一键解锁,2022阿里顶会创新技术前沿进展
过去多年来,阿里巴巴一直坚持把技术的持续创新力作为重要的企业能力,持续推动对下一代技术的探索创新。单是今年上半年,阿里巴巴在计算机科学前沿领域里,被收录的中国计算机协会推荐的国际A类顶会论文已经达到200余篇。
今天,我们聚焦计算机视觉、自然语言处理、机器学习、数据库、计算机系统五大技术领域,为大家精选了25篇有突破性的顶会论文,一起探索前沿热点创新成果。
希望本文能对大家提供一些有价值的参考,欢迎大家一起在留言区讨论。
Part 1 计算机视觉领域
编者按:CVPR是计算机视觉方向的三大顶级会议之一,主要内容是计算机视觉与模式识别技术;IJCAI是人工智能领域中最主要的学术会议之一;ICLR是深度学习领域顶会之一,关注有关深度学习各方面的前沿研究;ACM MM是多媒体领域顶会,研究领域覆盖图像、视频、音频、人机交互、社交媒体等多个主题。这里精选了其中九篇有代表性的工作为大家进行简要介绍。
1. 用于单目物体位姿估计的端到端概率n点透视算法
CVPR 2022:EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation
论文摘要:利用透视点(PnP)基数从单个 RGB 图像中定位 3D 物体是计算机视觉领域一个长期存在的问题。在端到端深度学习的驱动下,近期的研究建议将 PnP 解释为一个可微分层,如此 2D-3D 点对应就可以部分地通过反向传播梯度 w.r.t. 物体姿态来学习。然而,从零开始学习整套不受限的 2D-3D 点在现有的方法下很难收敛,因为确定性的姿态本质上是不可微的。
这篇论文提出了一种用于普遍端到端姿态估计的概率 PnP 层——EPro-PnP(end-to-end probabilistic PnP),它在 SE 流形上输出姿态的分布,实质地将分类 Softmax 带入连续域。2D-3D 坐标和相应的权值作为中间变量,通过最小化预测姿态与目标姿态分布之间的 KL 散度来学习。其基本原理统一了现有的方法,类似于注意力机制。EPro-PnP 的性能明显优于其他基准,缩小了基于 PnP 的方法与基于 LineMOD 6DoF 的姿态估计以及 nuScenes 3D 目标检测基准的特定任务方法之间的差距。

2. 基于重投影提升神经辐射场的视角外插能力
CVPR 2022:Ray Priors through Reprojection: Improving Neural Radiance Fields for Novel View Extrapolation
论文摘要:神经辐射场 (NeRF) 已成为场景表征以及高质量图像合成的有效方案。传统 NeRF的主要问题在于:其无法在与训练视点有着显著不同的新视角下进行高质量的渲染。对此,我们提出了RapNeRF (RAy Priors),通过随机视线投射以及视角先验信息大大提升了极端视角的鲁棒性,保证了高质量的图像合成。

3. 面向未裁剪视频的基于多层级一致性的自监督视频表征学习
CVPR 2022:Learning from Untrimmed Videos: Self-Supervised Video Representation Learning with Hierarchical Consistency
论文摘要:自然的无剪切长视频通常包含更丰富的语义信息,且更容易获取,在实际场景中有着非常重要的应用价值。然而现有视频自监督方法在长视频中却呈现出明显的性能下降,主要原因是其太强的时空一致性假设,这种假设在长视频中难以成立。因此,我们提出了分层一致性的方法—HiCo来直接进行长视频自监督,HiCo主要包括视觉一致性学习和主题一致性学习,即时间距离相近但视觉相似的片段保持视觉一致,时间相差较远但是表达内容语意相同的片段被认为主题一致,从两个维度进行表征学习。
