用独热码进行编码,但是独热码有很大的缺点。
它是高维,稀疏,硬编码。
可以想象,当编码对象是字典或电商ID时,编码长度甚至会达到千万级,这会对训练造成很大的挑战。所以还有种更好的替代方式即embedding。
embedding的特点为低维,稠密,自学习。这就代表了首先它运算友好,其次相近数据间有数学联系(例如:美国 - 华盛顿 = 越南 - 河内)。
两种编码对比:
下面使用如下模型进行训练:
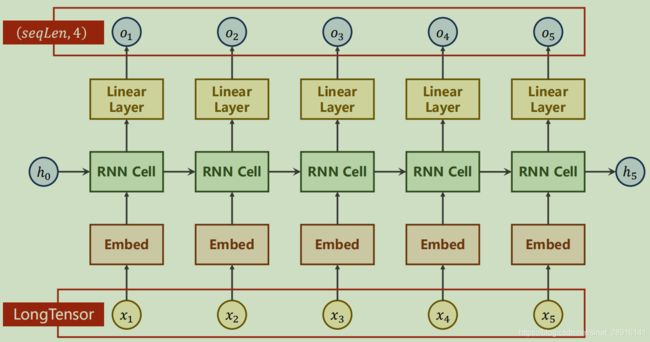
上代码:
import torch
num_class = 4
input_size = 4
hidden_size = 8
embedding_size = 10
num_layers = 2
batch_size = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]] # (batch, seq_len)
y_data = [3, 1, 2, 3, 2] # (batch * seq_len)
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.emb(x) # (batch, seqLen, embeddingSize)
x, _ = self.rnn(x, hidden)
x = self.fc(x)
return x.view(-1, num_class)
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='')
print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))
结果表明引入embedding确实加快了训练速度。
以上学习了RNN模型基础,但是目前更好的模型有LSTM和GRU,它们效果都比RNN好,由于本篇长度已经过长为了您的肠胃和视力考虑将会把代码单独一篇列出。