化妆品电商平台数据分析
一、背景和方法
本项目为ModelWhale平台每周挑战的一个业务分析类项目。根据给出的关于化妆品电商平台五个月数据,进行探索性分析。找到数据异常点,并尝试分析问题的原因、给出建议
所有分析过程大致遵循以下的流程:
* 自定义函数生成分析用数据框
* 自定义函数可视化
* 调用函数展示图标
* 根据图表分析问题
数据来源:https://www.heywhale.com/mw/dataset/6246e228e1d37c001704208d/file
1.1 整体分析思路及结论
使用python等相关库从以下角度进行探索性分析。使用多维度拆解方法和RFM分析方法进行分析。
(1)从总体营运角度,以不同的时间维度,对比流量、转化率、客单价、复购率等指标的表现。找出跟预期不符的异常时间段,分析可能的原因
(2)从商品维度,分析滞销品类和畅销品类
根据统计得到滞销品、滞销品、无销量的产品类别,如果有库存建议尽促销处理。
从畅销和滞销两个层面分析,为后续选品和优化库存提供支持
(3)根据RFM分析方法对用户精细化运营
选取重要发展客户为例,研究其在不同规的时间周期下的活跃规律,选择用户活跃时间点实施营销策路。同时研究其购物行为,针对有加入购物车的商品对用户采取专门的营销策略,促成最终的成交。
(4)针对一个异常点,探索性分析其原因
分析10月初购买转化率下降的原因。采用4p营销理论,分析原因可能是平台的促销活动是有针对性的。从RFM较角度划分这部分人群属于一般挽留和重要挽留客户,结合时间维度来看,应该是10月初的促销活动只针对新用户进行的。
(5)不足
该项目属于探索性分析,对业务指标的理解和对数据显示出来信息的捕捉会有不足的地方。后期随着会根据自己对业务理解的情况进行修改
针对异常点,只挑选了一个作为代表进行分析,没有具体业务数据,原因和建议仅供参考
二、数据整体初加工
(1)了解数据
* 读取并拼接5个原始数据表,得到9个字段,20692840行记录的数据框。
* 查看各个字段的数据类型,缺失值,重复值
* 查看了解用户行为的四种类别:'cart', 'view', 'remove_from_cart', 'purchase'。
* 查看时间数据的格式,需要处理
* 查看价格字段中小于等于0的情况
* 查看重复记录
(2)数据预处理
* 删除重复记录,1109098条
* 删除缺失值严重的字段category_code
* 判断字段price为单价,删除购买记录中价格小于等于0的记录
* 时间字段的格式转换
* 时间字段的数据提取:year(年)、month(月)、week(周)、year_month(年_月),hour(小时)
(3)最终数据框
* 数据由原来的20692840行减少到19583622行。保留率95%。保存为csv文件,方便后续调用
2.1 导入相关库
# 导入需要的包
import pandas as pd
import janitor
import numpy as np
from datetime import datetime
import warnings
#可视化相关包
import matplotlib.pyplot as plt
import plotly
import plotly.graph_objects as go
import plotly.express as px
from IPython.display import HTML
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from pyecharts.charts import Line,Funnel
from pyecharts.charts import Bar, Timeline
from pyecharts.commons.utils import JsCode
from mpl_toolkits.mplot3d import Axes3D
#解决pyecharts图表空白问题
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
CurrentConfig.ONLINE_HOST = 'https://assets.pyecharts.org/assets/'
#解决中文字体不显示,正负号不显示问题
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
warnings.filterwarnings('ignore')
%matplotlib widget2.2 数据初加工
2.2.1 数据导入、拼接、查看
#数据读取与拼接
df1 = pd.read_csv('2019-Oct.csv')
df2 = pd.read_csv('2019-Nov.csv')
df3 = pd.read_csv('2019-Dec.csv')
df4 = pd.read_csv('2020-Jan.csv')
df5 = pd.read_csv('2020-Feb.csv')
df = pd.concat([df1,df2,df3,df4,df5],ignore_index=True)
#删除数据释放内存
del df1 ,df2,df3,df4,df5
# 查看数据形状
df.shape
# 抽查一条记录,查看数据信息
# df.sample(2)
# 自定义函数,统计数据框各字段的信息:'总数','非空数', '缺失数', '缺失率','去重数'
def get_info(df):
# 提取数据框的字段名列表
index = df.columns.values.tolist()
# 需要统计的信息名称
columns = ['项目','总数','非空数', '缺失数', '缺失率','去重数']
info = []
# 将各个字段统计的数据添加到info列表中
for i in index:
info.append([i,df.shape[0],df[i].count(),df.shape[0]-df[i].count(),
round((df.shape[0]-df[i].count())/df.shape[0],2),
df[i].nunique()])
# 为字段名重新定义中文名
index_labels = ['时间','用户行为类别','产品id','产品类别id','产品类别编码'
,'商标','价格','用户id','用户会话']
# 将info列表转为数据框
df_info = pd.DataFrame(info,index=index_labels,columns=columns)
return df_info
# #调用自定义函数查看数据统计信息
get_info(df)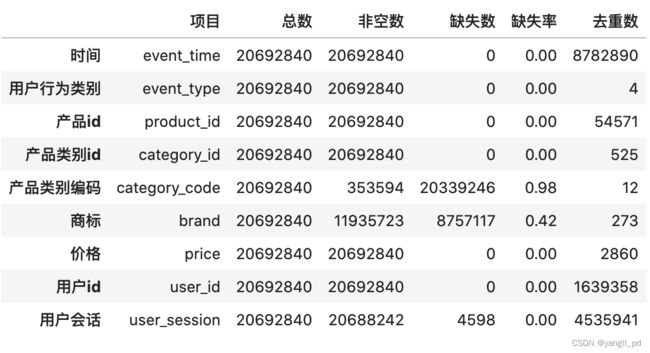
2.2.2 数据初加工
(1)price字段处理
# #用户行为类别:加入购物车,浏览,移除购物车,购买
# df['event_type'].unique()
# #查看重复值记录
# df[df.duplicated(keep=False)] #涉及2154860行
df.duplicated().sum() #1109098 条重复
## 删除重复数据
df = df.drop_duplicates()
print('所有记录中,price字段等于0的记录数量:')
print(df['price'][df['price']==0].count())
print('所有记录中,price字段小于0的记录数量:')
print(df['price'][df['price']<0].count())
print('购买行为的记录中price字段等于0的记录数量:')
print(df['price'][(df['event_type']=='purchase') & (df['price']==0)].count())#注意每条判断语句用小括号
print('购买行为的记录中price字段小于0的记录数量:')
print(df['price'][(df['event_type']=='purchase') & (df['price']<0)].count())
print('非购买行为的记录中price字段等于0的记录数量:')
print(df['price'][(df['event_type']!='purchase') & (df['price']==0)].count())
print('非购买行为的记录中price字段小于0的记录数量:')
print(df['price'][(df['event_type']!='purchase') & (df['price']<0)].count())
根据上面的统计,说明price字段是产品单价,\n所以接下来只删除购买行为记录中price字段为0和负数的记录
# #删除购买行为记录中price字段为0和负数的记录:120条记录
df = df[~((df['event_type']=='purchase') & (df['price']<=0))]
# #缺失值处理--删除category_code
df = df.drop('category_code',axis=1)(2)时间类型数据处理
df = (
df
.assign(event_time=lambda d:pd.to_datetime(d['event_time'].apply(lambda x:x.strip('UTC'))))
.assign(year=lambda d:d['event_time'].dt.year) #增加字段‘year'
.assign(month=lambda d:d['event_time'].dt.month)#增加字段‘month'
.assign(week=lambda d:d['event_time'].dt.dayofweek+1)#增加字段‘week'
.assign(y_m=lambda d:d['event_time'].astype('string').str.slice(0,7))#增加字段‘y_m'
.assign(hour=lambda d:d['event_time'].dt.hour) #增加字段‘hour'
