基于改进yolov4和unet的飞机目标的分割
一篇之前写的分割图片中小飞机目标的论文,思路较简单,先用yolo目标检测框架提取出ROI再用Unet进行分割,最后融合。
摘要:航拍影像中飞机目标占图像比例往往较低,为了解决语义分割中对飞机目标分割存在效果差,准确性低的问题,提出一种基于改进的yolov4和unet结合的小目标分割方法。为了提高yolov4的训练速度,降低模型复杂度,使用mobilenet对yolov4主干网络进行改进,使用改进后的模型提取出图像中ROI区域,再将该区域送入vgg16-unet进行分割,最后将分割出的各个子目标和原图像进行融合,得到完整的分割图。采用RSOD-Dataset作为训练数据集,使用UCAS-AOD数据集验证模型泛化能力,实验表明,该模型对图像中飞机目标有良好的分割效果。
关键字:Yolov4,unet,mobilenet
引言:近年来随着深度神经网络在目标检测,分割,分类等方向的成功应用,展示出其提取特征的强大能力。和分类,检测等任务不同的是,语义分割在于实现从像素到像素的映射,将图像逐像素进行分类,从而将需要识别的物体与背景分割开来,在医学图像,无人驾驶等方向有广泛应用。语义分割分包括监督分割、无监督分割、半监督分割等。在深度神经网络兴起之前,一般使用像素级的决策树分类来设计分割分类器,例如TextonForest和Random Forest。在2014年,加州大学伯克利分校的Long等推广了原有CNN结构,首先使用FCN对图像进行端到端的分割,并去掉了全连接层,实现了对像素的密集分类,使语义分割技术取得重大突破,后续提出的语义分割模型绝大部分均基于该结构。另一方面,使用FCN虽然能较好的提取特征并增加感受野,但丢失了像素的位置信息,忽视了像素间的关系,分割精度和空间一致性较差。
为了改进FCN存在的以上问题,pspnet融合了金字塔模块来聚合图片信息,segnet改进了解码过程中上采样的方式,unet在多尺度上提取特征,并通过拼接而不是相加的方式进行特征融合,DeepLab融合了空洞卷积与条件随机场,以及空间金字塔池化模块(ASPP)。这些模型通过融合上下文包含的语义信息,多尺度特征提取等方式达到了优秀的分割效果。也促进了图像分割在地物目标分割中的应用。为了解决对飞机目标进行语义分割时存在分割不准确,精度低的问题,本文采用改进的yolov4模型和unet相结合的方式,将端到端的深度学习方法应用到较小飞机目标检测中,在提高模型速度和降低复杂度的同时,较好的提高分割准确度。
- 改进的Yolov4框架和unet结合的分割算法设计
本文算法主要涉及到三个模块,分别是改进后的yolov4模块,vgg16-unet模块,以及图像融合模块。改进后的yolov4模块负责检测出原始图像中目标的位置,将其标记为ROI区域,剪裁出ROI区域的图像作为下一步vgg16-unet模块的输入,此时的ROI区域图像和原始图像相比尺寸大幅减少,并且目标物占整个图像的比例大幅提高,有利于进行进一步处理。由于原始图像中往往包含多个目标物,故每张图片会产生多个ROI区域图像,得到这些图像后分别送入vgg16-unet模型进行分割,由于该问题实际为图像像素的二分类问题,所以输出黑白二值图像作为分割结果,最后将所有分割好的ROI区域图像和原始图像送入图像融合模块进行融合,得到最终的分割结果。

传统YoloV4的整个结构包含三个部分。分别是主干特征提取网络(CSPdarknet53),用于获得三个初步有效特征层,加强特征提取网络(SPP和PANet)用于对三个初步有效特征层进行融合,得到三个更有效的特征层,预测网络(YoloHead)利用得到的特征进行预测。Mobilenet是谷歌提出的轻量级神经网络,其主要特点是使用了深度可分离卷积层。
为了减少模型复杂度,本文使用mobilenet网络替换yolov4原有的darknet53主干网络进行初步有效特征层的提取,使用mobilenet网络中提取到的三个特征层,替换darknet53输出的原有的三个特征层,替换后的网络参数量如下:
| Original yolov4 |
Mobilenetv1+yolov4 |
Mobilenetv2+yolov4 |
Mobilenetv3+yolov4 |
|
| Total params |
52,921,400 |
41,005,757 |
39,124,541 |
40,043,389 |
替换主干网络后的yolov4模型参数并没有明显减少,这是因为yolov4模型的大部分参数集中于用于提取加强特征的PANet部分,而对于PANet来说,其参数主要集中于其普通卷积层上,因此在这里近一步使用深度可分离卷积层来替换PANet和SPP中的普通卷积层,以此来进一步减少模型参数量。替换后的网络参数量如下:
| Original yolov4 |
mobilenetv1+yolov4 (depthwise_conv) |
Mobilenetv2+yolov4 (depthwise_conv) |
Mobilenetv3+yolov4 (depthwise_conv) |
|
| Total params |
52,921,400 |
12,754,109 |
10,872,893 |
11,791,741 |
经过测试,发现使用深度可分离卷积层的模型与仅使用mobilenet替换主干网络的模型相比,参数量大幅度的减小。我们最终使用Mobilenetv3+yolov4(depthwise_conv) 模型作为ROI区域检测的模型。其网络结构如下,yolov4中修改过的模块使用红框标出。

