《Elasticsearch核心技术与实战》笔记
《Elasticsearch核心技术与实战》笔记
-
- 1、Video1:
- 2、Video2:
- 3、Video3:简介及发展历史
- 4、Video4:家族成员
- 5、Video5:安装下载
-
- 逻辑设计:文档、类型和索引,对应关系型数据库的行、表、库
- 物理设计:节点和分片,默认每个节点有5个分片和5个副本
- 6、Video6:Kibana安装
- 7、Video7:Docker容器运行ELK Stack
- 8、Video8:Logstash安装与导入数据
- 9、Video9:索引、文档和REST API
- 10、Video10:相关概念
- 11、Video11:CRUD
- 12、Video12 : 倒排索引
- 13、Video13:Ananlysis与Analyzer(分词器)
- 14、Video14:Search-Api概览
- 14、Video14:ElasticSearch之查询返回结果各字段含义
- 15、Video15:URI Search详解
- 16、Video16:Request Body和Query
- 17、Video17: Query String and Simple Query String
- 18、Video18: Dynamic Mapping和常见字段类型
- 19、Video19: 显示Mapping设置与常见参数介绍
- 20、Video20:多字段特性及Mapping中配置自定义Analyzer
- 21、Video21:Index Tamplate和Dynamic Template
- 22、Video22:ES聚合分析简介
- 23、Video23:总结
- 24.Video24:基于词项和基于全文的查询
- 25、Video25:ES中结构化搜索
- 26、Video26:搜索的相关性算分
- 27、Video:Query&Filter与多字符串多字段查询
- 28、Video28:单字符串多字段查询1
- 29、Video29:单字符串多字段查询2
- 30、Video:多语言及中文分词与检索
- 31、Video31:一次全文搜索
- 32、Video32:Search Template -解耦程序 & 搜索DSL
- 33、Video33:综合排序:Function Score Query优化算分
- 34、Video34:Term & phrase suggester
- 35、Video35:自动补全与基于上下文的提示
- 36、Video36:配置跨集群搜索
- 37、Video37:集群分布式架构及选主与脑裂
- 38、Video38:分片与集群的状态转移
- 39、Video39:文档分布式存储
- 40、Video40:分片内部原理
- 41、 Video41:剖析分布式查询及相关性 算分
- 42、 Video42:排序及Doc Value & Fileddata
- 43、Video43:分页与遍历
- 44、Video44:处理并发读写操作
- 45、Video45: Buket & Metric聚合分析及嵌套聚合
- 46、Video46: Pipeline聚合分析
- 47、Video47: 聚合作用范围
- 48、Video48: 结合分析的原理及精准度问题
- 49、Video49: 对象及Nested对象
- 50、Video50: 文档的父子关系
- 51、Video51: Update By Query & Reindex
- 52、Video52: Ingest Pipeline & Painless Script
- 53、Video53:数据建模实例
- 54、Video54:数据建模
- 55、Video55:Part2总结回顾
- 56、Video56:集群身份认证与用户鉴权
- 57、Video57:集群内部安全通信
- 58、Video58:集群与外部间的安全通信
- 59、Video59:常见的集群部署方式
- 60、Video60:Hot & Warm 与Shard
- 61、Video61:分片设计与管理
- 62、Video62:如何对集群进行容量规划
- 63、Video63:在私有云上管理ES集群
- 64、Video64:在公有云上管理ES集群
- 65、Video65:生产环境常用配置
- 66、Video66:监控ES集群
- 67、Video67:诊断集群的潜在问题
- 68、 Video68解决集群Yellow和Red问题
- 69、Video69:提升集群写性能
- 70、Video70:提升集群读性能
- 71、Video71:集群压力测试
- 72、Video72:段合并的优化及相应的注意事项
- 73、Video73:缓存及使用Breaker限制
- 74、Video74:一些运维相关的建议
- 75、Video75:使用Shrink和Rollover API
- 76、Video76:索引全生命周期管理
- 77、Video77:logstash入门及价格介绍
- 78、Video78利用JDBC插件导入数据
- 79、Video79:Beats介绍
- 80、Video80:使用Index Pattern 配置数据
- ---------------------------------------------------------------------
- SpringBoot集成ElasticSearch
-
1、Video1:
开源搜索引擎,for search
开箱即用:localhost:9200
- elasticsearch-head:客户端工具
- 下载:https://github.com/mobz/elasticsearch-head
- 安装:https://blog.csdn.net/weixin_41673498/article/details/103667541
- 访问:http://localhost:9100
- elasticsearch-head:客户端工具
-
2、Video2:
开发:产品基本功能,底层原理
运维:
方案:解决大数据搜索的解决方案
elastic认证工程师。
内容:入门、集群管理、大数据分析、实战
-
3、Video3:简介及发展历史
-
近实时
-
分布式 存储/搜索/分析引擎
Solr(Apache)
Splunk
多编程语言类库
RESTful API
-
功能:搜索、聚合
Lucene 7.x
- 跨集群复制
- 索引生命周期管理
- SQL支持
-
-
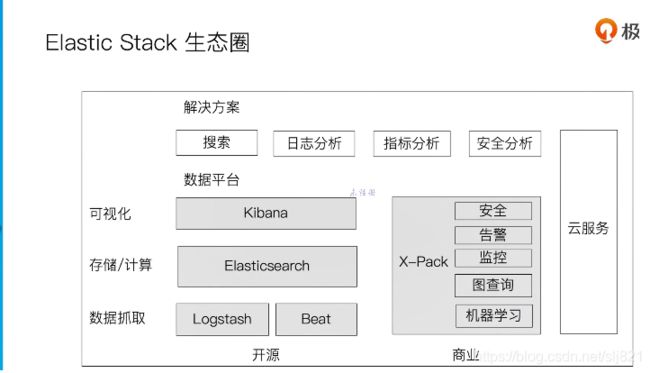
4、Video4:家族成员
-
ElasicSearch单独使用
-
与数据库集成情况:
- 与现有系统的集成
- 考虑事务性
- 数据更新频繁
-
5、Video5:安装下载
- Elasicsearch文件目录结构
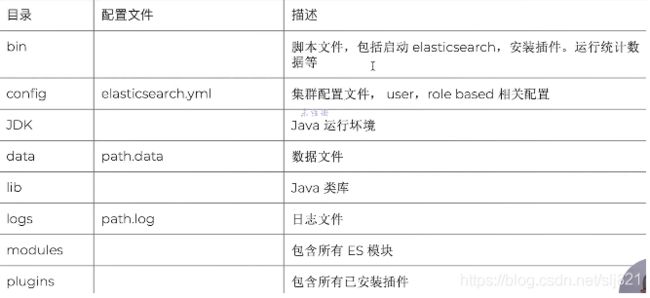
- JVM配置
- Elasicsearch文件目录结构

- 下载插件 :进入es安装目录的
D:\elasticsearch-5.6.9\bin>elasticsearch-plugin install analysis-icu
- 查询插件 :进入es安装目录的
D:\elasticsearch-5.6.9\bin>elasticsearch-plugin list
localhost:9200/_cat/plugins
- 开发机运行多个es实例
节点名称-集群名称-存放数据地址
bin/elasticsearch -E node.name=node1 -E cluster.name=geektime -E pah.data=nod1e_data -d
bin/elasticsearch -E node.name=node2 -E cluster.name=geektime -E pah.data=node2_data -d
bin/elasticsearch -E node.name=node3 -E cluster.name=geektime -E pah.data=node3_data -d
逻辑设计:文档、类型和索引,对应关系型数据库的行、表、库
物理设计:节点和分片,默认每个节点有5个分片和5个副本
-
6、Video6:Kibana安装
- 开箱即用:localhost:5601
kibana汉化配置
在kibana.yml文件最后一行加
注:5.6.9版本过低,无法通过配置汉化,只能下载汉化包汉化
i18n.locale: "zh-CN"

-
7、Video7:Docker容器运行ELK Stack
- Docker : ???
- cerebro : elasticsearch的监控工具
- 下载:https://github.com/lmenezes/cerebro/releases
- 安装:开箱即用:https://www.jianshu.com/p/433d821f9667
- 访问:localhost:9000
-
8、Video8:Logstash安装与导入数据
-
下载:https://www.elastic.co/cn/downloads/past-releases/logstash-5-6-9https://www.elastic.co/cn/downloads/past-releases/logstash-5-6-9
-
使用:解压后cmd进入\bin目录使用
-
bin/logstash -e 'input { stdin { } } output { stdout {} }' -
直接输入helloworld
-
样例:movielens.csv文件,配置config文件,将文件处理后输出到es的端口
-
-
9、Video9:索引、文档和REST API
- ES面向文档,是所有可搜索数据的最小单位(关系型中的一条记录)
- 文档被序列化JSON格式,保存在ES中
- 每个文档都有唯一 的Unique ID

- Mapping定义文档的字段名和字符类型,类似于关系型数据库的表结构定义
- Setting定义不同的数据分布
-
10、Video10:相关概念
- 节点:本质是一个JAVA进程,生产环境建议一台机器只运行一个节点实例
- 节点名字通过配置文件指定
- 每个节点都会分配一个UID,保存在data目录下
- Master Node主节点:修改集群状态信息
- Data Node数据节点:保存分片数据
- Coordinating Node协调节点:接收Client请求并分发到合适的节点
- 分片:运行的Lucene实例
- 分片需要提前做好容量规划
设置分片数量和副本数量:
方案1:创建索引的时候设置
PUT twitter { "settings" : { "index" : { "number_of_shards" : 3, "number_of_replicas" : 2 } } }方案2:创建Mapping的时候设置
PUT test { "settings" : { "number_of_shards" : 1 }, "mappings" : { "type1" : { "properties" : { "field1" : { "type" : "text" } } } } }- 集群健康状况:
- Green:主分片和副本都正常分配
- Yellow:主分片全部正常分配,有副本未能正常分配
- Red:有主分片未能分配
- Cerebro查看集群状态:localhost:9000
- 节点:本质是一个JAVA进程,生产环境建议一台机器只运行一个节点实例
-
11、Video11:CRUD

-
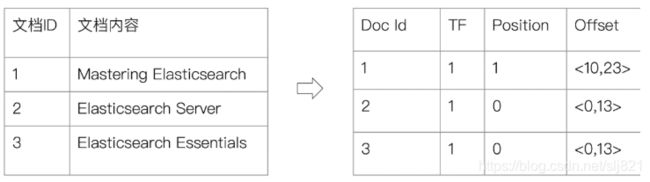
12、Video12 : 倒排索引
-
单词词典:
-
倒排列表:
-
-
13、Video13:Ananlysis与Analyzer(分词器)
-
Analyzer组成:
- Character Filter:针对原始文本处理,例如去除html
- Tokenizer:按照规则切分单词
- Token Filter:将切分的单词进行加工,小写,删除sopwords
-
ElasticSearch内置分词器
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6rbb893l-1615873812134)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20210311095203138.png)]
-
中文分词:
-
在elasicsearch的插件中下载ICU Analyzer
-
Elasticsearch-plugin install analysis -
从gitthub中下载IK分词器
https://github.com/medcl/elasticsearch-analysis-ik -
THULAC分词器(清华大学)
-
https://github.com/microbun/elasticsearch-thulac-plugin
-
-
-
DSL:
- 查询操作:
查询所有数据:
GET /_search
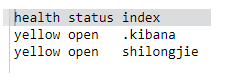
查看集群健康信息
GET /_cat/health?v

查看集群中节点信息
GET /_cat/nodes?v

查看集群中索引信息
GET /_cat/indices?v

简化:
GET /_cat/indices?v&h=health,status,index
- 索引操作
创建索引
PUT /baizhi
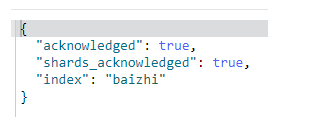
删除索引
DELETE /baizhi
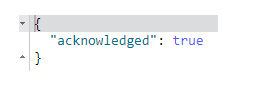
-
14、Video14:Search-Api概览
-
URI Search
- 在URL中使用查询参数

- 在URL中使用查询参数
-
Request Body Search
- DSL,Elesticsearch提供,给予json格式

- DSL,Elesticsearch提供,给予json格式
-
语法:

