
作者:韩信子@ShowMeAI
深度学习实战系列:https://www.showmeai.tech/tutorials/42
PyTorch 实战系列:https://www.showmeai.tech/tutorials/44
本文地址:https://www.showmeai.tech/article-detail/324
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容
如今 AI 艺术创作能力越来越强大,在艺术作画上表现也异常惊人,大家在ShowMeAI的文章 AI绘画 | 使用Hugging Face发布的diffuser模型快速绘画 和 AI绘画 | 使用Disco Diffusion基于文本约束绘画 了解新技术进展和 AI 作画效果展示,其中 OpenAI 的 DALL-E 2 和 Google 的 ImageGen 等项目基于文本提示作画的结果和真实艺术家的成品难辨真假。
但上述效果好的大厂项目通常是付费而非开源的,即使有少数开源项目,也远远超出了本地电脑的计算能力(至少对于那些电脑没有 GPU 的宝宝来说)。 本篇我们用不同于 diffuser 模型的另外一种方法:GAN(生成对抗网络)来完成AI作画。
本篇内容中ShowMeAI将带大家来使用 GAN 生成对抗网络完成莫奈风格作画。
GAN简介
我们本篇使用到的技术是GAN,中文名是『生成对抗网络』,它由两个部分组成:
- 生成器:『生成器』负责生成所需的内容(在当前场景下是图像),未经训练的生成器随机生成的效果类似噪声,但随着训练过程推进,生成器会产出越来越逼真的结果,直至『判别器』无法分辨真实图像与AI绘制的图像。
- 判别器:『判别器』负责监督生成器学习,它将真实图像与生成器生成的图像进行比较,检测和分辨真假。随着训练过程推进,它越来越有分辨能力,并督促生成器不断优化。
下图是一个简易的 GAN 示意图:
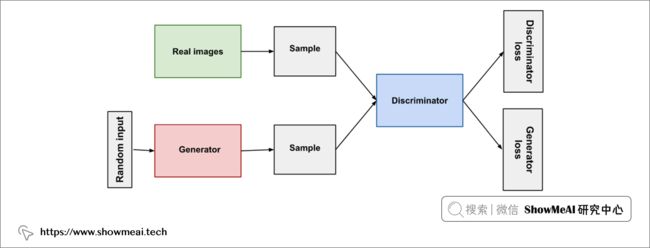
自2014年第一个 GAN 被研究者提出,经过多年它已经有非常长足的进步,产生越来越好的结果。在本教程中,ShowMeAI将基于 Pytorch 基础上的一个 GAN 工具库 torchgan 完成一个 DCGAN 并应用于莫奈风格的图像绘制任务上。

数据集&数据处理
本篇使用到的数据集来源于著名大师莫奈的画作,我们基于这些优秀的画作,让神经网络学习和尝试产生类似的内容。法国画家 克劳德·莫奈 生活在 19 世纪,他的画作可以在 https://www.wikiart.org/en/claude-monet 获取。
因为希望模型学习到的信息更充分,我们还扩充使用了很多类似大师风格的图像,更大的数据量可以使训练过程更容易。我们人类有很多背景知识先验知识,例如天空是蓝色的,树木是绿色的,但从神经网络的角度来看,任何图像都只是一个 RGB 数组,更多的数据可以帮助它们掌握这些基本规律。