.assign(weekofyear=lambda d:d['event_time'].dt.weekofyear) #增加字段‘weekofyear'
.assign(event_time=lambda d:pd.to_datetime(d['event_time'].astype('string').str.slice(0,10)))#年月日数据信息提取
)(3)处理后的数据保存和加载
df.shape#(19583622, 14)
# 加工数据保存
df.to_csv('./化妆品电商数据整体初加工.csv',index=False)
#加工数据读取
df = pd.read_csv('./化妆品电商数据整体初加工.csv',index_col=False,parse_dates=['event_time'])三、营运指标分析
流量相关指标
* PV(page view):浏览量
* UV(unique vistior):访客数(一段时间重复访问的只算一人)
* 平均访问深度(PV/UV)
成交指标
* 日/月成交金额,日/月成交用户数
效率指标
* 日/月客单价
客单价定义: 成交金额/ 成交用户数
客单价越高,支付买家数量一定的情况下,某产品的价值越高,或者某客户的价格高
分析流程
* 数据整理
* 数据可视化
* 问题总结
结论:
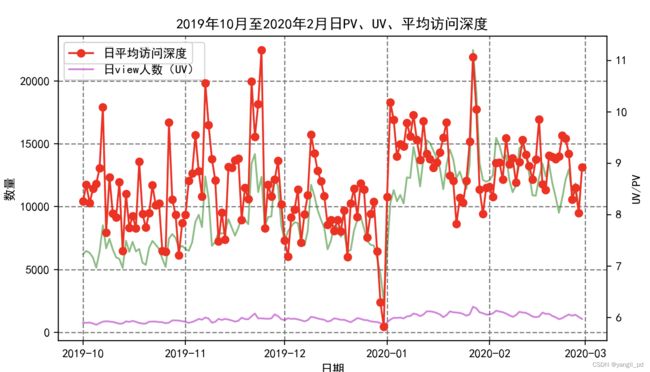
(1)从流量指标分析,有3个需要重点关注的时间段:
* 2019-10-1到8号,这几天的访客量大幅增加,平均访问深度却反而急剧减少。说明这段时间,有大量新的用户涌入,但是他们的浏览平均次数拉低了整体的访问深度,转化率也异常低下,属于营销失败。需要根据10月份营销活动的实际情况分析,找到导致访问深度以及cart到purchase这一环节转化率低的原因,总结经验教训。
* 2019年11月份的各方面指标表现正常,当月的营销活动比较成功。
* 2019年12月31日这天各方面的指标都急剧下降,需结合当天的具体情况分析原因
(2)客单价和效率指标分析,可以明显看到以下几个时间段的问题,具体如下:
* 2019年11月7号左右,每日购买人数暴增,客单价也有提升,活动效果理想
* 2019年11月21号左右,每日购买人数暴增,但是客单价一般
* 2019年12月31号左右,每日购买人数暴爹,客单价也不理想
* 2020年1月27号左右,购买人数暴增,客单价提升不明显
原因分析:连续的促销活动透支了客户的购买力,需结合当时业务分析具体原因
3.1 流量指标分析
3.1.1. 日流量指标分析
(1)自定义函数,统计每日不同的用户行为的总数量
# 数据准备
# 自定义函数,统计每日不同的用户行为的总数量
def table_day_liuliang(df):
# 提取用户行为的类别
type_list = df['event_type'].unique().tolist()
df = df[['user_id','event_time','event_type']]
user_analyse_day = pd.DataFrame(df['event_time'].unique(),columns=['event_time'])
#拼接每日不同的用户行为的总次数和总人数
for i in type_list:
user_analyse_day = pd.merge(user_analyse_day,
# 统计每日不同的用户行为的总次数
(
df[df['event_type']==i]
.groupby(['event_time'],as_index=False)
.count()
[['event_time','user_id']]
.rename(columns={'user_id':'日%s次数'%i})
),
on='event_time'
)
user_analyse_day = pd.merge(user_analyse_day,
#统计每日不同的用户行为的总人数
( df[df['event_type']==i]
.groupby(['event_time','user_id'],as_index=False)
.count()
.groupby('event_time',as_index=False)
.count()
[['event_time','user_id']]
.rename(columns={'user_id':'日%s人数'%i})
),
on='event_time'
)
return user_analyse_day(2)自定义函数可视化每日UV、PV、平均访问深度图
#可视化
#自定义函数可视化每日UV、PV、平均访问深度图
def figure_liuliang1(df):
data = table_day_liuliang(df)
fig = plt.figure(figsize=(10,6),dpi=100)
axe = fig.add_subplot(111)
axe.set_xlabel('日期')
axe.set_ylabel('数量')
axe.set_title('2019年10月至2020年2月日PV、UV、平均访问深度')
plt.grid(color='0.5',linestyle='--',linewidth=1)
axe.plot(data['event_time'],data['日view次数'],color='g',alpha=0.5,label='日view量(PV')
maxd = data[data['日view次数']==data['日view次数'].max()]['event_time'].apply(lambda x:x.strftime('%Y年%m月%d日')).values[0]
maxm = data[data['日view次数']==data['日view次数'].max()]['日view次数'].values[0]
plt.annotate(maxd,xy=('2019-11-22',maxm),xytext=('2019-12-01',100000),xycoords='data',
arrowprops=dict(facecolor='r',width=2,headwidth=5,shrink=8,headlength=4))
plt.plot(data['event_time'],data['日view人数'],color='m',alpha=0.5,label='日view人数(UV)')
mind = data[data['日view人数']==data['日view人数'].min()]['event_time'].apply(lambda x:x.strftime('%Y年%m月%d日')).values[0]
minm = data[data['日view人数']==data['日view人数'].min()]['日view人数'].values[0]
plt.annotate(mind,xy=('2019-12-31',minm+5000),xytext=('2019-11-20',10000),xycoords='data',
arrowprops=dict(facecolor='r',width=2,headwidth=5,shrink=8,headlength=4))
plt.legend()
axe1 = axe.twinx()
axe1.set_ylabel('UV/PV')
axe1.plot(data['event_time'],data['日view次数']/data['日view人数'],'r-o',label='日平均访问深度')
plt.legend(loc=2)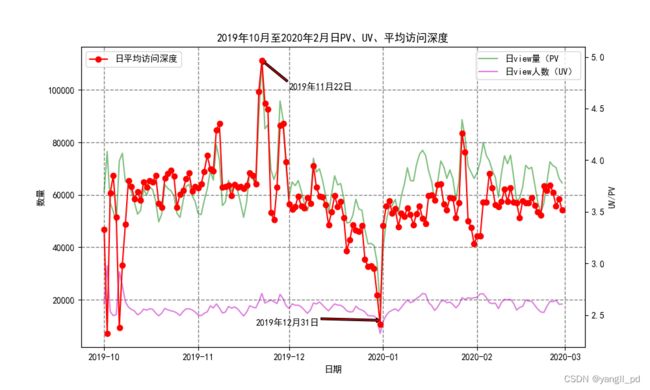
3.1.2. 月流量指标分析
(1)自定义函数,统计每月不同的用户行为的总数量
# 数据准备
# 自定义函数,统计每月不同的用户行为的总数量
def table_month_liuliang(df):
# 提取用户行为的类别
type_list = df['event_type'].unique().tolist()
df = df[['user_id','y_m','event_type']]
user_analyse_month = pd.DataFrame(df['y_m'].unique(),columns=['y_m'])
#拼接每月不同的用户行为的总次数和总人数
for i in type_list:
user_analyse_month = pd.merge(user_analyse_month,
#统计每月不同的用户行为的总次数
(df[df['event_type']==i]
.groupby('y_m',as_index=False)
.count()
[['y_m','user_id']]
.rename(columns={'user_id':'月%s次数'%i})
),
on='y_m'
)
user_analyse_month = pd.merge(user_analyse_month,
#统计每月不同的用户行为的总人数
( df[df['event_type']==i]
.groupby(['y_m','user_id'],as_index=False)
.count()
.groupby('y_m',as_index=False)
.count()
[['y_m','user_id']]
.rename(columns={'user_id':'月%s人数'%i})
),
on='y_m'
)
return user_analyse_month(2)自定义函数可视化月访问量、访客数、访问深度
#可视化
# 自定义函数可视化月访问量、访客数、访问深度
def figure_liuliang3(df):
data = table_month_liuliang(df)
fig = plt.figure(dpi=80)
axe = fig.add_subplot(111)
axe.set_xlabel('日期')
axe.set_ylabel('访客数/访问量')
axe.set_title('2019年10月至2020年2月月访客数/访问量/访问深度变化')