- 搜索的响应:
-
-
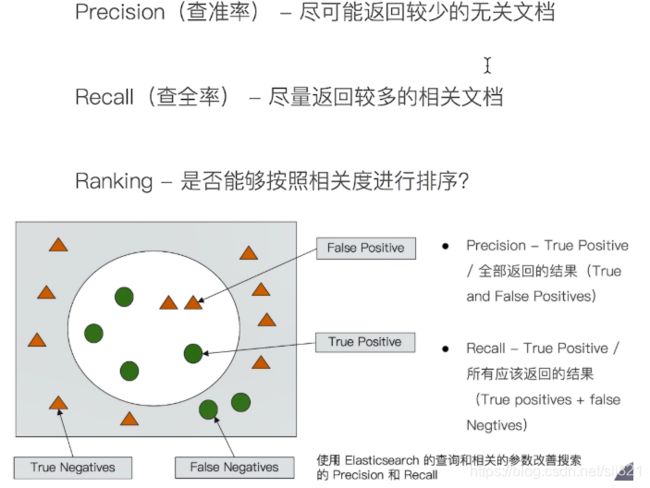
搜索的排序,谷歌采用Page Rank算法

- 相关性衡量:
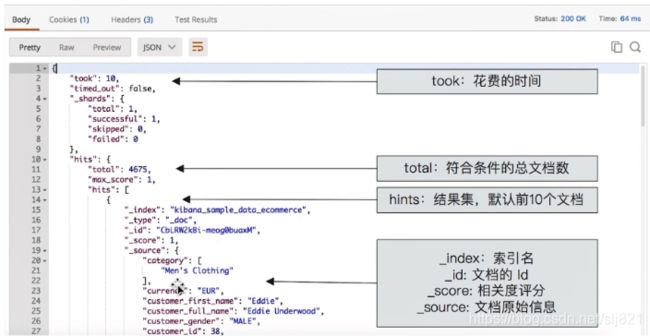
14、Video14:ElasticSearch之查询返回结果各字段含义
ES为了搜索提供了两大类api:URL search 和 Request Body Search
ElasticSearch查询返回结果各个字段的含义
GET /_search
结果略。从上到四个返回值,took,timed_out,_shards,hits。
- took:该命令请求花费了多长时间,单位:毫秒。
- timed_out:搜索是否超时
- _shards:搜索分片信息
- total:搜索分片的总数
- successful:搜索成功的分片数量
- skipped:没有搜索的分片,即跳过的分片
- failed:搜索失败的分片数量
- hits:搜索结果集,项目中一切数据都是从hits中获取
- total:返回多少条数据
- max_score:返回结果中最大的匹配度分值
- _index:索引库名称(库名)
- _type:类型名称(表名)
- _id:该条数据的id
- _score:关键字与该条数据的匹配度分值
- _source:索引库中类型,返回结果字段
15、Video15:URI Search详解
- 通过URI query实现搜索,请求格式为: 请求格式是 curl -XGET ip地址/索引/文档类型/_search?q=查询字段:查询条件
即在url 中拼接 “q” 跟着要查询的条件
查询条件格式为:查询字段:查询值 (key:value 格式)
curl -XGET http://localhost:9200/kibana_sample_data_ecommerce/_search?q=customer_first_name:Eddie

-
指定字段查询 / 泛查询
q=title:2012 / q=2012GET /movies/_search?q=2012&df=title { "profile":"ture" }// 泛查询,正对_all,所有字段
GET /movies/_search?q=2012// 指定字段
GET /movies/_search?q=title:2012 { "profile":"true" }Type:Disjunction Max Query:分离最大化查询:将任何与任一查询匹配的文档作为结果返回,但只将最佳匹配的评分作为查询的评分结果返回。弥补bool查询的不足
-
TermQuery:分词精确查询,如:查询hotelName分词后包含hotel的term文档
QueryBuilders.termQuery("hotelName","hotel")
- Terms Query:多term查询,查询hotelName 包含 hotel 或test 中的任何一个或多个的文档
QueryBuilders.termsQuery("hotelName","hotel","test")

// 使用引号,parase
```dsl
GET /movies/_search?q=title:"Beautiful Mind"
{
"profile":"true"
}
```
- Beautiful和Mind是or的关系,Beautiful是指定字段查询,Mind是泛查询,结果描述是泛查询
```dsl
GET /movies/_search?q=title:Beautiful Mind
{
"profile":"true"
}
```
```dsl
GET /movies/_search?q=title:(Beautiful Mind)
{
"profile":"true"
}
```
- 分组与引号:
 注:profile API 是 Elasticsearch 5.x 的一个新接口。通过这个功能,可以看到一个搜索聚合请求,是如何拆分成底层的 Lucene 请求,并且显示每部分的耗时情况。
注:profile API 是 Elasticsearch 5.x 的一个新接口。通过这个功能,可以看到一个搜索聚合请求,是如何拆分成底层的 Lucene 请求,并且显示每部分的耗时情况。
可以通过在 query 部分上方提供 “profile: true” 来启用Profile API。
- Bool分组查询,可合并多个查询语句,格式如下
{
"query":{
"bool":{
"must":[
],
"should":[
],
"must_not":[
],
"filter":[
],
"minimum_should_match":0
}
}
}
- 布尔与分组


GET /movies/_search?q=year:>190
{
"profile":"true"
}

GET /movies/_search?q=title:b*
{
"profile":"true"
}

16、Video16:Request Body和Query
- Request Body Search
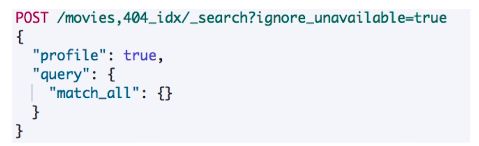
“match_all”:{} :匹配所有文档
-
分页

-
排序
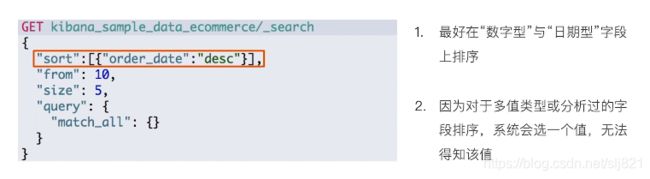
// 对日期进行排序
POST kibana_sample_data_ecommerce/_search
{
"sort":[{"order_date":desc}],
"query":{
"match_all":{}
}
}
-
对source的内容进行过滤,场景:有些时候不需要返回那么多字段,所以需要过滤掉不需要的字段,只返回需要的字段,类比select。
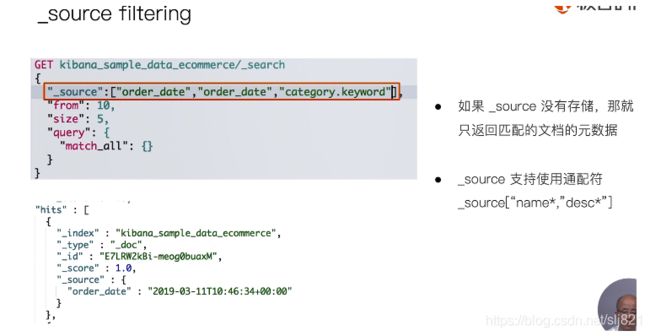
-
source filtering
POST kibana_sample_data_ecommerce/_search
{
"_source":[order_date"],
"query":{
"match_all":{}
}
}
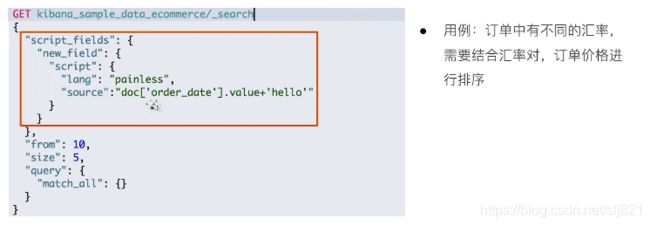
- 脚本字段script filed:动态是计算,模板
-:
"script": {
"lang": "...",
"source" | "id": "...",
"params": { ... }
}
-
lang:代表language脚本语言,默认指定为:painless。
-
source:脚本的核心部分,id应用于:stored script。
-
params:传递给脚本使用的变量参数。
- 使用查询表达式-Match

-
短语搜索 - Match Phrase:和match查询类似,match_phrase查询首先解析查询字符串来产生一个词条列表。然后会搜索所有的词条,但只保留包含了所有搜索词条的文档,并且词条的位置要邻接。
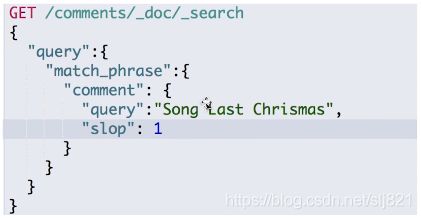
“slop”:1表示短语中单词之间可以有一个其他字符
17、Video17: Query String and Simple Query String
-
Query String 类似于Query

-
Simple Query String

18、Video18: Dynamic Mapping和常见字段类型
- Mapping的理解

- Dynamic Mapping动态映射机制是什么?
当Elasticsearch 遇到文档中以前 未遇到的字段,它用 dynamic mapping(动态映射) 来确定字段的数据类型并自动把新的字段添加到类型映射。

-
能否更改Mapping的字段类型?
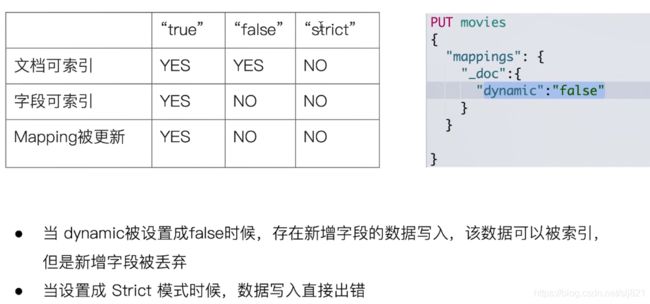
 - 控制Dynamic Mapping
- 控制Dynamic Mapping
-
字段的数据类型

19、Video19: 显示Mapping设置与常见参数介绍
- 如何定义一个Mapping?
PUT movies{
"mapping":{
// define your mappings here
}
}
- 自定义Mapping的建议:
- 参考API手册,纯手写
- 手写步骤:
1). 创建一个临时的index,写入一些样本数据
2).通过访问Mapping API获取该临时文件的动态Mapping定义
3).修改ES不正确的定义,使用该配置创建索引
4).删除临时索引
20、Video20:多字段特性及Mapping中配置自定义Analyzer
-
多字段类型
 如:为一个字段增加一个子字段keyword,为某些字段加上用英文或者拼音的方式进行分词
如:为一个字段增加一个子字段keyword,为某些字段加上用英文或者拼音的方式进行分词 -
精确值和全文本(Exact Value vs Full Text)

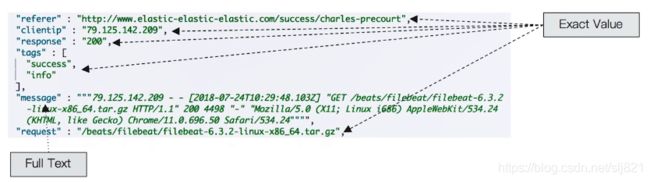 注:精确值不需要做分词处理
注:精确值不需要做分词处理 -
自定义分词器
-
当ES自带的分词器无法满足时自定义分词器,实现:通过自组合不同的组件实现。
-
ES中默认的Character Filters(字符过滤器):在Tokenizer之前对文本进行处理,例如增加删除及替换字符,可以配置多个Character Filter,但这样会影响Tokenizer的Position和offset信息
-
一些自带的Character Filter: HTML strip(去除html标签),Mapping(字符串替换)、Pattern replace(正则匹配替换)
-


-
设置一个自己的Custom Analyzer

21、Video21:Index Tamplate和Dynamic Template
-
Index template定义在创建新index时可以自动应用的settings和mappings
-
- 模板只有在一个索印被创建时才起作用,修改模板不会影响已创建的索引
-
- 可以设置多个索引模板,这些设置会被“merge”在一起
-
- 可以指定“order”的数值,控制“merging”的过程

- 可以指定“order”的数值,控制“merging”的过程
-
Dynamic template根据ES自动识别的数据类型,结合字段名称,动态设定字段类型
-
- 所有的字符串类型都设置成keyword,或者关闭keyword字段
-
- is开头的字段都设置成boolean
-
- long_开头的都设置成long型