关于数据处理与神经网络的详细原理知识,大家可以查看ShowMeAI制作的深度学习系列教程和对应文章
不过,即使采用了外观相似的图像,数据量依旧有点小。我们将使『数据增强』技术——它通过对图像的变换来构建新的图像达到数据扩增的效果。
我们创建一个自定义 Dataset 类,借助于 pytorch 的 transforms 功能,可以轻松完成数据扩增中的各种变换:
import torch.nn as nn
import torch.utils.data as data
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import torchvision.utils as vutils
from PIL import Image
import globimg_size = 256
class ImagesDataset(data.Dataset):
def __init__(self, images_path: str):
self.files = glob.glob(images_path)
self.images = [None] * self.__len__()
def __len__(self):
return 1000
def __getitem__(self, index):
if self.images[index] is None:
self.images[index] = self.generate_image()
return self.images[index]
def generate_image(self):
index = random.randint(0, len(self.files) - 1)
img = Image.open(self.files[index]).convert('RGB')
transform = transforms.Compose(
[transforms.Resize(img_size + img_size//2),
transforms.RandomCrop(img_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()])
resized = transform(img)
return resized, index上面的代码中,我们将所有图像调整为稍大的尺寸,然后应用随机裁剪和翻转构建新的输出图像。 对于莫奈的画,只使用了水平翻转和裁剪比较稳妥,但对于现代艺术样本,垂直翻转或随机旋转可能也是适用的。
我们随机取一点数据集,做可视化和验证有效性:
import torchvision.utils as vutils
import matplotlib.pyplot as plt
def show_images(batch):
plt.figure(figsize=(12, 12))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(batch, padding=2,
normalize=True).cpu(), (1, 2, 0)))
plt.show()dataset = ImagesDataset(images_path="Paintings/Monet/*.png")
dataloader = data.DataLoader(dataset, batch_size=batch_size,
shuffle=True)
batch = next(iter(dataloader))
show_images(batch[0][:64])运行代码后,我们可以看到如下结果:
莫奈创作了大约 2500 幅画作,当然完整的画作集中可能会包含不同的内容物,大家看可以稍作筛选。
构建神经网络
我们准备好数据集后,下一步就开始创建神经网络模型了。我们基于 torchgan 工具库,构建 GAN 并不复杂:
import torch
from torchgan.models import *
from torchgan.losses import *
dcgan_network = {
"generator": {
"name": DCGANGenerator,
"args": {
"encoding_dims": 100,
"step_channels": 40,
"out_channels": 3,
"out_size": img_size,
"nonlinearity": nn.LeakyReLU(0.3),
"last_nonlinearity": nn.Tanh()
},
"optimizer": {"name": Adam,
"args": {"lr": 0.0005, "betas": (0.5, 0.999)}}
},
"discriminator": {
"name": DCGANDiscriminator,
"args": {
"in_channels": 3,
"in_size": img_size,
"step_channels": 40,
"nonlinearity": nn.LeakyReLU(0.3),
"last_nonlinearity": nn.LeakyReLU(0.2)
},
"optimizer": {"name": Adam,
"args": {"lr": 0.0006, "betas": (0.5, 0.999)}}
}
}
lsgan_losses = [LeastSquaresGeneratorLoss(),
LeastSquaresDiscriminatorLoss()]我们通过配置的方式,通过字典对网络结构和参数进行了设置。我们这里定义的DCGAN模型包含一个生成器 DCGANGenerator 和一个判别器 DCGANDiscriminator 。
下一步我们训练网络:
# 使用GPU或者CPU
if torch.cuda.is_available():
device = torch.device("cuda:0")
torch.backends.cudnn.deterministic = True
else:
device = torch.device("cpu")batch_size = 64
# 迭代轮次
epochs = 2000
# 训练器
trainer = Trainer(dcgan_network, lsgan_losses,
sample_size=batch_size, epochs=epochs,
device=device,
recon="./torchgan_images",
checkpoints="./torchgan_model/gan2",
log_dir="./torchgan_logs",
retain_checkpoints=2)
# 训练
trainer(dataloader)
trainer.complete()上述代码中涉及的参数都可以调整,每一轮训练后会在 torchgan_images 文件夹中生成图像样本,训练得到的模型保存在 torchgan_model 文件夹中(模型文件不小,对于 256x256 的小尺寸图像,它的大小约为 440M Bytes),但我们仅在磁盘上保留最后 2 个模型 checkpoint。
训练过程中的中间数据日志记录在 torchgan_logs 文件夹下,我们可以通过 TensorBoard 工具实时查看训练中间状态,只需要运行 tensorboard -logdir torchgan_logs 命令即可,运行后我们可以在浏览器界面的 http://localhost:6006 URL中查看中间训练过程,如下图所示:

训练与优化
GAN的训练过程是比较缓慢的,大家可能需要一些耐心。 GeForce RTX 3060 显卡 GPU + Ryzen 9 CPU 的设备上,对尺寸为 256x256 的图像数据集进行 2000 次训练大约需要 4 小时。
整个训练过程中,可以看到神经网络逐步生成越来越好的图像,我们把不同阶段的生产效果做成动图,如下所示:
有兴趣大家可以试着调整一下输入参数,也可以采集和提供更多的训练图片,效果可能会更好。
总结
对比之前 ShowMeAI 提到过的 diffuser 模型,我们这里使用 DALL-E Mini 的在线版本 也生成了莫奈画作的图像,如下所示:
我们的DCGAN代码生成的结果分辨率会弱一点:
DALL-E Mini 的模型结构做过调整,且在数百万张图像进行过训练,比我们几个小时训练完的小模型效果好是正常的。大家如果采集更多的数据,尝试不同模型参数,结果可能会更好,快来一起试一试吧。
参考资料
- AI绘画 | 使用Hugging Face发布的diffuser模型快速绘画:https://www.showmeai.tech/article-detail/312
- AI绘画 | 使用Disco Diffusion基于文本约束绘画:https://www.showmeai.tech/article-detail/313
- 克劳德·莫奈:https://en.wikipedia.org/wiki/Claude_Monet
- Claude Monet 画作:https://www.wikiart.org/en/claude-monet
- 深度学习教程:吴恩达专项课程 · 全套笔记解读:https://www.showmeai.tech/tutorials/35
- 深度学习教程 | 深度学习的实用层面:https://www.showmeai.tech/article-detail/216
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读:https://www.showmeai.tech/tutorials/37
- 深度学习与CV教程(7) | 神经网络训练技巧 (下) :https://www.showmeai.tech/article-detail/266
- torchgan:https://github.com/torchgan/torchgan
- DALL-E Mini 的在线版本:https://huggingface.co/spaces/dalle-mini/dalle-mini
