自动驾驶中图像与点云融合的深度学习研究进展综述
点云PCL免费知识星球,点云论文速读。
文章:Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review
作者:Yaodong Cui, IEEE, Ren Chen, Wenbo Chu, Long Chen
翻译:particle
本文仅做学术分享,如有侵权,请联系删除。欢迎各位加入免费知识星球,获取PDF论文,欢迎转发朋友圈分享快乐。
论文阅读模块将分享点云处理,SLAM,三维视觉,高精地图相关的文章。公众号致力于理解三维视觉领域相关内容的干货分享,欢迎各位加入我,我们一起每天一篇文章阅读,开启分享之旅,有兴趣的可联系微信[email protected]。
●论文摘要
在过去的几年里,自动驾驶汽车得到了迅速的发展。然而,由于驾驶环境的复杂性和动态性,实现完全自主并非易事。因此,自动驾驶车辆配备了一套不同的传感器,以确保强健、准确的环境感知。尤其是摄像机融合正成为一个新兴的研究主题。然而,到目前为止,还没有关于基于深度学习的相机激光雷达融合方法的评论。为了弥补这一差距并推动未来的研究,本文致力于回顾最近基于深度学习的数据融合方法,这些方法同时利用图像和点云。简要介绍了图像和点云数据处理的深度学习。接着对摄像机激光雷达融合方法在深度学习领域的目标检测、语义分割、跟踪和在线交叉传感器标定等方面进行了深入的综述,并根据各自的融合层次进行了综述。此外,我们在公开的数据集上比较了这些方法。最后,我们发现了当前学术研究与实际应用之间的差距和挑战。在此基础上,我们提出了自己的见解,并指出了未来的研究方向。
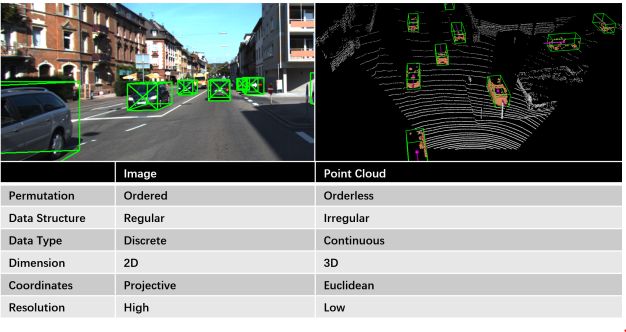
图像数据与点云数据的比较
● 相关工作与介绍
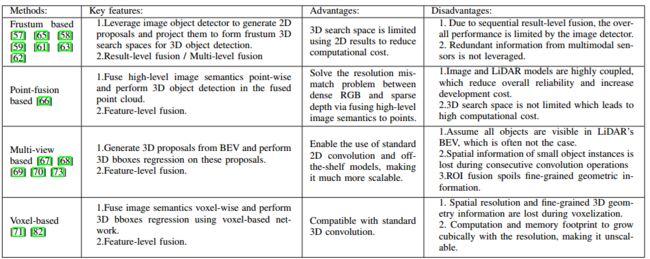
传感器融合技术利用多种具有互补特性的传感器来增强感知能力,降低成本,已成为一个新兴的研究课题。特别是深度学习技术提高了摄像机-激光雷达融合算法的性能。相机和激光雷达具有互补的特性,这使得融合模型比其他传感器融合配置更有效、更受欢迎。更具体地说,基于视觉的感知系统以低成本获得了令人满意的性能,然而,单摄像头感知系统无法提供可靠的3D几何结构,这对于自主驾驶至关重要。另一方面,立体相机可以提供三维几何体,但这样做的计算成本很高,并且在高遮挡和无纹理的环境中依旧很难实现。此外,相机基础感知系统与复杂或恶劣的照明条件作斗争,这限制了它们的全天候工作能力。相反,激光雷达可以提供高精度的三维几何图形,并且对环境光是不变性的。然而,移动式激光雷达受到分辨率低、低刷新率(10Hz)、恶劣天气条件(大雨、雾和雪)和高成本的限制。为了缓解这些挑战,许多研究将这两种互补传感器结合起来。

基于图像和点云融合的感知任务及其相应部分
相机-激光雷达融合不是一个简单的任务。首先,摄影机通过将真实世界投影到图像平面来记录真实环境,而点云则保留了三维几何图形。此外,在数据结构上,点云是不规则的、无序的、连续的,而图像是规则的、有序的、离散的。点云和图像的这些特征差异导致了不同的特征提取方法。在图1中,比较了图像和点的特征。先前关于多模数据融合深度学习方法的综述涵盖了广泛的传感器,包括雷达、摄像机、激光雷达、超声波、IMU、里程表、GNSS和HD地图。