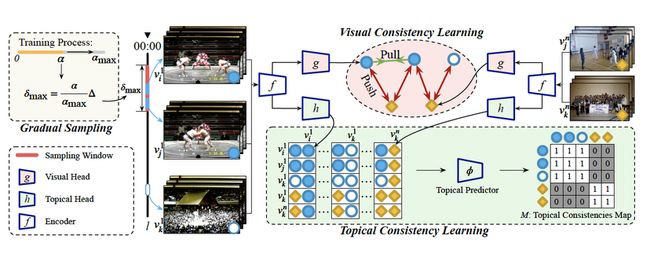
4. 关注视觉骨干:一种用于端到端视觉定位的查询调整优化网络
CVPR 2022:Shifting More Attention to Visual Backbone: Query-modulated Refinement Networks for End-to-End Visual Grounding
论文摘要:本工作主要解决视觉定位领域,现有模型的视觉骨干网络抽取特征与查询文本不一致的问题。我们注意到抽取不一致特征的根源在于视觉骨干网络是文本不感知的,因此提出利用查询文本特征对预训练的骨干网络进行调整,以提升视觉定位模型的性能。
5. LTP:基于车道片的自动驾驶轨迹预测
CVPR 2022:LTP: Lane-based Trajectory Prediction for Autonomous Driving
论文摘要:随着自动驾驶技术的快速发展,如何理解并预测动态驾驶环境中周围目标的行为已经成为自动驾驶系统落地过程中的重要一环。轨迹预测任务的结果是自动驾驶系统自主决策的重要信息之一。该任务旨在根据目标(如车辆、行人等交通参与者)当前及历史轨迹信息、环境信息等,对目标未来可能的行驶轨迹进行预测。轨迹预测任务存在交互关系难建模、预测过程多模态和预测结果难解释的难点。
因此,我们提出了一种基于车道片级锚点的两阶段轨迹预测方法。该方法将细粒度切分的车道片作为一种具有解释性的可共享型锚点,使用图神经网络和Transformer分别建模地图和周围目标的形状信息和交互关系,通过基于方差的非最大值抑制策略选择代表性轨迹以确保预测输出的多模性。在多个数据集上的实验表明,该方法的性能优于现有方法,在保证预测结果多模性的基础上能够有效提升轨迹预测的准确性。此外,该方法可以在闭环仿真中实现较低的碰撞率和较少的越界行为,并获得可靠的性能。
6. 用于无监督域适应的跨域Transformer
ICLR 2022:CDTrans: Cross-Domain Transformer for Unsupervised Domain Adaptation
论文摘要:为了解决目标场景无标注数据的问题,本文提出了一种基于交叉注意力机制的跨域方法(CDTrans)。该方法利用了交叉注意力机制对于噪声的强鲁棒性的特点,来进行不同场景的分布对齐。
7. Entroformer:基于Transformer的图像压缩概率模型
ICLR 2022:Entroformer: A Transformer-based Entropy Model for Learned Image Compression
论文摘要:图像压缩是计算机视觉领域一个基本性的任务。图像压缩的关键在于如何估计更准确的数据分布空间, 从而能够对图像数据进行更好的编码, 来得到更优的压缩率。本文提出基于Transformer的概率模型来得到更准确的分布估计, 同时对模型的效率进行了优化, 在提升了压缩性能的同时保持了较优的解压缩效率。
8. 感知图像内容的创意布局自动生成方法
IJCAI 2022:Composition-aware Graphic Layout GAN for Visual-textual Presentation Designs
点击查看论文详情解析
