数据预处理之归一化/标准化/正则化/零均值化
数据预处理之归一化/标准化/正则化/零均值化
- 一、标准化(Standardization)
- 二、归一化(Normalization)
- 三,中心化/零均值化 (Zero-centered)
- 四、正则化
- 五, boxcox变换
- 六, 非线性归一化
-
- sigmoid变换(sigmoid函数)
- softmax变换(softmax函数)
- 七,标准化(Standardization)与归一化(Normalization)的联系和差异
-
- 1. 联系
- 2. 差异
- 3. 什么时候使用
- 4. 是否所有情况都用Standardization或Normalization
- 其它
一、标准化(Standardization)
统计学中叫Z-Score
将数据变换为均值μ为0,标准差σ为1的分布切记,并非一定是正态的;
将数据按期属性(按列进行)减去其均值,并处以其方差。得到的结果是,对于每个属性/每列来说所有数据都聚集在0附近,方差为1。
实现时,有两种不同的方式:
- 使用sklearn.preprocessing.scale()函数,可以直接将给定数据进行标准化。
from sklearn import preprocessing
import numpy as np
X = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
X_scaled = preprocessing.scale(X)
print(X_scaled)
# 处理后数据的均值和方差
print(X_scaled.mean(axis=0))
print(X_scaled.std(axis=0))
[[ 0. -1.22474487 1.33630621]
[ 1.22474487 0. -0.26726124]
[-1.22474487 1.22474487 -1.06904497]]
[0. 0. 0.]
[1. 1. 1.]
- 使用sklearn.preprocessing.StandardScaler类,使用该类的好处在于可以保存训练集中的参数(均值、方差)直接使用其对象转换测试集数据。
from sklearn import preprocessing
import numpy as np
X = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
scaler = preprocessing.StandardScaler().fit(X)
print(scaler)
print(scaler.mean_)
#print(scaler.std_)
scaler.transform(X)
# 可以直接使用训练集对测试集数据进行转换
print(scaler.transform([[-1., 1., 0.]]))
StandardScaler(copy=True, with_mean=True, with_std=True)
[1. 0. 0.33333333]
[[-2.44948974 1.22474487 -0.26726124]]
得到的结果分布和原分布是一样的。不一定是标准正态分布。
标准化的目的是统一规格。使大家都在同一个量纲上。不至于一个特征的量纲过大而导致整个模型无法收敛。
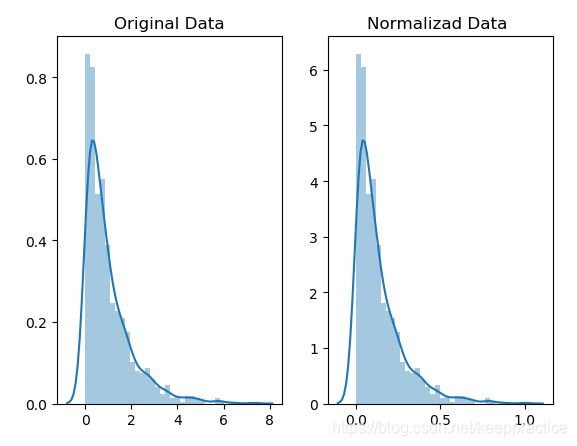
代码举例说明标准化后不一定是标准正态分布
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
original_data = np.random.exponential(size =1000)
normalizad_data = (original_data- original_data.mean())/original_data.std()
fig, ax = plt.subplots(1, 2)
sns.distplot(original_data, ax= ax[0])
ax[0].set_title("Original Data")
sns.distplot(normalizad_data, ax= ax[1])
ax[1].set_title("Normalizad Data ")
plt.show()

二、归一化(Normalization)
将一列数据变化到某个固定区间(范围)中,通常,这个区间是[0, 1],广义的讲,可以是各种区间,比如映射到[0,1]一样可以继续映射到其他范围,图像中可能会映射到[0,255],其他情况可能映射到[-1,1];
Mean normalization:


这种方法是将属性缩放到一个指定的最大和最小值(通常是1-0)之间,这可以通过preprocessing.MinMaxScaler类实现。
使用这种方法的目的包括:
1、对于方差非常小的属性可以增强其稳定性。
2、维持稀疏矩阵中为0的条目。
from sklearn import preprocessing
import numpy as np
X_train = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
min_max_scaler = preprocessing.MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(X_train)
print(X_train_minmax)
# 将相同的缩放应用到测试集数据中
X_test = np.array([[-3., -1., 4.]])
