爱番番企业查询结果优化实践

作者 | summer
导读:爱番番企业查询汇集了全网2亿+企业多维度全方位信息,使用开源全文搜索引擎Elasticsearch(下文简称ES)作为搜索平台,致力于让用户更快更准的找到所需企业,但怎样能让用户搜索到满意的符合预期的结果呢?本文将会讲述爱番番企业查询在检索结果优化方面的实践,期望与大家一同交流。
全文3943字,预计阅读时间10分钟。
01 初识
数据同步,平台搭建省略,咱们直奔主题,本文中的样例来源于测试录入,仅用于dsl查询语句结果展示。
我:hello ES ,很高兴与你相识,我现在有个需求,需要根据关键信息查询出包含该关键信息的企业,用什么比较合适呢 ?
ES:匹配查询 match 最合适不过了,它是一个高级 全文查询 既能处理全文字段,又能处理精确字段。
我:企业维度好多,我想多个字段进行匹配,使用 match 有些麻烦,有更便捷的方式吗?
ES:可以试试multi_match, multi_match默认情况下,它会为每个字段生成一个 match 查询。
我:哇,太好了,我试试。
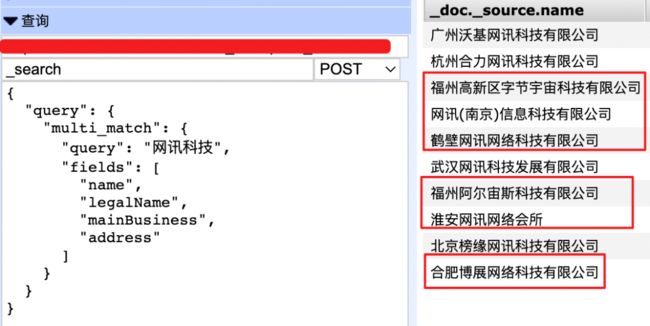
查到结果了,但结果中有些 name 中没有 " 网讯科技 " 其他字段中可以查到,有些 " 网讯科技 " 没在一起不是连续匹配的,甚至有些数据顺序还不一样,这样的结果是我们想要的吗 ?
每个平台对结果有自己的要求,有自己的评判标准,不能一概而论,我们通过用户调研,行为分析等方式发现用户主要关注以下几点:
-
查询结果与关键词的匹配度,主要侧重企业名称和法人;
-
期望可以根据用户关注的条件,查询到相关企业信息;
-
在关键词匹配到的前提下,希望能够按照企业健康情况排列( 如:经营状态是否正常,注册资本怎么样,是否存在风险等 )。
如何让用户关注的企业被检索出来呢 ?该如何进行优化呢 ?
02 探索
想要解决问题,先要知道问题出现的原因,这样才能针对性的解决,下面让我们走进es吧。
ES 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上,全文搜索主要包括索引创建和索引查询两个部分。
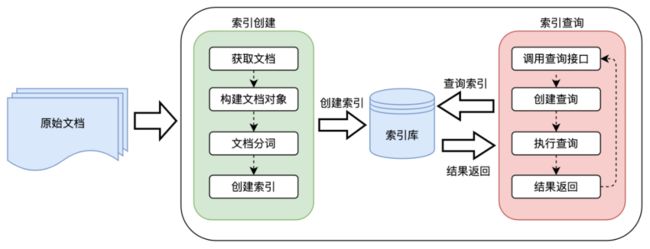
- 索引创建:文档,将原始文档按照一定规则分词,创建索引的过程。
分词:analysis 即文本分析,是把全文本转化为一系列单词( term / token )的过程,也叫分词;在 es 中通过 analyzer ( 分词器 ) 实现分词,可使用内置分词器也可按需定制分词器。
analyzer ( 分词器 ):
由三部分组成:
-
Character Filter:将文本中 html 标签剔除掉;
-
Tokenizer:按照规则进行分词,在英文中按照空格分词;
-
Token Filter:将切分的单词进行加工,小写,删除 stopwords,增加同义词;
会按照规则进行分词,可通过 _analyze 查询分词情况。
创建索引:
倒排序索引包含两个部分:
-
单词词典:记录所有文档单词,记录单词到倒排列表的关联关系;
-
倒排列表:记录单词与对应文档结合,由倒排索引项组成;
倒排索引项:
-
文档 id( DocId, Document Id ),包含单词的文档 id,用于获取原始信息;
-
词频( TF,Term Frequency ),记录 Term 在每篇文档中出现的次数,用于后续相关性算分( TF/IDF,BM25 );
