《深度学习进阶 自然语言处理》第三章:word2vec
文章目录
-
-
- 3.1 基于推理的方法
-
- 3.1.1 基于计数的方法的问题
- 3.1.2 基于推理的方法的概要
- 3.1.3 神经网路中单词的处理方法
- 3.2 简单的word2vec
-
- 3.2.1 CBOW模型的推理
- 3.2.2 CBOW模型的学习
- 3.2.3 word2vec的权重和分布式表示
- 3.3 word2vec的补充说明
-
- 3.3.1 CBOW模型和概率
- 3.3.2 skip-gram模型
- 3.3.3 基于计数和基于推理
- 3.4 小结
-
之前文章链接:
开篇介绍:《深度学习进阶 自然语言处理》书籍介绍
第一章:《深度学习进阶 自然语言处理》第一章:神经网络的复习
第二章:《深度学习进阶 自然语言处理》第二章:自然语言和单词的分布式表示
上一章我们使用基于计数的方法得到了单词的分布式表示。本章我们将讨论一种替代方法:基于推理的方法。
3.1 基于推理的方法
其实不管是基于计数的方法还是基于推理的方法,他们的背景都是分布式假设。接下来我们首先介绍基于计数方法的缺点,然后概括性的说明基于推理的方法是如何工作的。
3.1.1 基于计数的方法的问题
由第二章可知,基于计数的方法是根据一个单词周围的单词出现频数来表示该单词的。具体来说,先生成所有单词的共现矩阵,再对这个矩阵进行 SVD,以获得密集向量(单词的分布式表示)。但是,基于计数的方法在处理大规模语料库时会出现问题。
在现实世界中,语料库处理的单词数量非常大。假设词汇量超过100万个,那么使用基于计数的方法就需要生成一个 100万x100万的庞大矩阵,但对如此庞大的矩阵执行 SVD 显然是不现实的。
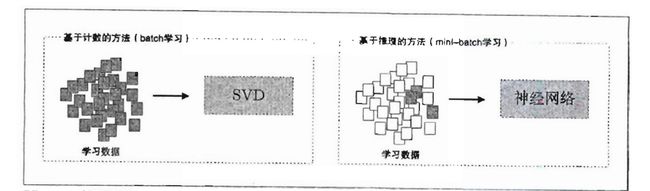
此时,神经网络就体现出重要的价值,如上截图所示,基于计数的方法一次性处理全部学习数据;反之,基于推理的方法使用部分学习数据逐步学习。这意味着,在词汇量很大的语料库中,即使 SVD 等的计算量太大导致计算机难以处理,神经网络也可以在部分数据上学习。并且,神经网络的学习可以使用多台机器、多个 GPU 并行执行,从而加速整个学习过程。
3.1.2 基于推理的方法的概要
基于推理的方法其主要操作就是“推理”,即当给出周围的单词(上下文)时,预测“?”处会出现的单词。

那么,怎么进行推理“?”处的内容呢?
它主要是引入某种模型。这个模型接收上下文信息作为输人,并输出(可能出现的)各个单词的出现概率。在这样的框架中,使用语料库来学习模型,使之能做出正确的预测。另外,作为模型学习的产物,我们得到了单词的分布式表示。这就是基于推理的方法的全貌。
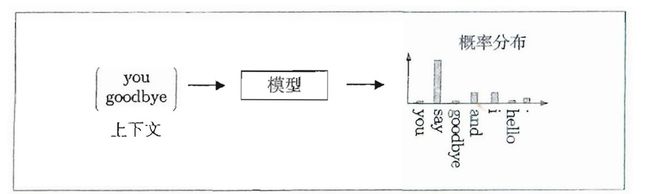
在上文中所讲的某种模型,其实就是引入神经网络的深度学习模型。不过在讨论引入什么样的神经网络之前,我们先要讨论一下在神经网络中单词该如何处理?
3.1.3 神经网路中单词的处理方法
因为神经网络并不可以直接处理单词,目前比较常规的处理方式是把单词转换为one-hot表示,然后把这些经过one-hot表示后的内容当做输入层,如下图:

然后把如上输入层神经元和中间层进行连接:

为了后期更好表示,把上面内容进行简化表示(后面如果没有特殊说明,均会用此种方法表示):

3.2 简单的word2vec
上一节中我们知道了什么是基于推理方法表示单词向量,接下来我们就看看word2vec中引入的神经网络模型,首先介绍一种最常见的模型:continuous bag-of-words(CBOW).
CBOW模型和skip-gram 模型是 word2vec中使用的两个神经网络。本节我们将主要讨论 CBOW模型。
3.2.1 CBOW模型的推理
CBOW模型是根据上下文预测目标词的神经网络(“目标词“是指中间的单词,它周围的单词是“上下文”)。通过训练这个 CBOW模型,使其能尽可能地进行正确的预测,我们可以获得单词的分布式表示。
CBOW 模型的输入是上下文。这个上下文用 [‘you‘,‘goodbye‘] 这样的单词列表表示。我们将其转换为 one-hot 表示,以便 CBOW模型可以进行处理。在此基础上,CBOW模型的网络可以画成下图这样。

