AXI-Stream-Interconnect 学习及仿真
学习环境
win10 64bit
vivado 2016.4
modelsim 10.6d
KC705开发板
学习目的
1)理解 AXI-Stream-interconnect 用法。
2)理解 AXI-Stream-interconnect ip core 各个参数的作用。
IP 简介
内部框图
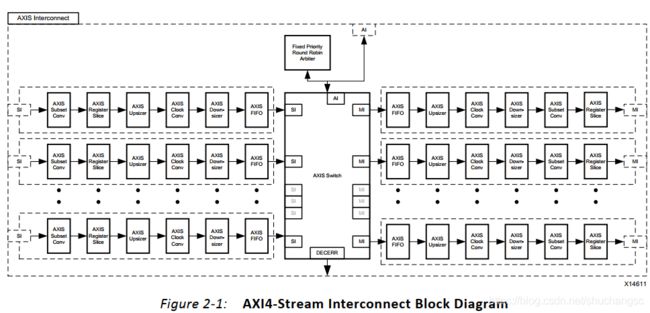
子模块说明
延迟特性


最高频率
pg085文件中的各AXI4-Stream IP核的最大频率可以达到250 MHz。对于某些-2或者-3速度等级的元器件,最大频率能够提高5% - 10%。但是对于AXI4-Stream Switch,当配置超过大概4个master或者slave时,支援的最大频率会降低20-25%。
吞吐量计算

user guide
各个通道复位必须与对应通道时钟同步,从而避免亚稳态产生。

reset时,终端们将TREADY和TVALID信号置为低电平,应该保证在8个时钟周期内。而ARESETn信号应该保持至少16个时钟周期,从而确保系统内的其他都能进入reset状态,并在reset状态结束前有时间去将它们的TREADY和TVALID输出信号置为低。
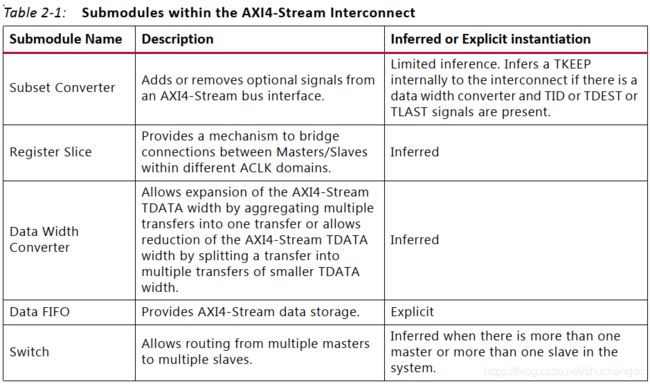
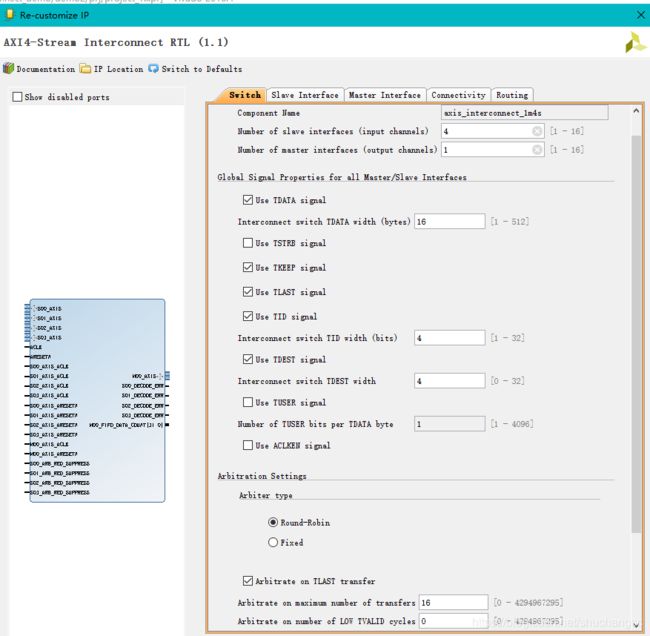
Arbitration Settings
ip core配置界面如下:
datasheet说明如下

arbitration setting 只有在slave接口数多于1时才支持修改。 而每个master接口,都有个单独的仲裁模块,来处理多种输入的请求报文。
Arbitrate on TLAST transfer
选中此项,检测到 switch的从slave 接口到 master 接口 传输报文的TLAST,表示一次事务完成。权限交给下一个仲裁winner。
Arbitrate on maximum number of transfers

此设置指定 放弃 granted arbitration之前,可以传输多少数据。 如果设置为0,则一次仲裁可以无限传输,但是 Arbitrate on TLAST transfer 必须使能。 如果设置为0, 则一次传输之后,switch放弃 control和request给下一个仲裁。
Arbitrate on number of LOW TVALID cycles