论文摘要:在广告投放过程中,需根据不同的商品制作创意以吸引用户。从历史实验上看,点击效果与创意视觉美观度呈正相关关系。目前,业界广泛应用的自动化创意制作方法,都是基于固定模板(布局)的元素替换或属性更改,即如下图所示,logo、文字、衬底、装饰元素等图形元素的位置不随商品图像变化而更改,常出现遮挡图像主体、视觉融合度不佳等问题,且千篇一律,容易产生视觉疲劳。在学术研究上,有一些自动生成布局的方法,但这些方法主要关注于布局的图形元素内部间的关系建模,未充分利用图像内容信息,无法解决上述问题。
因此,为解决这一业务痛点,我们提出了一种感知图像内容的创意布局自动生成方法,并基于该方法,可为商品图定制化地生成合理布局,保证商品主体的有效展示,提升创意美观度。
9. 基于可控图像生成的自监督文字擦除方法
ACM MM 2022:Self-Supervised Text Erasing with Controllable Image Synthesis
论文摘要:文字擦除任务是指对图像中的文字进行去除并进行缺失内容填补,以便还原出纯净图片用于重编辑。常规的文字擦除模型通常需要大量的标注数据用于训练,而电商海报中多样的文字类型则增加了数据标注以及有监督训练的难度。因此我们提出了自监督的学习框架,可以自动合成训练数据且同时进行文字的擦除。该方法由可控文字合成模块以及文字擦除模块构成,为了减轻合成数据和真实数据之间的风格差距,我们构建了一个策略网络,并通过有效的奖励函数来选择合适的风格参数。除此之外,我们还提出了三元组擦除损失函数来加强复杂背景纹理的生成。在不利用标注数据的情况下,我们提出的方法在高分辨率的创意图PosterErase数据集中取得了领先的视觉效果,FID指标相对于其他方法提升了20.9%,并在公开数据集中也超过了现有的有监督方法。该方法可用于还原去除“牛皮癣”后纯净的商品图,而纯净的商品图是广告创意图片制作的基础。

Part 2 自然语言处理领域
编者按:ACL是自然语言处理与计算语言学领域最高级别的学术会议。AAAI是人工智能领域的国际顶会之一,论文录用领域包括自然语言处理(NLP)、机器学习、AI和网络、机器学习应用等24个领域。这里精选了其中六篇有代表性的工作为大家进行简要介绍。
1. GALAXY:基于半监督学习的任务型对话预训练模型
AAAI 2022:GALAXY: A Generative Pre-trained Model for Task-Oriented Dialog with Semi-Supervised Learning and Explicit Policy Injection
论文概要:预训练模型已经在任务对话系统中得到了很多有效的应用,然而,目前的预训练方法主要侧重于建模对话理解和生成,而忽视了对话策略。在本文中,我们提出了GALAXY,一种新的预训练对话模型,它通过半监督学习方法,可以从有限的标注对话数据和大规模无标对话数据中显式学习出更好的对话策略。具体来说,我们在预训练期间引入了一个对话动作预测任务用于策略优化,并使用一致性正则化项借助无标对话语料来改进大模型的特征表示。同时我们还实现了一个数据选择机制来自动筛选出合适无标对话样本。实验结果表明,GALAXY显著地提高了任务对话系统的性能,在国际公开数据集 In-Car, MultiWOZ2.0和 MultiWOZ2.1上的端到端综合得分相比之前最好模型分别提高2.5分、5.3分和5.5分。实验还证明了在各种低资源设置下,GALAXY比现有模型具有更强的小样本学习能力。

2. 一种面向对话情绪识别的混合课程学习方法
AAAI 2022:Hybrid Curriculum Learning for Emotion Recognition in Conversation
