机器学习-决策树算法-01
文章目录
-
-
- 决策树算法
-
- 1. 什么是决策树/判定树
- 2. 决策树归纳算法
- 3. 熵概念
- 4. 具体算法
- 5. 决策树剪枝
- 6. 决策树算法的优缺点
- 7. 决策树算法的具体实现
-
- 7.1. 使用sklearn工具包实现
- 7.2. 模拟实现
-
决策树算法
1. 什么是决策树/判定树
决策树是一个类似于流程图的树结构,其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类的分布,树的顶层是根结点。决策树是一种有监督学习的一种算法,是机器学习中分类方法中的一个重要分支。
2. 决策树归纳算法
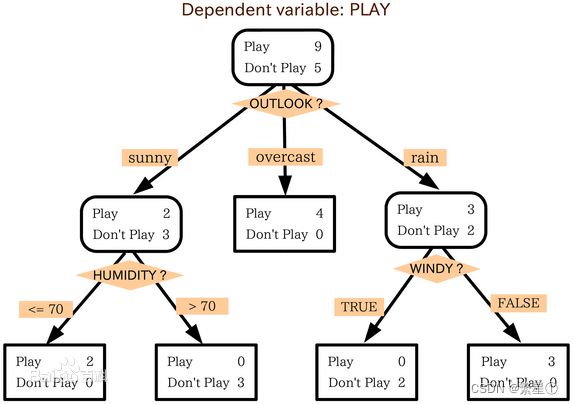
![]()
-
策略:
- 自根至叶的递归过程,在每个中间结点寻找一个"划分"属性
- 开始构建根结点,所有训练数据都放在根结点,选择一个最优特征,按照这一特征将训练集分割成子集,进入子结点
- 所有子集按内部结点的属性递归的进行分割
- 如果这些子集已经能够被基本正确分类,那么构建叶结点,并将这些子集分到所对应的叶结点上去
- 每个子集都被分到叶结点上,即都有了明确的类,这就生成了一颗决策树
三种停止条件:
- 当前结点包含的样本全属于同一个类别,无需划分
- 当前属性集为空,或者所有样本在所有属性上取值相同,无法划分
- 当前结点包含的样本集合为空,不能划分
3. 熵概念
-
用比特
(bit)来衡量信息的多少熵:
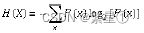
变量的不确定性越大,熵就越大。
信息的获取量:
Gain(A) = Info(D) - Infor_A(D)
4. 具体算法
- ID3算法
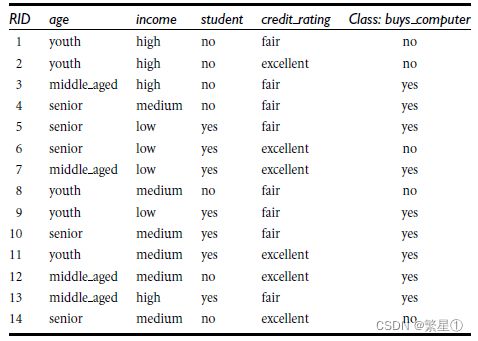
![]()
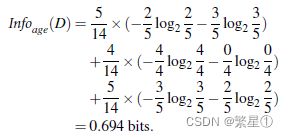
![]()
![]()
对于以上的四个属性中,最大的信息熵为age,所以选择age作为第一个分支,建立决策树

具体的实现过程:

-
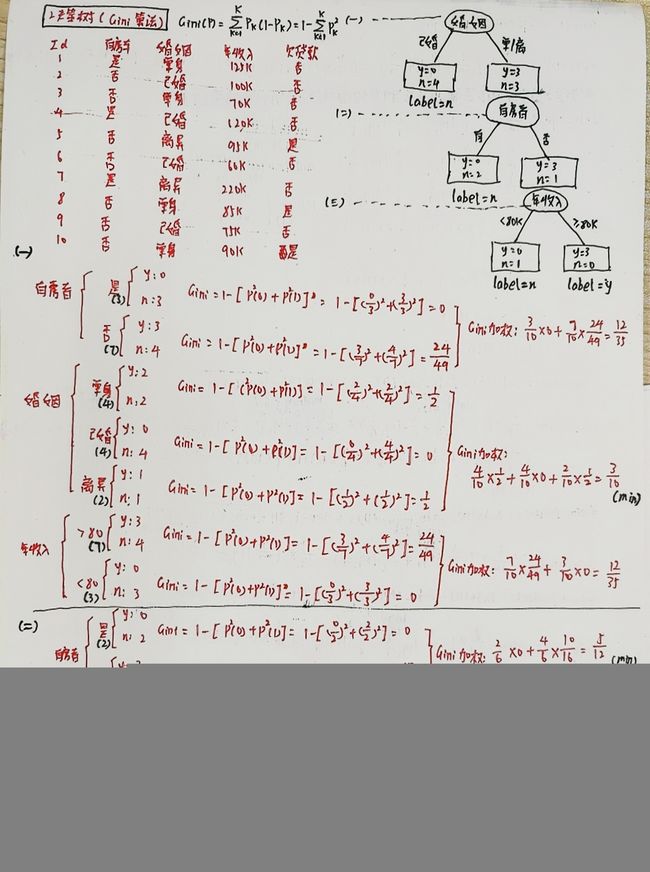
Gini算法
反映了从D中随机抽取两个样例,其类别标记不一致的概率
Gini(D)越小,数据集D的纯度越高
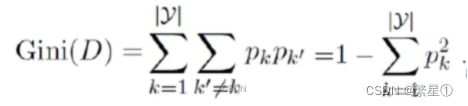
属性a的基尼指数:

在候选属性集合中,选取那个使划分后基尼系数最小的属性
-
增益率-C4.5算法
信息增益:对可取值数目较多的属性有所偏好(缺点)
增益率:

- 属性a的可能取值数目越大(即V越大),则IV(a)的值通常就越大
- 启发式:先从候选划分属性中找出信息增益高于平均水平的,再从中选取增益率最高的
5. 决策树剪枝
-
剪枝:防止决策树过拟合
-
基本策略:
- 预剪枝:提前终止某些分支的生长
- 后剪枝:生成一棵完全树,再回头剪枝
-
优缺点:
-
时间开销:
- 预剪枝:训练时间开销降低,测试时间开销降低
- 后剪枝:训练时间开销增加,测试时间开销降低
-
过/欠拟合风险:
- 预剪枝:过拟合风险降低,欠拟合风险增加
- 后剪枝:过拟合风险降低,欠拟合风险不变
-
泛化性能:
后剪枝通常由于预剪枝
-
6. 决策树算法的优缺点
- 优点:
- 速度快:计算量相对较少,且容易转化为分类规则。只要沿着树根向下一直走到叶,沿途的分裂条件就能唯一确定一条分类的谓词。
- 准确性高:挖掘出来的分类规则准确性高,便于理解,决策树可以清晰的看到哪些字段比较重要
- 非参数学习,不需要设置参数
- 缺点:
- 缺乏伸缩性:由于进行深度优先搜索,所以算法受内存大小限制,难于处理大训练集。
- 为了处理大数据集或连续值的种种改进算法(离散化、取样)不仅增加了分类算法的额外开销,而且降低了分类的准确性,对连续性的字段比较难预测,当类别太多时,错误可能就会增加的比较快,对有时间顺序的数据,需要很多预处理的工作。
7. 决策树算法的具体实现
7.1. 使用sklearn工具包实现
from sklearn.feature_extraction import DictVectorizer
# 读取和写入csv文件时用到
import csv
# 导入决策树模块
from sklearn import tree
# 导入数据预处理模块
from sklearn import preprocessing
# 读取csv文件,并将特征放入dict列表和类标签列表中
allElectronicsData = open("注意:文件路径",'rt')
reader = csv.reader(allElectronicsData)
headers = next(reader)
print(headers)
# 保存前面的属性组
featureList = []
# 保存后面的标签分类
labelList = []
for row in reader:
labelList.append(row[len(row)-1])
rowDict = {}
for i in range(1,len(row)-1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(featureList)
# 数据预处理,把分类数据二值化
vec = DictVectorizer()
dummyx = vec.fit_transform(featureList).toarray()
print("dummyX:" + str(dummyx))
print(vec.get_feature_names_out())
print("labelList:" + str(labelList))
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY:" + str(dummyY))
# 创建决策树分类的对象
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyx,dummyY)
# 可视化模型
with open("注意:文件路径", 'w') as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names_out(), out_file=f)
# 测试集进行验证
oneRowW = dummyx[0,:]
print("oneRowX:" + str(oneRowW))
# 把数据集中的年龄改为中年
newRowX = oneRowW
newRowX[0] = 1
newRowX[2] = 0
print("newRowX:" + str(newRowX))
newRowX = [newRowX]
predictedY = clf.predict(newRowX)
print("predictedY:" + str(predictedY))
结果展示:

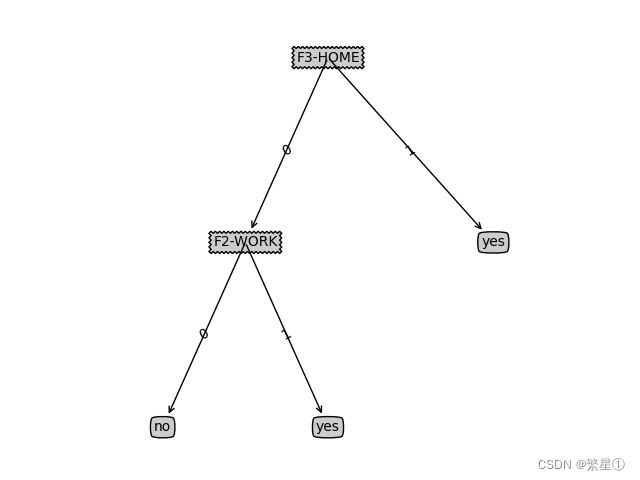
7.2. 模拟实现
- 导包操作
import matplotlib.pyplot as plt
from math import log
import operator
- 算法模拟核心
def createDataSet():
dataSet = [[0, 0, 0, 0, 'no'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['F1-AGE','F2-WORK','F3-HOME','F4-LOAN']
return dataSet,labels
def createTree(dataset,labels,featLabels):
"""
dataset:数据集
labels:最终的标签的分类
featLabels: 标签的顺序
"""
# 把数据集最后一列的值存入classList
classList = [example[-1] for example in dataset]
# 当样本的标签全部一样时,就会相等
if classList.count(classList[0]) == len(classList):
return classList[0]
# 当前数据集中只剩下一类标签,此时已经遍历完了所有的数据集
if len(dataset[0]) == 1:
return majorityCnt(classList)
# 选择最优的特征,对应索引值
bestFeat = chooseBestFeatureToSplit(dataset)
# 找到实际的名字
bestFeatLabel = labels[bestFeat]
featLabels.append(bestFeatLabel)
myTree = {bestFeatLabel:{}}
del labels[bestFeat]
featValue = [example[bestFeat] for example in dataset]
# 得到不同的分支
uniqueVals = set(featValue)
for value in uniqueVals:
# 递归运行过程中,标签值的更替
sublabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataset,bestFeat,value),sublabels,featLabels)
return myTree
def majorityCnt(classList):
"""计算哪一个类最多的"""
classCount = {}
for vote in classList:
if vote not in classCount.keys():classCount[vote] = 0
classCount[vote] += 1
# 排序后的结果
sortedclassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedclassCount[0][0]
def chooseBestFeatureToSplit(dataset):
numFeatures = len(dataset[0]) - 1
baseEntropy = calcShannonEnt(dataset)
# 最好的信息增益
bestInfoGain = 0
# 最好的特征
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataset]
uniqueVals = set(featList)
newEntropy = 0
for val in uniqueVals:
subDataSet = splitDataSet(dataset,i,val)
prob = len(subDataSet)/float(len(dataset))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def splitDataSet(dataset,axis,val):
retDataSet = []
for featVec in dataset:
if featVec[axis] == val:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def calcShannonEnt(dataset):
"""最开始时候的熵值"""
numexamples = len(dataset)
labelCounts = {}
# 先进行统计
for featVec in dataset:
currentlabel = featVec[-1]
if currentlabel not in labelCounts.keys():
labelCounts[currentlabel] = 0
labelCounts[currentlabel] += 1
shannonEnt = 0
for key in labelCounts:
prop = float(labelCounts[key])/numexamples
shannonEnt -= prop*log(prop,2)
return shannonEnt
- 画图操作
def getNumLeafs(myTree):
numLeafs = 0
firstStr = next(iter(myTree))
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = next(iter(myTree))
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
arrow_args = dict(arrowstyle="<-")
#font = FontProperties(fname=r"c:\windows\fonts\simsunb.ttf", size=14)
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)#, FontProperties=font
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree)
firstStr = next(iter(myTree))
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
plotTree(secondDict[key],cntrPt,str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
#清空fig
fig.clf()
axprops = dict(xticks=[], yticks=[])
#去掉x、y轴
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
#获取决策树叶结点数目
plotTree.totalW = float(getNumLeafs(inTree))
#获取决策树层数
plotTree.totalD = float(getTreeDepth(inTree))
#x偏移
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0
#绘制决策树
plotTree(inTree, (0.5,1.0), '')
plt.show()
- 具体实现
if __name__ == '__main__':
# 获取数据
dataset,labels = createDataSet()
featLabels = []
mytree = createTree(dataset, labels, featLabels)
createPlot(mytree)
- 结果展示