CVPR2022 | 通过目标感知Transformer进行知识蒸馏
前言 本文来自读者投稿,我们会在群内发最近几天出来的最新顶会论文,大家可以及时去阅读这些顶会,并写一个解读给我们投稿,会发稿费。加群请扫描文末二维码。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文:Knowledge Distillation via the Target-aware Transformer
代码:暂未发布
背景
蒸馏学习是提高小神经网络性能事实上的标准,以前的工作大多建议以一对一的空间匹配方式将教师的代表特征回归到学生身上。
然而,人们往往忽略这样一个事实,由于结构的差异,同一空间的语义信息通常是变化的,这大大削弱了一对一的蒸馏方法的基本假设。他们高估了空间顺序的先验性,而忽略了语义不匹配的问题,即在同一空间位置上,教师特征图的像素往往比学生的像素包含更丰富的语义。
为此,论文提出一种新的一对一空间匹配知识蒸馏方法。具体而言,论文允许教师特征的每一个像素都被提炼到学生特征的所有空间位置给出由一个由目标感知的transformer产生的相似性。

图1语义不匹配的图示
从图1可以看出教师模型有着更多的卷积操作,生成的教师特征图有着更大的感受野,并且包含更多的语义信息,通常的做法在在一对一的空间中直接回归学生和老师的特征匹配的做法可能不是理想的,因此论文提出一对多通过目标感知transformer进行知识蒸馏,可以让老师模型的空间成分被提炼到整个学生模型的特征图上。
一个基本的假设是每个像素的空间信息是相同的。在实践中,这种假设通常是无效的,因为学生模型通常比教师模型有更少的卷积层。
图1 (a)显示了一个例子,即使在相同的空间位置,学生特征的接受域往往显著地比老师的小,因此包含较少的语义信息。计算蒸馏损失方法一般需要从中选择源特征图老师和学生的目标特征图,这两个特征图必须具有相同的空间方面。
如图 1 (b) 所示,计算损失以一对一的空间匹配方式。
图1 (c)中,我们的方法在每个空间位置提取教师的特征通过参数化为学生特征的所有分量通过参数化为学生特征的所有分量。论文使用参数相关关系来衡量学生特征和教师特征的表征成分的语义距离,用来控制特征聚合的强度,这解决了知识蒸馏一对一的匹配的弊端。
贡献
1、论文提出通过目标感知的transformer进行知识蒸馏,使得整个学生能够分别模仿教师的每一个空间组件。通过这种方式,论文可以提高匹配能力进而提高知识蒸馏的性能。
2、论文提出分层蒸馏法,将局部特征与全局依赖性一起转移,而不是原始的特征图。这使得论文能够将所提的方法应用于因特征图的大尺寸而承担沉重的计算负担的应用。
3、通过应用论文的蒸馏框架,与相关的替代方案相比,论文在多个计算机视觉任务上实现了最先进的性能。
方法
1、拟定方案
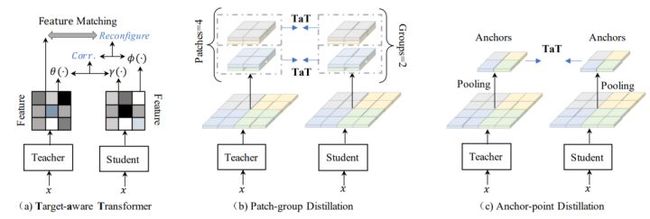
提出一对所有的空间匹配知识蒸馏途径允许教师的每个特征位置以动态的方式教授整个学生的特征。为了使整个学生模仿教师的空间分量,论文提出了目标感知的Transformer(TaT),以像素方式重新配置学生特征在特定位置的语义。给定教师的空间的分量(对齐目标),论文利用TaT引导整个学生在相应位置重建特征。论文使用一个线性算子来避免改变学生语义的分布,转换操作可以被定义为:
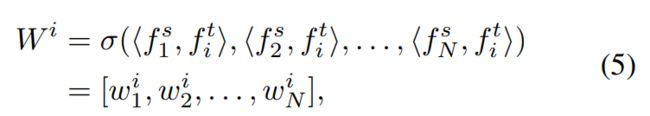
通过将这些相关的语义汇总到所有的组件中,论文得到了:

在目标感知Transformer的指导下,重新配置的学生特征可以被表述为:

TaT知识蒸馏的目标可以通过以下方式给出:

所提方法的总损失为:


图2(a)目标感知的transformer。以教师特征和学生特征为条件,计算转换映射,然后用相应的教师特征最小化L2损失。
2、分层蒸馏
论文提出一个分层蒸馏的方法来解决大特征图的限制,包括两个步骤:1)patch-group 蒸馏法,将整个特征图分割为更小的patchs,以便从教师到学生蒸馏出局部信息;2)进一步将局部的patchs总结为一个向量并将其提炼为全局信息。
2.1 patch-group蒸馏法

