Python字符串及其操作---索引、合并、拆分、格式化
Python字符串及其操作
- 1.概述
- 2.通用序列操作
-
- 2.1索引
- 2.2 切片
- 2.3 字符串合并
- 2.4 乘法
- 2.5 成员资格
- 2.6 长度、最小值和最大值
- 3 字符串格式化
-
- 3.1 字符串格式化
- 3.2 字符串的转义字符
- 3 字符串函数(方法)
-
- 3.1 测试函数
- 3.2 字符串查找函数
- 3.3 字符串替换函数
- 3.4 字符串合并
- 3.5 拆分函数
- 3.6 字符串与日期的转换
1.概述
- 在Python中,字符串是除数字外最重要的数据类型。字符串无处不在:将字符串输出到屏幕上;从用户的键盘输入读取字符串;文件通常被视为大型字符串;网页大部分是由文本组成的。
- 字符串是一种聚合数据结构,可充分利用索引和切片—用于从字符串中提取子串。
- 而Python正则表达式库,是一种用来处理字符串的微型语言,但功能强大。
2.通用序列操作
- Python中,字符串、列表和元组都属于序列。
- 序列有一些通用的操作。包括:索引(indexing)、切片(slicing)、加(adding)、乘(multiplying)、检查某个元素是否属于序列的成员(成员资格)、计算序列长度、找出最大元素和最小元素等。
2.1索引
- 序列中的所有元素都是有编号的—从0开始递增。这些元素可以通过编号分别访问。索引有正索引和负索引,可根据实际情况选用。
- 字符串就是一个由字符组成的序列,处理字符串时,经常需要访问其中的各个字符。索引0指向第1个字符。
例如:字符串’apple’的正索引和负索引