axe.plot(data['y_m'],data['月view人数'],'y-o',alpha=0.5,label='月view人数')
axe.plot(data['y_m'],data['月view次数'],'y-o',alpha=0.5,label='月view次数')
plt.legend(loc=6)
axe1 = axe.twinx()
axe1.set_ylabel('UV/PV')
axe1.plot(data['y_m'],data['月view次数']/data['月view人数'],'r-o',label='月平均访问深度')
plt.legend(loc=7)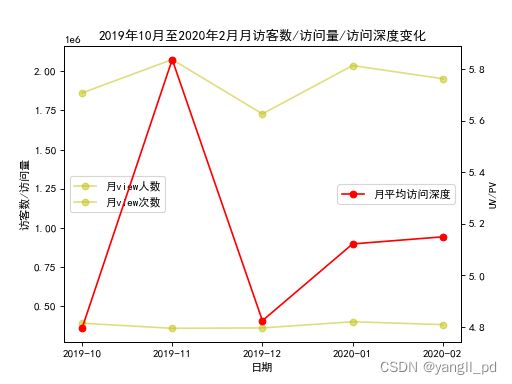
3.2. 转化率指标分析
3.2.1. 整体环节转化率
(1)自定义函数构建整体各环节人数及转化率表
# 数据准备
#自定义函数构建整体各环节人数及转化率表
#采用行为发生的人数来计算转化率
def table_zhuanhua(df):
m = []
for i in ['view','cart','purchase']:
num = df[df['event_type']==i]['user_id'].nunique()
m.append([i]+[num])
# print('%s人数:'%i)
# print(num)
df = (
pd.DataFrame(m,columns=['用户行为','人数'])
.assign(转化率类型=[np.nan,'view到cart','cart到purchase'])
.assign(转化率=lambda d:d['人数']/d['人数'].shift())
)
return df
#调用函数查看整体各环节人数及转化率表
table_zhuanhua(df)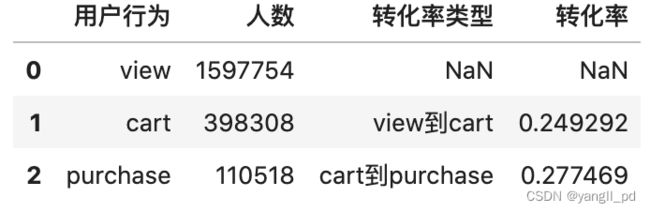
(2)可视化整体转化率
#可视化整体转化率
data = table_zhuanhua(df)
fig = go.Figure(go.Funnel(x=data['人数'],y=data['用户行为'],textposition = "inside",
textinfo = "value+percent previous",# 显示文本信息 ['label', 'text', 'percent initial', 'percent previous', 'percent total', 'value'] 前面选项的任意组合
opacity = 0.65,
marker = {"color": ["deepskyblue", "lightsalmon", "tan"], "line": {"width": [4, 2, 3, 1],
"color": ["wheat", "wheat", "blue"]}},
connector = {"line": {"color": "royalblue", "dash": "dot", "width": 3}}))
fig.update_layout(title='各阶段整体转化率',title_x=0.5)
HTML(fig.to_html())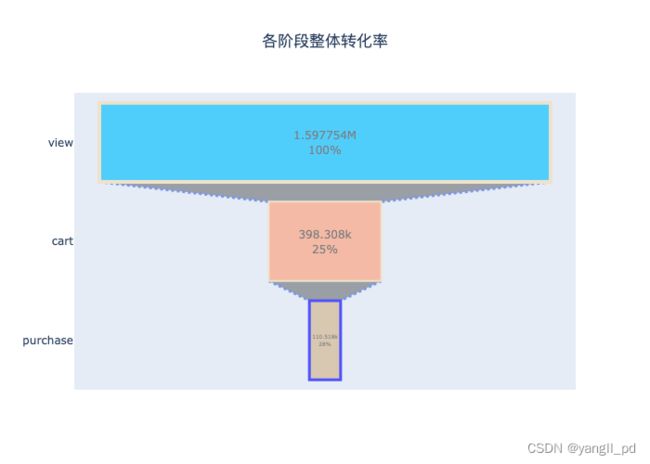
3.2.2 月转化率
(1)可视化每月各环节转化率
def figure_zhuanhua1(df):
data = table_month_liuliang(df)
fig = plt.figure(dpi=80)
axe = fig.add_subplot(111)
axe.set_xlabel('日期')
axe.set_ylabel('转化率')
axe.set_title('2019年10月到20202月各环节月转化率')
axe.plot(data['y_m'],data['月cart人数']/data['月view人数'],'g-o',alpha=0.5,label='view_cart转化率')
axe.plot(data['y_m'],data['月purchase人数']/data['月cart人数'],'b-o',alpha=0.5,label='cart_purchase转化率')
axe.plot(data['y_m'],data['月remove_from_cart人数']/data['月cart人数'],'m-*',alpha=0.5,label='remove_from_cart率')
plt.legend()
#调用函数查看每月各环节转化率图
figure_zhuanhua1(df)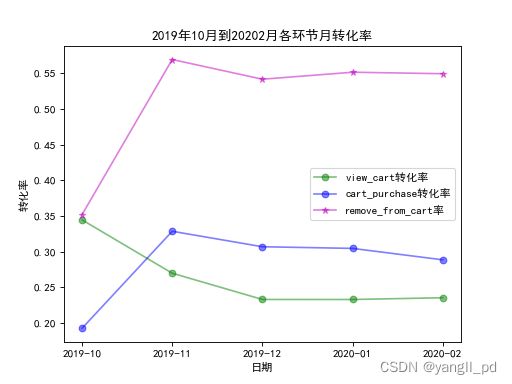
3.2.3 日转化率
(1)可视化每日各环节转化率
#可视化每日各环节转化率
def figure_zhuanhua2(df):
data = table_day_liuliang(df)
fig = plt.figure(figsize=(10,8),dpi=100)
axe = fig.add_subplot(111)
axe.set_xlabel('日期')
axe.set_ylabel('转化率')
axe.set_title('2019年10月到20202月各环节日转化率')
axe.plot(data['event_time'],data['日cart人数']/data['日view人数'],'b-o',alpha=0.5,label='view_cart转化率')
axe.plot(data['event_time'],data['日purchase人数']/data['日cart人数'],'g-o',alpha=0.5,label='cart_purchase转化率')
axe.plot(data['event_time'],data['日remove_from_cart人数']/data['日cart人数'],'m-*',alpha=0.5,label='remove_from_cart率')
plt.legend()
#调用函数查看每日各环节转化率
figure_zhuanhua2(df)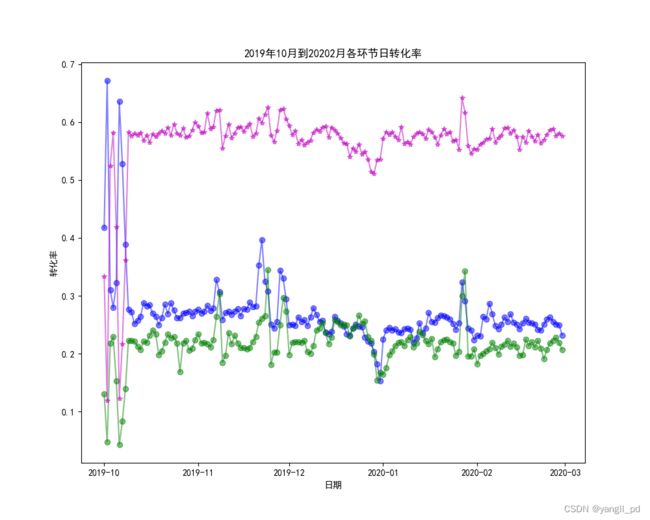
(2)异常点
2019年10月1日假日期间数据表现异常,日访客人数和加购人数都有有增加,而购买人数没有增加。转化率差
3.3 成交指标和客单价指标
3.3.1 日成交金额、购买用户、客单价
(1)自定义函数生成日成交金额,购买用户数,客单价数据框
# 数据准备
#自定义函数生成日成交金额,购买用户数,客单价数据框
def table_yingyun1(df):
df_s = (
df[['event_time','event_type','user_id','price']]
[df['event_type']=='purchase']
.groupby(['event_time','user_id'],as_index=False)
.agg({'event_type':'count','price':'sum'})
.groupby('event_time',as_index=False)
.agg({'event_type':'count','price':'sum'})
.rename(columns={'event_type':'每日购买人数','price':'每日成交金额'})
.assign(客单价=lambda d:round(d['每日成交金额']/d['每日购买人数'],2))
)
return df_s(2)自定义函数可视化每日成交金额及每日客单价图
#可视化
#自定义函数可视化每日成交金额及每日客单价图
def figure_yingyun1(df):
data = table_yingyun1(df)
fig = plt.figure(figsize=(10,6),dpi=80)
plt.grid()
axe = fig.add_subplot(111)
# axe.set_ylim((0,2500))
axe.set_xlabel('日期')
axe.set_ylabel('每日购买人数')
axe.set_title('2019年10月至2020年2月每日成交金额及每日客单价趋势')
axe.plot(data['event_time'],data['每日成交金额'],'r-o',label='每日成交金额')
plt.legend(loc=4)
axe1 = axe.twinx()
axe1.set_ylim((0,52))
axe.set_ylabel('每日客单价')
axe1.plot(data['event_time'],data['客单价'],'y--',label='每日客单价')
plt.legend(loc=3)
# 调用函数查看每日成交金额及每日客单价图
figure_yingyun1(df)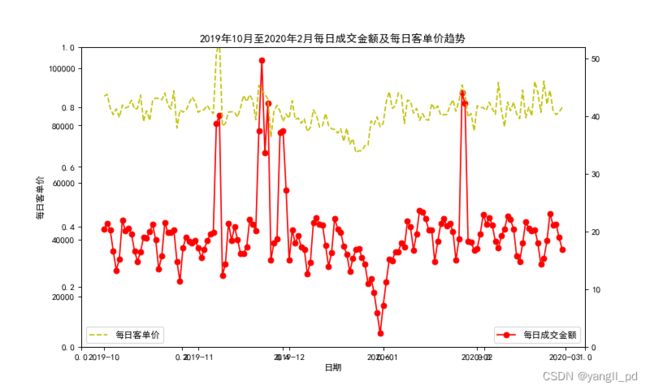
3.3.2 月成交金额,用户数,客单价
(1)自定义函数构建月成交金额,用户数,客单价数据框
# 数据准备
#自定义函数构建月成交金额,用户数,客单价数据框
def table_yingyun2(df):
df = (
df[['y_m','event_type','user_id','price']]
[df['event_type']=='purchase']
.groupby(['y_m','user_id'],as_index=False)
.agg({'user_id':'count','price':'sum'})
.groupby('y_m',as_index=False)
.agg({'user_id':'count','price':'sum'})
.rename(columns={'user_id':'每月购买人数','price':'每月成交金额'})
.assign(月客单价=lambda d:round(d['每月成交金额']/d['每月购买人数'],2))
)
return df(2)自定义函数可视化月成交金额,客单价图
#可视化
#自定义函数可视化月成交金额,客单价图
