NLP实践——Bert转onnx格式简介与踩坑记录
NLP实践——Bert转onnx格式简介与踩坑记录
- 1. transformers与onnx
- 2. 导出onnx模型
- 3. 载入onnx模型
- 4. 踩坑记录
- 5. 实验结果
本文是一篇实验性的记录,主要记录了近期对transformer模型转化onnx研究时,格式转化的过程,以及其中遇到的问题。由于并没有深入的调研,本文的所有结论还请选择性参考。
1. transformers与onnx
关于onnx,pytorch官方的说明文档介绍的例子都是CV的模型转到onnx格式,而nlp与cv的区别不大,主要是注意一下不输入序列定长的问题,也就是export方法中的dynamic_axes参数。
这里我主要参考了这个项目:
https://github.com/ChainYo/transformers-pipeline-onnx
这个项目是将transformers模块中的pipeline转为onnx格式使用的,预置一些模型配置,例如基本的序列分类,命名实体识别,seq2seq等任务,但是对于其中没有包含的模型结构,就需要自己去写了。于是我仿照其写法,尝试着转换自己的模型,按照该项目的思路,只把模型中的bert(或者其他别的transformer-based模型)部分转成了onnx格式,下游任务还是放在pytorch处理,我感觉这样做是比较合理的,毕竟整个模型的主要参数都集中在transformer中。
所以在接下来的介绍中,我也按照这样的思路去转换,即从模型中拿出主体encoder部分,用onnx的session.run替换掉原来的self.bert(*inputs)。
2. 导出onnx模型
其实整个导出就是一个export函数,是torch中自带的,其签名如下:
export(
model,
args,
f,
export_params=True,
verbose=False,
training=,
input_names=None,
output_names=None,
aten=False,
export_raw_ir=False,
operator_export_type=None,
opset_version=None,
_retain_param_name=True,
do_constant_folding=True,
example_outputs=None,
strip_doc_string=True,
dynamic_axes=None,
keep_initializers_as_inputs=None,
custom_opsets=None,
enable_onnx_checker=True,
use_external_data_format=False)
参数比较多比较复杂,在这里不做详细的介绍。
我们需要做的就是填充这些参数,具体怎么做,就直接参考前文中所提到的开源项目了。
pytorch版本不同可能会有所差别,我采用的是torch1.8 + transformers4.17.
参考该开源项目,找到导出部分的核心代码:
torch.onnx.export(
model,
(dummy_inputs,),
f=output_onnx_path,
input_names=list(onnx_config.inputs.keys()),
output_names=list(onnx_config.outputs.keys()),
dynamic_axes={
name: axes for name, axes in chain(onnx_config.inputs.items(), onnx_config.outputs.items())
},
do_constant_folding=True,
use_external_data_format=onnx_config.use_external_data_format(model.num_parameters()),
enable_onnx_checker=True,
opset_version=onnx_config.default_onnx_opset,
)
其中:
- model:是想要导出的模型,例如一个BertModel;
- (dummy_inputs,):这个是一个虚拟的输入,相当于告诉模型输入应该是怎样的;
- f:是onnx保存的文件路径;
- input_names: 输入变量的名称;
- output_names:输出变量的名称;
- dynamic_axes:动态的变量,我理解它是不固定尺寸的变量,例如batch,seq_len,这里直接把所有的输入变量全都设置成不固定尺寸了;
可以看到,其中好几个变量都是来自于这个onnx_config,这个东西是怎么创建的呢,以bert做文本分类为例:
首先,建立模型和分词器:
from tranformers import AutoModel, AutoConfig, AutoTokenizer
bert_model = AutoModel.from_pretrained('bert-base-uncased')
config = AutoConfig.from_pretrained('bert-base-uncased')
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
然后利用config生成一个onnx的config:
from transformers.onnx.features import FeaturesManager
onnx_config = FeaturesManager._SUPPORTED_MODEL_TYPE['bert']['sequence-classification'](config)
然后就可以得到上面所需的那些变量了。
dummy_inputs的计算需要利用到tokenizer:
dummy_inputs = onnx_config.generate_dummy_inputs(tokenizer, framework='pt')
3. 载入onnx模型
onnx模型的使用也不复杂,还是跟着别人的项目照葫芦画瓢即可:
options = SessionOptions() # initialize session options
options.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALL
# 这里的路径传上一节保存的onnx模型地址
session = InferenceSession(
"./output_onnx_model.onnx", sess_options=options, providers=["CPUExecutionProvider"]
)
# disable session.run() fallback mechanism, it prevents for a reset of the execution provider
session.disable_fallback()
然后运行它,session的输入就是原本模型的inputs,但是注意要放在cpu上(gpu上的实验我暂时还没有尝试)。
text = 'your text here.'