s = 'apple'
#索引
s[0]
for i in s:
print(i,end=" ")
for i in range(len(s)):
print(s[-(i+1)],end="") #反转列表,用索引
for i in reversed(s): #反转列表 用函数
print(i,end="")
2.2 切片
- 与使用索引访问单个元素类似,可以使用分片操作来访问一定范围内的元素。分片是实际应用中经常使用的技术,被截取的部分称为“子串”
- Python 3支持的分片格式为:S[i:j:k]
表示:索引S对象中的元素,从索引为i直到索引为j-1,每隔k个元素索引一次,第三个限制k为步长,默认为1,也可以使用负数作为步长,步长-1表示分片将会从右至左进行而不是通常的从左至右,实际效果主是将序列反转。 - 在Python中,还可以使用split()函数来截取字符串。
#切片索引,类似列表
food = "apple pie"
food[0:5]
food[0:5:2]
food[::2]
food[1::2]
food[::-1] #反转字符串 还可以用函数 reversed(s)
#一个应用
def get_ext(fname):
"""
返回文件的扩展名
"""
dot = fname.rfind(".") #获得.的索引(从右边开始找)
if dot == -1:
return ''
else:
return fname[(dot+1):]
get_ext("apple.avi")
2.3 字符串合并
这一节参考了博客.
Python中有join()和os.path.join()两个函数,具体作用如下:
join(): 连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
os.path.join(): 将多个路径组合后返回
-
join()函数
语法: ‘sep’.join(seq)
参数说明
sep:分隔符。可以为空
seq:要连接的元素序列、字符串、元组、字典
上面的语法即:以sep作为分隔符,将seq所有的元素合并成一个新的字符串
返回值:返回一个以分隔符sep连接各个元素后生成的字符串. -
os.path.join()函数
语法: os.path.join(path1[,path2[,…]])
返回值:将多个路径组合后返回
注:第一个绝对路径之前的参数将被忽略.
#字符串拼接,合并
str1 = "Hello, ";str2 = "LL!"
str1 + str2
#'Hello, LL!'
#对列表进行操作(分别使用' '与':'作为分隔符)
seq1 = ['hello','beautiful','gril','ll']
print (' '.join(seq1))
#hello good boy doiido
print (':'.join(seq1))
#hello:good:boy:doiido
#对字符串进行操作
seq2 = "hello beautiful gril ll"
print (':'.join(seq2))
#h:e:l:l:o: :b:e:a:u:t:i:f:u:l: :g:r:i:l: :l:l
#对元组进行操作
seq3 = ('hello','beautiful','gril','ll')
print(':'.join(seq3))
#hello:beautiful:gril:ll
#对字典进行操作,实际上是对字典的键进行操作
seq4 = {'hello':1,'beautiful':2,'gril':3,'ll':4}
print ('-'.join(seq4))
#hello-beautiful-gril-ll
#合并目录
import os
os.path.join('/hello/','deer/gril/','ll')
#'/hello/deer/gril/ll'
2.4 乘法
- 用数字x乘以一个序列会生成新的序列,在新的序列中,原来的序列被重复x次。
str1 = "love you!"
str1*3 #'love you!love you!love you!'
li = ['I','love','you']
li*3 #列表长度扩展为9.
tup = ('I','love','you')
tup*3 #元组长度扩展为9.
dict1 = {'I':5,"love":2,'you':0}
dict1*3 #注意字典不是序列,不能乘。
2.5 成员资格
为了检查一个值是否在序列中,可以使用in运算符。该运算符检查某个条件是否为真,若为真返回True,否则返回False。
#成员资格 in
s = "你怎么那么好看?"
"你" in s
"我" in s
li = list(s)
"你" in li
"我" in li
tup = tuple(s)
"你" in tup
"我" in tup
2.6 长度、最小值和最大值
len、min和max都是内置函数。
- len—返回序列中包含的元素个数。
- min—返回序列中的最小值。
- max—返回序列中的最大值。
3 字符串格式化
3.1 字符串格式化
C语言使用函数printf()格式化输出结果,Python也提供了类似功能。
Python将若干值插入带有“%”标记的字符串中,从而可以按照指定格式输出字符串。
语法:
“%s” % str1
“%s %s” % (str1, str2)
- Python格式化字符串的替代符及含义:
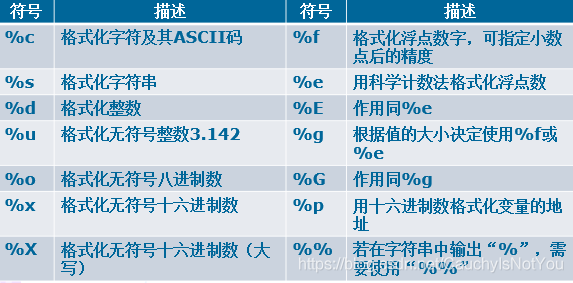
- 符号、对齐和用0填充
在字段宽度和精度之间还可以放置一个“标志”,该标志可以是零、加号、减号或空格。零表示数字将会用0填充。
#字符串格式化
s = 'Version'
n = 1.0
print("%s" %s) # %s 字符串
print("%s %d" %(s,n)) # %d 整型
print("%s %.1f" %(s,n)) # %f 浮点型
'''
输出:
Version
Version 1
Version 1.0
'''
#带精度的格式化
n = 3.1415926
print("%f" %n) #3.141593 直接输出
print("%.2f" %n) #3.14 保留2位小数
print("%.3f" %n) #3.142 保留3位小数
from math import pi
print('%010.2f' %pi) #表示字段宽度为10(包括小数点),精度为2,空位用0填充。
print('%-10.2f' %pi)
print('%10.2f' %pi) #用(-)号来左对齐数值。
print(('%+5d' %10)+'\n'+('%+5d' %-110)) #(+)号标示出 符号
'''
0000003.14
3.14
3.14
+10
-110
'''
3.2 字符串的转义字符
- 计算机中存在可见字符与不可见字符。可见字符指键盘上的字母、数字和符号。不可见字符是指换行、回车、制表符等字符。
- 对于不可见字符,Python使用的方法类似于C语言,都是使用“\”作为转义字符。
- Python还提供了函数strip()、lstrip()、rstrip()去除字符串中的转义字符。