本文只关注相机融合,因此能够对各种方法进行更详细的综述。此外,我们还涵盖了更广泛的感知相关主题(深度完成、动态和静态目标检测、语义分割、跟踪和在线交叉传感器校准),这些主题是相互关联的。本文的主要贡献如下:
•据我们所知,本文首次对自主驾驶中基于深度学习的图像和点云融合方法进行了研究,包括深度完成、动态和静态目标检测、语义分割、图像融合、图像融合、点云融合等,跟踪和在线交叉传感器校准。
•本文根据融合方法对方法进行了组织和评审。此外,本文还介绍了最新的(2014-2020年)最新的相机-激光雷达融合方法的概述和性能比较。
•本文提出了一些被忽视的开放性问题,如开放检测和传感器不可知论框架,这些问题对于自主驾驶技术的实际应用至关重要。
关于点云的深度学习分类可以查看以下文章:
三维点云语义分割总览
【论文速读】点云深度学习论文综述
【论文速读】2020最新点云深度学习综述
● 内容精华
一,深度估计
深度估计模型是一种通过将稀疏的点云通过上采样的方法生成稠密有规则的深度值(点云),这样生成的点云更加有利于后期的感知模块的实现,这种模型可以改善激光雷达扫描得到的点云的不均匀分布。这种上采样的方法通常是通过高分辨率的图像作为辅助条件来完成稠密深度值得生成。该图说明了不同的层次的深度值生成方案的时间线。
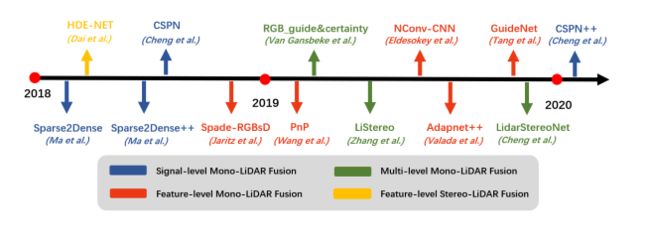
图给出了深度估计模型的时间轴及其相应的融合方法
图像引导深度完值估计背后的思想是密集的RGB/颜色信息包含相关的3D几何信息。因此,图像可以作为深度采样的参考。
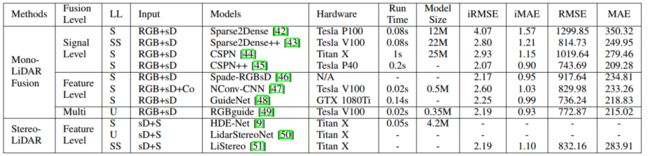
二,单目和激光雷达的融合:
1)信号级融合:2018年,Ma等人提出了一种基于ResNet的自动编码器网络,该网络利用RGBD图像(即与稀疏深度图连接的图像)来预测密集深度图。为了实时生成清晰的密集深度图,Cheng等人将RGB-D图像传送到卷积空间传播网络(CSPN)。
2) 特征级融合:Jaritz等人提出了一种自动编码器网络,它可以在不应用有效性掩码的情况下,从稀疏深度图和图像中执行深度完成或语义分割。图像和稀疏深度图首先由两个基于NASNet的并行编码器进行处理,然后将它们融合到共享解码器中。这种方法可以在非常稀疏的深度输入(8通道激光雷达)下获得良好的性能。
GuideNet将图像特征融合到编码器不同阶段的稀疏深度特征,引导稀疏深度的上采样,在KITTI深度完成基准中达到了最高性能。这些方法的局限性在于缺乏具有密集深度-地面真实性的大规模数据集。
3) 多层次融合:Van Gansbeke等人]在图像引导深度完成网络中进一步结合了信号级融合和特征级融合。该网络由一个全局分支和一个局部分支组成,对RGB-D数据和深度数据进行并行处理,然后根据置信图进行融合。
三,立体相机和激光雷达融合
与RGB图像相比,立体相机的密集深度视差包含了更丰富的地面真实三维几何结构。另一方面,激光雷达的深度是稀疏的,但精度较高。这些互补特性使得基于立体激光雷达融合的深度完成模型能够产生更精确的密集深度。不过,值得注意的是,立体摄像头的射程有限,在高遮挡、无纹理的环境中也会遇到困难。