- long_开头的都设置成long型
22、Video22:ES聚合分析简介
-
ES除搜索之外,提供了针对ES数据进行统计分析的功能(Aggregation)
-
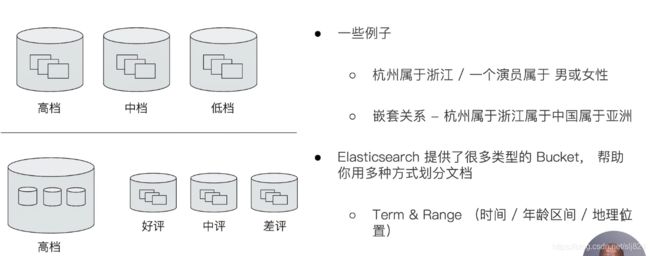
集合的分类
-
 - Bucket : 对应GROUP BY brand,一组满足条件的文档
- Bucket : 对应GROUP BY brand,一组满足条件的文档

-
Metric :对应SELECT COUNT(brand) from cars,一些系列的统计方法
-

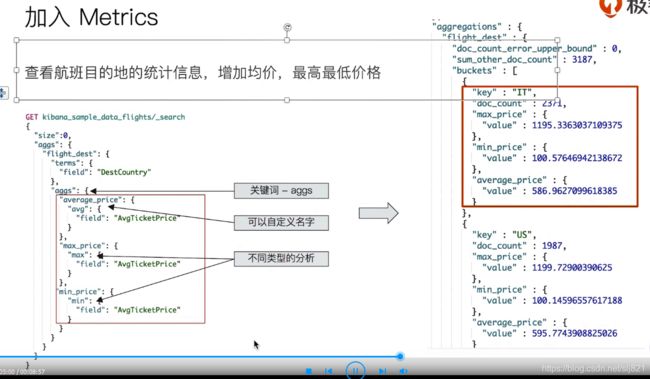
23、Video23:总结




 Answer:
Answer:
- 错,需要用POST创建
- 错,Update文档,使用POST,PUT只能用来做Index或者Create
- 对
- 默认情况下,会创建相应的索引,并且自己设置Mapping,当然,实际情况还要看是否有合适的Index Template
- ES7中只能有一个type,合法的是_doc
- 精确值不会被Analyzer分词的,全文本会被分词
- 三部分 :Character Filter–>Tokenizer–>Token Filter
 Answer:
Answer:
8. Match中terms之间是or的关系,Match phrase的terms之间是and的关系,并且term之间的位置关系也会之间影响搜索的结果
9. slop
10. 直接报错
11. 文档被索引,新增的字段在_source中可见,但是该字段无法被搜索
12. 错,字段类型修改,需要reindex操作
13. 对,在Mapping文件中可以为indexing和searching指定不同的analyzer
24.Video24:基于词项和基于全文的查询
- 基于Term的查询:Term是表达语意的最小单位,搜索和利用统计语言模型进行自然语言处理都需要处理term
- 基于全文的查询:


25、Video25:ES中结构化搜索


 范围查询:rang
范围查询:rang
query filter term搜索对文本不分词,直接拿去倒排索引匹配,你输入的是什么就去匹配什么
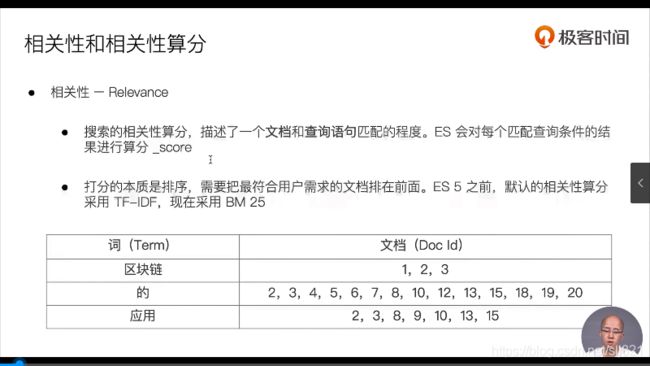
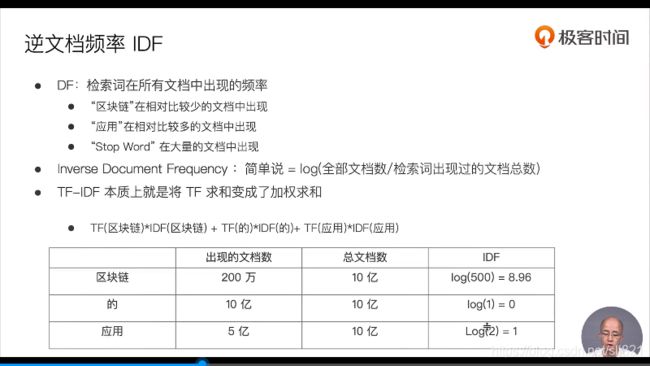
26、Video26:搜索的相关性算分



27、Video:Query&Filter与多字符串多字段查询
- 复合查询:bool Query
-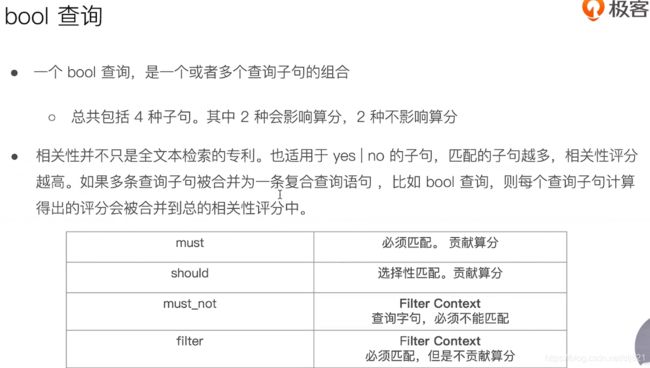

- 如何解决结构化查询-“包含而不是相等”问题


- bool Query支持嵌套
 - 查询语句的结构,会对相关度算法产生影响
- 查询语句的结构,会对相关度算法产生影响
- - 同一层级下的竞争字段,具有相同的权重
- 同一层级下的竞争字段,具有相同的权重- 通过嵌套bool查询,可以改变对算分的影响
- 通过设定每个字段的boosting的值可以控制相关度的算分,该值越大,算分越高
 “explain”: true,:查看如何算分
“explain”: true,:查看如何算分
28、Video28:单字符串多字段查询1
 以上算分的过程:
以上算分的过程:
- 查询should语句中的两个查询
- 两个平均的查询相加
- 乘以匹配语句的总数
- 除以所有语句的总数
上例中,title和body互相竞争:不应该将分数简单叠加,而是应该找到单个最佳匹配的字段的评分
- Disjunction Max Query查询:将任何与任一查询匹配的文档作为结果返回。采用字段上最匹配的评分作为最终算分返回
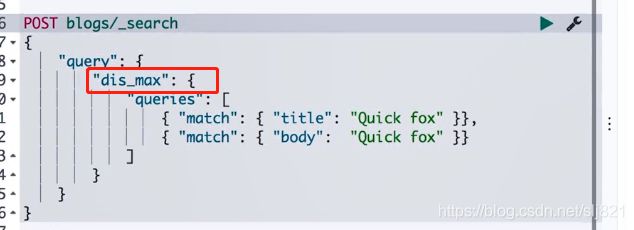
- 当最大评分相同时,如
 可以通过Tie Breaker参数调整
可以通过Tie Breaker参数调整
Tie Breaker是一个介于0-1之间的浮点数。0代表使用最佳匹配,1代表所有语句同等重要,示例如下:

- 获得最佳匹配语句的评分
- 将其他匹配语句的评分与tie_breaker相乘
- 对以上评分求和并规范化
29、Video29:单字符串多字段查询2
- Multi Match Query(多字段查询)
 多字段查询也会进行分词,其中type的设置如下:
多字段查询也会进行分词,其中type的设置如下:
 在搜索语句的filed,通过控制字段的权重,可以终止算分结果的返回。
在搜索语句的filed,通过控制字段的权重,可以终止算分结果的返回。
组合两个字段可以使用copy_to将两个字段合并到full_name中去,但会造成磁盘额外的开销
cross_filed支持使用Oprator,可以为单个字段提升权重
30、Video:多语言及中文分词与检索
- 自然语言与查询Recall
 - 混合多语言的挑战
- 混合多语言的挑战
 -
- - 分词的挑战

- 中文分词方法的演变—字典法

- 中文分词方法的演变—基于统计法的机器学习算法

HanLP–面向生产环境的自然语言处理工具包
http://hanlp.com/.
https://github.com/KennFalcon/elasticsearch-analysis-hanlp.
IK分词器
https://github.com/medcl/elasticsearch-analysis-hanlp.
icu
pinyin

31、Video31:一次全文搜索
- 搜索结果的分析
- 一个模型或者算法不是全适应的
,算法和模型的配合找最优解。

32、Video32:Search Template -解耦程序 & 搜索DSL
- Search Template:可以将一些搜索模板化,每次执行这些搜索,可以直接调用模板,传入一些参数即可,从而实现程序解耦。
- 语法:
search template:"{{field}}" : "{{value}}"
- 示例
GET /blog_website/blogs/_search/template
{
"inline" : {
"query": {
"match" : {
"{{field}}" : "{{value}}"
}
}
},
"params" : {
"field" : "title",
"value" : "博客"
}
}
相当于
GET /blog_website/blogs/_search
{
"query": {
"match" : {
"title" : "博客"
}
}
}
- Index Alias

33、Video33:综合排序:Function Score Query优化算分

注:当算分差别非常大的时候,可以通过Modifier平滑曲线

引入factor,更好的控制算分曲线

![]()
-
Boost Mode 和Max Boost
-

– ES可以指定一个字段,该字段的算分作为主要的参考依据 -
一致性随机函数
让每个用户能看到不同的***随机排名***,对于同一用户的访问,结果的相对顺序保持一致
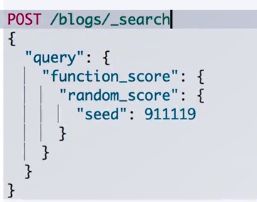 只要“seed”的值不变,搜索的结果相对顺序保持一致
只要“seed”的值不变,搜索的结果相对顺序保持一致
34、Video34:Term & phrase suggester
- ES Suggester API
-原理:将输入的文本分解为Token,然后在索引的字典里查找相似的Term并返回。 - ES设计了四种类别的Suggester
- Term & phrase suggester
- Complete & Context Suggester
Term suggester mode
 - 过程:用户输入一个错误的拼写到指定字段搜索,当搜索不到时会根据suggest-mode返回建议的词
- 过程:用户输入一个错误的拼写到指定字段搜索,当搜索不到时会根据suggest-mode返回建议的词
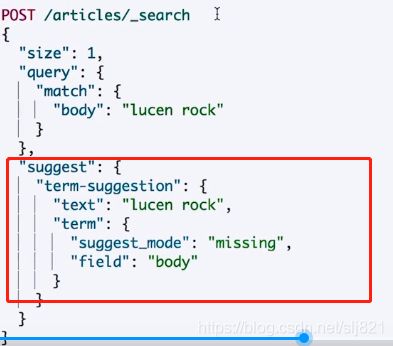
- phrase suggester

35、Video35:自动补全与基于上下文的提示
-
Completion Suggester:提供了自动完成的功能。用户每输入一个字符,就需要即时发送一个查询请求到后段查找匹配项。
-
注意:对性能要求苛刻,ES采用了不同的数据结构,并非通过倒排索引来完成,而是将Analyze的数据编码成FST和索引一起存放。FST会被ES整个加载进内存,速度很快。
-
FST只能用于前缀查找。
解释:FST是lucene中用来存储字典,并进行检索的核心数据结构,FST本质上是一个比HashMap有更强大功能keyvalue存储结构 -
使用步骤:
- 定义Mapping,使用"completion" type

- 索引数据
- 运行“suggest”查询,得到搜索建议
- Context Suggester

– 对比
- 精准度:Completion>Phrase>Term
- 召回率:Term>Phrase>Completion
- 性能:Completion>Phrase>Term
36、Video36:配置跨集群搜索
水平拓展痛点:
-
单集群:水平拓展时,节点不能无限增加。因为当集群的meta信息过多,会导致更新压力变大,单个Active Master会成为性能瓶颈,导致整个集群无法工作
-
跨集群搜索:Cross -cluster search,ES5.3引入
允许任何节点扮演federated节点,以轻量的方式,将搜索请求代理。
不需要以client node的方式加入 -
配置及查询

-
本地启动3个集群

37、Video37:集群分布式架构及选主与脑裂
-
ES分布式架构:
-
- 不同的集群通过不同的名字来区分,默认名字是“elasticsearch”
-
- 通过配置文件来修改,或者在命令行中-E cluster.name=newName
-
节点:

-
Coordinating Node:处理请求的节点,索引节点都默认是此节点通过将其他类型设置为false.使其成为Dedicated Coordinating Node
-
Data Node : 可以保存数据的节点,节点启动后默认就是数据节点,通过设置node.data:false禁止
-
Data Node的职责:保存分片数据,由Master决定如何把分片分发到数据节点上。通过增加数据节点,可以解决数据水平拓展和解决数据单点问题。
-
Master Node

-
Master eligible Node & 选主流程

-
集群状态信息(cluster state)保存有
- 所有的节点信息
- 所有的索引和其相关的Mapping和Setting信息
- 分片的路由信息
-
在每个节点都保存了集群的状态信息,但只能由Master Node才能修改状态信息并同步至其他节点。
-
选主流程:
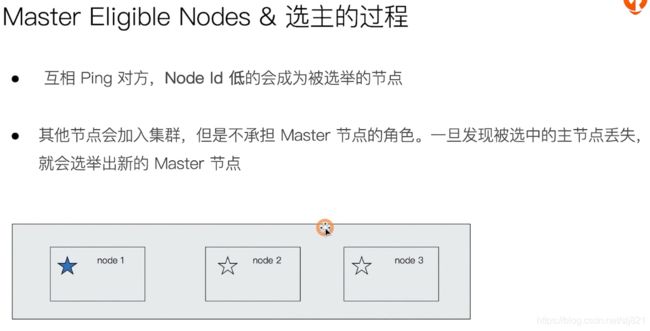 脑裂问题
脑裂问题
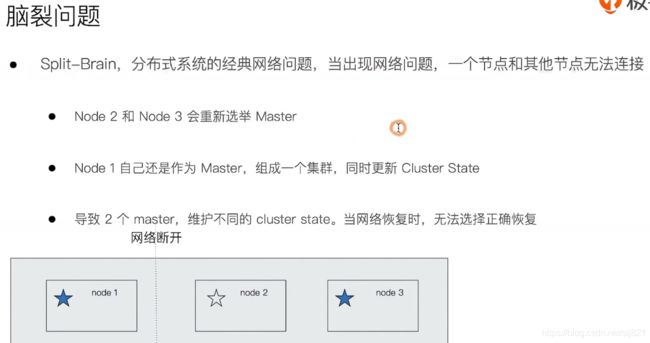 - 脑裂问题解决方案
- 脑裂问题解决方案

-
配置节点类型
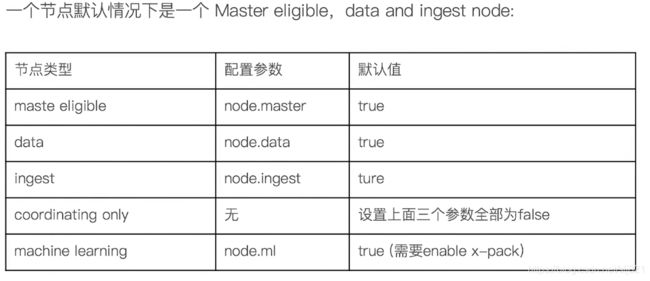
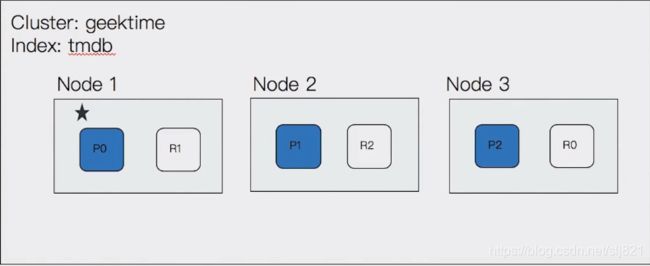
38、Video38:分片与集群的状态转移
- Primary shard-提升系统储存容量

- Replica shard-提高数据可用性

- 分片数的设定:
 注:副本分片必须和主分片分配到不同节点上,这样才能保证数据不会产生丢失,否则集群状态为Yellow
注:副本分片必须和主分片分配到不同节点上,这样才能保证数据不会产生丢失,否则集群状态为Yellow
 注:Master决定分片会分配到哪个节点。
注:Master决定分片会分配到哪个节点。
- 故障转移:
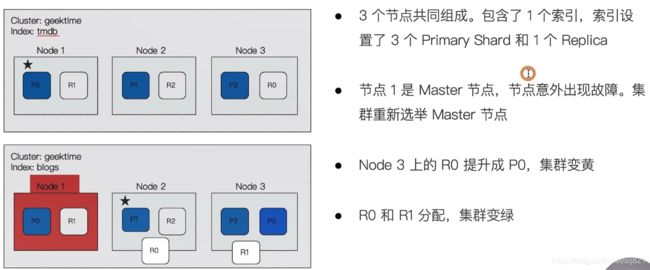
39、Video39:文档分布式存储
- 文档会存储在具体的某个主分片和副本分片上,例如文档1,存储在P0和R0上。
- 文档到分片的映射算法:

- 文档到分片的路由算法:
shard=hash(_rounting)%number_of_primary_shards
 不能修改Primary的原因是因为文档到分片的路由算法是由主分片数计算出来的
不能修改Primary的原因是因为文档到分片的路由算法是由主分片数计算出来的
- 更新文档的流程:
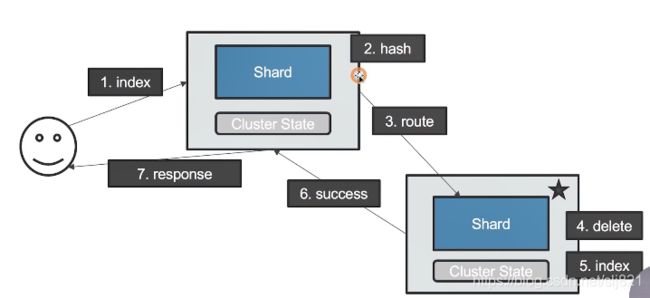
- 删除文档请求
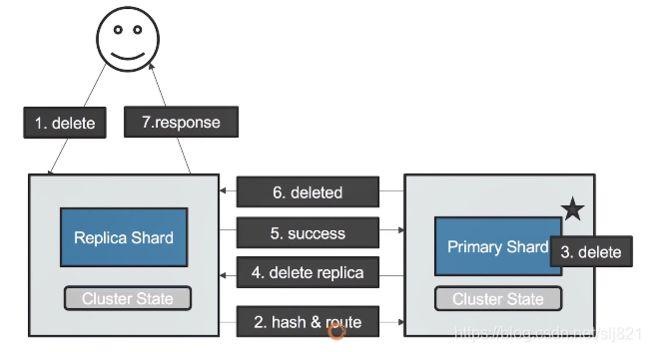
40、Video40:分片内部原理
-
ES中最小的工作单元是一个Lucene index ,一个分片就是一个Lucene index
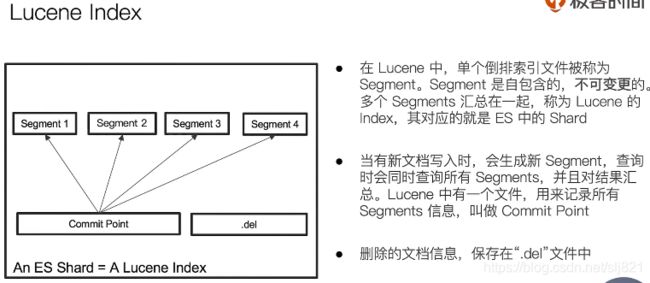
-
问题1:为什么ES的搜索是近实时的?
Refresh频率默认1s/次 -
Refresh:
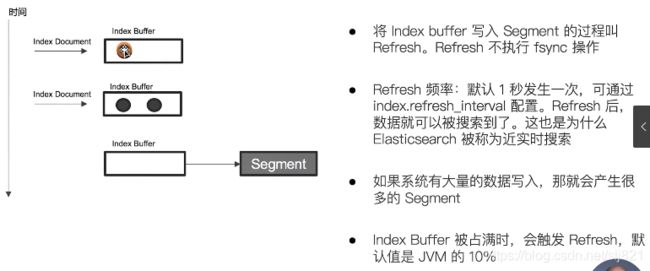
-
问题2:ES如何保证断电时数据也不丢失?
-
Transaction Log:
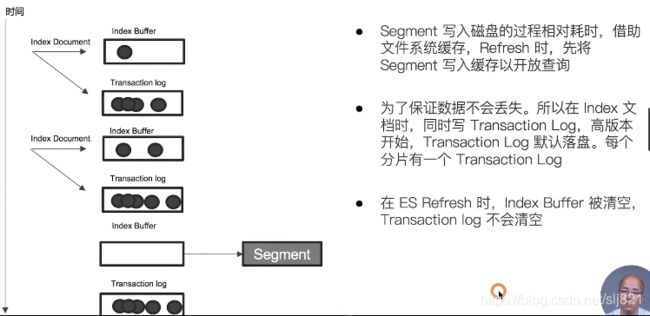
-
问题3:为什么删除文档,并不会立刻释放空间?
删除的文件保存在.del文件中,flush才会被彻底删除 -
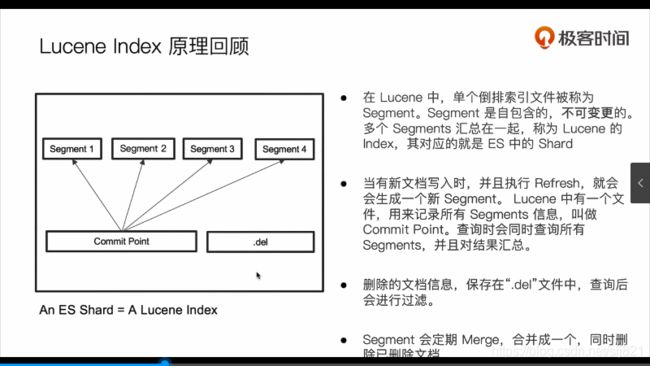
倒排索引不可变性
倒排索引一旦生产,不可更改。 -
好处:
- 无需考虑并发写文件的问题,避免了锁机制带来的性能问题。
- 一旦读入内核的文件系统缓存,便留在那里,只要文件系统有足够的空间,大部分请求直接请求内存,不会命中磁盘,提升了性能。
- 缓存容易生成和维护/数据可以被压缩。
-
坏处:如果让一个新文档可以被搜索,需要重建整个索引。
-
Flush

-
Merge

41、 Video41:剖析分布式查询及相关性 算分
- 分布式搜索运行机制(两个阶段):
- 阶段1:Query
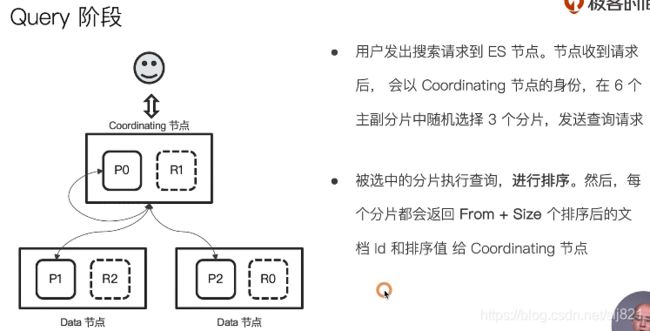
- 阶段2:Fetch
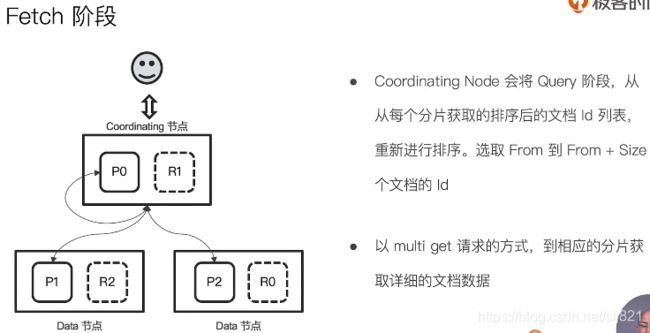
- Query then Fetch潜在问题
- 性能问题