3.2.2 CBOW模型的学习
CBOW模型在输出层输出了各个单词的得分。通过对这些得分应用 Softmax 函数,可以获得概率。进而通过概率表示哪个单词会出现在给定的上下文(周围单词)中间。

如上图举例,上下文是 you 和 goodbye。正确解标签(神经网络应该预测出的单词)是 say。这时,如果网络具有“良好的权重”, 那么在表示概率的神经元中,对应正确解的神经元的得分应该更高。
现在,我们来考虑一下上述神经网络的学习。其实很简单,这里我们处理的模型是一个进行多类别分类的神经网络。因此,对其进行学习只是使用一下 Softmax 函数和交叉熵误差。首先,使用 Softmax 函数将得分转化为概率,再求这些概率和监督标签之间的交叉熵误差,并将其作为损失进行学习,这一过程可以用下图表示。

3.2.3 word2vec的权重和分布式表示
如前所述,word2vec 中使用的网络有两个权重,分别是输人侧的全连接层的权重(Win)和输出侧的全连接层的权重(Wout)。一般而言,输人侧的权重 (Win) 的每一行对应于各个单词的分布式表示。另外,输出侧的权重(Wout) 也同样保存了对单词含义进行了编码的向量。
那么,我们最终应该使用哪个权重作为单词的分布式表示呢?这里有三个选项。
-
A.只使用输入侧的权重
-
B.只使用输出侧的权重
-
C.同时使用两个权重
方案A 和方案 B只使用其中一个权重。而在采用方案C的情况下,根据如何组合这两个权重,存在多种方式,其中一个方式就是简单地将这两个权重相加。
就 word2vec(特别是 skip-gram 模型)而言,最受欢迎的是方案A。 许多研究中也都仅使用输人侧的权重 Win作为最终的单词的分布式表示。
为什么使用Win更加有效,感兴趣的同学可以进一步阅读书中提供的参考文献[38].
3.3 word2vec的补充说明
3.3.1 CBOW模型和概率
本节中主要专注于如何用概率方法表示CBOW模型。这里,我们使用包含单词 w1,w2,⋯,wT的语料库。如下图所示,对第t个单词,考虑窗口大小为1 的上下文。
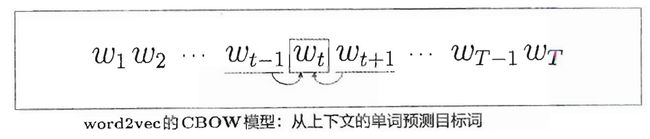
我们用数学式来表示当给定上下文wt-1和 wt+1时目标词为wt 的概率。使用后验概率:

那么最后构建的损失函数可以写为:

3.3.2 skip-gram模型
如前所述,word2vec 有两个模型:
- 一个是我们已经讨论过的 CBOW 模型;
- 另一个是被称为 skip-gram 的模型.skip-gram 是反转了 CBOW模型处理的上下文和目标词的模型。
举例来说,两者要解决的问题如下图所示:

skip-gram模型网络结构图:

3.3.3 基于计数和基于推理
到目前为止,我们已经了解了基于计数的方法和基于推理的方法(特别是 word2vec)。两种方法在学习机制上存在显著差异:
- 基于计数的方法通过对整个语料库的统计数据进行一次学习来获得单词的分布式表示,
- 而基于推理的方法则反复观察语料库的一部分数据进行学习(mini-batch 学习)。
这里,我们就其他方面来对比一下这两种方法。
-
首先,我们考虑需要向词汇表添加新词并更新单词的分布式表示的场景。
-
基于计数的方法需要从头开始计算。即便是想稍微修改一下单词的分布式表示,也需要重新完成生成共现矩阵、进行 SVD 等一系列操作。
-
基于推理的方法(word2vec)允许参数的增量学习。具体来说,可以将之前学习到的权重作为下一次学习的初始值,在不损失之前学习到的经验的情况下,高效地更新单词的分布式表示。
-
在这方面,基于推理的方法 (word2vec) 具有优势。
-
-
其次,从两种方法得到的单词的分布式表示的性质和准确度进行对比:
- 就分布式表示的性质而言,基于计数的方法主要是编码单词的相似性。
- 而 word2vec(特别是 skip-gram 模型)除了单词的相似性以外,还能理解更复杂的单词之间的模式。关于这一点,word2vec 因能解开 “king - man + woman = queen〞这样的类推问题而知名。
基于计数和基于推理的方法,我们不可以笼统的说出哪种方法更优,有不少研究表明它们在某些情况下是不分伯仲。
3.4 小结
本章我们详细解释了 word2vec 的 CBOW 模型,(具体实现可以参考书中代码)。CBOW模型基本上是一个2层的神经网络,结构非常简单。
遗憾的是,现阶段的 CBOW模型在处理效率上还存在一些问题。不过,在理解了本章的 CBOW模型之后,离真正的 word2vec 也就一步之遥了。下一章,我们将改进 CBOW 模型。