X_test_minmax = min_max_scaler.transform(X_test)
print(X_test_minmax)
# 缩放因子等属性
print(min_max_scaler.scale_)
print(min_max_scaler.min_)
[[0.5 0. 1. ]
[1. 0.5 0.33333333]
[0. 1. 0. ]]
[[-1.5 0. 1.66666667]]
[0.5 0.5 0.33333333]
[0. 0.5 0.33333333]
当然,在构造类对象的时候也可以直接指定最大最小值的范围:feature_range=(min, max),此时应用的公式变为:
X_std=(X-X.min(axis=0))/(X.max(axis=0)-X.min(axis=0))
X_scaled=X_std/(max-min)+min
代码举例说明标准化后不一定是标准正态分布
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
original_data = np.random.exponential(size =1000)
normalizad_data = (original_data- original_data.mean())/original_data.std()
fig, ax = plt.subplots(1, 2)
sns.distplot(original_data, ax= ax[0])
ax[0].set_title("Original Data")
sns.distplot(normalizad_data, ax= ax[1])
ax[1].set_title("Normalizad Data ")
plt.show()
三,中心化/零均值化 (Zero-centered)
另外,还有一种处理叫做中心化,也叫零均值处理,就是将每个原始数据减去这些数据的均值。
x ′ = x − μ x' = x - μ x′=x−μ
四、正则化
正则化的过程是将每个样本缩放到单位范数(每个样本的范数为1),如果后面要使用如二次型(点积)或者其它核方法计算两个样本之间的相似性这个方法会很有用。
正则化主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后样本的p-范数(l1-norm,l2-norm)等于1。
L1 norm 是指对每个样本的每一个元素都除以该样本的L1范数.
L2 norm 是指对每个样本的每一个元素都除以该样本的L2范数.
p-范数的计算公式: ∣ ∣ X ∣ ∣ p = ( ∣ x 1 ∣ p + ∣ x 2 ∣ p + . . . + ∣ x n ∣ p ) 1 / p ||X||p=(|x1|^p+|x2|^p+...+|xn|^p)^{1/p} ∣∣X∣∣p=(∣x1∣p+∣x2∣p+...+∣xn∣p)1/p
该方法主要应用于文本分类和聚类中。例如,对于两个TF-IDF向量的l2-norm进行点积,就可以得到这两个向量的余弦相似性。
1、可以使用preprocessing.normalize()函数对指定数据进行转换:
from sklearn import preprocessing
import numpy as np
x = np.array([[1.,-1.,2.],
[2.,0.,0.],
[0.,1.,-1.]])
x_normalized = preprocessing.normalize(x, norm='l2', copy=True)
print(x_normalized)
#y = np.sqrt(x)
y = np.square(x)
y = np.sum(y, axis=1)
y = np.sqrt(y)
y = y[:, np.newaxis]
print(y)
print(x/y)
[[ 0.40824829 -0.40824829 0.81649658]
[ 1. 0. 0. ]
[ 0. 0.70710678 -0.70710678]]
[[2.44948974]
[2. ]
[1.41421356]]
[[ 0.40824829 -0.40824829 0.81649658]
[ 1. 0. 0. ]
[ 0. 0.70710678 -0.70710678]]
2、可以使用processing.Normalizer()类实现对训练集和测试集的拟合和转换:
from sklearn import preprocessing
import numpy as np
x = np.array([[1.,-1.,2.],
[2.,0.,0.],
[0.,1.,-1.]])
normalizer = preprocessing.Normalizer().fit(x) # fit does nothing
print(normalizer)
print(normalizer.transform(x))
print(normalizer.transform([[-1., 1., 0.]]))