信号定义

AXIS_TID : 数据流ID指示,用于区分不同的数据流。
AXIS_TDEST : 数据流路由信息,(不清楚与TID有啥区别??????)
ARB_REQ_SUPPRESS : 置高,此通道不接受下一次仲裁, 如果这个bus已经是获得仲裁权限状态的话,它会保持被允许状态直到仲裁周期结束。
DECODE_ERR : 表示刚接收到的传输中的TDEST值没有匹配到任何一个master,然后丢弃这个传输;仅在TDEST模式中存在.
仿真
仿真模型
目标搭建下图的仿真模型,首先例化 AXI-Stream-interconnect 的ip core。
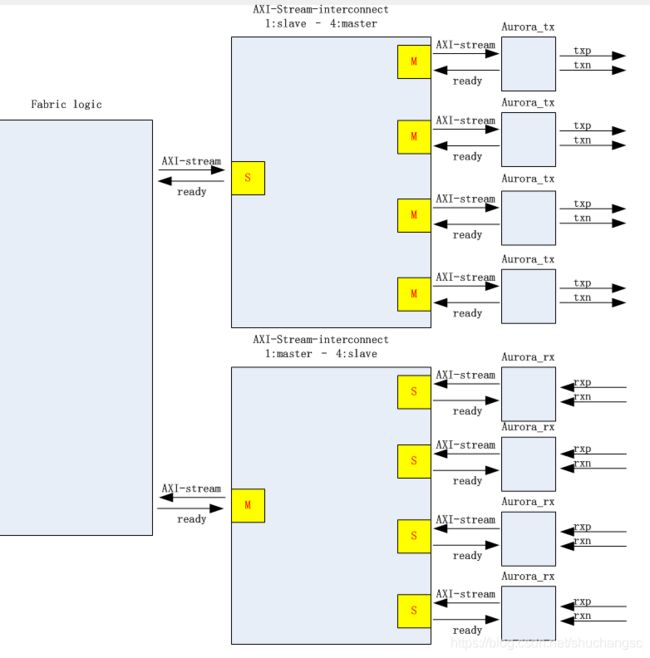
aurora发送方向仿真
选择 AXI4-Stream interconnect RTL ,弹出ip core设置如下, 这里switch 位宽设置为16byte,
slave位宽16byte, master位宽8byte, 整个系统共用时钟源156.25Mhz。

slave 的ready 与 mater位宽关系
1.axis-interconnect 1:slave - 4:master , switch位宽128bit,slave位宽128bit, master位宽64bit。

2.interconnect switch 位宽= 32byte, S_TDATA= 32byte, M_TDATA = 8byte, ready 仿真波形。

slave 的ready 与 slave DATA FIFO关系
1.interconnect_1s4m, 增加slave DATA FIFO 深度, TREADY能保证开始连续缓存的数据更多,当减小DATA FIFO深度时,TREADY连续缓存数据的数据量变小。(master DATA FIFO 未使能)


2.DATA FIFO深度从256改为64后,连续缓存的数据变少。(master DATA FIFO 未使能)


2.DATA FIFO深度为64后,FIFO_DATA_COUNT = 0X40 时,TREADY开始翻转, 即DATA FIFO满时,控制TREADY翻转,来抑制入口流量。
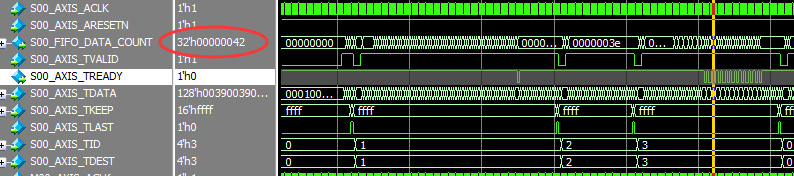
slave 的ready 与 master DATA FIFO关系


从仿真结果上看,增加slave 和 master的 DATA FIFO深度,都会对吞吐量有影响。顺带提一句,DATA FIFO使能后,FIFO Depth为16或32时,内部使用LUT实现FIFO, FIFO Depth 大于或等于64时,内部使用BLOCK RAM实现。
DATA FIFO Mode比较

master0 axis仿真结果:

master1 axis仿真结果:
![]()
master2 axis仿真结果:

master3 axis仿真结果:

对比4个master接口的 TVALID生效时,对应FIFO_DATA_COUNT的值,FIFO mode为normal时,收到3个数据,master就开始输出数据, 而FIFO mode为packet时,收到一个完整的packet,master才开始输出数据。
aurora接收方向仿真
Arbitrate on maximum number of transfers
axis_interconnect_1m4s, Arbitrate on maximum number of transfers = 1

传输一个数据,就转交权限给下一个通道。
axis_interconnect_1m4s, Arbitrate on maximum number of transfers = 16


1)传输不足16个数据,用TLAST触发仲裁权限转交,对应第一个图,master发送 slave2 -> slave0 -> slave1 ,通过last信号来转移发送权限。
2)报文长度大于16时,传输到16个数据时,转交仲裁权限。对应第二个图,slave2发送了16个数据后,开始发送slave3的数据。
testbench已上传,有需要可以下载参考, AXI4-Stream-Interconnect testbench.