教师和学生特征被切片并被重新组织为蒸馏组。通过在一个组中连接patches,论文明确引进patches之间的空间相关性,patches之间的空间相关性超越了他们本身。在蒸馏过程中,学生不仅可以学到单个像素,而且可以学到他们之间的相关性。在实验中论文研究了不同大小的组的效果。
2.2 Anchor-point 蒸馏
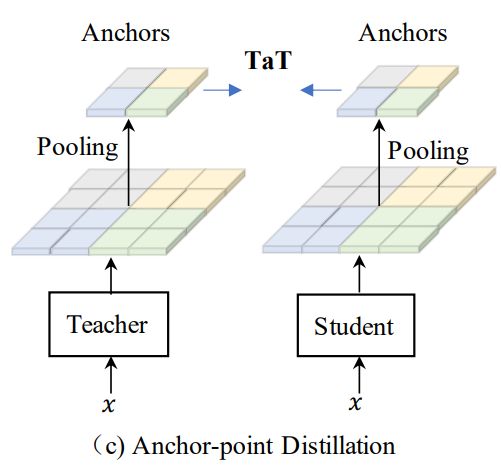
一种颜色表示一个区域。论文利用平均池化来提取在给定特征图中局部区域的锚点,形成一个更小尺寸的新的特征图。产生的锚点特征会参与蒸馏过程。由于新的特征图由原始特征的总和组成,它可以近似地替代原始特征来获取全局依赖性。
论文为语义分割设计的目标可以表述为:

实验
图片分类实验方面,论文利用在知识蒸馏领域被广泛使用的数据集例如Cifar-100和ImageNet,并表明论文的模型与许多最先进的基准相比,可以显著提高学生的性能。此外,论文还做了语义分割的实验来进一步验证论文方法的泛化性。
1、实验数据集:
Cifar-100、ImageNet、Pascal VOC、COCOStuff10k
2、图片分类:
在Cifar-100上的结果

在Cifar-100数据集上的Top-1准确率
论文的方法在七个教师-学生设置中有六个超过了所有基线,而且通常有显著的优势。这证明了该方法的有效性和泛化能力。
在ImageNet上的结果

在ImageNet数据集上的Top-1准确率
论文的方法同样以显著的优势超越目前最先进的方法。
3、语义分割

在Pascal VOC上与不同方法比较的语义分割结果

在COCOStuff10k上与不同方法比较的语义分割结果
论文的方法明显超过所有的baseline。
结论
这项工作通过目标感知的transformer开发了一个知识蒸馏的框架,使得学生能够将有用的语义聚集在自己身上以提高每个像素的表现力。这使得学生能够作为一个整体来模仿老师,而不是并行地将每个部分的分歧最小化。
论文的方法通过由patch-group蒸馏和anchor-point蒸馏组成的分层蒸馏,成功地拓展到了语义分割,旨在关注局部特征和长期依赖。论文进行了全面的实验,以验证该方法的有效性,并提高了最先进的水平。
我们建立了一个知识星球,星球内每天都会布置一些作业,这些作业会引导大家去学一些东西。如果有人觉得自己一个学习没有动力,或想要养成一个很好的学习习惯,每天完成在知识星球内的作业是一个不错的做法。
另外,我们建立了一个交流群,群内会经常发布最近几天出来的最新顶会论文,大家可以下载这些论文去阅读,如果看完写一个解读,可以给我们投稿,我们将付稿费。既可以保持阅读最新顶会、持续输出的习惯,又能提高写作能力,日后还可以在简历上写在公众号CV技术指南上投稿几十、一百余篇文章,对于提高能力、保持学习态度、个人履历等方面会是一大作用。
加群加星球方式:关注公众号CV技术指南,获取编辑微信,邀请加入。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

其它文章
招聘 | 迁移科技招聘深度学习、视觉、3D视觉、机器人算法工程师等多个职位
计算机视觉入门路线
YOLO系列梳理(一)YOLOv1-YOLOv3
YOLO系列梳理(二)YOLOv4
YOLO系列梳理(三)YOLOv5
Attention Mechanism in Computer Vision
从零搭建Pytorch模型教程(五)编写训练过程--一些基本的配置
从零搭建Pytorch模型教程(四)编写训练过程--参数解析
从零搭建Pytorch模型教程(三)搭建Transformer网络
从零搭建Pytorch模型教程(二)搭建网络
从零搭建Pytorch模型教程(一)数据读取
StyleGAN大汇总 | 全面了解SOTA方法、架构新进展
一份热力图可视化代码使用教程
一份可视化特征图的代码
工业图像异常检测研究总结(2019-2020)
关于快速学习一项新技术或新领域的一些个人思维习惯与思想总结