机器学习面试题——评价指标
ML之评价指标
平时傻傻地分不清,到底啥是ROC,AUC,下面我理解一下:
说说机器学习评价指标
AUC是什么?AUC是否对正负样本比例敏感?
分类模型如何评价
准确率与精准率的区别
AUC的意义和两种计算方法
讲讲分类,回归,推荐,搜索的评价指标
AB test的原理
推荐系统中的评价指标
知识,你看了不代表你会了,而是要自己记笔记,或者给别人讲懂,才算是真的深刻理解了
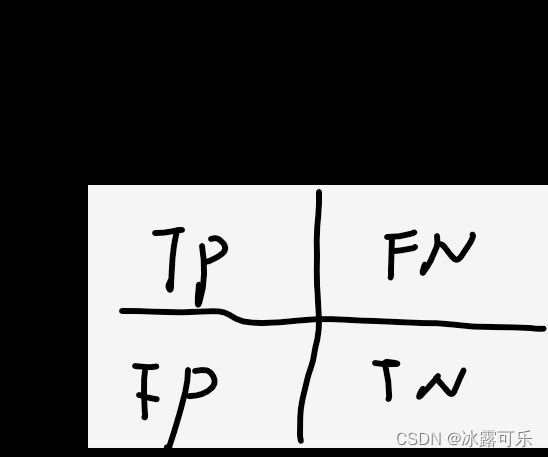
搞懂评价指标之前,需要知道啥是TP,FP,TN,FN?
先说一下含义:TP、FP、FN、TN分别为真阳性、假阳性和假阴性、真阴性。
简单来说,就是:
● 真阳性(True Positive,TP):标签为正类,预测为正类;
——TPR:true positive rate真阳性率,所有正例中,预测正确的比率【有的正被判为FN】
● 假阳性(False Positive,FP):标签为负类,预测为正类;
——FPR:false positive rate假阳性率,所有负例中,被误判为正例的比率【有的负例被判为正例了】
● 假阴性(False Negative,FN):标签为正类,预测为负类;
● 真阴性(True Negative,TN):标签为负类,预测为负类;
——这里不得不说,挺狗的一件事,咱们要是用英语去理解可能还好,但是要翻译为汉语再倒腾一遍,确实容易搞混淆了……
【粘贴图片到CSDN文章中也是可以的,只不过有时候网络不好,就无法粘贴而已】
准确率(Accuracy)
定义:即所有分类正确的样本占全部样本的比例

精确率/查准率(Precision)
定义:预测是正例的结果中,确实是正例的比例。Precision同样是衡量误检
分母是TP和FP,FP是原来为负,被误判为正了

题目: 准确率与精准率的区别,显然两者的公式,不一样,区别在分母,是总量,还是判为正样本的量。
推荐系统中的精确率:Precision=推荐正确的数量/推荐给定的列表长度

查全率(Recall)=真阳性率(TPR)
定义:即所有正例的样本中,被找出的比例。Recall同样是衡量漏检
也就是说,所有正,可能预测正确为TP,也可能被误判为负了FN
TP占比为recall,召回率:=真阳性率(TPR)
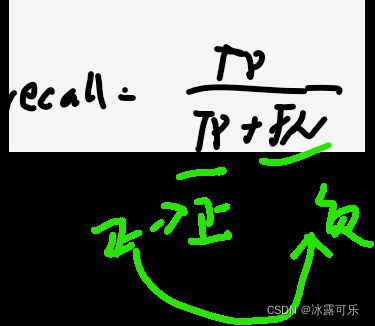
推荐系统中的recall:系统推荐正确的数量/用户实际点击的长度。