- 相关性算分

- 解决相关性算分不准的方法

42、 Video42:排序及Doc Value & Fileddata
- 排序:
- 默认情况下,ES根据算法进行降序排序
- 可以通过设定sorting参数,自行设定排序
- 如果不指定_score , 算分为null
- 排序的过程
- 排序是针对字段原始内容进行的,倒排索引无法发挥作用
- 需要用到正排索引,通过文档Id和字段快速得到字段原始内容
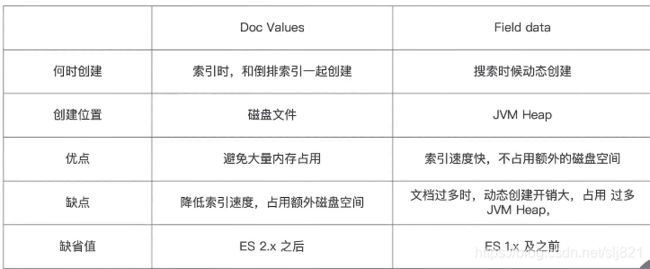
- ES排序的实现方法
- Fileddata(如果对Text类型字段排序,需要把Fileddata设置为true)
- Doc value(列式储存,对Text类型无效)
- Doc value VS Fileddata
- 关闭Doc value:
注意事项:- Doc value默认启用,可以通过Mapping设置关闭
优点:增加索引速度,减少内存空间 - 如果重新打开,需要重建索引
- 明确不需要做排序和聚合分析时关闭

- Doc value默认启用,可以通过Mapping设置关闭
43、Video43:分页与遍历
- From / Size
- 默认情况下,查询按照相关度算分排序,返回前10条记录
- 容易理解的分页方案:
From:开始的位置
Size:期望获取文档的总数
- 分布式系统中深度分页的问题
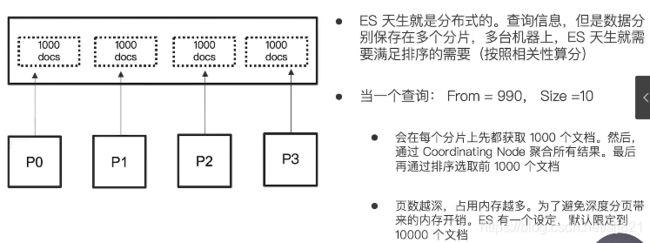
- 如何避免深度分页:Search After API
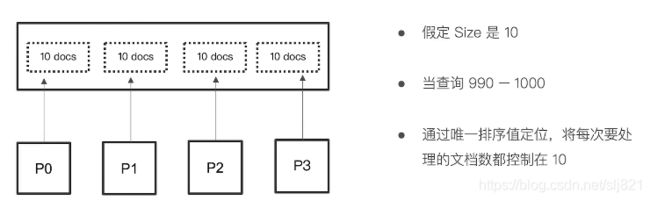
- Scroll API

- 不同搜索类型和使用场景
- Regular:需要实时获取顶部的部分文档,例如查询最新的订单
- Scroll:需要全部文档,例如导出全部数据
- Paginatuion:From和Size,如果需要深度分页,则选用Search API
44、Video44:处理并发读写操作
-
通过_version版本号的方式进行乐观锁并发控制
-
在es内部第次一创建document的时候,它的_version默认会是1,之后进行的删除和修改的操作_version都会增加1。可以看到删除一个document之后,再进行同一个id的document添加操作,版本号是加1而不是初始化为1,从而可以说明document并不是正真地被物理删除,它的一些版本号信息一样会存在,而是会在某个时刻一起被清除。
-
es提供了一个外部版本号的乐观控制方案来替代内部的_version:
?version=1&version_type=external
- 内在version和外部version区别:
对于内在_version=1,只有在后续请求满足?_version=1的时候才能够更新成功;对于外部_version=1,只有在后续请求满足?_version>1才能够修改成功,即必须大于对应的版本才可以进行修改。
45、Video45: Buket & Metric聚合分析及嵌套聚合
- bucket:一个数据分组,类似于group by user_id --> 那些user_id相同的数据,就会被划分到一个bucket中
- metric:对一个数据分组执行的统计,类似于count(*),对每个user_id bucket中所有的数据,计算一个数量
"aggregations" : { // 表示聚合操作,可以使用aggs替代
"" : { // 聚合名,可以是任意的字符串。用做响应的key,便于快速取得正确的响应数据。
"" : { // 聚合类别,就是各种类型的聚合,如min等
<aggregation_body> // 聚合体,不同的聚合有不同的body
}
[,"aggregations" : { [<sub_aggregation>]+ } ]? // 嵌套的子聚合,可以有0或多个
}
[,"" : { ... } ]* // 另外的聚合,可以有0或多个
}
-注:聚合是和查询同等级的
例:
curl -XPOST "192.168.1.101:9200/student/student/_search" -d
'
{
"query": { // 可以先使用query查询得到需要的数据集
"term": {
"classNo": "2"
}
},
"aggs": {
"min_age": {
"min": {
"field": "age"
}
}
}
}
'
46、Video46: Pipeline聚合分析
-
支持对聚合分析的结果,再次进行聚合分析;
-
Pipeline 的分析结果会输出到原结果中,根据位置的不同,分为两类
-
Sibling - 结果和现有分析结果同级
- max / min / avg & sum bucket
- stats / extended status bucket
- percentiles bucket
-
Parent - 结果内嵌到现有的聚合分析结果之中
- Derivate - 求导
- Cumultive Sum - 累计求和
- Moving Function - 滑动窗口
-
-
例1:平均工资最低的工资类型 | sibling Pipeline
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"min_salary_by_job":{
"min_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
- 例2:平均工资的平均工资 | Sibling Pipeline
POST employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"avg_salary_by_job":{
"avg_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
- 例3:按照年龄对平均工资求导 | Parent Pipeline
POST employees/_search
{
"size": 0,
"aggs": {
"age": {
"histogram": {
"field": "age",
"min_doc_count": 1,
"interval": 1
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
},
"derivative_avg_salary":{
"derivative": {
"buckets_path": "avg_salary"
}
}
}
}
}
}
47、Video47: 聚合作用范围
- 聚合的作用范围
- ES 聚合分析的默认作用范围是 query 的查询结果集
- ES 还支持以下方式改变聚合的作用范围
- Filter
- Post_Filter
- Global
参考:
链接: https://blog.csdn.net/xixihahalelehehe/article/details/114411134.
-
排序
指定orde,默认情况下按照降序排序
指定size,就能返回相应的桶 -
ES内部排序
- _count:这个参数对应的就是doc_count
GET /cars/transactions/_search
{
"size":0,
"aggs":{
"popular_colors":{
"terms": {
"field": "color",
"order": { ---表示要对聚合结果做排序
"_count": "desc" ---排序字段是doc_count,顺序是降序
}
}
}
}
}
- _key:在区间聚合的时候(histogram或者date_histogram),可以根据桶的key做排序:_key:在区间聚合的时候(histogram或者date_histogram),可以根据桶的key做排序:
GET /cars/transactions/_search
{
"size": 0,
"aggs": {
"price": {
"histogram": { ---区间聚合
"field": "price", ---取price字段的值
"interval": 20000, ---每个区间的大小是20000
"order": { ---表示要对聚合结果做排序
"_key": "desc" ---排序字段是桶的key值,这里是每个区间的起始值,顺序是降序
}
}
}
}
}
48、Video48: 结合分析的原理及精准度问题
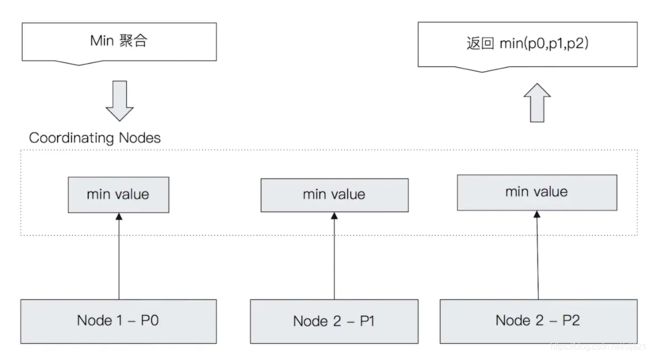
-
min 聚合分析的执行流程
-
Terms Aggregation | 返回参数中的 2 个特殊值
- doc_count_error_upper_bound:被遗漏的分桶中可能包含的文档数的最大数;
- sum_other_doc_count:除了返回结果中的 Bucket 中的文档以外,其他文档的数量(索引中总文档数 - 桶中返回的文档数);
-
Terms Aggregation | 执行流程
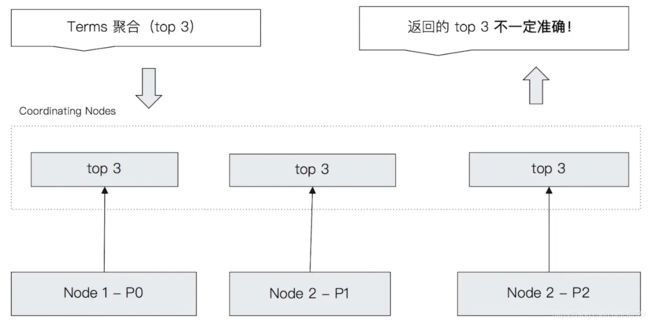 注:返回分桶中文档数最大的 3 个分桶;结果不一定准确;
注:返回分桶中文档数最大的 3 个分桶;结果不一定准确;
-
Term聚合不正确的案例:
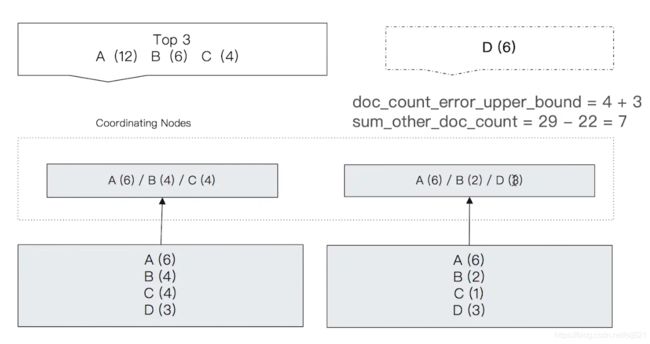 文档数最多的 3 个桶应该是 A,B,D,但是 Terms 聚合的结果是 A,B,C;
文档数最多的 3 个桶应该是 A,B,D,但是 Terms 聚合的结果是 A,B,C; -
doc_count_error_upper_bound | 举例分析
左边的分片中,选出来的文档数最大的 3 个桶中的文档数分别是:6, 4, 4,那么遗漏的文档数最大可能就是 4; -
右边的分片中,选出来的文档数最大的 3 个桶中的文档数分别是:6, 3, 2,那么遗漏的文档数最大可能就是 2(图中有错);
-
sum_other_doc_count | 举例分析
索引中全部文档数 - 返回的 3 个桶中的文档总数,29 - 22 = 7; -
解决 Terms 聚合不准的问题 | 提升 shard_size 的参数
Terms 聚合分析不准的原因:
数据分散在多个分片上,Coordinating Node 无法获取数据的全貌;
解决方法1:
当数据量不大时,设置 Primary Shard 数为 1,实现准确性;
解决方法2:
当数据分布在多个 Primary Shard 上时,设置 shard_size 参数,提升准确性,其原理是:每次从 Shard 上额外多获取数据,提升准确率; -
参数 | shard_size | 设定
通过调大 shard_size 的大小,使得 doc_count_error_upper_bound 的值降低,从而提升准确度,其原理是:增加整体计算量,提高精准度的同时会降低响应时间; -
shard_size 默认大小
shard_size = size * 1.5 + 10
49、Video49: 对象及Nested对象
- 对象类型
使用json、json数组作为字段值,动态映射会默认使用对象类型(type object)。
参考:https://blog.csdn.net/liuhe2296044/article/details/103745740?utm_source=app&app_version=4.5.5
50、Video50: 文档的父子关系
-
对象 | Nested 对象 | 局限性
每篇博客的文档中,包含作者信息,当作者信息变更时,整个博客文档都需要变更; -
Parent & Child
- ElasticSearch 中提供了类似关系型数据库中 Join 的实现,使用 Join 数据类型实现,可以通过维护 Parent / Child 的关系,从而分离两个对象;
- 父文档和子文档是两个独立的文档;
- 更新父文档,无需重新索引子文档;子文档被添加、更新或删除也不会影响到父文档和其他的子文档
-
定义父子关系的步骤
- 设置索引的Mapping
- 索引父文档
- 索引子文档
- 按需查询文档
-
文档父子关系实例:
- “type”: “join” 指定这是一个父子文档;
- relations 中 “blog”: “comment” 指明 blog 是父文档,comment 是子文档;
DELETE my_blogs
PUT my_blogs
{
"settings": {
"number_of_shards": 2
},
"mappings": {
"properties": {
"blog_comments_relation": {
"type": "join",
"relations": {
"blog": "comment"
}
},
"content": {
"type": "text"
},
"title": {
"type": "keyword"
}
}
}
}
参考链接:https://blog.csdn.net/weixin_33669968/article/details/106422331?utm_source=app&app_version=4.5.5
51、Video51: Update By Query & Reindex
-
重建索引的场景
- 索引的Mapping发生变更:字段类型更改,分词器及字典更新
- 索引的Setting发生变更:索引的主分片数发生变更
- 集群内、集群间需要做数据迁移
-
重建索引的API: Update By Query Reindex
-
Update By Query :在现有索引上重建
POST 索引/索引类型/_update_by_query
{
"script": {
"source": "ctx._source['修改的字段名'] = '修改后的值'"
},
"query": {
"bool": {
"must": [
{
"term": {
"查询条件此处为字段名": "字段的值"
}
}
],
"must_not": [],
"should": []
}
}
}
查询index索引,type等于index_type中数据满足field=value的数据,修改其中field=test,对应的就是关系型数据库的update set … where…语句;
-
Reindex:在其他索引上重建索引
-
Reindex基础实现: _reindex会将一个索引的快照数据copy到另一个索引,默认情况下存在相同的_id会进行覆盖(一般不会发生,除非是将两个索引的数据copy到一个索引中),
POST _reindex
{
"source": {
"index": "my_index_name"
},
"dest": {
"index": "my_index_name_new"
}
}
52、Video52: Ingest Pipeline & Painless Script
-
Elasticsearch可以使用自身的Ingest Pipeline功能进行数据预处理, 无须借助Logstash.
-
Ingest Pipeline介绍:Ingest Pipeline 就是在文档写入Data Node之前进行一系列的数据预处理, 进行数据预处理的就是processor, 一组处理器构成了Pipeline. 所有的预处理都在Ingest Node上执行, 默认情况下所有节点都是Ingest Node.
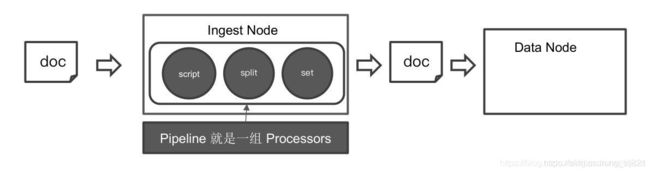 - 常用的process
- 常用的process -
split processor
字符串切分成数组 -
join processor
数组转化成字符串 -
gsub processor
字符串替换 -
set processor
创建或替换一个字段. -
remove processor
移除一个字段 -
rename processor
重命名一个字段 -
lowercase processor
字符串小写化 -
upcase processor
字符串大写化 -
script processor
使用painless脚本进行复杂的处理 -
语法:
- 创建Pipeline
PUT /_ingest/pipeline/my_pipeline_id
{
"description": "to split blog tags",
"processors": [
{
"split": {
"field": "tags",
"separator": ","
}
}
]
}
description是对pipeline的描述, processors定义了一组处理器.
- painless脚本定义Processor : Elasticsearch内置了很多processor, 可以进行一些简单的数据预处理, 但如果我们想进行复杂的数据预处理, 就需要使用painless脚本来自定义processor.
(1). 创建Pipeline:
使用painless脚本来自定义一个processor, 如果存在一个content的字段, 则新增一个content_length, 值为content字段值的长度.
PUT /_ingest/pipeline/my_pipeline_id
{
"description": "to split blog tags",
"processors": [
{
"split": {
"field": "tags",
"separator": ","
}
},
{
"script": {
"source": """
if(ctx.containsKey("content")){
ctx.content_length = ctx.content.length();
}else{
ctx.content_length = 0;
}
"""
}
}
]
}
(2)新增文档
PUT /blogs/_doc/1?pipeline=my_pipeline_id
{
"title": "Introducing big data......",
"tags": "hadoop,elasticsearch,spark",
"content": "You konw, for big data"
}
PUT /blogs/_doc/2?pipeline=my_pipeline_id
{
"title":"Introducing cloud computering",
"tags":"openstack,k8s",
"content":"You konw, for cloud"
}
(3) 查看文档
GET /blogs/_search
(4)结果:
"hits" : [
{
"_index" : "blogs",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "Introducing big data......",
"content" : "You konw, for big data",
"content_length" : 22,
"tags" : [
"hadoop",
"elasticsearch",
"spark"
]
}
},
{
"_index" : "blogs",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"title" : "Introducing cloud computering",
"content" : "You konw, for cloud",
"content_length" : 19,
"tags" : [
"openstack",
"k8s"
]
}
}
]
- Ingest Pipeline 和 Logstash 的对比