论文概要:对话情绪识别(ERC)旨在预测对话中每轮话语的情绪标签。最近的研究证明,将训练数据样例按有意义的顺序比随机喂入模型,更能提升模型效果, 受此研究启发,我提出了一个面向对话的混合课程学习框架。这个框架由两个课程组成:(1)对话级课程(CC);(2)话语级课程(UC);对于对话级课程(CC),基于对话中情绪偏移的频率设计一个难度评分器。然后按对话难度评分按"从易到难"安排学习课程。对于话语级课程(UC),从情绪相似性的角度出发,逐渐增强了模型识别不易区分情绪的能力。使用我们提出的与模型无关的混合课程学习策略,发现各种现有ERC模型的性能有明显提升,并且在四个公共ERC数据集上创造新的SOTA的结果。

3. 基于连续语义增强的神经机器翻译
ACL 2022:Learning to Generalize to More: Continuous Semantic Augmentation for Neural Machine Translation
论文摘要:神经机器翻译是目前的主流AI翻译技术,需要从大量双语数据中学习翻译能力。然而双语数据有限且获取成本很高,翻译质量的提升遇到诸多困难,数据稀缺的场景问题更加凸显。
针对这一问题,该论文突破了传统离散语义空间数据增强方法:以有限的训练样本为锚点,学习连续语义分布以建模全局的句子空间,并据此构建神经机器翻译引擎,有效提升数据的利用效率,显著改善模型的泛化能力和鲁棒性。实验结果显示,该技术在多个公开数据集上均取得了最佳效果:在使用同等双语数据的前提下:该技术相比传统方法,连续语义增强能够显著提升翻译质量。只使用少量双语数据的情况下:该技术也能充分学习,达到与传统方法使用全部双语数据同等的效果。目前,该技术已应用于AliExpress国际化电商翻译场景,为全球商家提供精准的多语种翻译服务,并显著提升商品转化效率,同时该论文获得了ACL 2022杰出论文奖。

4. IAM:一个针对综合型论辩挖掘任务的全面且大型的数据集
ACL 2022:IAM: A Comprehensive and Large-Scale Dataset for Integrated Argument Mining Task
论文摘要:一场传统辩论通常需要冗长的人工准备过程,包括阅读大量文章、选择论点、选择支持每个论点的论据等。随着人工智能辩论近年来受到更多关注,将辩论系统中涉及的繁琐过程自动化是一个值得研究的方向。在我们的工作中,我们介绍了一个名为 IAM 的综合性大数据集,可应用于一系列论据挖掘任务,包括论点抽取、立场分类、论据提取等。我们进一步提出了与辩论准备过程相关的两个新的综合论辩挖掘任务:(1)论点和立场共同抽取(CESC)和(2)论点论据对抽取(CEPE)。我们的实验结果显示了我们提出的任务的价值和挑战,希望可以对将来论辩挖掘的研究带来一定启发。
5. GlobalWoZ:全球化MultiWoZ以开发多语种任务型对话系统
ACL 2022:GlobalWoZ: Globalizing MultiWoZ to Develop Multilingual Task-Oriented Dialogue Systems
论文摘要:在过去的几年里,多语言任务型对话(ToD)系统有了快速发展,该系统可以为说不同语言的人提供服务。然而,现有的多语言ToD数据集要么由于数据管理的高成本而对语言的覆盖范围有限,要么忽略了在使用这些语言的国家几乎不存在对话实体的事实。为了解决这些限制,我们引入了一种新的数据增强方法,该方法生成GlobalWoZ一个从英语ToD数据集全球化的大规模多语言ToD数据集,用于多语言 ToD系统的三个使用场景。我们的方法基于翻译对话模板并用目标语言国家的本地实体填充它们。此外,我们将目标语言的覆盖范围扩大到20种语言。我们将发布我们的数据集,以推动对多语言ToD系统的实际应用研究。