inputs = tokenizer(text, return_tensors='pt')
inputs = {k: v.detach().cpu().numpy() for k, v in inputs.items()}
# 运行
# 这里的logits要有export的时候output_names相对应
session.run(output_names=['logits'], input_feed=inputs)
执行的结果就是numpy格式的(batch, len, hidden)的向量,接下来就可将这个logits给下游任务了。
4. 踩坑记录
在实际应用中,我们的模型一般不是只有一个编码器那么简单,编码器可能是复杂模型中的一部分,例如我试着对老朋友OneIE进行转换,我希望将OneIE的BertEncoder放在onnx执行。
于是我从整个oneie_model中把bert取了出来,再存成onnx格式,却报了这样的错误:
RuntimeException: [ONNXRuntimeError] : 6 : RUNTIME_EXCEPTION : Non-zero status code returned while running Reshape node. Name:'Reshape_138' Status Message: /onnxruntime_src/onnxruntime/core/providers/cpu/tensor/reshape_helper.h:41 onnxruntime::ReshapeHelper::ReshapeHelper(const onnxruntime::TensorShape&, std::vector
通过查资料发现onnx对torch的很多操作都不太友好,尤其是reshape,诸如torch.view等操作在onnx里边可能会过不去。
对于我遇到的场景,解决方法其实很简单,只需要从AutoModel.from_pretrained方法构建模型就可以了。
然后对于构建的初始化bert模型,再把oneie中bert相关的参数单独拿出来,让这个初始化的bert模型去load它,再导出onnx就不会报错了。
bert_model = AutoModel.from_pretraind('bert-large-cased')
state_dict = torch.load('oneie_model.bin')
bert_state_dict = {k[5:]: v for k, v in state_dict['model'].items() if k.startswith('bert.')}
bert_model.load_state_dict(bert_state_dict)
进一步地,我比较好奇问题出在哪里,这两种做法有什么区别,于是我把模型放到Netron可视化,观察报错的节点Reshape_138:
-
从整个大模型取出来的bert部分构建的onnx模型:
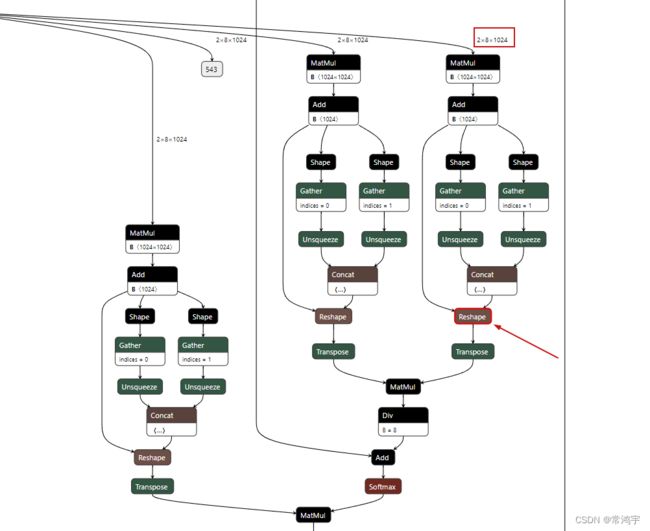
-
初始化构建的bert模型:
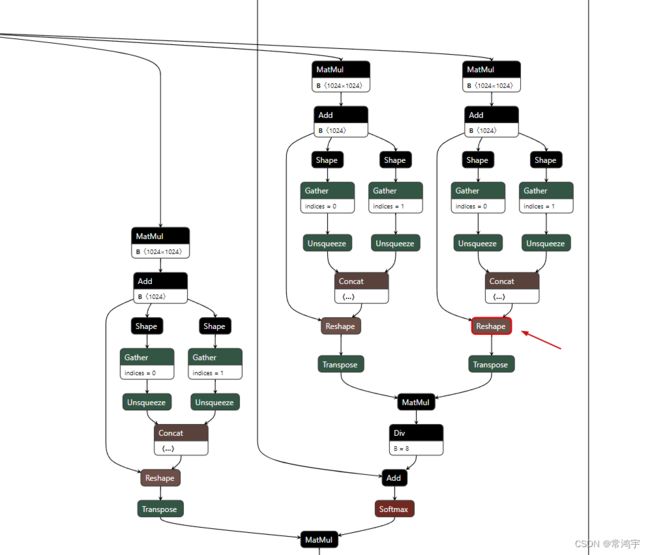
可以看到报错的reshape位于self-attention中,应该是multi-head维度拆分的位置,即transpose_for_scores的地方。两个模型的结构上基本是一样的,但是仔细看可以发现,第一张图的输入尺寸是固定的,也就是export的时候设置的动态参数并没有生效,模型误把我们给入的dummy inputs当成了真正的输入,导致对于不定长的序列,无法完成reshape操作。
至于这个问题为什么会出现,我不清楚。一个直观地猜测是,onnx是类似于tensorflow的计算图结构(从export的地方也可以感受到,给定input和output name的操作,好像是在给计算图创造placeholder),这就导致它和pytorch是天然不适配的,如果想把torch模型转成onnx结构,需要生成一个假的计算图。问题或许就出现在这里,当我给出的是一个大模型里的子结构的时候,导致onnx创建的计算图没有维持它最初应该保持的样子?
以上的分析只是我的猜想,我对onnx并没有什么深入的研究,也希望有对这方面有认真研究大佬们帮忙分析一下。
5. 实验结果
最终我的转换工作还是顺利完成了,使用onnx之后bert编码器在cpu上的推理耗时与torch在3090显卡上的耗时基本持平,从效果看还是很不错的,可以节省很多计算资源。