53、Video53:数据建模实例
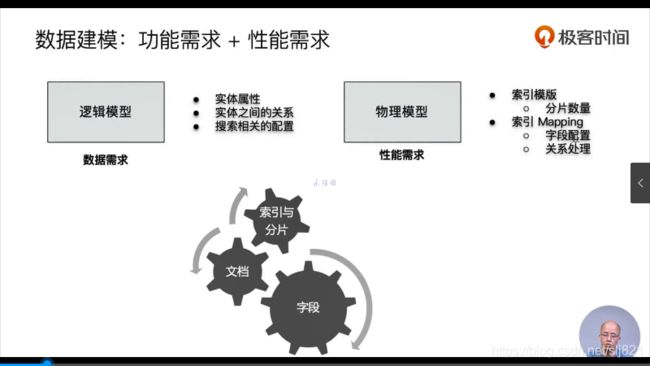
- 数据建模概念
 - 数据建模:功能需求+性能需求
- 数据建模:功能需求+性能需求
 - 如何对字段进行建模步骤:
- 如何对字段进行建模步骤:
- 字段类型
- 是否要搜索及分词
- 是否要聚合及排序
- 是否要额外的存储
- 选择字段类型

- 字段类型:结构化数据

- 检索的角度:

- 聚合及排序的角度

- 额外的存储角度

- 数据建模实例理解
- 创建一个文档:关于图书的信息
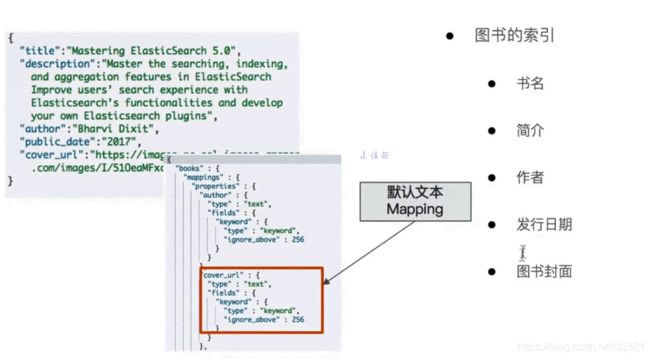 2. 优化字段设定:cover_url不会被检索
2. 优化字段设定:cover_url不会被检索
 3. 需求变更:增加字段处理办法
3. 需求变更:增加字段处理办法

- Mapping字段的设置

- 一些相关的API

54、Video54:数据建模
- 建模建议(1):如何处理关联关系

注:Kibana目前不支持nested类型和parent/child类型,未来可能会支持。
- 建模建议(2):避免过多字段
 - 导致文档中有成百上千的字段原因:
- 导致文档中有成百上千的字段原因:
Dynamic VS Strict

- 解决方案:Nested Object & Key Value
- 存在的不足:
 - 建模建议(3):避免正则查询
- 建模建议(3):避免正则查询
 - 解决方案:将字符串转换为对象
- 解决方案:将字符串转换为对象

建模建议(4):避免空值引起的聚合不准
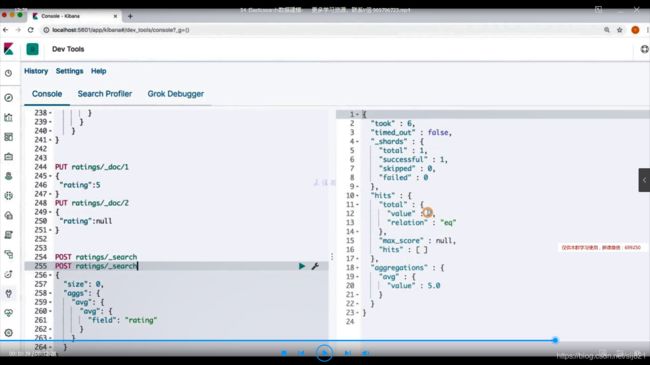
建模建议(5):为索引的Mapping加入Meta信息

55、Video55:Part2总结回顾
- 搜索与算分

 - 聚合/分页
- 聚合/分页
 - ES分布式模型
- ES分布式模型

- 数据建模及重要性

56、Video56:集群身份认证与用户鉴权
-
用户文档信息泄露原因:
-
- ES在默认安装后,不提供任何形式的安全防护
-
- 错误的配置信息导致公网可以访问集群:在elasticsearch.yml文件中,server.host被错误的配置为0.0.0.0
-
数据安全的基本需求

-
免费方案:
 - Authtication - 身份认证
- Authtication - 身份认证

-
RBAC - 用户鉴权

-
使用Security API创建用户

-
开启并配置X-Pack的认证与鉴权

57、Video57:集群内部安全通信
- ES内部是通过9300端口进行数据传输
- 避免数据抓包,敏感信息泄露
- 避免Impostor Node



58、Video58:集群与外部间的安全通信
- 配置ES for HTTPS

59、Video59:常见的集群部署方式
- 节点参数配置
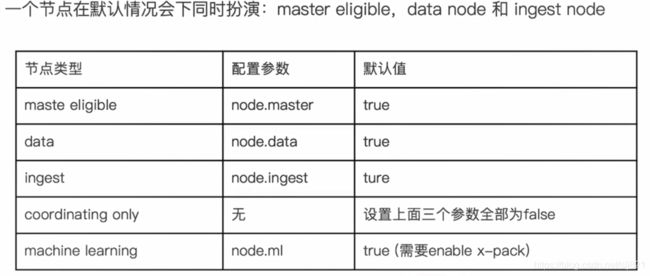
- 单一职责的节点
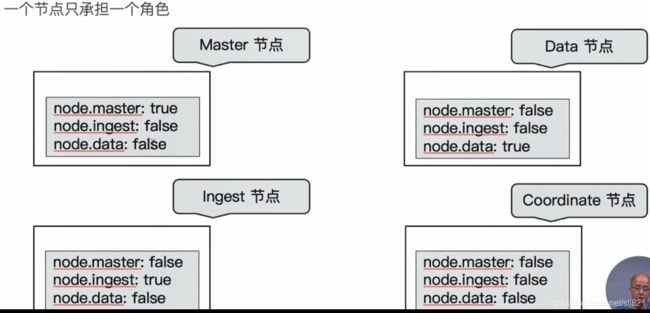
- 单一角色:职责分离的好处



