改进YOLOv5系列:结合ShuffleNet V2主干网络,高效CNN架构设计的实用指南
- 统一使用 YOLOv5、YOLOv7 代码框架,结合不同模块来构建不同的YOLO目标检测模型。
在设计一个高效网络时应该遵循以下几点建议:
- 使用平衡性的卷积(还有通道宽度)
- 谨慎使用分组卷积的数量
- 降低网络分支的数量
- 降低元素级操作次数
- 同时在实际使用也应该注意到操作平台的影响。
本篇为 YOLOv5 + ShuffleNetV2 改进
文章目录
-
- 一、ShufflNet V2论文理论部分
-
- shufflNetv2高效的网络结构
- 二、结合YOLOv5 应用 ShuffleNetV2 为主干网络
-
- 2.1 网络配置
- 3.2 核心代码
- 3.2 运行
一、ShufflNet V2论文理论部分
近来,深度CNN网络如ResNet和DenseNet,已经极大地提高了图像分类的准确度。但是除了准确度外,计算复杂度也是CNN网络要考虑的重要指标,过复杂的网络可能速度很慢,一些特定场景如无人车领域需要低延迟。另外移动端设备也需要既准确又快的小模型。为了满足这些需求,一些轻量级的CNN网络如MobileNet和ShuffleNet被提出,它们在速度和准确度之间做了很好地平衡。今天我们要讲的是ShuffleNetv2,它是旷视最近提出的ShuffleNet升级版本,并被ECCV2018收录。在同等复杂度下,ShuffleNetv2比ShuffleNet和MobileNetv2更准确。

shufflNetv2高效的网络结构
在ShuffleNet V1中,面临的主要问题是在有限计算资源的情况下,特征通道数量不够多,为了解决这个问题,采取了两项新技术:pointwise group conv和 bottle-like 结构,与此同时,“通道打乱操作”引入到网络中增强信息的交互性。
4条指导准则总结如下:
1x1卷积进行平衡输入和输出的通道大小;
组卷积要谨慎使用,注意分组数;
避免网络的碎片化;
减少元素级运算。
根据前面的4条准则,作者分析了ShuffleNetv1设计的不足,并在此基础上改进得到了ShuffleNetv2,两者模块上的对比如图所示:
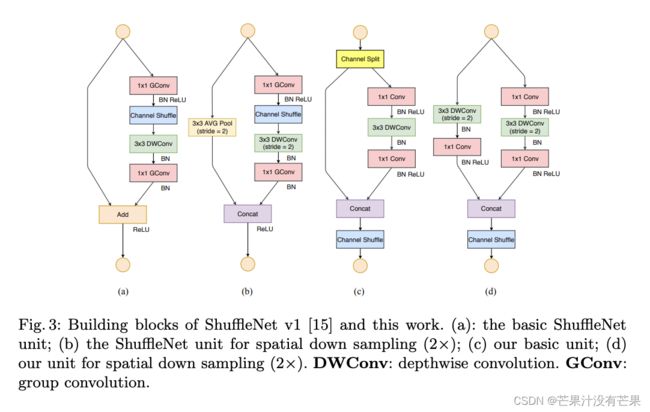
在ShuffleNetv1的模块中,大量使用了1x1组卷积,这违背了G2原则,另外v1采用了类似ResNet中的瓶颈层(bottleneck layer),输入和输出通道数不同,这违背了G1原则。同时使用过多的组,也违背了G3原则。短路连接中存在大量的元素级Add运算,这违背了G4原则。
为了改善v1的缺陷,v2版本引入了一种新的运算:channel split。具体来说,在开始时先将输入特征图在通道维度分成两个分支:通道数分别为 c’ 和 c-c’ ,实际实现时 c’ = c / 2。左边分支做同等映射,右边的分支包含3个连续的卷积,并且输入和输出通道相同,这符合G1。而且两个1x1卷积不再是组卷积,这符合G2,另外两个分支相当于已经分成两组。两个分支的输出不再是Add元素,而是concat在一起,紧接着是对两个分支concat结果进行channle shuffle,以保证两个分支信息交流。其实concat和channel shuffle可以和下一个模块单元的channel split合成一个元素级运算,这符合原则G4。
对于下采样模块,不再有channel split,而是每个分支都是直接copy一份输入,每个分支都有stride=2的下采样,最后concat在一起后,特征图空间大小减半,但是通道数翻倍。
ShuffleNetv2的整体结构如表2所示,基本与v1类似,其中设定每个block的channel数,如0.5x,1x,可以调整模型的复杂度。
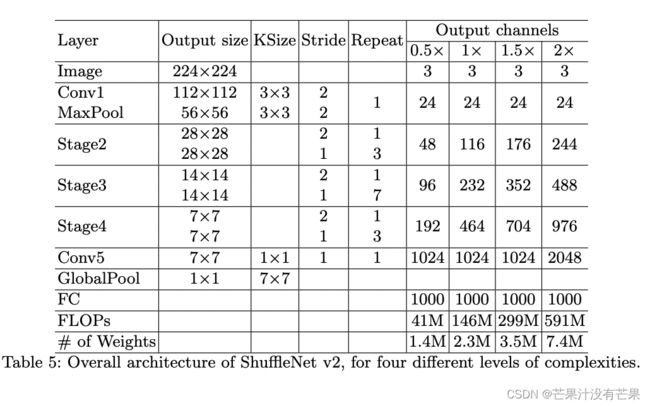
值得注意的一点是,v2在全局pooling之前增加了个conv5卷积,这是与v1的一个区别。最终的模型在ImageNet上的分类效果如表3所示:
可以看到,在同等条件下,ShuffleNetv2相比其他模型速度稍快,而且准确度也稍好一点。同时作者还设计了大的ShuffleNetv2网络,相比ResNet结构,其效果照样具有竞争力。
二、结合YOLOv5 应用 ShuffleNetV2 为主干网络
2.1 网络配置
1.增加ShuffleNetV2Block.yaml文件
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
backbone:
# [from, number, module, args]
[[-1, 1, Conv_maxpool, [24]], # 0-P2/4
[-1, 1, ShuffleNetV2Block, [116, 2]], # 1-P3/8
[-1, 3, ShuffleNetV2Block, [116, 1]], # 2
[-1, 1, ShuffleNetV2Block, [232, 2]], # 3-P4/16
[-1, 7, ShuffleNetV2Block, [232, 1]], # 4
[-1, 1, ShuffleNetV2Block, [464, 2]], # 5-P5/32
