浅析大规模多语种通用神经机器翻译方法
导语:只训练一个模型就能够支持在多个语言之间的翻译
| 作者 | 陈贺轩 单位 | 小牛翻译 陈贺轩,东北大学自然语言处理实验室研究生,研究方向为机器翻译。 小牛翻译,核心成员来自东北大学自然语言处理实验室,由姚天顺教授创建于1980年,现由朱靖波教授、肖桐博士领导,长期从事计算语言学的相关研究工作,主要包括机器翻译、语言分析、文本挖掘等。团队研发的支持140种语言互译的小牛翻译系统已经得到广泛应用,并研发了小牛翻译云(https://niutrans.vip)让机器翻译技术赋能全球企业。 |
目前,神经机器翻译(NMT)已经成为在学术界和工业界最先进的机器翻译方法。最初的这种基于编码器-解码器架构的机器翻译系统都针对单个语言对进行翻译。近期的工作开始探索去扩展这种办法以支持多语言之间的翻译,也就是通过只训练一个模型就能够支持在多个语言之间的翻译。
尽管目前最流行的Transformer模型已经大大推动了机器翻译在单个语言对上性能的提升,但针对多语言的机器翻译模型的研究源于其特殊的需求,如多语言之间互译的模型参数量、翻译服务部署困难等。尽管多语言NMT已经存在大量的研究,然而,识别语言之间的共性以及针对现实场景下的大规模多语言模型等,仍然存在问题和挑战。
一、Multilingual Machine Translation
多语言机器翻译的最理性的目标是通过单一模型能够翻译任意一个语言对。如果将所有语言对的全部都只看做为“源语言”-“目标语言”的这样一种特殊的单语言对,那么其概率模型仍可以表示为:
![]()
尽管不同的模型有不同的损失计算方式,以Dong等人[1]提出的模型为例,很多模型内部计算损失时,仍将依赖于特定语言对计算:
![]()
多语言机器翻译模型的研究存在着多个原因。
假设我们现在需要针对N个语言之间进行互译,传统的方法就是训练N(N-1)个互译的模型,如果通过某种中介语言,仍然需要训练2(N-1)个互译的模型。当需要互译的语言数N比较大的时候,相应的就会需要大量的模型训练、部署等,耗费大量的人力物力。而通过合理的设计和训练,获得单一模型实现这些语言之间的互译,就会极大的减少开销。
由于联合训练以及学习到的知识从高资源语言的迁移,多语言模型提高了在低资源甚至是零资源的语言对互译的性能。然而这也导致了对原本高资源语言对训练的干扰从而降低了性能。同时获得性能的提升仍是一个具有挑战性的问题。
从语言对之间映射的角度来看,基于源语端和目标语端所涵盖的语言数量,在多语言NMT模型中,存在三种策略,包括多对一、一对多以及多对多。多对一模型学习将任何在源语端的语言翻译成目标端的一种特定的语言,这种情况下通常会选取语料丰富的语言比如英语,相似的,一对多模型学习将在源语端的一种语言翻译成目标端任意一种语言。多对一这种模式通常会看作多领域学习的问题,类似于源语端的输入分布是不一致的,但是都会翻译成一种目标语。而一对多这种模式可以被看作是多任务的问题,类似于每一对源语到目标语看作一个单独的任务。多对多这种模式就是这两个模式的集合。
不管源语端和目标语端语言的数量,多语言机器翻译模型的提升也基于“相关领域”以及“相关任务”之间知识的迁移作用。
尽管多语言NMT已经被大量的研究,但是这种研究仍然存在着极大的限制,所验证的语言对数量也很有限。尽管单独的一个模型能将一个大规模语言对的所能达到的性能是值得研究的,但是存在着大量的困难:不同语言对之间的迁移学习;模型本身参数和学习能力的限制。在大规模语言对包括在低资源和高资源数据(这种高低的比较是通过整体数据量的对比)上多语言机器翻译的性能和问题也得到了广泛的研究和探讨。
二、训练策略
与针对单对语种的翻译模型的训练方法相比,由于模型和数据分布的不同,多语种的训练方法有着明显的不同。由于多语种数据中是由不同的语言对的数据构成,甚至不同的语言对的数量也有差异,存在数据不平衡的问题。这就使得如果采用与针对单对语种训练方式相同的策略会导致所得到的模型性能的降低。所以制定一个好的训练策略对多语言机器翻译模型是一个比较重要的事。