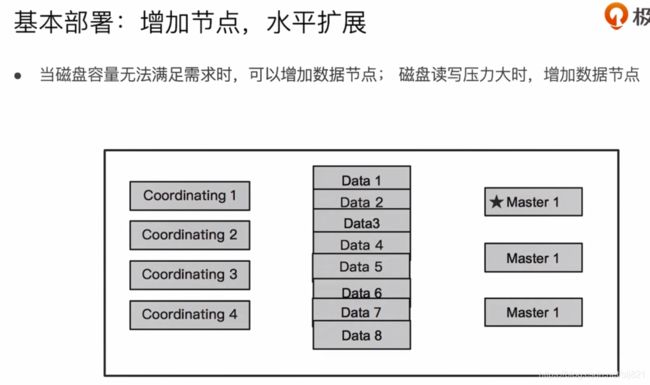
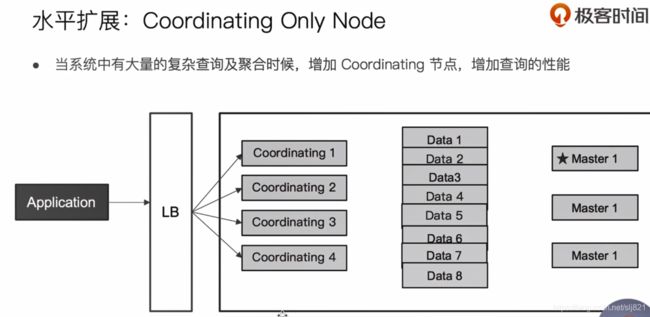
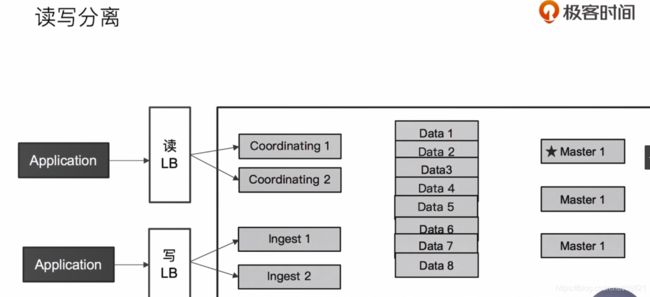
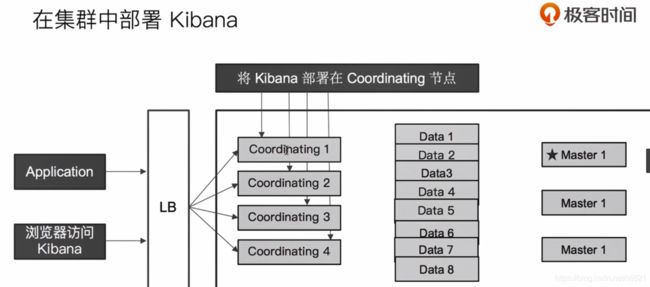
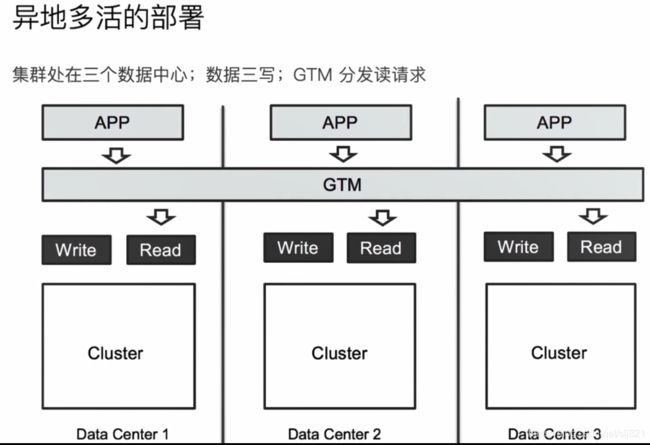
60、Video60:Hot & Warm 与Shard

-
Hot Nodes
用于数据的写入,- Indexing对CPU和IO都有很高的要求,所以需要使用高配置的机器
- 储存的性能要好,建议使用SSD
-
Warm Nodes
用于保存只读索引- 通常使用大容量的磁盘(通常是Spinning Disks)
-
配置Hot & Warm Architecture
- 使用Shard Filtering 步骤分为以下几步
-
标记节点
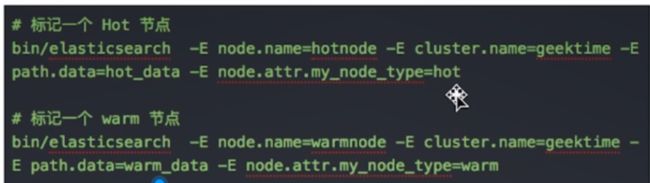
-
配置索引到Hot Node

-
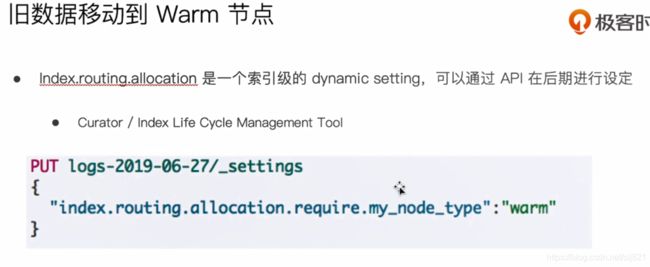
配置索引到Warm Node
-
- 使用Shard Filtering 步骤分为以下几步
- Rack Awareness
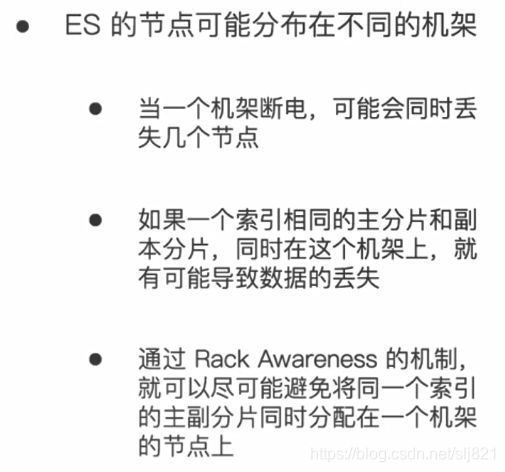
- 标记Rack节点+配置集群
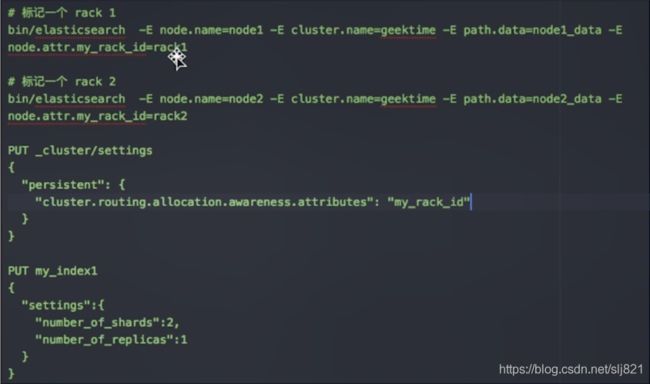
- Shard Filtering
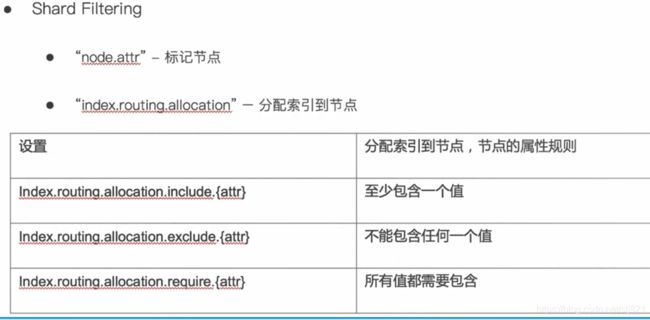
61、Video61:分片设计与管理
-
ES7.0开始,新建一个索引时,默认创建一个分片
-
单分片:
- 好处:查询算分,聚合不准问题都可以得到避免
- 坏处:单索引单分片时,集群无法实现水平扩展
-
集群增加一个节点后,ES会自动进行分片的移动
-
如何设计分片?

-
案例:

-
分片过多的副作用

-
ES官方确定主分片数

-
ES官方确定副分片数

-
调整分片总数设定,避免分配不均衡

62、Video62:如何对集群进行容量规划
-
容量规划

-
评估业务的性能需求

-
常见用例

-
硬件配置

-
部署方式

-
容量规划案例



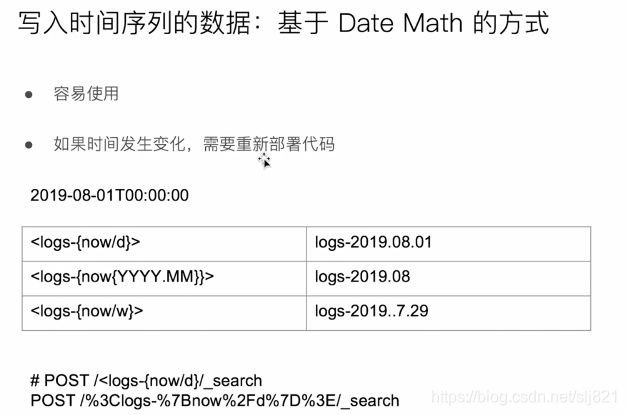

- 拆分索引

- 集群扩容

63、Video63:在私有云上管理ES集群
-
管理单个集群
-
ECE:管理多个ES集群
-
Kubernetes:

-
构建自己的管理系统

64、Video64:在公有云上管理ES集群
65、Video65:生产环境常用配置
-
Development VS Production Mode

-
Bootstrap Checks

-
JVM设定

-
集群的API设定

-
系统设置
参考官方手册 -
网络

-
内存设定计算实例

-
存储

-
服务器硬件

-
Throttles限流

-
关闭Dynamic Indexes

-
集群安全设定

66、Video66:监控ES集群
-
ES stas 相关的API

-
ES Task 相关的API

-
The index & Query Slow Log
- 支持将分片上Search和Fetch阶段的慢查询写入文件
- 支持为Query和Fetch分别定义阈值
- 索引级的动态设置,可以按需设置,或者通过Index Template统一设定
- Slog log 文件通过log4j2.properties配置
-
如何创建监控Dashboard

67、Video67:诊断集群的潜在问题
- 集群运维所面临的挑战



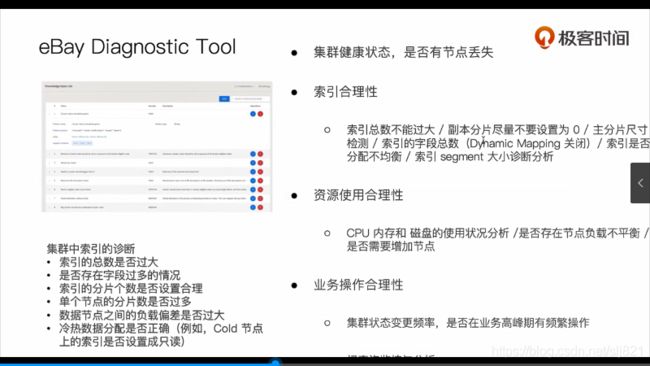

68、 Video68解决集群Yellow和Red问题
-
集群健康度
-
-
Health相关的API
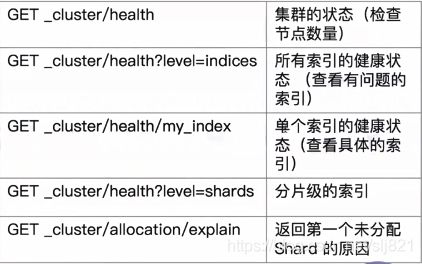
-
案例分析
集群变红:

集群变黄

-
分片没有被分配的一些原因

-
常见问题与解决方法

69、Video69:提升集群写性能
-
提升写性能的方法

-
服务器端优化写入性能的一些手段

-
关闭无关功能

-
针对性能的取舍

-
数据写入过程



-
分片的设定

-
Bulk,线程池和队列大小

-
一个索引设定的例子

70、Video70:提升集群读性能
-
尽量Denormalize数据

-
数据建模


- 优化分片

71、Video71:集群压力测试
 - 测试目标
- 测试目标
 - 测试脚本
- 测试脚本
 - ES Rally
- ES Rally
72、Video72:段合并的优化及相应的注意事项
-
Merge优化


-
Force Merge

73、Video73:缓存及使用Breaker限制
- Es的缓存
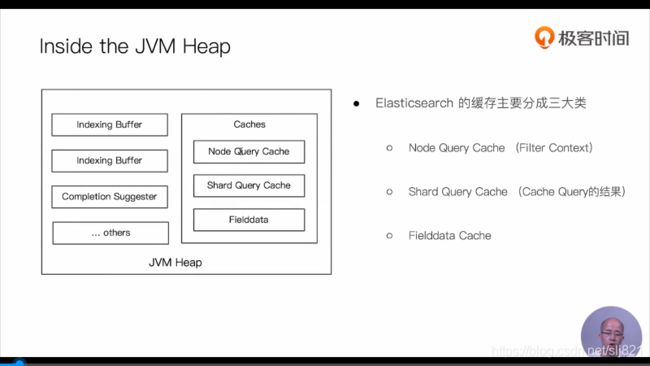
- Node Query Cache

- Shard Query Cache

- Fileddata Cache

- 缓存失效

- 管理内存的重要性

-
诊断内存情况
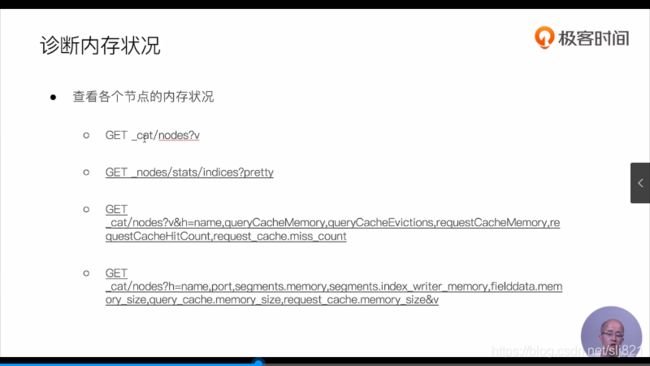
-
常见内存问题



-
Circuit Breaker(断路器)