[-1, 3, ShuffleNetV2Block, [464, 1]], # 6
[-1, 1, SPPF, [1024, 5]], # 7
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 8
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 11
[-1, 1, Conv, [256, 1, 1]], # 12
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 15 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 12], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 18 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 8], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 21 (P5/32-large)
[[15, 18, 21], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
3.2 核心代码
1.在common中新增以下代码
class Conv_maxpool(nn.Module):
def __init__(self, c1, c2): # ch_in, ch_out
super().__init__()
self.conv= nn.Sequential(
nn.Conv2d(c1, c2, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(c2),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
def forward(self, x):
return self.maxpool(self.conv(x))
class ShuffleNetV2Block(nn.Module):
def __init__(self, inp, oup, stride): # ch_in, ch_out, stride
super().__init__()
self.stride = stride
branch_features = oup // 2
assert (self.stride != 1) or (inp == branch_features << 1)
if self.stride == 2:
# copy input
self.branch1 = nn.Sequential(
nn.Conv2d(inp, inp, kernel_size=3, stride=self.stride, padding=1, groups=inp),
nn.BatchNorm2d(inp),
nn.Conv2d(inp, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True))
else:
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential(
nn.Conv2d(inp if (self.stride == 2) else branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
nn.Conv2d(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1, groups=branch_features),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = self.channel_shuffle(out, 2)
return out
def channel_shuffle(self, x, groups):
N, C, H, W = x.size()
out = x.view(N, groups, C // groups, H, W).permute(0, 2, 1, 3, 4).contiguous().view(N, C, H, W)
return out
第二步:
然后在 在yolo.py中配置
找到./models/yolo.py文件下里的parse_model函数,将类名加入进去
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部
对应位置 下方只需要增加 代码
参考代码
elif m in [ShuffleNetV2Block, Conv_maxpool]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not outputss
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
3.2 运行
python train.py --cfg ShuffleNetV2Block.yaml即可