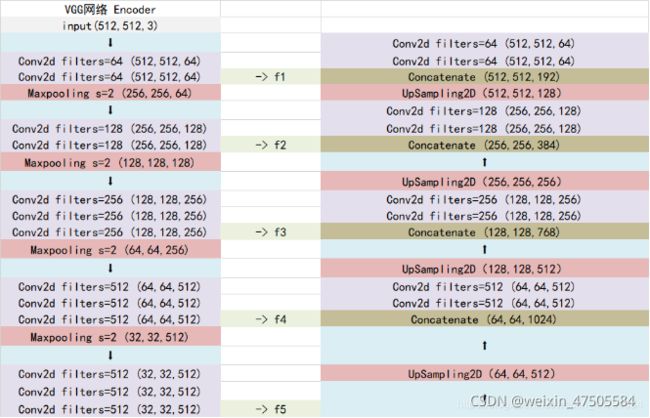
Unet模型结构简单且性能优异,使用较少的数据集就能得到较好的分割效果,其结构包括三个部分,首先是主干特征提取模块,通过对卷积层和最大池化层进行堆叠,得到五个初步有效特征层,其次是加强特征提取模块,利用上一步得到的五个初步有效特征层进行上采样和特种融合,最终得到一个融合了所有特征的特征层,最后是预测模块,利用融合好的特征层对每一个像素点进行分类,得到最终的分割结果。
Unet的主干特征提取部分整体结构与VGG网络类似,故本文使用主干网络为vgg16的unet模型对ROI区域图像进行目标物分割,通过迁移学习的方式,使用已有的预训练权重对模型进行训练。
- 模型测试与评估
深度神经网络模型的构建一般包括,数据采集,图像预处理,图像标记,数据增强,模型训练,模型评估等环节,数据增强可以有效提升模型的泛化能力,但经过测试,对本文使用的数据集进行数据增强并不能提升模型性能,故不采取模型增强策略。本文使用的训练平台为CPU:AMD3700x,GPU:RTX2070 SUPER,采用RSOD-Dataset作为训练数据集,包含446张机场航拍图像及其对应的xml标签文件,将原始图像和其对应标签生成Voc2007格式的数据集,送入改进的yolov4模型进行训练,训练集和验证集比例为9:1,得到不同batch_size的模型损失如下。
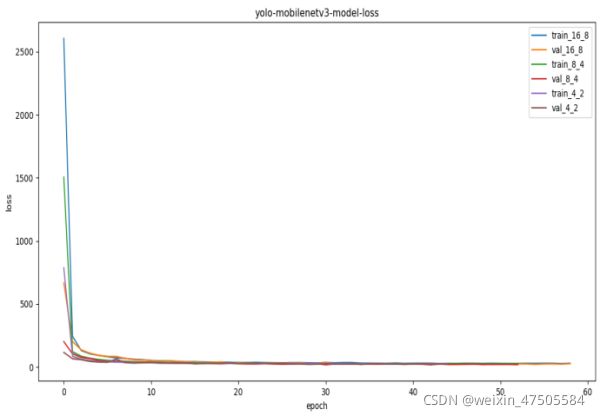
模型训练采用冻结学习的方式,通过在训练开始的前若干代冻结模型参数,防止模型参数在训练早期被破坏,同时防止模型过早收敛,从而提高模型的准确度,最终确定的最佳参数如下。
| Freeze |
Unfreeze |
|
| epoche |
50 |
50 |
| Batch_size |
4 |
2 |
| Lr |
0.001 |
0.0001 |
| Alpha |
1 |
1 |
在完成yolov4模型的训练之后,使用该模型进行对RSOD-Dataset数据集中的目标进行检测,并提取出ROI区域图像,从这些图像中随机抽取62张图片制作供unet模型使用的Voc2007格式数据集,送入vgg16-unet模型进行训练,训练集和验证集比例为9:1,同样采用冻结学习的方式冻结训练开始的若干代参数,并通过迁移学习的方式使用已有的针对unet网络进行优化的预训练权重,以此得到更好的性能,训练过程中不同batch_size下模型的损失率如下。
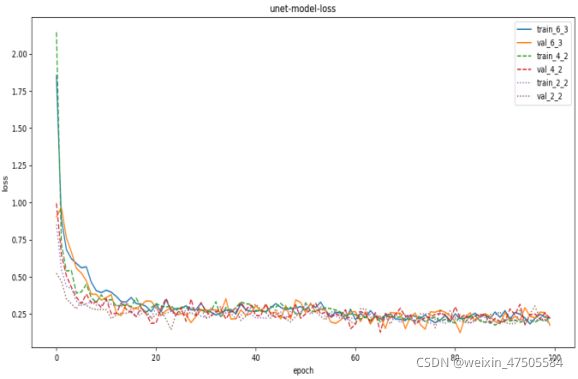
经过测试得到的最佳参数如下。
| Freeze |
Unfreeze |
|
| epoche |
50 |
50 |
| Batch_size |
4 |
2 |
| Lr |
0.0001 |
0.00001 |
| Loss_function |
Cross Entropy |
Cross Entropy |
语义分割问题一般使用MIoU指标对模型进行评估,即为真实值和预测值两个集合的交集和并集之比。