#转义字符的应用
print("\' and \" are quotes")
print("\\ must be written \\\\") #"\\\\",第1,3反斜线表示转义字符。
print("one\ntwo\nthree")
print("hello\tworld\n")
print(r"hello\tworld\n") #加个r,可以忽略转义字符的作用,直接输出原始内容。
print(len("\\")) #计算字符长度时,不包括转义字符"\"
print(len("a\nb\nc"))
'''
输出:
' and " are quotes
\ must be written \\
one
two
three
hello world
hello\tworld\n
1
5
'''
3 字符串函数(方法)
- Python字符串自带了大量很有用的函数,要查看这些函数,可调用dir并将参数指定为任何字符串(如:dir(’ '))。
- 虽无必要准确记住所有函数功能,但最好有个大致了解,这样有益于需要时去查询具体使用。
- 字符串函数的详细介绍可参阅其文档字符串或Python在线文档
此处介绍常用的字符串函数。
3.1 测试函数
用于检测字符串是否为特定格式的函数,它们组成了一个最大的字符串函数组。
测试函数都返回True或False,因此也称为布尔函数或谓词。

s = 'abcdefg hhh'
#字符串测试函数 startswith endswith.....
s.startswith("b") #是否以"b"开头
s.startswith("abc")
s.isupper()
3.2 字符串查找函数

- 说明:函数index和find之间的差别在于没有找到指定子串的情形。函数index引发异常ValueError,而函数find将返回-1。
#查找函数应用
str1 = "I love you"
print(str1.find("o"))
print(str1.rfind("o"))
print(str1.index("o"))
print(str1.rindex("o"))
print(str1.find("dog"))
print(str1.index("dog"))
'''
3
8
3
8
-1
Traceback (most recent call last):
File "", line 6, in
print(str1.index("dog"))
ValueError: substring not found
'''
3.3 字符串替换函数
Python字符串自带了两个替换函数,如下表所示
 注意:使用替换函数可轻松地删除字符串中的子串。
注意:使用替换函数可轻松地删除字符串中的子串。
#字符串替换
s = "up, up and away"
s1 = "up,\tup\tand\taway"
print(s)
print(s.replace("up", "down"))
print(s.replace('up','')) #直接删掉了'up'
print(s1)
print(s1.expandtabs(8))
print(s1.expandtabs(10))
3.4 字符串合并
Python可使用“+”连接不同的字符串。除此之外,还可以使用join函数(是split方法的逆方法)和reduce函数实现字符串的合并。
join函数的举例见2.3节。
使用reduce函数连接字符串
from functools import reduce
import operator
strs = ["Hello","world","hello","China!"]
operator.add(1,2) #加法1+2
reduce(operator.add, [1,2,3,4,5]) #(((1+2)+3)+4)+5
#用reduce实现对空字符串”的累计连接,每次连接列表strs中的一个元素
res = reduce(operator.add,strs,"")
print(res)
3.5 拆分函数
拆分函数将字符串拆分成多个子串。如下表所示。

#例6-13:拆分字符串
url='www.google.com'
print(url.partition('.'))
print(url.rpartition('.'))
print(url.split('.'))
story='A long time ago, a princess ate an apple.'
print(story.split()) #默认以空格分隔
'''
('www', '.', 'google.com')
('www.google', '.', 'com')
['www', 'google', 'com']
['A', 'long', 'time', 'ago,', 'a', 'princess', 'ate', 'an', 'apple.']
'''
#例6-14:调用split()截取子串
sentence="Bob said: 1, 2, 3, 4, 5"
#根据空格获取子串,原串中含6个空格,返回7个子串
print(sentence.split())
#根据逗号取子串,原串中含4个逗号,返回5个子串
print(sentence.split(","))
#根据逗号个数分割字符串,将原串分割为4个子串
print(sentence.split(",",3))
print(sentence.split(",",2))
print(sentence.split(",",1))
'''
3.6 字符串与日期的转换
- 在实际应用中,经常需要将日期类型与字符串类型互相转换。
- Python提供了time模块处理日期和时间。函数strftime()可以实现从时间到字符串的转换。
- 字符串到时间的转换要进行两次转换,需要使用time模块和datetime类。
。。。
参考资料:liyumei老师的课件.