针对模型训练阶段,不同的模型结构决定不同的策略。Dong等人[1]针对一对多多语言机器翻译模式设计了单一编码器以及多个语言独立的解码器模型结构,在这个结构下,采用了一种轮换的方式去更新模型的参数,在更新迭代的过程中,固定相邻的n个批次的数据为同一种语言,同时轮换不同的语言以相同的方式,这种策略使得在针对单个语言的训练来看“批次”中的数据会变大,为n个批次数据的大小。Johnson等人[2]采用了更加简单的模型结构,与针对单对语种的机器翻译模型相同只采用一个编码器和一个解码器结构,并只针对源语句子上添加一个表示所翻译目标语的前缀标识来训练模型,这种极为简单的模型结构也对模型训练产生了极大的压力,由于数据的不平衡,采用过采样或者欠采样的方式,甚至在构建单个批次时也构建一定比例的不同语言对数量。
训练的策略也包括了针对无监督的训练方式(Sen等人[3])、知识精炼(Tan等人[4])以及在原有多语机器翻译上增加新语言对(Escolano等人[5])等不同训练策略。
三、大规模多语种机器翻译
为了去探索单个模型最大程度上学习大规模的语言数量。Aharoni等人[10]对此进行了研究和实现了大量的实验。
实验采用了Ha等人[6],Johnson等人[2]以及在源语句子上使得能够进行多对多的翻译。翻译模型采用完全基于Attention的Transformer模型架构(Vaswani等人[7])。在所有的实验结果中,采用BLEU(Papineni等人[8])的评测方式。在模型训练中,单个批次混合不同语言对数据。实验采用了内部数据集。该数据集包括102种语言对,由于语言对之间是相互的,可以将它们与英语进行“镜像”转换,每个语言对最多有100万个示例。这样一来,总共可以翻译103种语言,并同时训练204种翻译方向。
实验选取了不同语言族的10种语言:Semitic(Arabic(Ar),Hebrew(He));Romance(Galician(Gl),Italian(It) ,Romanian(Ro));Germanic(German(De),Dutch(Nl)); Slavic(Belarusian(Be),Slovak(Sk))以及Turkic(Azerbaijani (Az),Turkish(Tr))。
模型结构
实验所采用的模型是Transformer结构,如图1。
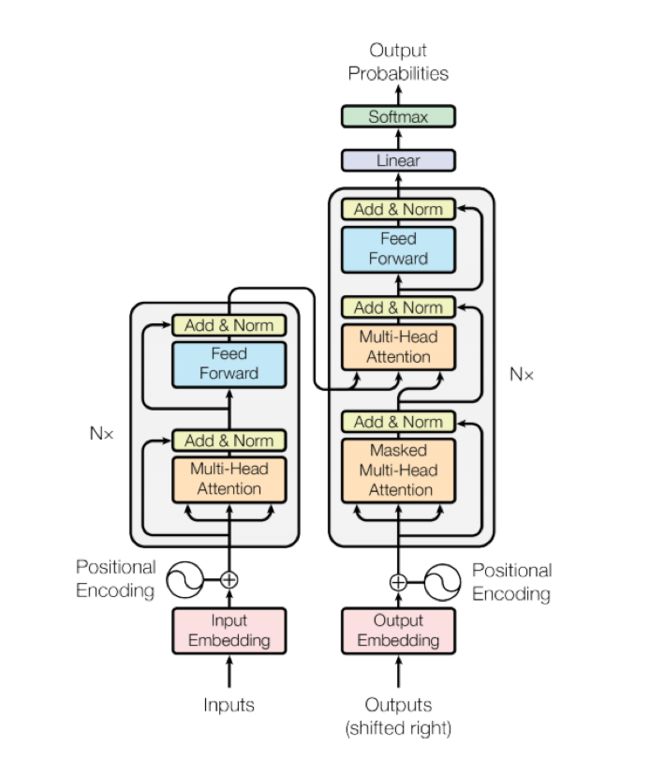
图1 Transformer模型结构
更多细节可以参考Vaswani等人[7]的工作。
实验结果
表1就是从10种语言翻译与英语的一对多、多对一和多对多实验结果。
其中上表表示了从10种语言翻译到英语的翻译结果,下表表示了从英语到10种语言的翻译结果。
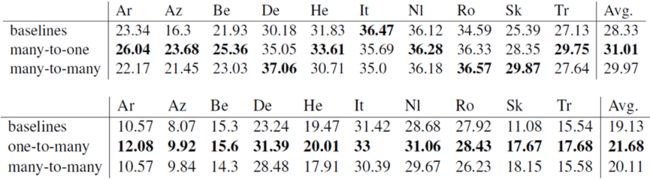
表1 高资源数据中一对多、多对一以及多对多的实验结果
分析
在实验中,针对103种语言构建了以英文为中心的多语言机器翻译。
在相同数据的情况下,多语言模型一对多、多对一以及多对多大多都高于单语对模型,表明模型具备同时训练更多语言对的能力。但是一些语言对仍然出现了高度的波动以及低于相应的单语对模型。这也说明在这种设置下,一些语言对受到了比较大的干扰比如Italian-English。
多语言模型模式中,一对多、多对一大都超过了多对多模型的性能。同样,这种优势可能是由于一对多和多对多模型处理较少的任务,而不像多对多模型那样在目标端偏向于英语。其中,多对一仍然存在着要弱于多对多的语言对,这种情况由于目标端大量的英文数据,潜在的可能由于受到相似语言之间的迁移学习以及解码端的过拟合问题。
以上结果表明,大量的多语言NMT确实可以在大规模环境中使用,并且可以在强大的双语基线上提高性能。
问题
尽管已经添加了大量的语种,显示了单模型进行多语言翻译的潜力。但是仍然是在一个比较受限的情况下,现实已经证明,海量的单语言对能够大大提高模型的翻译能力,但是多语言同时使用这样的海量数据的性能并没有得到合理的证明,同时实验使用的数据质量比较高,在现实中,采集的数据会存在大量的噪音,也会损失模型的性能。
四、总结和展望