四,动态物体的检测
目标检测(3D)的目标是在三维空间中定位、分类和估计有方向的边界框。本节致力于动态目标检测,包括常见的动态道路对象(汽车、行人、骑车人等)。目标检测有两种主要方法:顺序检测和单步检测。基于序列的模型按时间顺序由预测阶段和三维边界框(bbox)回归阶段组成。在预测阶段,提出可能包含感兴趣对象的区域。在bbox回归阶段,基于从三维几何中提取的区域特征对这些建议进行分类。然而,序列融合的性能受到各个阶段的限制。另一方面,一步模型由一个阶段组成,其中二维和三维数据以并行方式处理。图4和图5显示了3D目标检测网络和典型模型结构的时间线。

三维目标检测网络的时间轴及其相应的融合方法
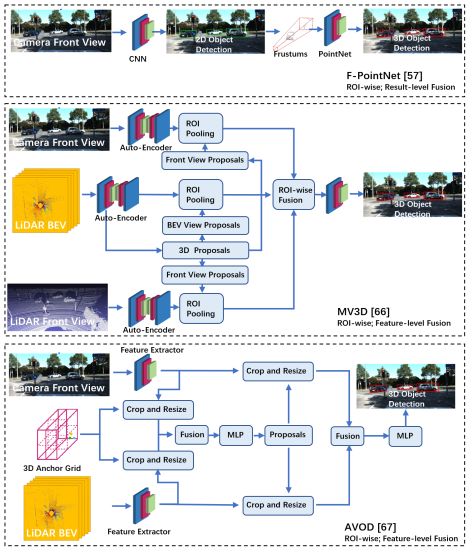
三种典型动态目标检测模型体系结构的比较
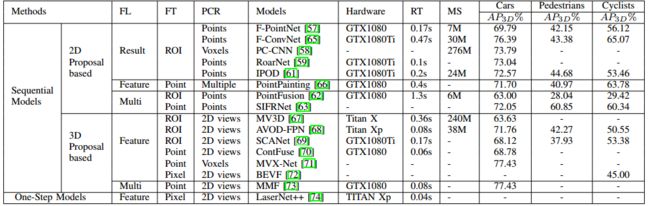
显示了在KITTI 3D物体检测基准上的3D物体检测模型的比较结果
总结和比较了动态目标检测模型
五,道路静止目标检测
基于相机-激光雷达融合的静止道路目标检测方法的最新进展。固定道路对象可分为道路上的物体(例如路面和道路标记)和越野物体(例如交通标志)。道路和越野物体为自动驾驶车辆提供法规、警告禁令和指导。
下图比较了车道/道路检测和交通标志识别(TSR)的典型模型结构。
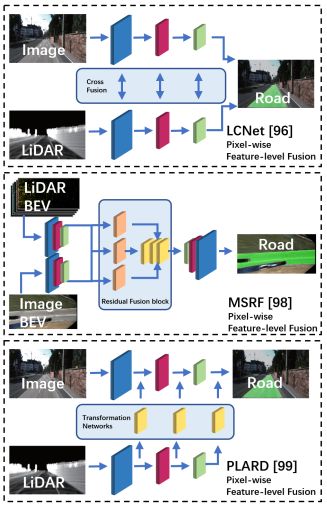
道路/车道检测的几种典型模型结构及融合方法
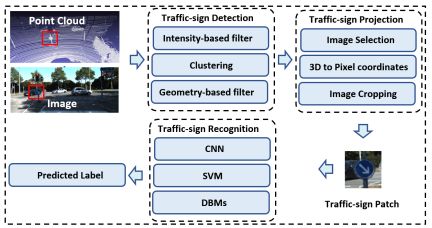
一种典型的基于融合的交通标志识别流程
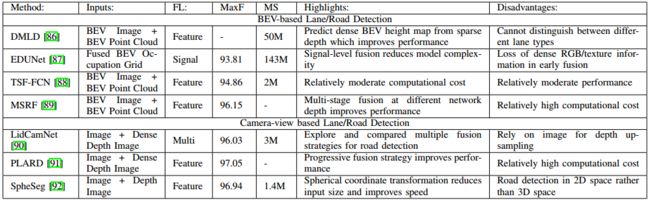
kitti数据集上不同模型的比较结果,并对这些模型进行了总结和比较
六,语义分割
现有的摄像机-激光雷达融合方法的二维语义分割、三维语义分割和实例分割。2D/3D语义分割的目的是预测每像素和每点的类标签,而实例分割也关注单个实例。
下图展示了3D语义分割网络和典型模型架构的时间轴。
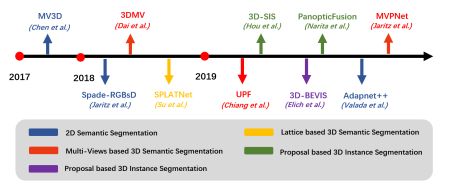
三维语义分割网络的时间轴及其相应的融合方法

语义分割的几种典型模型结构与融合方法
七,目标跟踪
多目标跟踪(Multiple object tracking,MOT)的目标是保持目标的身份,并在数据帧间(随着时间的推移)跟踪它们的位置,这对于自主车辆的决策是必不可少的。为此,本节回顾了基于cameraldar融合的目标跟踪方法。基于目标初始化方法,MOT算法可以分为基于检测的跟踪(DBT)和无检测跟踪(DFT)两种框架。DBT或tracking by detection框架利用对象检测器产生的一系列对象假设和更高层次的线索来跟踪对象。在DBT中,通过数据(检测序列)关联或多假设跟踪来跟踪目标。相反,DFT框架是基于有限集统计(fist)进行状态估计的。常用的方法有多目标多贝努利(成员)滤波和概率假设密度(PHD)滤波。