6. 基于并行实例查询网络的命名实体识别
ACL 2022:Parallel Instance Query Network for Named Entity Recognition
论文摘要:命名实体识别(NER)是自然语言处理中的一项基本任务,目的是识别指代实体的文本片段。近期的工作将命名实体识别视为阅读理解任务,人工构建基于类型的问题,从句子中抽取实体,取得了很好的效果。这种范式存在两种问题。第一,实体预测是类型相关的,每次推理只能抽取出一种类型的实体,不仅效率低,而且忽略了不同类型实体之间的交互。第二,查询需要人工构建,在更多的实体类型的实际场景中很难应用。
为了应对这些问题,我们提出实例查询网络,将基于类型的查询变化为基于实体。每一个实例查询负责预测句子中的一个实体,通过同时输入多个实例查询,我们的模型可以并行查询句子中所有实体。并且,实例查询是可学习的,我们不需要人工构建。在训练时,实例查询是隐式的,无法预先被指定事实标签,因此我们将标签分配视为一对多的线性分配问题,采用匈牙利算法动态地指定标签。在嵌套的NER数据集上的实验表明,我们提出的方法优于以前最先进的模型。
Part 3 机器学习领域
编者按:ICML被认为是人工智能、机器学习领域最顶级的国际会议之一,在计算机科学界享有崇高的声望。这里精选了其中两篇有代表性的工作为大家进行简要介绍。
1. Fedformer:基于频域增强的分解式长程序列预测transformer模型
ICML 2022:Fedformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting
论文摘要:时间序列预测在众多领域中(例如电力、能源、天气、交通等)都有广泛的应用。时间序列预测问题极具挑战性,尤其是长程时间序列预测(long-term series forecasting)。在长程时间序列预测中,需要根据现有的数据对未来做出较长时段的预测。在部分场景中,模型输出的长度可以达到 1000 以上,覆盖若干周期。该问题对预测模型的精度和计算效率均有较高的要求。且时间序列往往会受到分布偏移和噪音的影响,使得预测难度大大增加。
长程时序预测任务是时间序列领域一个经典的任务。输入序列与输出序列分布差异过大是导致很大误差的一个重要原因。本文提出了基于分解式transformer框架的频域增强模型,利用基于频域变换的稀疏表征,实现了线性计算复杂性且大幅降低了预测误差。

2. OFA: 架构、任务、模态统一的序列到序列学习框架
ICML 2022:OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
论文摘要:近年来,基于大规模无监督数据的预训练逐渐成为深度学习研究的热潮,大规模预训练模型也凭借其强大的模型表现和迁移能力逐渐在AI领域扮演着基础模型的角色。
在这项工作中,我们追求多模态预训练的统一范式,以打破复杂的模态/任务特定框架。本文提出OFA,将不同模态(视觉、语言)和任务(图像生成、物体指代、文本生成等)统一为一个基于编解码器架构的序列到序列学习框架。凭借统一范式的设计,OFA在一系列多模态任务上取得了最优的结果,并在单模态任务上也能有不错的表现。

Part 4 数据库领域