-
位置( Position ),记录 Term 在每篇文档中的分词位置( 多个 ),用于做词语搜索( Phrase Query );
-
偏移( Offset ),记录 Term 在每篇文档的开始和结束位置,用于高亮显示等。
由此可知索引中记录了分词的位置信息, 可用来解决不连续匹配的情况。
- 索引查询:根据关键字查询索引、根据索引查找具体文档、从而找到要查询的内容返回结果的过程。
ES 使用 布尔模型(Boolean model) 查找匹配文档,并用一个名为 实用评分函数(practical scoring function) 的公式来计算相关度。这个公式借鉴了 词频/逆向文档频率(term frequency/inverse document frequency) 和 向量空间模型(vector space model),同时也加入了一些现代的新特性,如协调因子(coordination factor),字段长度归一化(field length normalization),以及词或查询语句权重提升。
(详见官方文档:
https://www.elastic.co/guide/cn/elasticsearch/guide/current/practical-scoring-function.html#practical-scoring-function)
默认情况下,返回结果是按相关性倒序排列的,每个文档都有相关性评分,用一个正浮点数字段 _score 来表示。_score 的评分越高,相关性越高。查询语句会为每个文档生成一个 _score 字段。评分的计算方式取决于查询类型不同的查询语句用于不同的目的:fuzzy 查询会计算与关键词的拼写相似程度,terms 查询会计算找到的内容与关键词组成部分匹配的百分比,但是通常我们说的 relevance 是我们用来计算全文本字段的值相对于全文本检索词相似程度的算法。
影响相关度主要工具:
1、查询时权重提升,任意类型的查询都能接受 boost 参数;
2、使用 constant_score 查询,为任意一个匹配的文档指定评分,忽略 TF/IDF 信息;
3、使用 function_score 查询,它允许为每个与主查询匹配的文档应用一个函数,可以改变甚至完全替换原始查询评分 _score 。
可通过 explain 获取 dsl 查询结果的评分细节,仅做调试,生产环境不建议使用。
03 优化
有了相关原理的支持,下面让我们看下上述用户关注问题在爱番番中的解决实践吧。
3.1 关键词匹配度
1、添加单独根据企业名称、法人等用户重点关注信息短语匹配查询
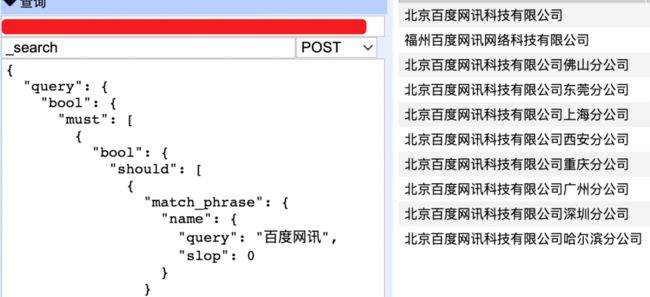
match_phrase 要求必须命中所有分词,并且返回的文档命中的词也要按照查询短语的顺序,使用 slop 设置词的间距,要求较严格,满足条件才能被查询到。
2、设置企业名称和法人权重,法人加入短语匹配
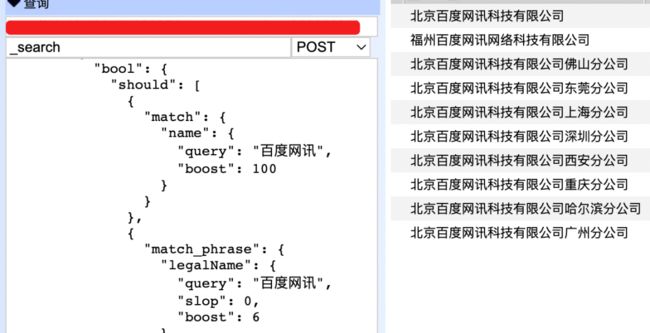
可以根据数据质量通过 boost 调整权重,根据数据长度适当使用短语匹配,match 和 match_phrase 搭配使用,即能避免单独使用match_phrase 导致的数量减少又能提高文档相关性评分。
3.2 添加筛选项
将用户关注的条件添加到筛选项里面,让用户设置筛选条件,根据筛选条件过滤,查询到符合条件的企业。