不同模型在KITTI多目标跟踪基准(car)上的性能,提供了DBT和DFT方法之间的比较。

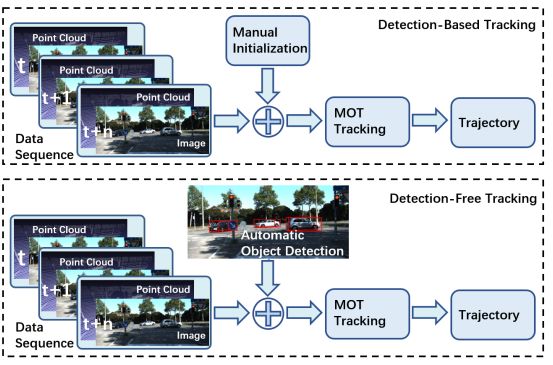
基于检测的跟踪(DBT)和无检测跟踪(DFT)方法的比较
八,在线交叉传感器校准
相机-激光雷达融合管道的先决条件之一是传感器之间的无缺陷注册/校准,这可能很难满足。由于机械振动和热波动,传感器之间的校准参数会不断变化。由于大多数融合方法对校准误差非常敏感,这可能严重削弱其性能和可靠性。此外,离线校准是一个麻烦和耗时的过程。因此,研究交叉传感器在线自动标定具有重要的实用价值。
A、 经典的在线校准
在线校准方法在没有校准目标的情况下,估计自然环境中的外源性。许多研究[124][125][126][127]通过最大化不同模式之间的互信息(MI)(原始强度值或边缘强度)来发现外部性。然而,基于MI的方法对于纹理丰富的环境、较大的去校准和传感器位移引起的遮挡不具有鲁棒性。或者,基于激光雷达的视觉里程计方法[128]使用相机的自我运动来估计和评估相机激光雷达的外部参数。尽管如此,[128]仍然难以进行大规模的去校准,无法实时运行。
B、 基于DL的在线校准缓解了上述挑战,Schneider等人。[129]设计了一个实时能力的CNN(RegNet)来估计外部性,它是在随机的去纤维数据上训练的。该方法将图像和深度特征分成两个平行的分支,并将它们串联起来生成融合后的特征映射。融合后的特征映射被输入到网络中的网络(NiN)模块和两个完全连接的层中,用于特征匹配和全局回归。然而,RegNet对传感器的固有参数是不可知的,一旦这些内在参数发生变化,就需要重新训练。为了解决这个问题,口径网[130]学会了以一种自我监督的方式最小化失调深度和目标深度之间的几何和光度不一致性。因为内部函数只在3D空间变换器中使用,所以校准网络可以应用于任何内部校准的相机。然而,基于深度学习的交叉传感器校准方法计算量大。
九,趋势、开放的挑战和有希望的方向
无人驾驶汽车中的感知模块负责获取和理解其周围的场景。它的下游模块,如计划、决策和自我定位,都依赖于它的输出。因此,它的性能和可靠性是整个无人驾驶系统能否胜任的先决条件。为此,应用激光雷达和摄像机融合技术提高感知系统的性能和可靠性,使无人驾驶车辆更能理解复杂场景(如城市交通、极端天气条件等)。因此,在本节中,我们将总结总体趋势,并讨论这方面存在的挑战和潜在的影响因素。
如表所示,我们的重点是提高融合方法的性能和融合管道的鲁棒性。
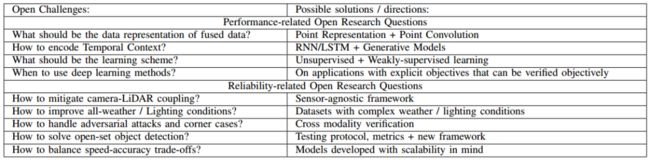
从上述方法中,我们观察到图像和点云融合方法的一些普遍趋势,总结如下:
•二维到三维:随着三维特征提取方法的发展,在三维空间中对物体进行定位、跟踪和分割已成为研究的热点。
•单任务到多任务:最近的一些工作[73][122]结合了多个互补任务,如目标检测、语义分割和深度完成,以获得更好的整体性能并降低计算成本。
•信号级到多级融合:早期的工作通常利用信号级融合,其中3D几何体被转换到图像平面,以利用现成的图像处理模型,而最近的模型尝试在多层次(例如早期融合、后期融合)和时间上下文编码中融合图像和激光雷达。
●总结