编者按:SIGMOD、ICDE是数据库领域三大顶会之二,SIGMOD是在数据库领域具有最高学术地位的国际性学术会议,ICDE旨在解决设计,构建,管理和评估高级数据密集型系统和应用程序中的研究问题;SIGKDD是数据挖掘领域最重要的国际会议。这里精选了其中六篇有代表性的工作为大家进行简要介绍。
1. Remus:支持快照隔离的高效的分布式数据库在线迁移机制
SIGMOD 2022:Remus: Efficient Live Migration for Distributed Databases with Snapshot Isolation
论文摘要:Shared-nothing架构是当前横向扩展数据库计算和存储能力的一种主流架构。在线迁移是解决在该架构下数据和负载倾斜以及支持按需扩缩容的一个核心技术。在Remus这篇论文中,我们提出了一种新的分布式数据库shard在线热迁移技术,可以做到迁移shard的同时,对前端应用性能影响极小:完全零中断,对应用的吞吐和延时影响极小,并且适用于通用分布式数据库产品。Remus核心想法是利用保证分布式事务timestamp order的协议提出了一个高效的单向同步的DUAL执行模型,从而支持轻量级开销的数据ownership无缝平滑切换。同时我们结合MVCC和OCC提出了在单向DUAL模型下保证快照隔离的并发控制协议MOCC。
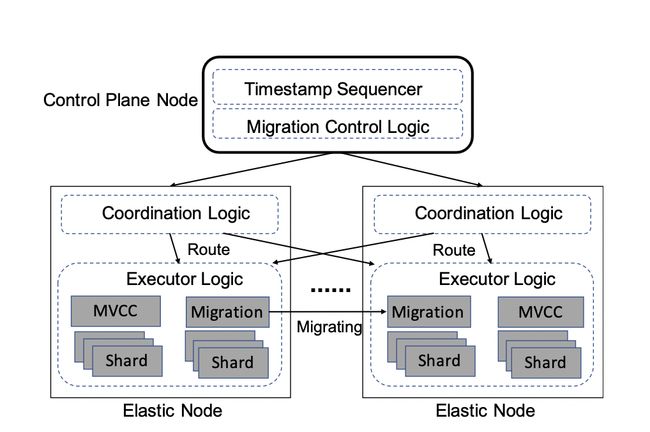
2. ESDB: 实时处理极度不均衡的负载
SIGMOD 2022:ESDB: Processing Extremely Skewed Workloads in Real-time
论文摘要:随着云计算的普及,如何管理多租户数据成为云计算服务商必须要面对的挑战。在这篇论文中,我们介绍了阿里巴巴交易数据库ESDB。作为一款云原生多租户文档型数据库,ESDB不仅拥有强大的全文检索能力,并且能够实时地平衡由百万级别商家带来的极度不均衡的负载。

3. PreQR: 一种基于预训练的SQL编码模型
SIGMOD 2022:PreQR: Pre-training Representation for SQL Understanding
论文摘要:基于学习的模型在许多数据库任务中表现出优于传统方法的性能,然而现有大多数基于学习的SQL查询表示方法都采用了one-hot编码,无法捕捉复杂的语义上下文,如查询结构、数据库模式定义和列的分布变化。为了解决上述问题,我们提出了一种新的预训练SQL表示模型PreQR,它将语言表示方法扩展到SQL查询。论文提出了一种自动机机制来对查询结构进行编码,并应用一个图神经网络来对基于查询的数据库模式信息进行编码。通过采用注意力机制来支持动态查询感知模式链接,建立了一个新的SQL编码器。在真实数据集上的实验结果表明,用PreQR查询表示代替one-hot编码可以显著提高现有基于学习的模型在多个数据库任务上的性能。
4. 面向动态工作负载的安全调参
SIGMOD 2022:Towards Dynamic and Safe Coonfiguration Tuning for Cloud Databases
论文摘要:数据库系统的配置参数对于实现高吞吐量和低延迟至关重要。然而,只有少数有经验的数据库管理员(DBA)掌握调节数据库配置参数的技能。并且,在云数据库中,面对不断变化的工作负载,以及数据库安全性的要求,即使是最有经验的 DBA 也无法解决大部分调参问题。我们设计了面向面向动态工作负载的自适应安全调参系统,在不断变化的云环境中自适应地调整在线数据库,利用黑盒和白盒知识评估配置参数的安全性,安全地探索参数空间。该系统大大减少了数据库调参过程的人力和时间成本,并且显著降低了调参过程中应用不良配置参数的风险,是第一个考虑安全性的数据库在线调参系统。