Normalizer(copy=True, norm='l2')
[[ 0.40824829 -0.40824829 0.81649658]
[ 1. 0. 0. ]
[ 0. 0.70710678 -0.70710678]]
[[-0.70710678 0.70710678 0. ]]
补充:

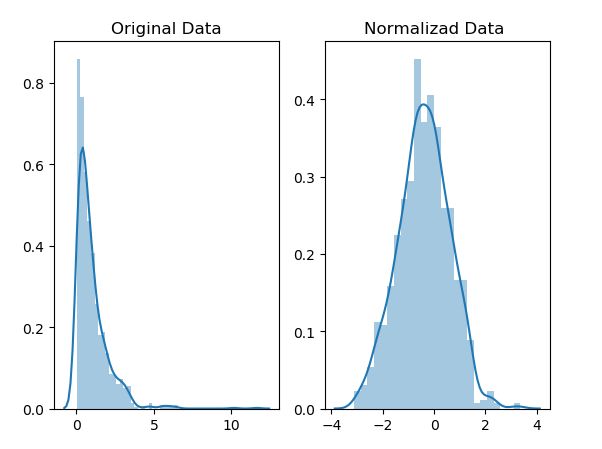
五, boxcox变换
对数据的分布的进行转换,使其符合某种分布(比如正态分布)的一种非线性特征变换。
来自百度百科

import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
original_data = np.random.exponential(size =1000)
normalizad_data = stats.boxcox(original_data)[0]
fig, ax = plt.subplots(1, 2)
sns.distplot(original_data, ax= ax[0])
ax[0].set_title("Original Data")
sns.distplot(normalizad_data, ax= ax[1])
ax[1].set_title("Normalizad Data ")
plt.show()
六, 非线性归一化
sigmoid变换(sigmoid函数)
![]()
softmax变换(softmax函数)
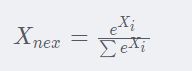
七,标准化(Standardization)与归一化(Normalization)的联系和差异
1. 联系
Standardization和Normalization本质上都是对数据的线性变换,广义的说,你甚至可以认为他们是同一个母亲生下的双胞胎,为何而言,因为二者都是不会改变原始数据排列顺序的线性变换:
假设原始数据为X ,
令 α = X m a x − X m i n α =X_{max}-X_{min} α=Xmax−Xmin and β = X m i n β = X_{min} β=Xmin 很明显,数据给定后α 、 β就是常数),
则 X = X i − β α = X i α − β α = X i α − c X =\frac{X_{i}-\beta}{\alpha}=\frac{X_{i}}{\alpha}-\frac{\beta}{\alpha}=\frac{X_{i}}{\alpha}-c X=αXi−β=αXi−αβ=αXi−c
可见Normalization是一个线性变换,按α进行缩放,然后平移c个单位。
其实 X i − β α \frac{X_{i}-\beta}{\alpha} αXi−β中的β 和α 就像是Standardization中的μ和σ(数据给定后,μ和σ也是常数)。线性变换,必不改变原始的排位顺序。
2. 差异
- Normalization会严格的限定变换后数据的范围,比如按之前最大最小值处理的Normalization,它的范围严格在[0,1]之间; 而Standardization就没有严格的区间,变换后的数据没有范围,只是其均值是0,标准差为1。
- 归一化(Normalization)对数据的缩放比例仅仅和极值有关,就是说比如100个数,你除去极大值和极小值其他数据都更换掉,缩放比例 α = X m a x − X m i n α=X_{max}-X_{min} α=Xmax−Xmin是不变的;反观,对于标准化(Standardization)而言,它的α= σ,β = μ,如果除去极大值和极小值其他数据都更换掉,那么均值和标准差大概率会改变,这时候,缩放比例自然也改变了。
3. 什么时候使用
如果你对处理后的数据范围有严格要求,那肯定是归一化,个人经验,标准化是ML中更通用的手段,如果你无从下手,可以直接使用标准化;如果数据不为稳定,存在极端的最大最小值,不要用归一化。在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,标准化表现更好;在不涉及距离度量、协方差计算的时候,可以使用归一化方法。
PS:PCA中标准化表现更好的原因可以参考(PCA标准化)
4. 是否所有情况都用Standardization或Normalization
当原始数据不同维度特征的尺度(量纲)不一致时,需要标准化步骤对数据进行标准化或归一化处理,反之则不需要进行数据标准化。也不是所有的模型都需要做归一的,比如模型算法里面有没关于对距离的衡量,没有关于对变量间标准差的衡量。比如决策树,他采用算法里面没有涉及到任何和距离等有关的,所以在做决策树模型时,通常是不需要将变量做标准化的;另外,概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率。
其它
面试相关的。
标准化对逻辑回归有什么好处吗?
答案是有好处,进行标准化后,我们得出的参数值的大小可以反应出不同特征对样本label的贡献度,方便我们进行特征筛选。如果不做标准化,是不能这样来筛选特征的。
答到这里,有些厉害的面试官可能会继续问,做标准化有什么注意事项吗?
最大的注意事项就是先拆分出test集,不要在整个数据集上做标准化,因为那样会将test集的信息引入到训练集中,这是一个非常容易犯的错误!