神经网络与深度学习-9- 网络结构 -PyTorch
参考
《神经网络与深度学习》
课时14 张量数据类型-1_哔哩哔哩_bilibili
深度神经网络(DNN) - _yanghh - 博客园
目录
1: 常见网络结构
2: 前馈神经网络
3: 反向传播算法
4: Softmax 分类例子
## Versions:
- [Version 1.0](https://docs.google.com/presentation/d/11mR1nkIR9fbHegFkcFq8z9oDQ5sjv8E3JJp1LfLGKuk/edit?usp=sharing)
一 常见网络结构
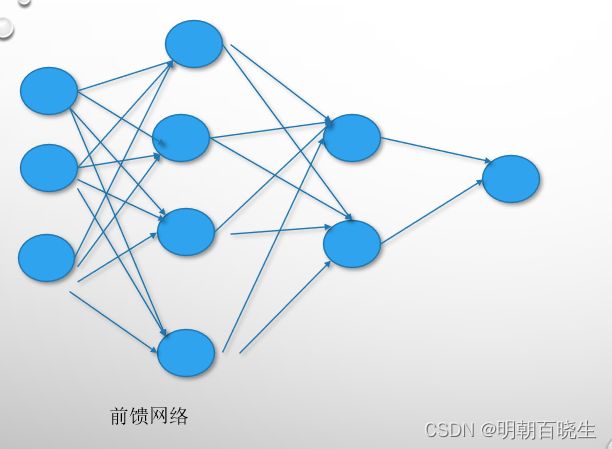
1.1 前馈网络
定义:
每一层中的神经元接收前一层神经元的输出,并输出到下一层神经元。
主要包括:
全连接前馈网络 和 卷积神经网络
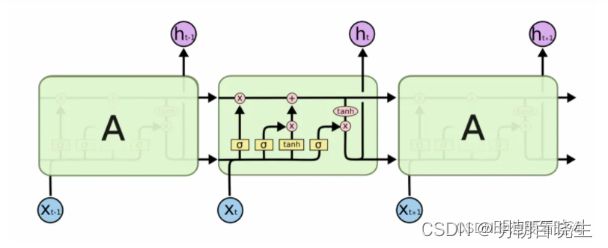
1.2 记忆网络
称为反馈网络,网络中的神经元不但可以接收其它神经元的信息,也可以接收自己的历史信息。 增加了记忆功能
主要包括:
RNN,LSTM,Hopfield,玻尔兹曼机,受限玻尔兹曼机
1.3 图网络
前面输入都可以表示向量或者向量序列,实际应用中很多数据是图结构数据,比如
知识谱,社交网络,分子网络。
主要包括:
图卷网络 Graph Conolutional Network
图注意网络: Graph Attention Network GAT
消息传递网络 Message Passing Neural Netwrok
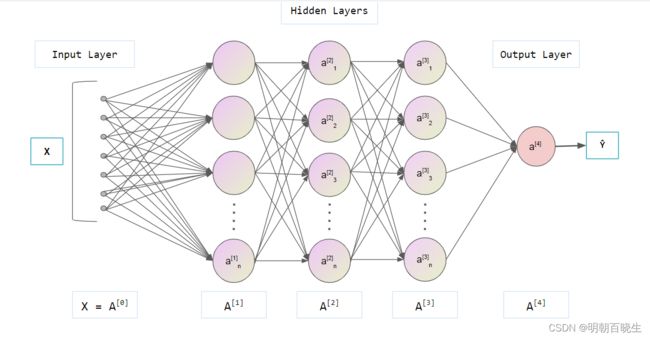
二 前馈神经网络
2.1 前馈神经网络记号
 : 神经网络层数
: 神经网络层数
![]() :第l层神经网络的个数
:第l层神经网络的个数
![]() :第L层神经元的激活函数
:第L层神经元的激活函数
![]() : l-1层到l层的权重系数矩阵
: l-1层到l层的权重系数矩阵
![]() : l-1层到l层的偏置
: l-1层到l层的偏置
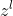 : l 层神经元的输入
: l 层神经元的输入
![]() : l层神经元的输出
: l层神经元的输出
![]()
![]()
2.2 参数学习
这边以分类问题为例,其损失函数为
![]()
给定训练集![]() ,将每个样本输入给前馈神经网络,得到网络的输出为
,将每个样本输入给前馈神经网络,得到网络的输出为![]() , 结构化风险函数为
, 结构化风险函数为
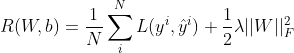
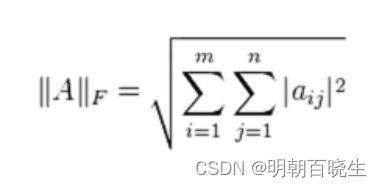
F: Frobenius 范数
在梯度下降法的每次迭代中,第l层的参数![]() 和
和![]() 参数更新方式为
参数更新方式为
![]()
![]()
在神经网络的训练过程中经常使用反向传播算法来高效计算梯度
四 张量数据类型
pytorch 没有string 类型,对于单个字母用one-hot向量表示
如果是字符串,用word2vec 或者 glove 来实现
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 5 21:50:02 2022
@author: cxf
"""
import torch
def Debug():
data = torch.randn(2,3)
print("\n 数据类型: ",data.type(),"\t 维度 ",data.dim())
data_gpu = data.cuda()
hardware = isinstance(data_gpu, torch.cuda.FloatTensor)
print("是否为GPU类型:",hardware)
a = torch.tensor(1.0) #标量
print("\n 标量: ",a.type(),a.shape,len(a.shape),a.size(),"\t 维度 ",a.dim()) #标量维度
if __name__ == "__main__":
Debug()二 反向传播算法

以DNN为例:
输入:
训练集
验证集V, 学习率
repeat
训练集随机排序
for n =1 ... N do
选取样本
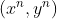
前向传播:
(神经元输入)
(激活函数)
反向传播计算每一层的误差
求
层:
更新每一层的导数
更新每一层的参数
损失函数

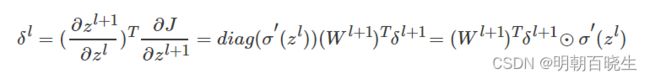
import torch
import torch.utils.data as Data
import numpy as np
'''
shuffle:(数据类型 bool)
洗牌。默认设置为False。在每次迭代训练时是否将数据洗牌,默认设置是False。
将输入数据的顺序打乱,是为了使数据更有独立性
num_workers:(数据类型 Int)
工作者数量,默认是0。使用多少个子进程来导入数据。
设置为0,就是使用主进程来导入数据。注意:这个数字必须是大于等于0的,负数估计会出错。
drop_last:(数据类型 bool)
丢弃最后数据,默认为False。设置了 batch_size 的数目后,
最后一批数据未必是设置的数目,有可能会小些。这时你是否需要丢弃这批数据。
'''
def load(x,y,batch):
BATCH_SIZE = batch #批训练数据量的大小
trainset = Data.TensorDataset(x, y) #训练数据集