74、Video74:一些运维相关的建议
- 集群的生命周期管理

- 部署的建议

- 遵循的规范


- 数据备份

- 定期更新新版本

- ES的版本

- 升级方法
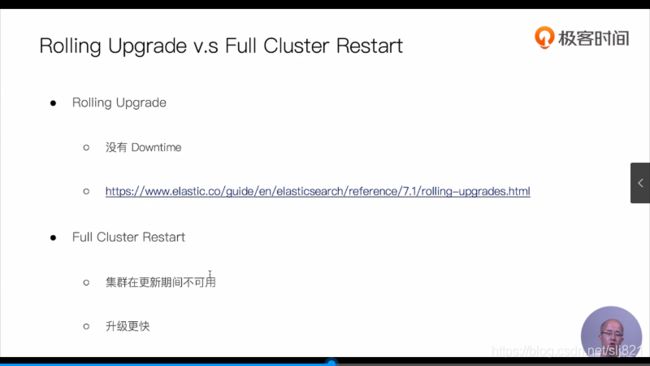
- Full Restart 步骤

- 移动分片

- 移除节点

- 控制Allocation和Recovery

- Synced Flush

- 清空节点上的缓存

- 控制搜索的队列

- 设置Circuitt Breaker

75、Video75:使用Shrink和Rollover API
- 索引管理API

- shrink API

- Rollover API

76、Video76:索引全生命周期管理
- 时间序列的索引

- 索引常见的生命阶段

- ES Curator

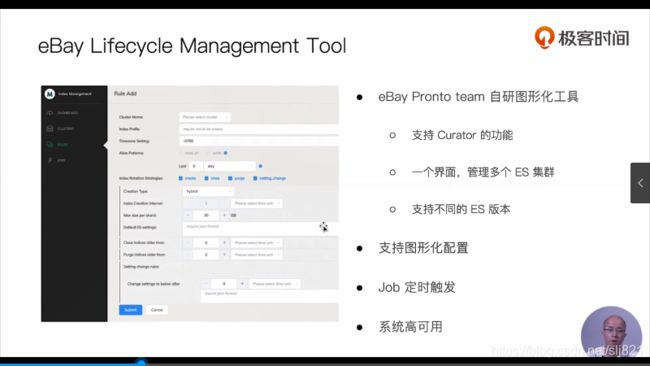


77、Video77:logstash入门及价格介绍
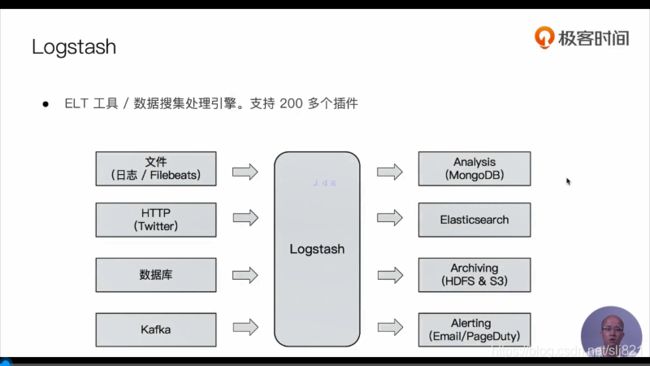
- Logstash concepts
 - logstash架构
- logstash架构
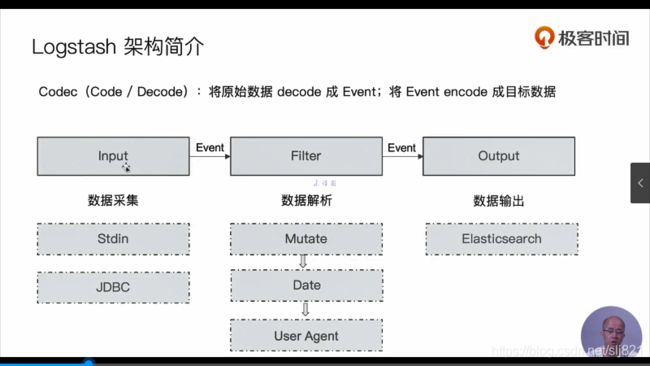
- logstash配置文件结构

- Input Plugins

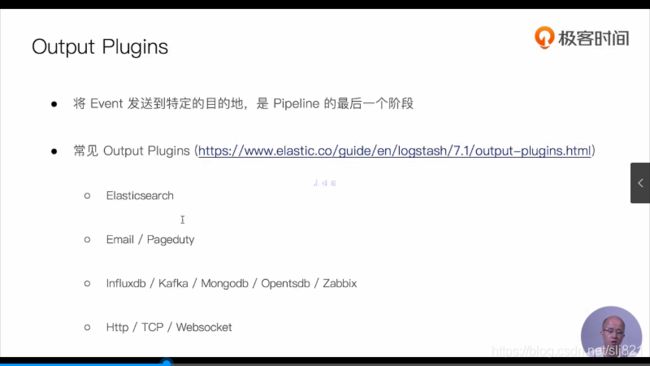
- Out plugins
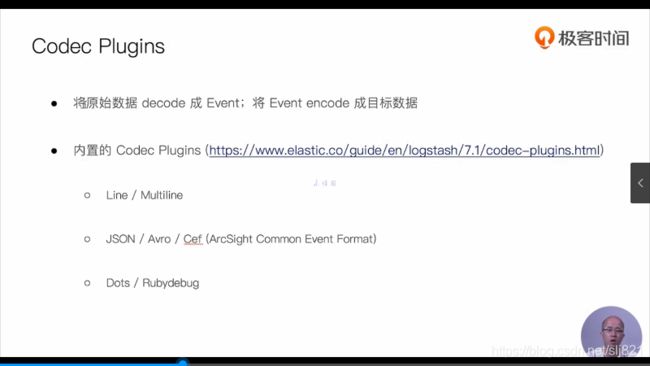
-
Codec Plugind
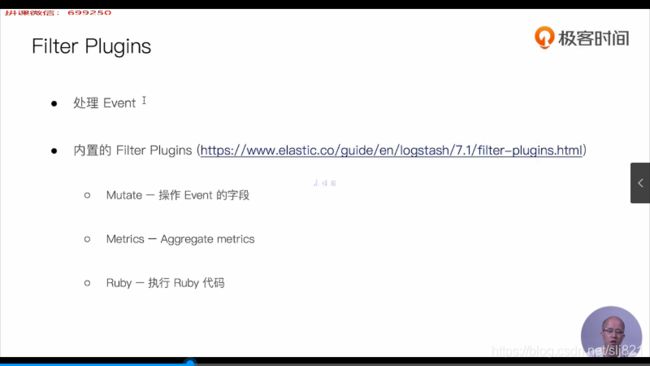
-
Filter Plugins
-
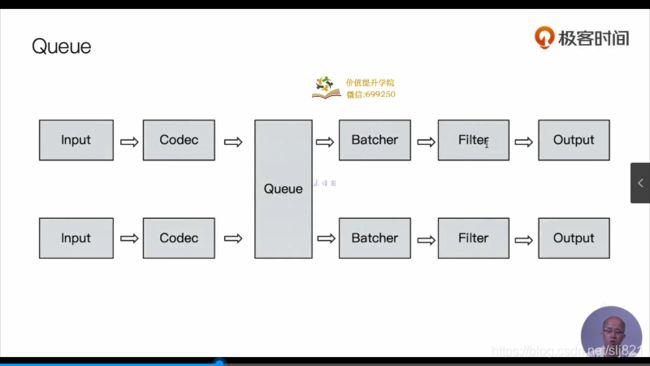
Queue
-
-
多Pipeline实例
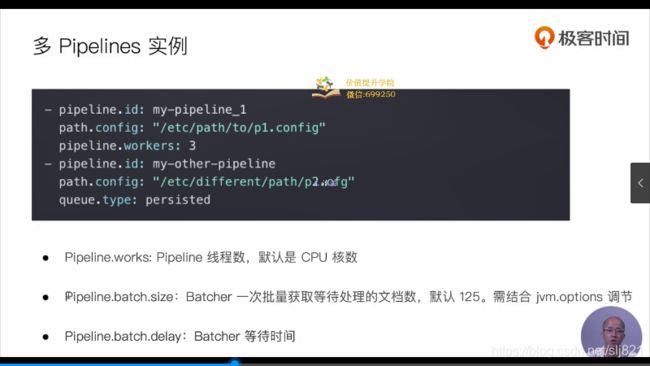
-
logstash Queue

-
Codec Plugin -single Line

-
Codec Plugin -multiline

-
Filter Plugin


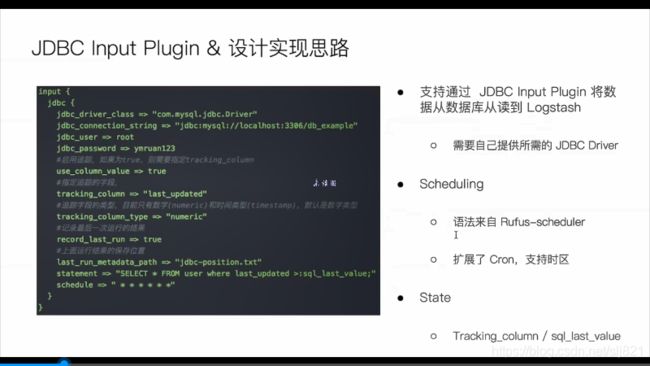
78、Video78利用JDBC插件导入数据

79、Video79:Beats介绍
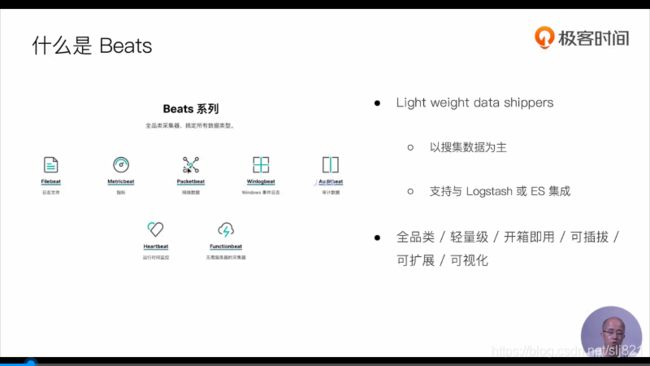

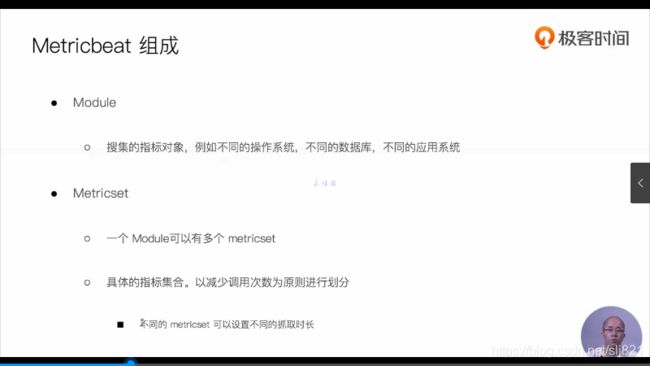
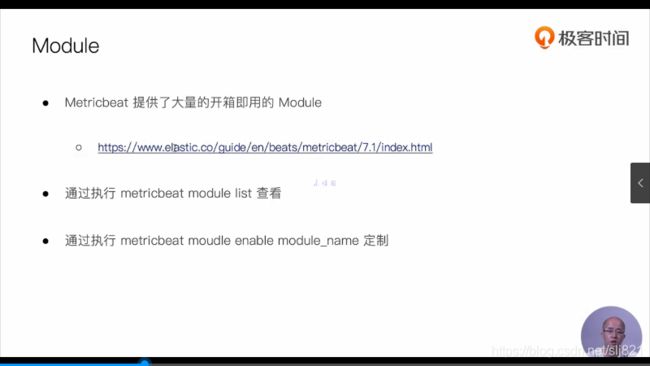
- Packbeat

80、Video80:使用Index Pattern 配置数据
---------------------------------------------------------------------
SpringBoot集成ElasticSearch
6.0以上版本的ElasticSearch直接导入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
6.0以下2版本的ElasticSearch依赖配置
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>transportartifactId>
<version>5.6.9version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-coreartifactId>
<version>6.6.1version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-highlighterartifactId>
<version>6.6.1version>
dependency>
<dependency>
<groupId>org.apache.lucenegroupId>
<artifactId>lucene-queriesartifactId>
<version>6.6.1version>
dependency>
注:版本号获取
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NuxCkTIB-1615873812156)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20210312112549525.png)]