def figure_yingyun2(df):
data = table_yingyun2(df)
fig = plt.figure(dpi=80)
axe = fig.add_subplot(111)
axe.set_xlabel('日期')
axe.set_ylabel('每月成交金额')
axe.set_title('2019年10月至2020年2月每月成交金额及客单价图')
axe.plot(data['y_m'],data['每月成交金额'],'b-',label='每月成交金额')
plt.legend(loc=4)
axe1 = axe.twinx()
axe1.set_ylabel('每月客单价')
axe1.set_ylim((0,50))
axe1.plot(data['y_m'],data['月客单价'],'m--',label='月客单价')
plt.legend(loc=7)
#调用函数查看月成交金额,用户数,客单价图
figure_yingyun2(df)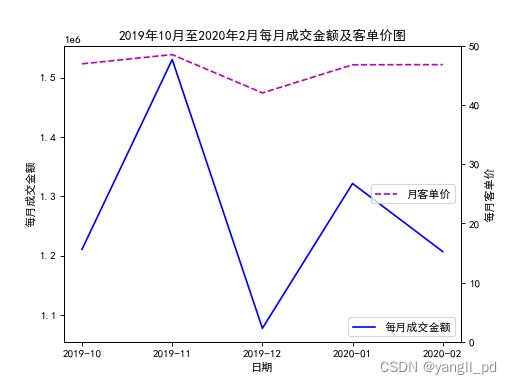
'''11月份销售额明显提升,这与双11促销相关,而12月份的销售额出现了了明显的降低,
一方面是双十一透支了客户的消费力,同时12月份的促销活动做的不够理想
'''
3.4 用户数据指标
相关指标
* (有购买行为的用户)留存率:某段时间新增用户中在第n个时间段中再次使用的用户数/某段时间的新增用户数
衡量不同时期购买用户的流失情况
* 复购率:某时间段内,购买次数大于等于两次的用户占比。(一天内多次购买算作一次)
分析流程
* 数据整理
* 数据可视化
* 问题总结
结论:
* 用户留存率整体在不断降低,基于目前的数据进行的分析,没有看留存率有明显的稳定趋势,注意加强运营,提高留存率。
* 复购率变化较大,跟每日购每人数有一定的相关性,而购买人数的增加与营销活动和节日促销粘性较大,因此经常性的活动宣传或者活动力度对保持复购率有一定的作用。
3.4.1. 每日新增用户数
意义:① 用户对产品的关注度 ② 用于判断渠道推广的效果
(1)自定义函数生成每日新增用户数
# 自定义函数生成每日新增用户数
def table_rizeng(df):
#筛选出有购买的用户数据
d = list(df['event_time'].unique())
l = []
# 迭代生成不同周期后的留存数量,保存在列表中
for i in range(len(d)):
#筛选某月内新增的用户id
s = set(df[df['event_time']==d[i]]['user_id'].unique())
for p in d[:i]:
s -= s.intersection(set(df[df['event_time']==p]['user_id'].unique()))
l.append(len(s))
plt.plot(d,l)  日新增用户数
日新增用户数
3.4.2 留存率
(1) 自定义函数生成每个月新增用户留存率数据框
# 自定义函数生成每个月新增用户留存率数据框
def table_liucun(df):
#筛选出有购买的用户数据
# df = df[df['event_type']=='purchase']
y_m = list(df['y_m'].unique())
l = []
# 迭代生成不同周期后的留存数量,保存在列表中
for i in range(len(y_m)):
#筛选某月内新增的用户id
s = set(df[df['y_m']==y_m[i]]['user_id'].unique())
for p in y_m[:i]:
s -= s.intersection(set(df[df['y_m']==p]['user_id'].unique()))
a = []
#添加后几个月每个月的用户留存数
for j in y_m[i+1:]:
a.append(len((s
.intersection(set(df[df['y_m']==j]['user_id'].unique())))))
#注意把没有值的位置填充为0
if i >0:
for q in range(i):
a.append(0)
l.append([len(s)]+a)
return (#生成数据框
pd.DataFrame(l)
.rename(index=dict(zip([0,1,2,3,4],y_m)),columns=
{0:'当月新增用户数',1:'第1个月后留存率',2:'第2个月后留存率',3:'第3个月后留存率',4:'第4个月后留存率'})
.fillna('')
.assign(第1个月后留存率=lambda d:round(d['第1个月后留存率']/d['当月新增用户数'],2))
.assign(第2个月后留存率=lambda d:round(d['第2个月后留存率']/d['当月新增用户数'],2))
.assign(第3个月后留存率=lambda d:round(d['第3个月后留存率']/d['当月新增用户数'],2))
.assign(第4个月后留存率=lambda d:round(d['第4个月后留存率']/d['当月新增用户数'],2))
.T
.replace(0,'')
)
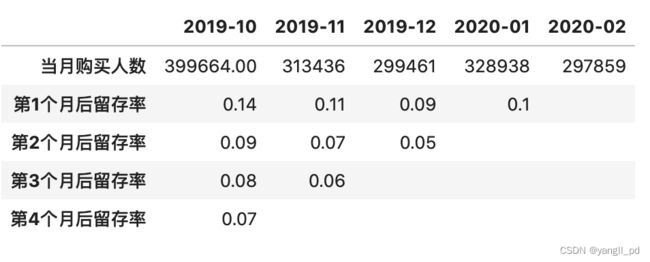
(2)自定义函数可视化不同月份客户的留存率
# 自定义函数可视化不同月份客户的留存率
def figure_(df):
fig = plt.figure()
data = table_liucun(df).iloc[1:]
for i in range(data.shape[1]-1):
plt.plot(data.iloc[:,i].iloc[0:(4-i)].index.values
,data.iloc[:,i].iloc[0:(4-i)],label='%s'%data.columns[i],marker='o')
plt.title('每个月新增用户在下一个周期的留存率')
plt.legend()
#调用函数展示图表
figure_(df) 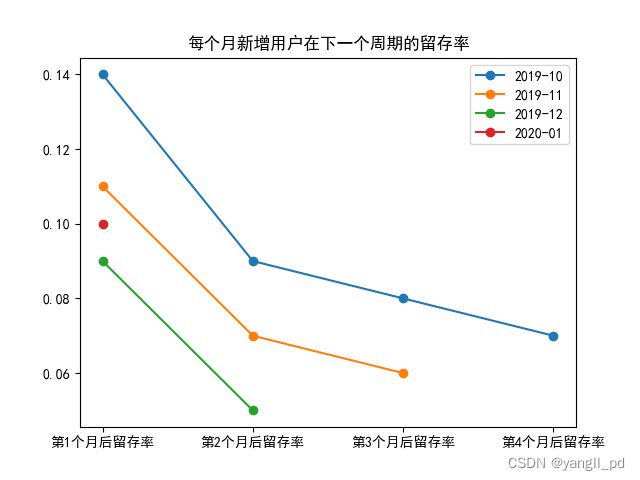
3.4.3 90天滚动复购率
初始复购率为自2020-10到2020-12月90天,之后以每30天(一个月)进行滚动,计算复购率
(1)自定义函数生成90天滚动复购率
def gundong_gugou(df):
date_list = df['y_m'].unique().tolist()
d = []
for i in range(len(date_list)-2):
# print(date_list[i])
d.append('d%d'%i)
date_l = []
date_l.append(date_list[i])
# print(date_l)
for j in range(i+1,i+3):
date_l.append(date_list[j])
# print(type(date_l))
# print(date_l)
d[i] = (
df[(df['event_type']=='purchase')&(df['y_m'].isin(date_l))]
.drop_duplicates(subset=['event_time','user_id'])
[['y_m','user_id','event_type']]
.groupby(['user_id'])
.count()
.rename(columns={'y_m':'购买','event_type':'复购'})
.assign(复购=lambda d:d['复购'].where(d['复购']>1))
.count()
.pipe(pd.DataFrame)
.T
.assign(复购率=lambda d:d['复购']/d['购买'])
.rename(index={0:'%s~%s'%(date_l[0],date_l[2])})
)
df_ = pd.concat(d).assign(复购率=lambda d:d['复购率'].apply(lambda x:format(x,'.2%')))
return df_(2)90天复购率表
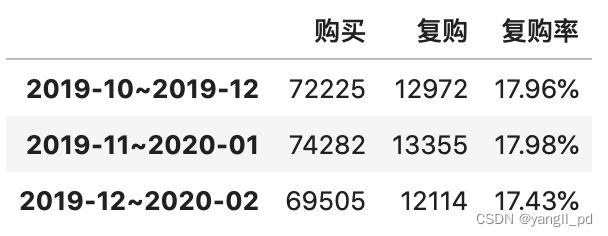
90天滚动复购率基本稳定。参考精益数据分析中的经验,90天复购率在15%到30%之间的公司属于,混合模式,即:电商公司应兼顾新客户的获取和回头客的招揽。一方面努力获得更多的用户,还要适时提高用户的购买频率。
四、商品指标分析
本节将产品分为有销量和没有销量两大类,从产品类别(category_id)角度分析(product_id这里不细化)分析商品相关指标,找到最热销的类别,和最滞销的类别,以求带来最大的销售业绩,同时优化库存和商品。
相关指标
* 产品贡献度分析(帕累托法则):
累计贡献率(%)=(累加销售收入/销售总收入)*100%
* 四象限图分析:
销量和销售额划分
分析流程
* 数据整理
* 数据可视化
* 问题总结
结论:
(1)滞销类别
* 对于有销量的468个类别,结合产品贡献度和四象限两种分析方法。找到累计贡献度率80%之后的类别。
* 接着从累计贡献度率80%之后的类别中,再筛选价值更低的类别,自定义筛选系数,结果筛选出55个类别,建议尽快处理积压的库存,后续暂不考虑采购
(2)热销类别
* 通过统计分析展示了总销量、总销售额排行榜。
* 同时展示了每个月的销量、销售额排行榜
* 可进一步预测热销品未来销量(数据时间集中在年底,宣传促销活动比较多,暂时不做这方的探索)
(3)无购买记录的类别
* 找到没有销量的类别为57,占总类别数的11%,进一步分析知道这些类别中有43个类别,已经上线至少4个月以上,可视为为无效库存,考虑降价清仓处理。
(4)同时热销和热搜的产品
* 从各方面的统计分析可以看出,1487580005092295511为最佳销售类别
4.1. 有销量商品的数据分析
本项目选取一级商品类别进行分析
滞销品:销售额累计贡献率80%之后的类别,或者销量和销售额都小于平均值的类别
畅销品:销量和销售额前n的类别
4.1.1 滞销品分析