#创建一个dataloader类的实例
loader = Data.DataLoader(
dataset=trainset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2,
drop_last = True)
return loader
'''
显示数据集
'''
def sampling(x,y,batch):
loader = load(x,y,batch)
for epoch in range(1):
print("\n--------------------")
for batch_idx, (batch_x, batch_y) in enumerate(loader):
#print("\n batch_idx:{},\n batch_x:{}, \n batch_y:{}".format(batch_idx, batch_x, batch_y))
return batch_x, batch_y
'''
随机采样的API
'''
def sampling(x,y,batch,N):
indices = np.arange(0,N)
np.random.shuffle(indices)
indices1 = indices[0:batch]
index = torch.tensor(indices1,dtype=torch.int)
#indices = torch.tensor([0, 2])
trainData = torch.index_select(x, 0, index) #行抽取
trainLabel = torch.index_select(y, 0, index) #行抽取
print("\n trainlabel ",trainLabel)
return trainData, trainLabel
----------------
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 8 17:09:56 2022
@author: chengxf2
https://blog.51cto.com/u_15132389/4755744
"""
import numpy as np
import torch
from sklearn.datasets import load_iris
import sampling
import torch.nn.functional as F
class BP:
'''
损失值
args
y: 标签值
predY: 预测值 [150, 4]
return
loss 值
'''
def loss(self, y, predY):
s = -torch.mm(y.T, torch.log(predY))
loss = s.numpy()[0,0]
#print("\n s ",loss)
return s
'''
激活函数
args
x: 输入
return
y: 输出
'''
def softmax(self,x):
y = F.softmax(x,dim=0) #1 行
"""
z = torch.exp(x)
s = z.sum()
y = z/s
"""
return y
'''
训练
args
trainData: 训练数据集
trai
'''
def train(self):
m=150
W =0
trainData = self.x
trainLabel = self.y
W = torch.ones((3,4))
m,n = self.x.shape[0],self.x.shape[1]
print("\n m ",m, "\t n ",n)
trainData, trainLabel = sampling.sampling(self.x,self.y, self.batch,m)
for j in range(self.maxIter):
for i in range(self.batch):
x = trainData[i].view(4,1)
y = trainLabel[i].view(3,1)
a = torch.mm(W, x)
predY = self.softmax(a)
deltaW = torch.mm(predY-y,x.T)
W= W-self.learnRate*deltaW
loss = self.loss(y, predY)
print("\n i %d loss %7.3f"%(j,loss))
print(W)
'''
加载数据集#[100,4]
'''
def load_data(self):
iris = load_iris()
x = iris.data #数据
y = iris.target #特征
print("\n数据集数据的形状:", x.shape) #[150,4]
print("\n数据集的标签:\n", y) #[0,1,2]
self.x = torch.tensor(x, dtype=torch.float)
self.m, self.n = self.x.shape[0], self.x.shape[1]
self.y =torch.zeros([self.m,3],dtype=torch.float)#one-hot
for i in range(self.m):
j = y[i]
self.y[i,j] =1.0
def __init__(self):
self.m = 0
self.n = 0
self.batch = 20 #从每类数据中随机选取40个
self.maxIter = 1000 #最大迭代次数
self.learnRate = 0.1 #学习率
if __name__ == "__main__":
bp = BP()
bp.load_data()
bp.train()