自从多语言NMT的概念被提出后,相关的论文层出不穷。近年针对在实际中使用的大规模多语言机器翻译也受到了广泛的研究(Aharoni等人[10],Arivazhagan等人[9]),为在更复杂的真实世界的使用提供了有力的支持。
这种大规模多语言机器翻译所期待的优良特性包括:
-
在单个模型中考虑的语言数量方面的最大。在模型中多能互译的语言对越多越好,也就更能节省更多的资源;
-
知识从高资源语言对向低资源语言的最大正向迁移。这样不仅能够获得高资源语言对的性能,也能提高低资源语言对的性能,充分的利用了数据。
-
对高资源语言的最小干扰(负迁移)。避免其他因素对高资源语言对训练的消极影响。
-
健壮的多语言NMT模型,在现实的开放域设置中表现良好。有助于现实的部署和使用。
尽管当前取得了极大的进展,多语言机器翻译仍然有很多的问题和挑战。
参考文献
[1] Daxiang Dong, Hua Wu, Wei He, Dianhai Yu, and Haifeng Wang. 2015. Multi-task learning for multiple language translation.
[2] Melvin Johnson, Mike Schuster, Quoc V Le, et al. 2017. Google’s multilingual neural machine translation system: Enabling zero-shot translation.
[3] Sukanta Sen, Kamal Kumar Gupta, Asif Ekbal, Pushpak Bhattacharyya .2019.Multilingual Unsupervised NMT using Shared Encoder and Language-Specific Decoders
[4] Xu Tan, Yi Ren, Di He, Tao Qin, Zhou Zhao, Tie-Yan Liu.2019. Multilingual Neural Machine Translation with Knowledge Distillation
[5] Carlos Escolano, Marta R. Costa-jussà, José A. R. Fonollosa.2019. From Bilingual to Multilingual Neural Machine Translation by Incremental Training
[6] Thanh-Le Ha, Jan Niehues, and Alexander Waibel. 2016. Toward multilingual neural machine translation with universal encoder and decoder.
[7] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ?ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.
[8] Kishore Papineni, Salim Roukos, ToddWard, andWei- Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation.
[9] Naveen Arivazhagan, Ankur Bapna, Orhan Firat, Dmitry Lepikhin, Melvin Johnson, Maxim Krikun, Mia Xu Chen, Yuan Cao, George Foster, Colin Cherry, Wolfgang Macherey, Zhifeng Chen, Yonghui Wu. 2019. Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges
[10] Roee Aharoni, Melvin Johnson, Orhan Firat. 2019. Massively Multilingual Neural Machine Translation