YOLOX部署实战 | 重写TensorRT版本(代码开源)
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
公众号后台回复关键字【YOLOX】获取本文代码链接
前言
YOLOX是前段时间旷视开源的一个目标检测算法,据说效果很好,这两天有空了就准备研究一下,看了论文感觉里面干货还是很多的,等后面再仔细研究研究。从论文放出的结果来看,YOLOX在速度和精度上应该是全面超过了之前的YOLO系列算法的。

比较良心的是,作者不仅开源了代码和模型,还放出了TensorRT、OpenVINO、NCNN等框架下的模型部署示例代码,可谓是工程人的福音。
看了TensorRT版本的C++部署示例代码,决定自己重新写一下,就当练手了。
实现过程
这里主要记录需要注意的事项和与官方示例代码不一样的地方。
1. 下载ONNX模型
ONNX模型可以从下面的链接页面中下载:
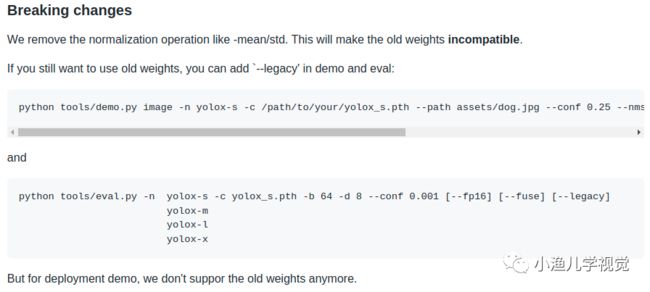
https://github.com/Megvii-BaseDetection/YOLOX/releases/需要注意的是,我们需要下载0.1.1pre版本的权重,最新的代码中作者已经修改了图像预处理的方式,这会导致之前版本的ONNX模型权重与最新的代码不兼容,这是作者的说明:
2. TensorRT解析ONNX模型
YOLOX官方提供的TensorRT版本示例代码是先通过tools/trt.py脚本把ONNX模型解析再后序列化到model_trt.engine文件中,然后C++代码再从该文件中加载模型去进行推理。这里我们可以直接在C++代码中去解析ONNX模型,然后把它序列化到.engine文件中,TensorRT解析ONNX模型的方法可以参考英伟达官方提供的sampleOnnxMNIST例程。
if (!isFileExists(engine_path)) {
std::cout << "The engine file " << engine_path
<< " has not been generated, try to generate..." << std::endl;
engine_ = SerializeToEngineFile(model_path_, engine_path);
std::cout << "Succeed to generate engine file: " << engine_path
<< std::endl;
} else {
std::cout << "Use the exists engine file: " << engine_path << std::endl;
engine_ = LoadFromEngineFile(engine_path);
}这里首先判断ONNX模型对应的.engine文件是否存在,如果存在就直接从.engine文件中加载模型,否则就创建一个ONNX模型解析器去解析模型,然后把模型序列化到.engine文件中方便下次使用。
//把模型序列化到engine文件中
nvinfer1::IHostMemory *trtModelStream = engine->serialize();
std::stringstream gieModelStream;
gieModelStream.seekg(0, gieModelStream.beg);
gieModelStream.write(static_cast(trtModelStream->data()),
trtModelStream->size());
std::ofstream outFile;
outFile.open(engine_path);
outFile << gieModelStream.rdbuf();
outFile.close(); 3. 自动获取模型输入尺寸
官方示例代码中,默认模型的输入尺寸是640x640
static const int INPUT_W = 640;
static const int INPUT_H = 640;但是如果模型的输入尺寸是416x416或者是长宽不等的512x416这种尺寸,那么就还需要改代码,感觉不是很方便。其实模型的输入输出维度都可以通过TensorRT提供的接口获取,这样就方便根据模型解析的结果自动获取输入尺寸,然后根据这个信息去对输入图像做resize了。
nvinfer1::Dims input_dim = engine_->getBindingDimensions(index);
int input_size = 1;
for (int j = 0; j < input_dim.nbDims; ++j) {
input_size *= input_dim.d[j];
}上面的代码中,input_dim.d为模型的输入尺寸,按照NCHW的顺序排列。
4. 图像预处理
官方示例代码中,预处理的时候是对图像做长宽等比例缩放,不足的地方再进行填充:
cv::Mat static_resize(cv::Mat& img) {
float r = std::min(INPUT_W / (img.cols*1.0), INPUT_H / (img.rows*1.0));
int unpad_w = r * img.cols;
int unpad_h = r * img.rows;
cv::Mat re(unpad_h, unpad_w, CV_8UC3);
cv::resize(img, re, re.size());
cv::Mat out(INPUT_H, INPUT_W, CV_8UC3, cv::Scalar(114, 114, 114));
re.copyTo(out(cv::Rect(0, 0, re.cols, re.rows)));
return out;
}我就直接简单粗暴地resize了(不要学我):
cv::Mat resize_image;
cv::resize(input_image, resize_image, cv::Size(model_width_, model_height_));两种方法的对比:


5. 后处理
后处理是对模型推理的结果进行解析,YOLOX是anchor-free的目标检测算法,解析的时候相对要简单一些。与YOLOv3类似,YOLOX还是在3个尺度上去做检测,每一层特征图上的单元格只预测一个框,每个单元格输出的内容是x,y,w,h,objectness这5个内容再加上每个类别的概率。可以用Netron看一下模型后面几层的结构:

可以看到,如果模型输入尺寸为640x640,分别降采样8,16,32倍后得到的特征图尺寸分别为80x80,40x40,20x20,COCO数据集有80个类别那么每个特征图的单元格输出的数据长度为5+80=85,3个特征图上的结果最终会concat到一起进行输出,所以最终输出的数据维度为(80x80+40x40+20x20)x85=8400x85。
官方示例代码中用了好几个函数做后处理,感觉有点繁琐,于是我重写了这部分的代码:
const std::vector strides = {8, 16, 32};
float *ptr = const_cast(output);
for (std::size_t i = 0; i < strides.size(); ++i) {
const int stride = strides.at(i);
const int grid_width = model_width_ / stride;
const int grid_height = model_height_ / stride;
const int grid_size = grid_width * grid_height;
for (int j = 0; j < grid_size; ++j) {
const int row = j / grid_width;
const int col = j % grid_width;
const int base_pos = j * (kNumClasses + 5);
const int class_pos = base_pos + 5;
const float objectness = ptr[base_pos + 4];
const int label =
std::max_element(ptr + class_pos, ptr + class_pos + kNumClasses) -
(ptr + class_pos);
const float confidence = (*(ptr + class_pos + label)) * objectness;
if (confidence > confidence_thresh) {
const float x = (ptr[base_pos + 0] + col) * stride / width_scale;
const float y = (ptr[base_pos + 1] + row) * stride / height_scale;
const float w = std::exp(ptr[base_pos + 2]) * stride / width_scale;
const float h = std::exp(ptr[base_pos + 3]) * stride / height_scale;
Object obj;
obj.box.x = x - w * 0.5f;
obj.box.y = y - h * 0.5f;
obj.box.width = w;
obj.box.height = h;
obj.label = label;
obj.confidence = confidence;
objs->push_back(std::move(obj));
}
}
ptr += grid_size * (kNumClasses + 5);
} 这里有个小技巧:没有必要每个单元格都先去解析出x,y,w,h后再去看置信度是否大于阈值,而应该先判断置信度,如果置信度大于阈值再去解析x,y,w,h。这样做还是可以减少很多计算量的(在嵌入式平台上还是能省则省吧),毕竟一般几千个单元格的结果可能只有几十个是符合条件的。
最后我用Soft-NMS算法(不知道我写的对不对)做非极大值抑制去除重复的框。
结果
用yolox_s.onnx模型测试的几个结果:



在GeForce RTX 2080显卡上测试的的各个模型的耗时如下表所示(不是很精确):
| 模型 | 输入尺寸 | 耗时 |
|---|---|---|
| yolox_darknet.onnx | 640x640 | 22 ms |
| yolox_l.onnx | 640x640 | 21 ms |
| yolox_m.onnx | 640x640 | 11 ms |
| yolox_s.onnx | 640x640 | 7 ms |
| yolox_tiny.onnx | 416x416 | 3 ms |
| yolox_nano.onnx | 416x416 | 2 ms |
针对上一节中的第3点,我试了不管模型输入尺寸是640x640,416x416还是512x416都是可以的,程序会做自适应处理。
总结
一句话:YOLOX又快又好!
后台回复【模型部署】获取模型部署交流群二维码!
往期回顾
手把手教学!TensorRT部署实战:YOLOv5的ONNX模型部署

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