(1)自定义函数构建有销量的468个类别(category_id)的销售数据表
#自定义函数构建有销量的468个类别(category_id)的销售数据表
# print(df[df['event_type']=='purchase']['category_id'].nunique())#category_id数量总共525
# print(df[['category_id']].nunique())有销量的category_id468个
# print(df[['product_id']].nunique())#product_id数量54569
# print(df[df['event_type']=='purchase']['price'].sum())# 总销售额6348267.7
def category(df):
data =(
df[df['event_type']=='purchase']
[['category_id','user_id','price']]
.groupby(['category_id'],as_index=False)
.agg({'user_id':'count','price':'sum'})#一天多次购买同一类产品都要计数
.sort_values(by='price',ascending=False)
.rename(columns={'user_id':'销量','price':'销售额'})
.assign(销售额倒数排名=lambda d:d['销售额'].rank())
)
return data(2)自定义函数进行贡献度分析,并得到累计贡献度率80%之后的类别生成列表l1
# 自定义函数进行贡献度分析
def contribution(df):
data =(
category(df)
[['category_id','销售额']]
.assign(累计贡献率=lambda d:(d['销售额'].cumsum()/d['销售额'].sum()))
.reset_index()
)
#根据二八法则,得到累计贡献度率80%之后的类别
l1 = data[data['累计贡献率']>0.801]['category_id'].values.tolist()
# print('贡献度80%之后的类别:',l)
fig = plt.figure(figsize=(8,6),dpi=100)
axe = fig.add_subplot(111)
axe.set_title('产品贡献度分析(有销量)')
axe.set_ylabel('销售额')
axe.set_xlabel('排名')
x = [i+1 for i in data.index.values]
y = data['销售额']
axe.bar(x,y,color='g')
axe1 = axe.twinx()
axe1.set_ylabel('累计贡献率')
y1 = data['累计贡献率']
axe1.plot(x,y1,'r-',alpha=0.5)
s = data[data['累计贡献率']<0.801].tail(1)#查看累计贡献率达到80%的数据点
rate = (data[data['累计贡献率']<0.801].count()[0])/(df[['category_id']].nunique())#贡献度为80%的产品类别数量占总产品类别数的比率
plt.annotate('86个类别占比16.4%,贡献了80%的销售额',xy=(86,0.8),xytext=(100,0.6),xycoords='data',
arrowprops=dict(facecolor='r',width=1,headwidth=6,shrink=8,headlength=4))
return l1#(返回贡献度20%的类别)
#调用函数查看产品贡献度图,并得到累计贡献度率80%之后的类别
l1 = contribution(df)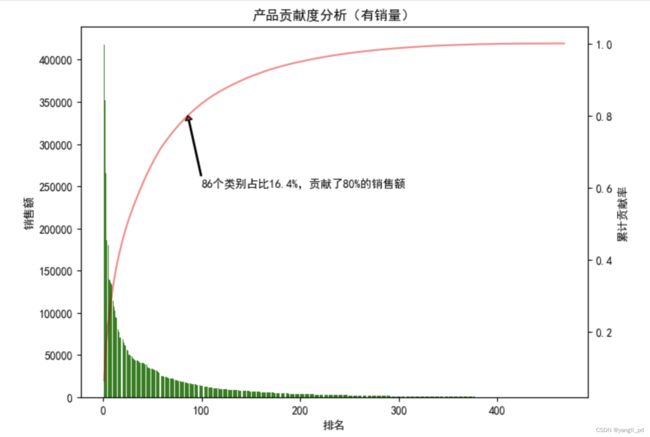
(3)自定义函数进行四象限图分析,并找到销量和销售额都小于平均值的类别生成列表l2
# 自定义函数进行四象限图分析
def figure_cate1(df):
data = category(df)
fig = plt.figure(figsize=(10,6))
plt.title('不同类比的产品四象限图评估图')
plt.xlabel('销量')
plt.ylabel('销售额')
plt.scatter(data['销量'],data['销售额'],color='b',alpha=0.8)
plt.axhline(y=data['销售额'].mean(),ls="-",color="#ff7f0e",linewidth=1)#y=0表示水平线过y=0,ls设置线条类型,linewidth设置线条粗细
#添加垂直直线
plt.axvline(x=data['销量'].mean(),ls="-",color="#d62728",linewidth=1)
# 找到销量和销售额都小于平均值的类别
l2 = data[(data['销量'] 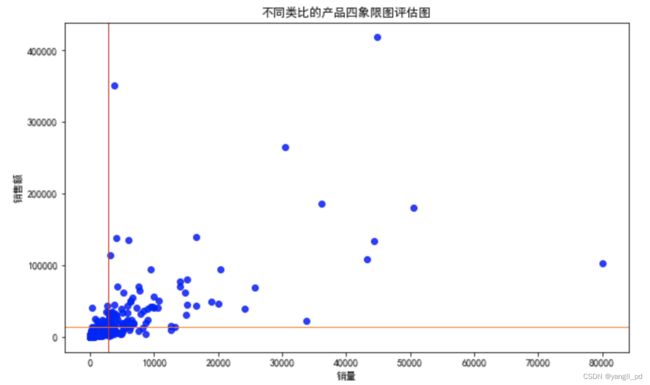
(4)比较l1与l2,并分析是否是同一部分类别
print('累计贡献度率80%之后的类别数量为:',len(l1))
print('四象限分析法中销量和销售额都小于平均值的类别数量为:',len(l2))
print('同时存在以上两种分析方法中价值低的类别的数量为:',len(set(l1).intersection(set(l2)))) 累计贡献度率80%之后的类别数量为: 382 四象限分析法中销量和销售额都小于平均值的类别数量为: 346 同时存在以上两种分析方法中价值低的类别的数量为: 346
(5)择从四象限图分析的346个类别中,继续挑选销售热度最靠后的的类别l3
#选择从四象限图分析的346个类别中,继续挑选销售热度最靠后的的类别l3
def figure_cate2(df):
data = category(df)
data = data[(data['销量']筛选出的满足条件的l3中类别的数量、类别的销量、类别的总销售额分别为: (55, 705, 4762.82)

#检验这55个类别销的售额倒数排名
print('这55个类别的产品中最大的销量为:')
print(category(df)[category(df)['category_id'].isin(l3)]['销量'].max())
print('这55个类别的产品中最大的销售额为:')
print(category(df)[category(df)['category_id'].isin(l3)]['销售额'].max())
#打印这55个类别的编码
print(l3)
4.1.2 畅销品分析
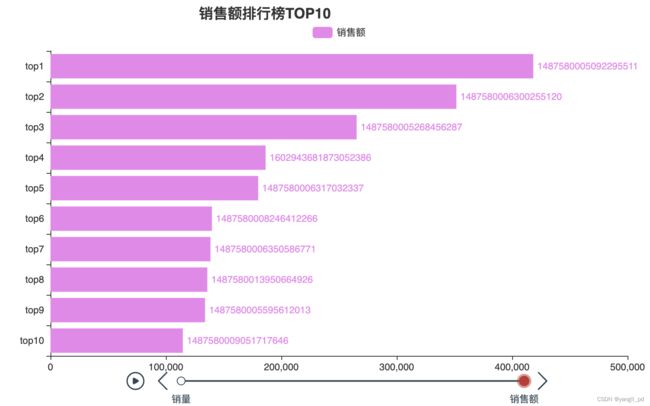
(1)总销售排行分析,示例为销量和销售额TOP10
# 整体的销量和销售额排行榜TOPn
def figure_top(df,n):
'''
参数df是整体加工过的数据
n:自定义排行榜名次
'''
x = ['top%d'%i for i in range(1,n+1)][::-1]
tl = Timeline()
for i in ['销量','销售额']:
data = category(df).sort_values(by=[i],ascending=False).head(n)
data = data[[i,'category_id']].astype({i:'float','category_id':'string'})
y = []
for p , q in zip(data[i].values.tolist()[::-1],data['category_id'].values[::-1]):
y.append({'value':p,'id':q})
bar = (
Bar()
.add_xaxis(x)
.add_yaxis(i,y,color='violet',
label_opts=opts.LabelOpts(position="right",formatter=JsCode(
"function(x){return x.data.id }"))
)
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts("{0}排行榜TOP{1}".format(i,n),
subtitle=None,
pos_left='30%'
),
legend_opts=opts.LegendOpts(pos_top='5%')
)
)
tl.add(bar, "{}".format(i))
return tl
figure_top(df,10).load_javascript()
figure_top(df,10).render_notebook()#注意与上一行代码在不同cell中运行,否则可能会不显示图片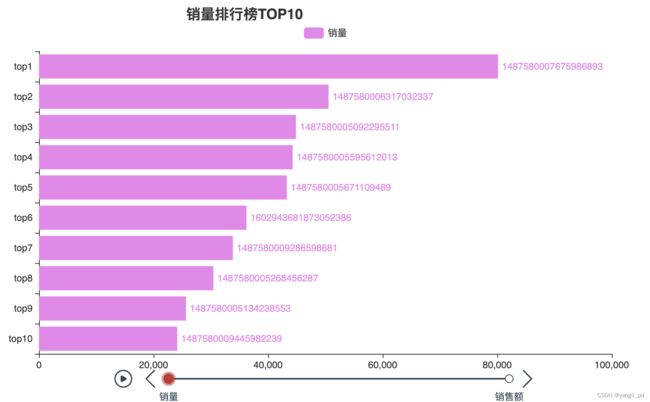
(2) 每个月销售排行分析,并可视化
#每个月总销售额排行榜topn
def category_month(df,type_,n):
'''
参数df是整体加工过的数据
type_:取值“销量”,“销售额”
n:自定义排行榜名次
'''
data =(
df[df['event_type']=='purchase']
[['y_m','category_id','user_id','price']]
.groupby(['y_m','category_id'],as_index=False)
.agg({'user_id':'count','price':'sum'})#一天多次购买同一类产品都要计数
.rename(columns={'user_id':'销量','price':'销售额'})
.groupby(['y_m'],as_index=False)
.apply(lambda d:d.sort_values(by=type_,ascending=False)