其中Pij表示真实值为i,被预测为j的数量, k+1是类别个数(包含空类)。Pii是真正true positive的数量。Pij、Pji则分别表示假正false positive和假负false negative。这里使用提取得到的ROI区域图像中的验证集图像来计算模型的MIoU指标,得到结果如下,可以看出模型的总体MIoU为83.62,其中对飞机分割的MIoU为68.95,说明模型具备较好的准确性。
| background |
Plane |
Overall MIoU |
|
| MIoU |
98.28 |
68.95 |
83.62 |
至此完成了对改进yolov4模型和unet模型的训练,为了验证模型的泛化能力,使用UCAS-AOD数据集进行测试,首先使用YOLOV4进行ROI区域提取。

随后将提取得到的ROI区域图像送入训练好的unet模型进行分割,并与原图进行融合,得到如下结果。在该测试数据集上取得了良好效果。

总结
鉴于语义分割在飞机目标分割中存在效果差,准确度低的问题,本文提出一种基于改进yolov4网络和unet模型相结合的分割算法,先使用yolov4模型提取图像ROI区域,再利用unet进行进一步分割,最后将得到的结果和原图进行融合。该算法具备结构简单,可行实现性强的特点,实验显示该算法能有很好的分割出较小的飞机目标。但该算法依然存在一些限制,例如最终效果很大依赖于yolov4模型的检测效果,若无法检测出飞机目标就无法进行后续分割,一些飞机分割边缘存在毛刺,空洞等,这些进行继续改进。
- Li Xiaojin,Qian Wenhua,Xu Dan,Liu Chunyu. Image Segmentation Based on Improved Unet[J]. Journal of Physics: Conference Series,2021,1815(1).
- Emek R. A.,Demir N.. BUILDING DETECTION FROM SAR IMAGES USING UNET DEEP LEARNING METHOD[J]. ISPRS - International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences,2020,XLIV-4/W3-2020.
- Z. Chu, T. Tian, R. Feng and L. Wang, "Sea-Land Segmentation With Res-UNet And Fully Connected CRF," IGARSS 2019 - 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 2019, pp. 3840-3843, doi: 10.1109/IGARSS.2019.8900625.
- Zhibin Cheng,Fuquan Zhang,Chao-Yang Lee. Flower End-to-End Detection Based on YOLOv4 Using a Mobile Device[J]. Wireless Communications and Mobile Computing,2020,2020.
- Jiao Libin,Huo Lianzhi,Hu Changmiao,Tang Ping. Refined UNet V2: End-to-End Patch-Wise Network for Noise-Free Cloud and Shadow Segmentation[J]. Remote Sensing,2020,12(21).
- Yue Cao,Shigang Liu,Yali Peng,Jun Li. DenseUNet: densely connected UNet for electron microscopy image segmentation[J]. IET Image Processing,2020,14(12).
- J. -Y. Sung, S. -B. Yu and S. -h. P. Korea, "Real-time Automatic License Plate Recognition System using YOLOv4," 2020 IEEE International Conference on Consumer Electronics - Asia (ICCE-Asia), Seoul, Korea (South), 2020, pp. 1-3, doi: 10.1109/ICCE-Asia49877.2020.9277050.
- . Incorporating DeepLabv3+ and object-based image analysis for semantic segmentation of very high resolution remote sensing images[J]. International Journal of Digital Earth,2021,14(3).
- Na Jiang, Jiyuan Li. An Improved Semantic Segmentation Method for Remote Sensing Images Based on Neural Network[J]. Traitement du Signal,2020,37(2).
- Youssef Wageeh,Hussam El-Din Mohamed,Ali Fadl,Omar Anas,Noha ElMasry,Ayman Nabil,Ayman Atia. YOLO fish detection with Euclidean tracking in fish farms[J]. Journal of Ambient Intelligence and Humanized Computing,2021(prepublish).