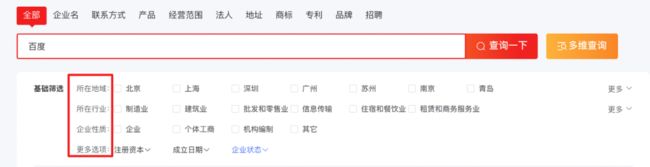

使用 bool 查询的过滤器 filter,过滤器可减少查询范围,被过滤掉的内容不会影响返回内容的排序,不计算相关性评分,可以使用 ES 内部的缓存,提升查询速度。
3.3 自定义评分
function_score 查询,能够将全文查询与最新发生这种因子结合在一起评分,可以不完全根据评分 _score 或时间 date 进行排序;可以使两个效果融合:仍然根据全文相关度进行排序,但也会同时考虑其他因素。
function_score 提供了五种打分函数:
-
weight:为每个文档应用一个简单而不被规范化的权重提升值,最终结果_score乘以一个权重数值;
-
random_score:为每个用户都使用一个不同的随机评分对结果排序;
-
field_value_factor:使用某个字段影响_score;
-
decay fucntion:包括 gauss、exp、linear 三种衰减函数;
-
script_score:这是最灵活的方式,使用自定义脚本控制评分计算;
结合爱番番自身场景,因子较多,涉及到逻辑处理,我们选择了最灵活的script_score。

在脚本中通过 doc[‘field’] 获取文档字段,doc[‘field’].value 获取文档字段值。
使用了自定义评分最终结果的 score 记为 result_score 的计算过程如下:
-
原始分数:原始文档相关性评分 score ,记为query_score 。
-
自定义函数得分:执行自定义打分函数得到的新的文档分数,记为 func_score 。
-
最终结果 score:最终文档分数 result_score 等于 query_score 与 func_score 按某种方式计算的结果(计算方式由参数 boost_mode决定,默认是相乘)。
评分因子较多,每一个小的调整都会导致结果变更,调整前需要确定结果优化评判标准,调整中要有所侧重,有所平衡,上线后要采集用户查询满意度,或通过埋点等方式侧面评估效果,同时进行 badcase 收集,便于后续优化。
3.4 主动干预
影响相关性评分因子较多,我们需要根据数据情况进行取舍,达到结果的相对平衡,难免会有 badcase 的出现,为了提升效果,我们还进行了如下优化:
1、提取关键词
对重点信息( 如:企业名称 )可以提取关键词,添加 mapping ,关键词使用短语匹配,提升相关性评分,关键词抽取可查看《企业知识图谱技术与应用》。
2、二次排序
针对用户查询结果设置规则提取一定数量,根据规则进行关键词匹配,匹配到关键词的企业排名放到前面。
最终查询结果:

04 总结
查询结果优化是个循序渐进的过程,需要不断调整,对比优化效果,其中免不了有一些权衡和取舍,找到适合自己产品的最优设置。
爱番番企业查询结果优化就介绍到这里了,但这并不意味着我们的优化到此结束,优化出适合自己业务,符合用户要求的查询结果,是我们长期的目标,我们会为此不断努力。
————END————
推荐阅读:
百度工程师带你探秘C++内存管理(理论篇)
YYEVA动效播放器–动态元素完美呈现新方案
百度交易中台之资产系统架构浅析
从零到一了解APP速度测评
流日志轻松应对“10亿级别IP对”复杂场景,实现超大规模混合云网络流量可视化
百度App Android启动性能优化-工具篇
数字人技术在直播场景下的应用