.assign(排序=d[type_].rank(ascending=False)).head(n))#组内按照销售额/销量降序
)
return data
#可视化排行榜
def figure_month_top(df,type_,n):
'''
参数df是整体加工过的数据
type_:取值“销量”,“销售额”
n:自定义排行榜名次
'''
x = ['top%d'%i for i in range(1,n+1)][::-1]
tl = Timeline()
for i in ['2019-10','2019-11','2019-12','2020-01','2020-02']:
data = category_month(df,type_,n)[category_month(df,type_,n)['y_m']==i]
data = data[[type_,'category_id']].astype({type_:'float','category_id':'string'})
y = []
for p , q in zip(data[type_].values.tolist()[::-1],data['category_id'].values[::-1]):
y.append({'value':p,'id':q})
bar = (
Bar()
.add_xaxis(x)
.add_yaxis(type_,y,color='blueviolet',
label_opts=opts.LabelOpts(position="right",formatter=JsCode(
"function(x){return x.data.id }"))
)
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts("{0}{1}排行榜TOP{2}".format(i,type_,n),
subtitle=None,
pos_left='30%'
),
legend_opts=opts.LegendOpts(pos_top='5%')
)
)
tl.add(bar, "{}".format(i))
return tl
#可更改参数查看销售额或者销售数量排行榜,以下是示例
figure_month_top(df,'销售额',10).load_javascript()
figure_month_top(df,'销售额',10).render_notebook()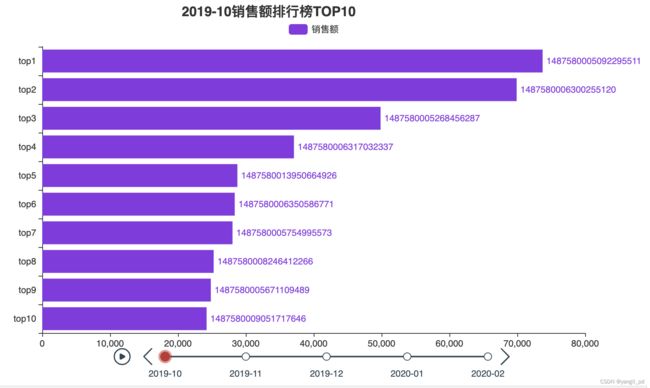
(3)综合分析
从五个月的数据分析可知,不论是销售额还是销售数量来看,编号为1487580005092295511的类别都排名前三。其下有产品653种。
df[(df['event_type']=='purchase') &(df['category_id']==1487580005092295511)]['product_id'].nunique() 4.2 没有销量商品的数据分析
(1) 筛选没有销量的类别
# 没有销量的类别525-468=57
# 找到这些没有销量的类别的最早有浏览记录的时间,假定时间间隔超过1个月,尽快处理库存。
def category_nosale(df):
return (
df[~df['category_id'].isin(df[df['event_type']=='purchase']['category_id'])]
[['event_time','category_id']]
.groupby(['category_id'])
.min()
.assign(最早一次非购买行为的距今时长=lambda d:
(pd.Timestamp('2020-3-1')-d['event_time']).dt.days)
.assign(分类=lambda d:pd.cut(d['最早一次非购买行为的距今时长'],bins=[0,30,60,90,120,155]))
)(2)自定义函数展示无销量类别的‘最早一次非购买行为的距今时长’的分布图
# 自定义函数展示无销量类别的‘最早一次非购买行为的距今时长’的分布
def figure_nosale(df):
data = category_nosale(df)
fig = plt.figure()
axe = fig.add_subplot(111)
axe.set_title('无销量类别的‘最早一次非购买行为的距今时长’的分布')
axe.set_ylabel('类别数量')
axe.set_xlabel('最早一次非购买行为的距今时长')
axe.hist(data['最早一次非购买行为的距今时长'],bins=[0,30,60,90,120,155],color='m',alpha=0.5)
m = data.groupby('分类').count()[['event_time']].rename(columns={'event_time':'类别数量'}).values.tolist()
for i ,j in zip([0,30,60,90,120,155],[m[p][0] for p in range(len(m))]):
plt.text(i+15,j,j,ha='center')
plt.show()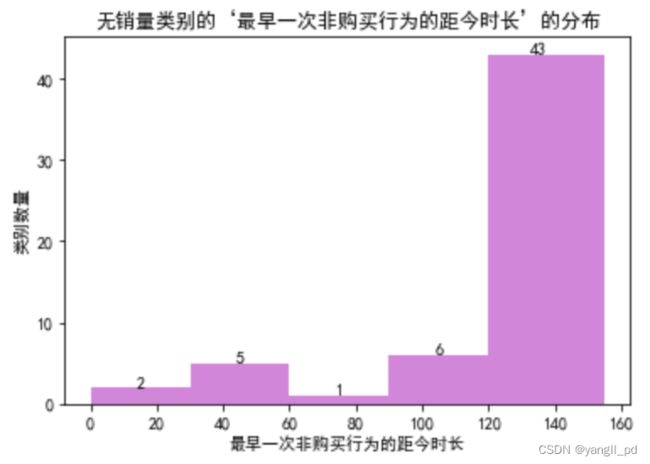
4.3 热搜产品类别
(1)筛选热搜前3的产品类别
#热搜前3的产品类别
(
df[['category_id','user_id']]
.groupby('category_id')
.count()
.sort_values(by='user_id',ascending=False)
.head(3)
) 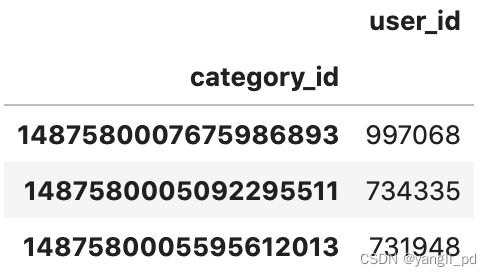
从上表可以看出,1487580005092295511既是热销产品也是热搜产品。
5. 用户价值分析-RFM分析
为了实现精细化运营,使用RFM分析方法,将用户分为8类,对不同价值的用户使用不同的运营决策
- R :每个用户最近一次消费的距今天数
- F :每个用户交易总次数(一天多次算一次)
- M :每个用户消费总额
分析流程
- 数据整理
- 数据可视化
- 问题总结
结论:
- 使用RFM分析方法,将客户分为5类,其中重要客户只有一个客户,可以结合业务具体分析该客户,可作为异常点
- 综合考虑不同客户群体的规模和各环节转化率,结合公司资源能力。可优先选择人数占比13%,而对整体销售额贡献占比42%的重点发展客户作为后续营销重点,提高这类客户的消费频率。
- 其次选择人数占比36%,对整体销售额贡献占比18.2%的一般发展客户,提高他们的消费频率和金额
- 最后人数占比大约42%的一般挽留客户,以及占比8%的重点挽留客户要要根据情况采取一定的挽留措施。
最后选择重要发展客户为例,具体研究了其上网时间特性,从而为日常促销时间点的设定提供参考
5.1 客户RFM分类并统计
5.1.1 自定义函数构建RFM表
# 数据整理
#自定义函数构建RFM表
def table_RFM(df):
data = df[['event_time','event_type','user_id','price']][df['event_type']=='purchase']
#将user_id为150318419客户排除,对分类结果没有影响
# data =data[data['user_id']!=150318419]
RFM = (
data
.assign(event_time=lambda d:d['event_time'].dt.date)
.assign(R=lambda d:(d['event_time'].max()-d['event_time']).apply(lambda x:x.days))
.groupby(['user_id','event_time'],as_index=False)
.agg({'event_type':'count','price':'sum','R':'min'})
.groupby('user_id')
.agg({'event_type':'count','price':'sum','R':'min'})
.rename(columns={'event_type':'F','price':'M'})
)
return RFM
table_RFM(df).describe()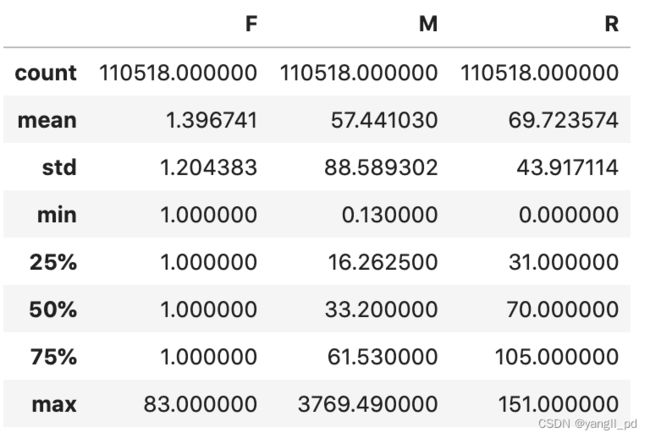
5.1.2 自定义函数构建RFM评分表,并可视化
#数据整理
# 自定义函数构建RFM评分表
def table_RFM_score(df):
RFM_score = (
table_RFM(df)
.assign(R_C=lambda d:np.where(d['R']>=d['R'].mean(),'1','2'))
.assign(F_C=lambda d:np.where(d['F']>=d['R'].mean(),'2','1'))
.assign(M_C=lambda d:np.where(d['M']>=d['R'].mean(),'2','1'))
.assign(RFM_C=lambda d:d['R_C']+d['F_C']+d['M_C'])
.replace({'RFM_C':dict(zip(['111','112','121','122','211','212','221','222'],
['一般挽留客户','重要挽留客户','一般保持客户','重要保持客户'
,'一般发展客户','重要发展客户','一般价值客户','重要价值客户']))})
.reset_index()
)
return RFM_score
# 自定义函数构建RFM分类统计表
def table_RFM_stat(df):
RFM_num = (
table_RFM_score(df)
[['user_id','RFM_C']]
.groupby('RFM_C')
.count()
.reindex(index=['一般挽留客户','重要挽留客户','一般保持客户','重要保持客户'
,'一般发展客户','重要发展客户','一般价值客户','重要价值客户'])