Precision和Recall的应用场景:
(1)地震的预测,对于地震的预测,我们希望的是Recall非常高,
也就是把正例尽可能预测为正例,别误判了,导致真的地震来了也不知道。
也就是说每次地震我们都希望预测出来。
这个时候我们可以牺 牲Precision。【既然希望把负例也判正例,阈值低,那精确度自然就降低了。】
情愿发出1000次警报,把10次地震都预测正确了;也不要预测100次对了8次漏了两次。
“宁错拿一万,不放过一个”,分类阈值较低
嫌疑人定罪基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。
即使有时候放过了一些罪犯,但也是值得的。
因此我们希望有较高的Precision值,可以合理地牺牲Recall。
【也就是说,不是罪犯的,你少判为罪犯,精确率提升,那可能是罪犯的就被判为无罪了,FN变大,那就是recall降低了】
“宁放过一万,不错拿一个”,“疑罪从无”,分类阈值较高
这俩是相反的极端走向:
我们知道随着阈值的变化Recall和Precision往往会向着反方向变化,
但有的场景我们希望Precision和Recall都最大。
所以我们需要一个综合评价两者的指标:F1-score
F1-score
定义:衡量Precision 和 Recall 之间的联系。自定义的一个公式:
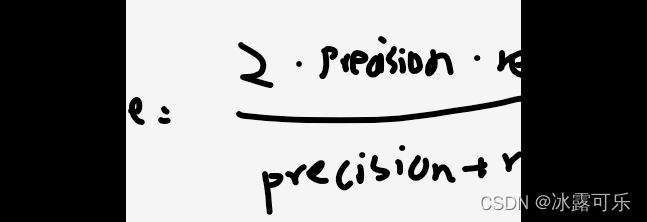
显然,当precision和recall都最大时,整体F1score才会最大,相当于折中妥协
推荐系统的F1-score也是这个定义,但是precision和recall的含义上面解释过了,有点区别。
ROC 和 AUC
AUC是一种模型分类指标,且仅仅是二分类模型的评价指标。
AUC是Area Under Curve的简称,那么Curve就是 ROC(Receiver Operating Characteristic),翻译为"接受者操作特性曲线"。
也就是说ROC是一条曲线,AUC是 一个面积值。
ROC曲线
ROC曲线为 FPR 与 TPR 之间的关系曲线,这个组合以 FPR 对 TPR,即是以代价 (costs) 对收益 (benefits),显然收益越高,代价越低,模型的性能就越好。
不同的分类阈值,得到的FPR和TPR不同,
上面解释过,FPR,TPR是啥意思
x 轴为假阳性率(FPR):在所有的负样本中,分类器预测错误的比例:
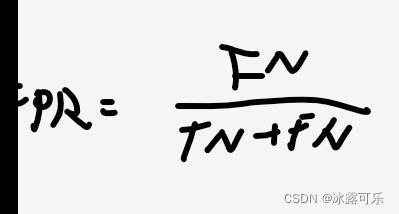
y 轴为真阳性率(TPR):在所有的正样本中,分类器预测正确的比例(等于Recall)

那么每一个分类阈值都可以得到一组(FPR,TPR)=(x,y),以此画出ROC曲线:
ROC推导过程,挺复杂:

AUC定义:
AUC 值为 ROC 曲线下方所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
AUC = 1,是完美分类器。【有的大厂就会考这个为选择题,很骚的】
0.5 < AUC < 1,优于随机猜测。有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。

以下为ROC曲线和AUC值的实例:

Precision-Recall曲线
PR曲线的横坐标是精确率P(precision),纵坐标是召回率R(recall)。
评价标准和ROC一样,先看平滑不平滑(蓝线明显好些)。
一般来说,在同一测试集,上面的比下面的好(绿线比红线好)。
当P和R的值接近时,F1值最大,此时画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1(光滑的情况下),此时的F1对于PRC就好像AUC对于ROC一样。
一个数字比一条线更方便调型。
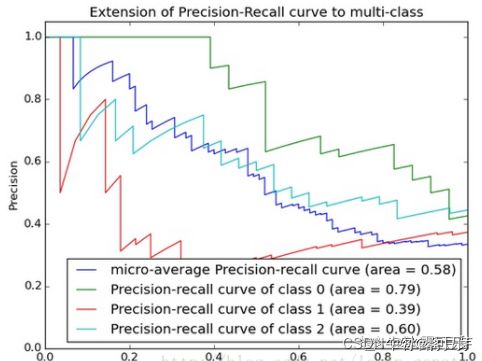
此时曲线上的点就对应F1。
P-R曲线同样可以用AUC衡量,AUC大的曲线越好。
IOU和mIOU
IOU(Intersection over Union)
iou:交集占并集的大小。交并比 跟踪,目标检测经常用
公式其实很简单,就是交集占并集的大小。
![]()
mIOU
mIOU一般都是基于类进行计算的,将每一类的IOU计算之后累加,再进行平均,得到的就是mIOU。
AP和mAP
AP(average Precision)和
mAP(mean average Precision)常用于目标检测任务中。
AP就是每一类的Precision的平均值。——这可不是准确率哦,而是精确率,所有正例中被检测出来的比率平均值。
而mAP是所有类的AP的平均值。
问题1:AUC是什么?AUC是否对正负样本比例敏感?AUC的意义和两种计算方法是什么?
答:不敏感:
AUC定义:AUC 值为 ROC 曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
**AUC还有另一个意义:**分别随机从正负样本集中抽取一个正样本,一个负样本,正样本的预测值大于负样本的概率。
![]()
分母是正负样本总的组合数,分子是正样本大于负样本的组合数
故,与正负样本的比例没啥关系:
所以答案是:AUC对正负样本比例不敏感
问题2:讲讲分类,回归,推荐,搜索的评价指标
分类指标:
上面那些个acc,precision,recall,F1score,ROC,AUC,NDCG, HR,LogLoss 等
——NDCG:这个评价指标名为Normalized Discounted cumulative gain直接翻译为归一化折损累计增益。它有一些前辈,我们先来介绍一下他的前辈们,然后再来介绍NDCG。
(1)CG:cumulative gain(CG)可翻译为累积增益,改评价指标只考虑相关性而没有考虑位置的影响。其计算方式也比较简单,对搜索相关性进行求和,公式如下:

在推荐系统中,[公式]表示第i个位置的item是否是用户喜欢的,喜欢为1,否则为0。CG只能反映总体情况,即反映该页面中推荐的所有item的总分是好是坏。
(2)DCG:discounted CG简称为DCG,这对CG的问题,DCG的计算方式考虑了位置因素。例如,被推荐的item排在第1位和排在第10位,他们的影响力是不同的,肯定是第1位的影响力更大。因为用户进去第一眼就能看到第1位的item。计算公式如下,第1位不需要衰减,而随着位次不断靠后,其影响力也不断减弱。

工业界:还有一种计算DCG常见的公式,如下式所示:

NDCG:ok,千呼万唤始出来,终于来到我们的主角了。搜索结果,或者召回结果,推荐结果等,这些结果是一个集合,对于不同的关键词,或者不同的用户系统返回的结果数量是不同的。而上面的CG和DCG他们只是单纯的进行求和**,无法进行不用用户之间的对比**,因此需要对其进行标准化,从而诞生了NDCG。 这里对DCG进行标准化的方式是对其处以IDCG,公式如下:


其中REL表示将原始的召回集合R按照得分从大到小排序后的集合,将排序后的集合计算DCG得到IDCG。标准化后得到的NDCG是一个相对值,**从而使得即使不同的用户之间可以进行比较。**IDCG表示的是召回的集合中的item用户都喜欢的最理想情况。所以IDCG中的分子部分其实都是1。
——HR命中率(Hit Rate,HR),它反映的是在推荐序列中是否包含了用户真正点击的item,公式如下,N表示推荐次数,hit()函数表示是否命中,即用户选择的item是否在推荐序列中,存在则为1,反之则为0。分母是用户数量,分子也是以用户数量。

平均:

——MRR:平均倒数排名(Mean Reciprocal Rank,MRR),该指标反应的是我们找到的这些item是否摆在用户更明显的位置,强调位置关系,顺序性。公式如下,N表示推荐次数,[公式]表示用户真实访问的item在推荐列表中的位置,如果没在推荐序列中,则p为无穷大,1/p为0。

举个栗子:加入我们去top-5,推荐[1,2,3,4,5]这5个item,然后测试数据中对应的访问的item为3,则1/p=1/3。
—— **MAP:**平均精度均值(Mean Average Precision,MAP),该指标在目标检测、多标签等领域也都有应用,是一个应用很广的评价指标。MAP是计算AP(Average Precision)的均值,因此我们需要先知道如何计算AP。其中hit就是之前HR中的hit函数值域为{0,1},而这边的p就是在MRR中和位置相关的p。

举个栗子:假设两个推荐系统甲、乙,分别对a,b,c三个item进行推荐,结果为:
系统 推荐item 位置系数1/p
甲: [0,1,0], [1/1,1/2,1/3]
乙: [0,0,1] [0, 1/2,1/3]
则我们可以计算得到AP(甲)=1/2,AP(乙)=1/3,因此甲更优。 可以发现AP是在单个user或者说单次推荐中进行计算的,将所有User或者说多次推荐后的AP进行平均就是MAP。公式如下,

——**F-Score:**刚刚我们提到同时考虑Precision和Recall的MAP,这里还有一个可以同时考虑P和R的指标就是F-score。这个指标其实也很常用,这里就不过多介绍了。公式如下,

——LogLoss:通常还会计算一下LogLoss来进行对比,这里就不赘述了,LogLoss就是我们在训练模型用到的损失函数。
回归指标(回头我们会讲损失函数,regression的损失函数那会透彻地讲)
有几个指标:均方误差(MSE),均方根误差(RMSE),MAE(平均绝对误差),R Squared
推荐任务评价指标:
离线评估 offline evaluation
评分预测:对于评分预测模型:训练数据集训练好模型,测试数据集预测用户对物品的评分。评价指标:MAE和RMSE
对于Top N模型:对排名进行评估。评价指标:准确率acc,召回率recall,F1score
在线评估 online evaluatuion
A/B test:将用户划分为A,B两组,A实验组用户,接受所设计的推荐算法推荐的商品,B对照组用户,接受基线方法推荐的商品。通过对比两组用户的行为来评估推荐算法的性能。
**AB test的原理:**说白了就是优化方案和baseline,看看谁更好?
CTR:用户点击率,通过该算法计算出的被点击的项目,占推荐项目总数的百分比
CR:用户转化率,用户购买的项目,占被点击的项目的比率。
搜索任务评价指标:Accuracy、Precision、Recall、AUC、P-R曲线