本文对自主驾驶环境下点云与图像融合的深度学习模型的最新研究进展进行了综述。具体地说,这篇综述基于它们的融合方法来组织方法,涵盖深度完成、动态和静态目标检测、语义分割、跟踪和在线交叉传感器校准等主题。此外,表中还列出了公开数据集的性能比较、模型的亮点和优缺点。典型的模型体系结构如图所示。最后,我们总结了总体趋势,并讨论了面临的挑战和可能的未来方向。这项调查也提高了人们的认识,并对一些被研究界忽视但却困扰着自动驾驶技术实际应用的问题提供了见解
资源
三维点云论文及相关应用分享
【点云论文速读】基于激光雷达的里程计及3D点云地图中的定位方法
3D目标检测:MV3D-Net
三维点云分割综述(上)
3D-MiniNet: 从点云中学习2D表示以实现快速有效的3D LIDAR语义分割(2020)
win下使用QT添加VTK插件实现点云可视化GUI
JSNet:3D点云的联合实例和语义分割
大场景三维点云的语义分割综述
PCL中outofcore模块---基于核外八叉树的大规模点云的显示
基于局部凹凸性进行目标分割
基于三维卷积神经网络的点云标记
点云的超体素(SuperVoxel)
基于超点图的大规模点云分割
更多文章可查看:点云学习历史文章大汇总
SLAM及AR相关分享
【开源方案共享】ORB-SLAM3开源啦!
【论文速读】AVP-SLAM:自动泊车系统中的语义SLAM
【点云论文速读】StructSLAM:结构化线特征SLAM
SLAM和AR综述
常用的3D深度相机
AR设备单目视觉惯导SLAM算法综述与评价
SLAM综述(4)激光与视觉融合SLAM
Kimera实时重建的语义SLAM系统
SLAM综述(3)-视觉与惯导,视觉与深度学习SLAM
易扩展的SLAM框架-OpenVSLAM
高翔:非结构化道路激光SLAM中的挑战
SLAM综述之Lidar SLAM
基于鱼眼相机的SLAM方法介绍
往期线上分享录播汇总
第一期B站录播之三维模型检索技术
第二期B站录播之深度学习在3D场景中的应用
第三期B站录播之CMake进阶学习
第四期B站录播之点云物体及六自由度姿态估计
第五期B站录播之点云深度学习语义分割拓展
第六期B站录播之Pointnetlk解读
[线上分享录播]点云配准概述及其在激光SLAM中的应用
[线上分享录播]cloudcompare插件开发
[线上分享录播]基于点云数据的 Mesh重建与处理
[线上分享录播]机器人力反馈遥操作技术及机器人视觉分享
[线上分享录播]地面点云配准与机载点云航带平差
点云PCL更多活动请查看:点云PCL活动之应届生校招群
扫描下方微信视频号二维码可查看最新研究成果及相关开源方案的演示:

如果你对本文感兴趣,请点击“原文阅读”获取知识星球二维码,务必按照“姓名+学校/公司+研究方向”备注加入免费知识星球,免费下载pdf文档,和更多热爱分享的小伙伴一起交流吧!

扫描二维码
关注我们
让我们一起分享一起学习吧!期待有想法,乐于分享的小伙伴加入免费星球注入爱分享的新鲜活力。分享的主题包含但不限于三维视觉,点云,高精地图,自动驾驶,以及机器人等相关的领域。
分享及合作方式:可联系微信“920177957”(需要按要求备注)联系邮箱:[email protected],欢迎企业来联系公众号展开合作。
点一下“在看”你会更好看耶