.fillna(0)
.rename(columns={'user_id':'user_num'})
.reset_index()
)
return RFM_num
#RFM模型分类可视化
data = table_RFM_score(df)
data['color'] = data['RFM_C'].map(dict(zip(data['RFM_C'].unique(),range(len(data['RFM_C'].unique())))))
fig = px.scatter_3d(data,x='R',y='F',z='M',color='color')
HTML(fig.to_html())
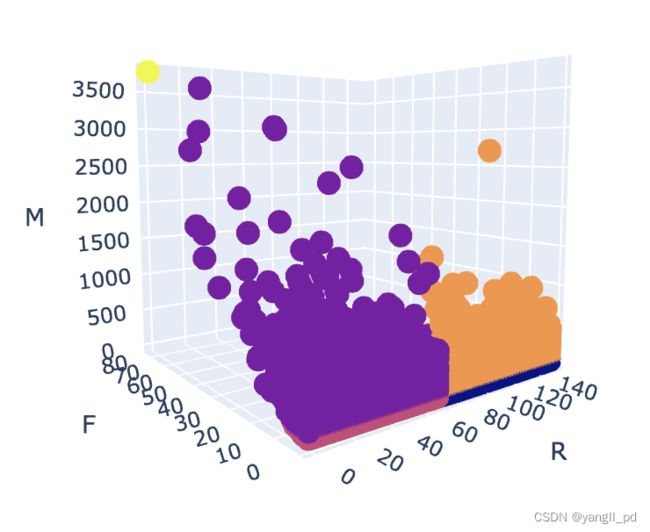
5.1.3 自定义函数可视化根据RFM进行的客户分类及数量分布图
#可视化
#自定义函数可视化根据RFM进行的客户分类及数量分布图
def figure_FRM_stat(df):
data = table_RFM_stat(df)
#有该买记录的总人数
m = len(table_RFM(df).index)
fig = plt.figure(figsize=(8,6),dpi=100)
axes = fig.add_subplot(111)
axes.bar([i for i in range(1,9)],data['user_num'].astype('int'),color='#ff7f0e',alpha=0.5)
axes.set_title('客户分类及数量分布图')
axes.set_ylabel('人数')
xlabels = ['一般挽留客户','重要挽留客户','一般保持客户','重要保持客户'
,'一般发展客户','重要发展客户','一般价值客户','重要价值客户']
plt.xticks(range(1,9),xlabels,rotation=20)
for a,b in zip([i for i in range(1,9)],data['user_num'].astype('int')):
plt.text(a,b+1000,'%d\n占比:%.2f'%(b,b/m),ha='center',va='center')
plt.show()
#调用函数查看客户分类及数量分布图
figure_FRM_stat(df)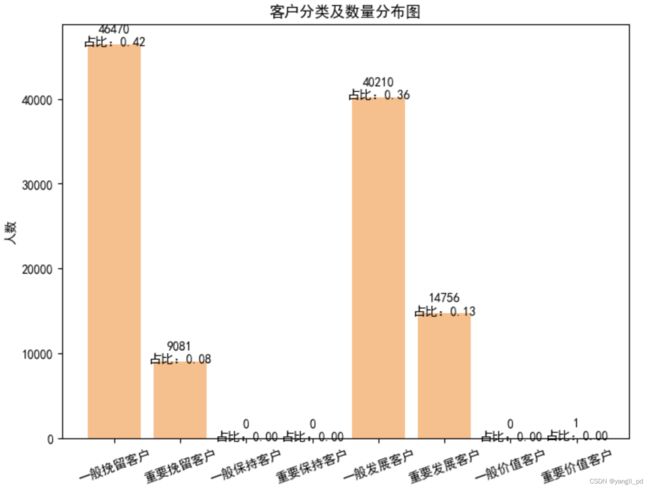
#核查所有的会员数
# 46470+9081+40210+14756+1=110518
df[df['event_type']=='purchase']['user_id'].nunique()5.2 各类客户销售额贡献度
(1)自定义函数分析各个类别客户的销售额贡献度
# 自定义函数分析各个类别客户的销售额贡献度
def table_contribution(df):
#五个月总的销售额
#df[df['event_type']=='purchase']['price'].sum()#6348267.7
data = table_RFM_score(df)
total = data['M'].sum()
print('五个月总的销售额:%d'%total)
for i in ['一般挽留客户','重要挽留客户','一般保持客户','重要保持客户','一般发展客户','重要发展客户','一般价值客户','重要价值客户']:
part = data[data['RFM_C']==i]['M'].sum()
rate = round(part/total,4)
print('%s对销售额的贡献占比:'%i,rate)
#调用函数查看贡献度
table_contribution(df)
在资源有限的情况下,可优先对重要发展客户进行运营,提高他们的消费频率。
5.3 各类客户的各环节转化率
此处用购物行为发生次数来计算转化率
(1)各类用户各环节转化率计算
def zhuanhua(df):
l = []
for i in ['一般挽留客户','重要挽留客户','一般发展客户','重要发展客户','重要价值客户']:
data = table_RFM_score(df)
user_id = data[data['RFM_C']==i]['user_id'].unique()
view_num = df[(df['user_id'].isin(user_id)) & (df['event_type']=='view')]['user_id'].count()
cart_num = df[(df['user_id'].isin(user_id)) & (df['event_type']=='cart')]['user_id'].count()
purchase_num = df[(df['user_id'].isin(user_id)) & (df['event_type']=='purchase')]['user_id'].count()
print(i,view_num,cart_num,purchase_num)
view_cart = round(cart_num/view_num,2)
cart_purchase = round(purchase_num/cart_num,2)
l.append([i,view_cart,cart_purchase])
return pd.DataFrame(l,columns=['分类','view_cart转化率','cart_purchase转化率'])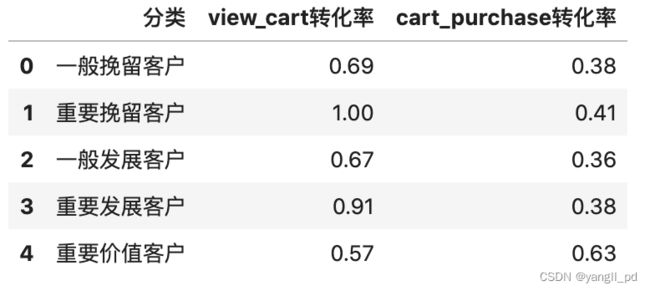
'''
从上表可看出,不同客户群体的各环节转化率表现普遍良好.需根据公司资源能力,正对不同群体采用不同措施
一般挽留客户和重要挽留客户的各环节的转换率率相比其他类别的客户也很高。针对他们应该重新激活他们进行购物
'''
5.4 精细化运营—以重要发展客户为例
结论
- 综合考虑,每周四上午十点或者下午19点,可以作为活动秒杀点
- 至于remove_from_cart最高峰发生在周一的19点,通过神马运营手段去试试改善吧
5.4.1 重要的发展客户购物时间分布
(1)自定义函数获取重要发展客户信息表
#自定义函数获取重要发展客户信息表
def important_develop(df):
l = (
table_RFM_score(df)
.pipe(lambda d:d[d['RFM_C']=='重要发展客户']['user_id'])
.values
.tolist()
)
print('重要发展客户有:%d人'%len(l))
df = df[df['user_id'].isin(l)]
return df
#调用函数查看重要发展客户信息表
df1 = important_develop(df)(2)研究重点发展客户的日常上网时间喜好并可视化
#研究重点发展客户的日常上网时间喜好
def figure_hour(df1):
fig = plt.figure(figsize=(10,10))
for i, j in zip(['view','cart','remove_from_cart','purchase'],[1,2,3,4]):
data = (
df1[df1['event_type']==i][['user_id','hour']]
.groupby('hour')
.count()
)
axe = fig.add_subplot(2,2,j)
axe.bar([i for i in range(0,24)],data['user_id'],color='blue',alpha=0.5)
plt.title('%s时间分布'%i)
plt.xlabel('时间')
plt.ylabel('人数')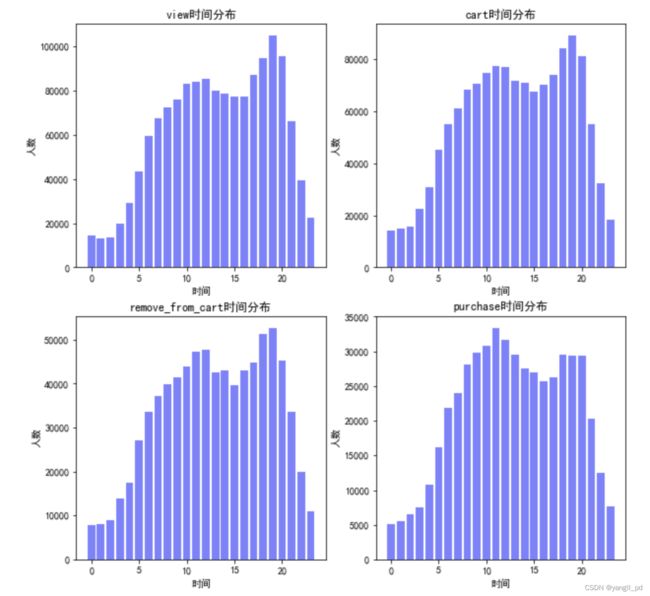
购物高峰在上午十点,和晚上19点。促销活动可以选择设置在这两个时间点
(3)小结
综合考虑,每周四上午十点或者下午19点,可以作为活动秒杀点,至于remove_from_cart最高峰发生在周一的19点,通过神马运营手段去试试改善吧
5.4.2 重要发展客户RFM三个指标的分布
#调用函数生成重要发展客户的RFM表
df1_rfm = table_RFM(df1)(1)R最近一次购买距今时间间隔(天):重要发展客户最近一次购买距今时间间隔(天)分布
plt.hist(df1_rfm['R'],color='g',alpha=0.5)
plt.title('重要发展客户最近一次购买距今时间间隔(天)分布')
plt.xlabel('R')
plt.ylabel('人数')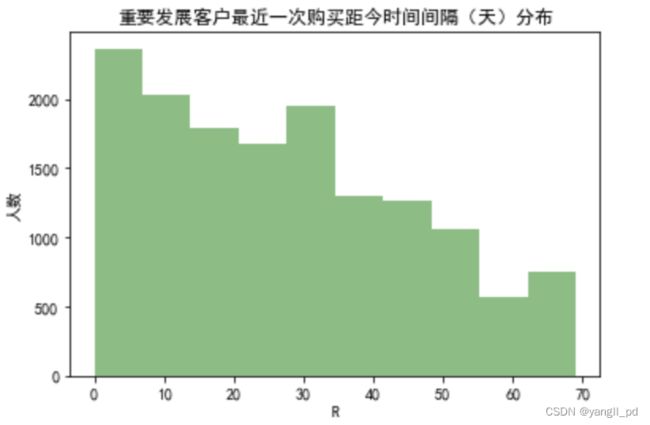
(2)F消费频率分布
plt.hist(df1_rfm['F'],color='g',alpha=0.5)
plt.title('重要发展客户的消费频率分布')
plt.xlabel('消费频率')
plt.ylabel('人数')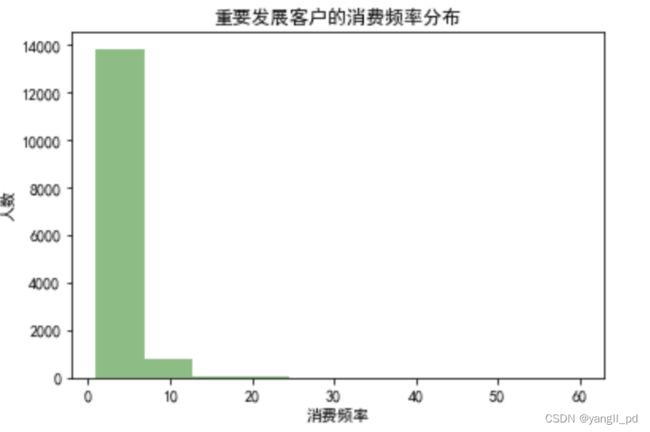
(3)M消费金额分布
plt.hist(df1_rfm['M'],color='g',alpha=0.5)
plt.title('重要发展客户的消费金额分布')
plt.xlabel('消费金额')
plt.ylabel('人数')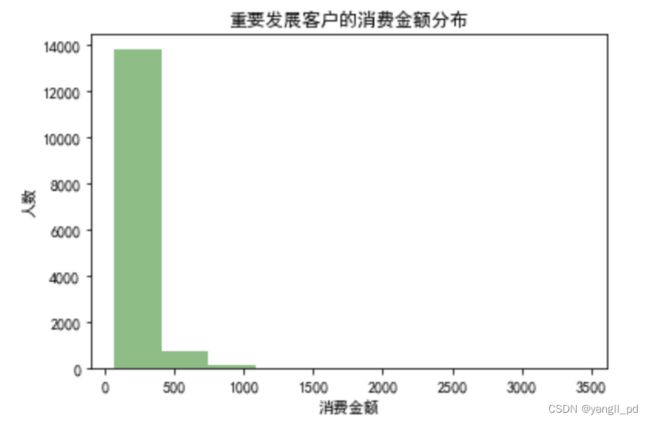
(4)小结
'''
重要发展客户在购物频率和购买金额上还有提升的空间,同时有一部分客户的最近购物的时间间隔有超过两个月,
应该有针对的激活购买记忆
'''
5.4.3 用户行为分析
主要分析一下几种用户行为数量:
- view-cart-purchase:有浏览记录和加入购物车记录并最后购买该产品的用户行为
- view-puchase:只有浏览记录最后购买的用户行为
- cart_purchase:直接从购物车购买的用户行为
- view_only:只有浏览记录的用户行为
- cart_only:只有加入购物车记录的用户行为
- view_cart_only:浏览加入购物车的用户行为
#统计重要发展用户的行为
(
df1[['user_id','category_id','product_id','event_type']]
.assign(次数=1)
.pipe(lambda d:pd.pivot_table(d,index=['user_id','category_id','product_id'],
columns=['event_type'],values='次数',
aggfunc=np.sum,fill_value=0
))
.pipe(lambda d:d.case_when(((d.purchase>=1)&(d.view>=1)&(d.cart==0)),'view_purchase',
((d.purchase>=1)&(d.view==0)&(d.cart>=1)),'cart_purchase',
((d.purchase>=1)&(d.view>=1)&(d.cart>=1)),'view_cart_purchase',
((d.purchase==0)&(d.view>=1)&(d.cart>=1)),'view_cart_only',
((d.purchase==0)&(d.view>=1)&(d.cart==0)),'view_only',
((d.purchase==0)&(d.view==0)&(d.cart>=1)),'cart_only',
((d.purchase>0)&(d.view==0)&(d.cart==0)&(d.remove_from_cart>=1)),'purchase_remove_from_cart',
((d.purchase==0)&(d.view==0)&(d.cart==0)&(d.remove_from_cart>=1)),'remove_from_cart',
'other',
column_name='行为路径'
)
)
['行为路径']
.value_counts()
)
通过分析可知某个用户有某个商品的cart_only和view_cart_only行为的记录370406+193318=563724
可优先对这部分客户加入购物车具体的某产品采取一定的营销策略,促成最终的成交。
5.4.4 重要发展客户日行为规律
(1)调用函数生成重要发展客户每日不同行为的数量、人数
# 调用函数生成重要发展客户每日不同行为的数量、人数
table_day_liuliang(df1)(2)自定义函数可视化重要发展客户每日UV、PV、平均访问深度图
#可视化
#自定义函数可视化重要发展客户每日UV、PV、平均访问深度图
def figure_liuliang0(df):
data = table_day_liuliang(df)
fig = plt.figure(figsize=(10,6),dpi=100)
axe = fig.add_subplot(111)
axe.set_xlabel('日期')
axe.set_ylabel('数量')
axe.set_title('2019年10月至2020年2月日PV、UV、平均访问深度')
plt.grid(color='0.5',linestyle='--',linewidth=1)
axe.plot(data['event_time'],data['日view次数'],color='g',alpha=0.5,label='日view量(PV')
axe.plot(data['event_time'],data['日view人数'],color='m',alpha=0.5,label='日view人数(UV)')
plt.legend()
axe1 = axe.twinx()
axe1.set_ylabel('UV/PV')
axe1.plot(data['event_time'],data['日view次数']/data['日view人数'],'r-o',label='日平均访问深度')
plt.legend(loc=2)
figure_liuliang0(df1)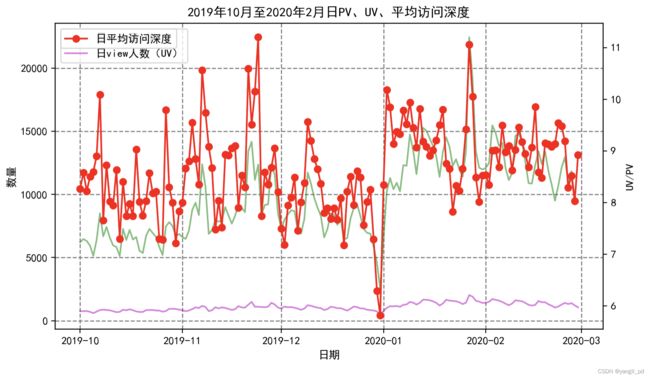 重要发展客户
重要发展客户
重要发展客户的各指标基本稳定。12月30,31两天表现异常
(3)调用函数查看重要发展客户的日转化率
#调用函数查看重要发展客户的日转化率
figure_zhuanhua2(df1)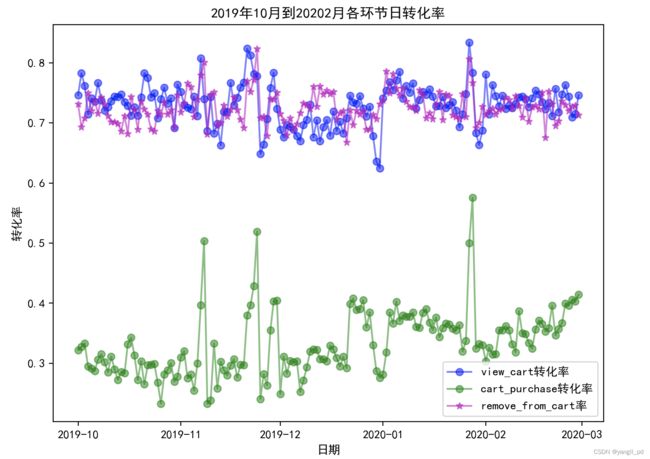
六、异常点分析--10月初成交转化率低的原因分析
6.1 采用4P营销理论,利用假设检验的方法寻找原因
6.1.1 4P营销理论—产品
- 假设产品一级类别在售数量减少导致10月初的成交转化率降低
可以从两个层面分析每日在售商品种类数量:一级类别数量,二级产品种类量,本例选取一级类别
用户有任何行为记录代表该类别或者商品ID在售
(1)每日在售商品一级类别数量
# 每日在售商品一级类别数量
(
df[['event_time','category_id','user_id']]
.groupby(['event_time','category_id'])
.count()
.groupby(['event_time'])
.count()
.rename(columns={'user_id':'category_num'})
.plot()
)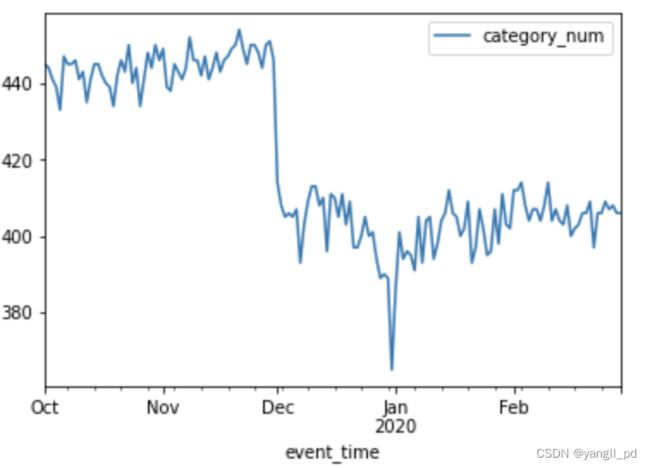
从上图可以看出,10月初,产品一级类别在售数量基本稳定
11月底公司应该有意识的对上线的产品类目进行一定的削减,或者促销重点改变。
而12月底这次的类目数量急剧减少,具体原因需要跟营销部门沟通
(2)再以热销一级类别1487580005092295511为例,查看每日二级product_id的日在售种类数
#再以热销一级类别1487580005092295511为例,查看每日二级product_id的日在售种类数
(
df[df['category_id']==1487580005092295511]
[['event_time','product_id','user_id']]
.groupby(['event_time','product_id'])
.count()
.groupby(['event_time'])
.count()
.rename(columns={'user_id':'product_num'})
.plot()
)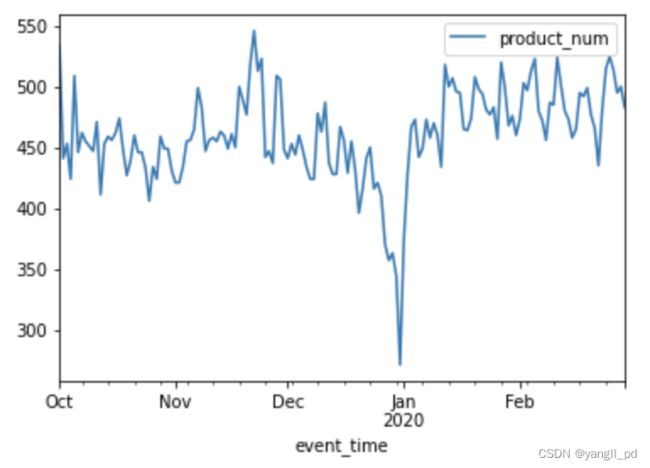
(3)热销类别为1487580005092295511的在10月初的售商品数量基本稳定。综上,假设产品一级类别在售数量减少导致10月初的成交转化率降低,假设不成立
6.1.2 4P营销理论——价格
- 假设产品一级类别在售价格降低导致10月初的成交转化率降低
(1)以热销一级类别1487580005092295511为例,分析每日在售类别价格
## 假设12月31日产品一级类别的价格上升销售额的降低
## 以热销一级类别1487580005092295511为例,每日在售类别价格
(
df[df['category_id']==1487580005092295511]
[['event_time','price']]
.groupby('event_time')
.mean()
.plot()
)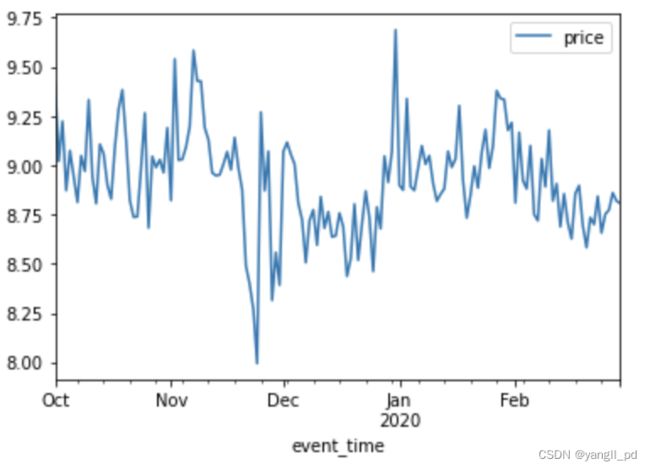
(2)从图中可以看出,10月出处=初的商品均价基本稳定 ,假设不成立
6.1.3 4P营销理论——渠道
由于案例中没有渠道相关数据,这里我们选择不同客户群体来分析,看是哪部分客户群体在当天表现不佳。
- 假设某些客户群体的行为表现导致10月初的成交转化率降低
(1)自定义函数生成不同价值用户的信息表
def different_c(df,t):
l = (
table_RFM_score(df)
.pipe(lambda d:d[d['RFM_C']==t]['user_id'])
.values
.tolist()
)
print('%s有:%d人'%(t,len(l)))
df = df[df['user_id'].isin(l)]
return df(2)分析不同价值用户的日流量和各环节转化率图
t=['一般挽留客户','重要挽留客户','一般发展客户','重要发展客户']
for i in t:
客户 = different_c(df,i)
table_day_liuliang(客户)#调用自定义日流量指标函数
figure_liuliang0(客户)#调用自定义函数生成日流量指标可视化图
figure_zhuanhua2(客户)#调用自定义函数生成转化率可视化图一般挽留客户的日流量图和转化率图
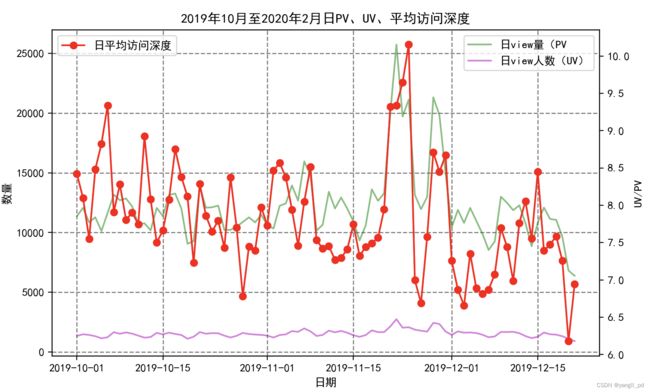
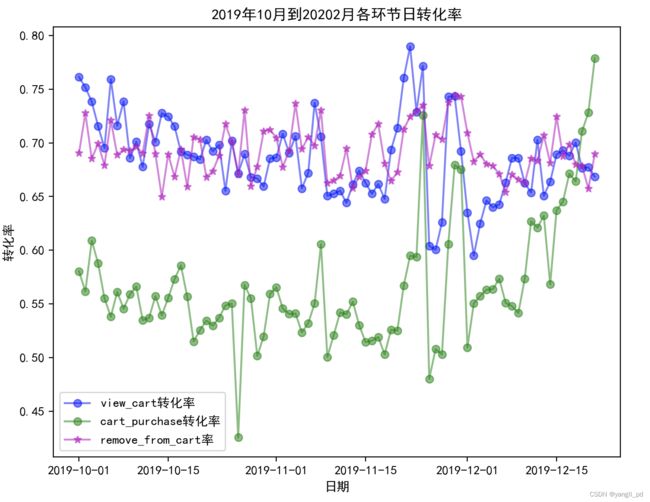
重要挽留客户的日流量图和转化率图
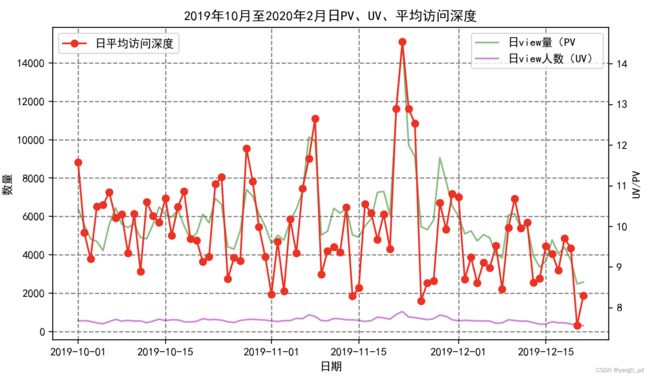
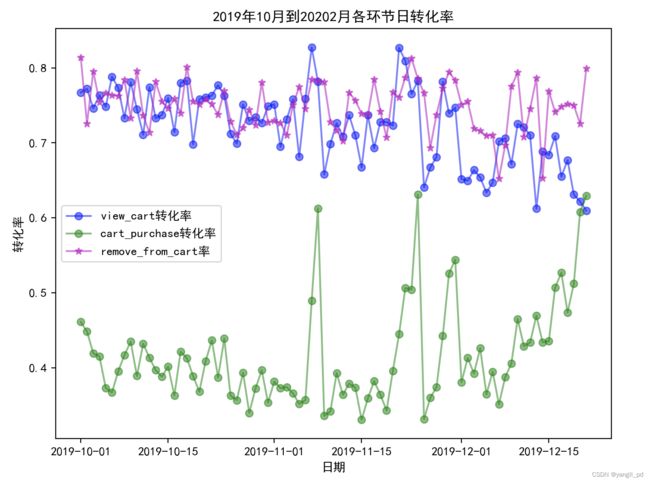
一般发展客户的日流量图和转化率图
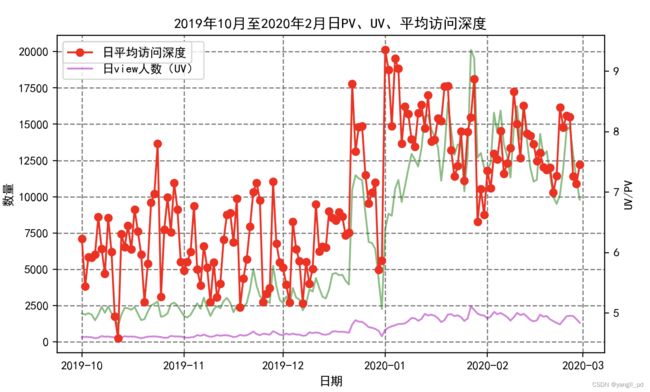
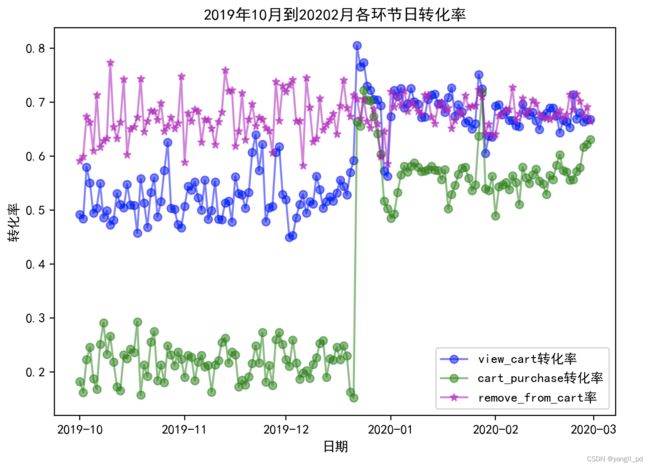
重要发展客户的日流量图和转化率图
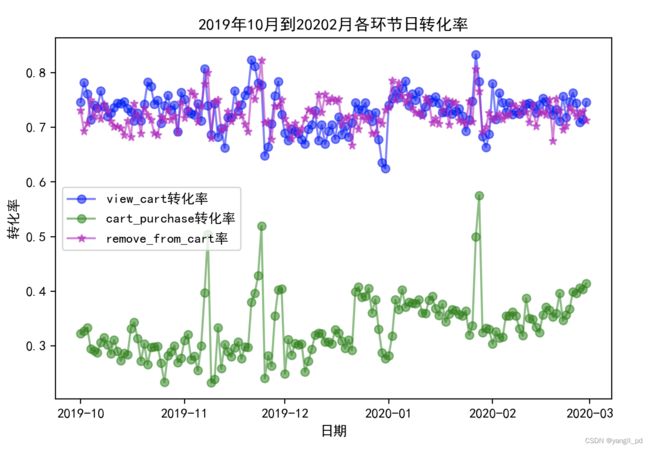
(3)根据以上分析,促销活动应该是针对的一般挽留和重要挽留客户,所以这两类客户的转化率比较高。一般发展和重要发展用户转化率较低。或者促销是针对新用户进行的。
6.1.3 4P营销理论——宣传
从数据来看10月初,平台进行了相关的促销方案。结合6.1.3应该是平台的在这个时间段的促销方案主要针对新用户
6.2 结论
10月初转化率下降的原因可能是平台的促销活动是有针对性的。从RFM较角度划分这部分人群属于一般挽留和重要挽留客户,结合时间维度来看,应该是10月初的促销活动只针对新用户进行的。
(同时还能看出,12月底这次转化率的大幅下降,跟运营策略的调整,上线产品的二级(product_id)类目数量和种类调整有很大的关系。)