5. AMCAD:自适应非欧表征广告检索系统
ICDE 2022:AMCAD: Adaptive Mixed-Curvature Representationbased Advertisement Retrieval System
点击查看论文详情解析
论文摘要:作为电商场景核心业务之一,搜索广告旨在满足用户搜索意图(Query)下精准检索触达相关的商品(Item、Ad)。图表征检索是目前信息检索领域最流行的方法之一,但是它们往往建模在平坦的欧氏空间中,正如在CurvLearn开源 | 阿里妈妈曲率学习框架详解中介绍的,在面对非均匀图数据时,欧氏图表征会存在不可避免的精度损失。淘系搜索广告图往往呈现复杂异构的特性;一方面Query节点具备语义上下位词关系,可以映射到类目树上,整体呈现较强的层次结构;另一方面Item/Ad节点均位于叶子类目,根据共现关系相似聚集性强,整体呈现较强的环形属性。针对此类大规模复杂异构图,单一表征空间限制了图建模精度。为此我们提出了自适应非欧表征广告检索系统AMCAD,首次将混合曲率空间应用到大规模工业数据上,使模型端到端的根据复杂数据结构自动学习出损失最低的表征空间。
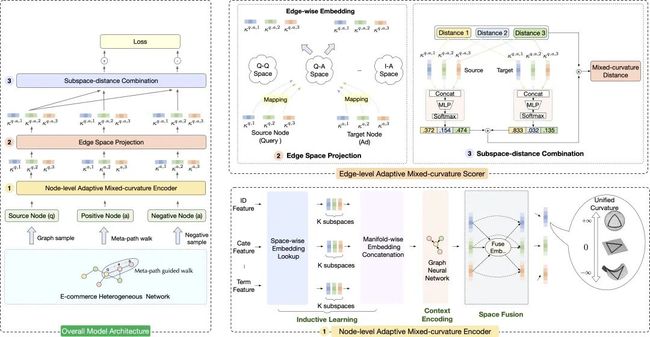
6. CausalMTA: 基于因果推断的无偏广告多触点归因技术
SIGKDD 2022:CausalMTA: Eliminating the User Confounding Bias for Causal Multi-touch Attribution
点击查看论文详情解析
论文摘要:多触点归因(MTA)是一种基于数据驱动的归因技术,着重还原用户触点轨迹并公平分配贡献,帮助商家优化广告资源投放,从而优化提升整体营销收益。MTA是预算分配与智能广告投放的基础,现有方法多采用历史数据训练一个转化预估模型,然后根据Shapley Value分配每个触点的贡献,这类方法的前提是转化预测模型需是无偏的,但广告系统的投放与用户的转化行为往往受到用户偏好的影响,导致上述假设并不成立。本文定义了基于因果推断的无偏多触点归因任务,并提出了CausalMTA模型。通过用户浏览路径重加权与因果转化率预测,系统性地消除了静态与动态混淆偏差的影响。实验结果表明,CausalMTA不仅在预测转化率上超过其他SOTA方法,同时还能为不同广告渠道中得到更加客观公正的分配结果。
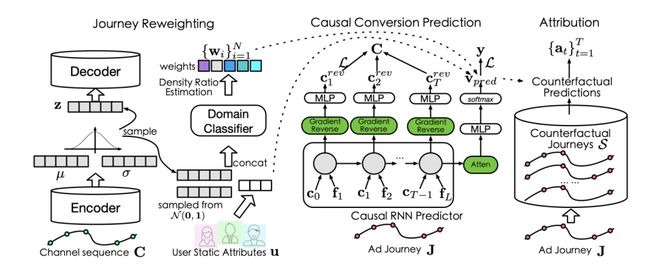
Part 5 计算机系统领域
编者按:USENIX ATC是计算机系统领域国际顶级学术会议之一,在计算机系统领域极具影响力。这里精选了其中两篇有代表性的工作为大家进行简要介绍。
1. Whale: 在异构GPU集群高效训练大模型
USENIX ATC 2022:Whale: Efficient Giant Model Training over Heterogeneous GPUs
论文摘要:Whale是阿里云机器学习PAI平台自研的分布式训练框架。Whale通过对不同并行化策略进行统一抽象、封装,在一套分布式训练框架中支持多种并行策略,并进行显存、计算、通信等全方位的优化,来提供易用、高效的分布式训练框架。Whale提供简洁易用的接口,用户只需添加几行annotation即可组合各种混合并行策略。同时Whale提供了基于硬件感知的自动化分布式并行策略,感知不同硬件的算力、显存等资源,均衡不同硬件上的计算量,最大化计算效率。

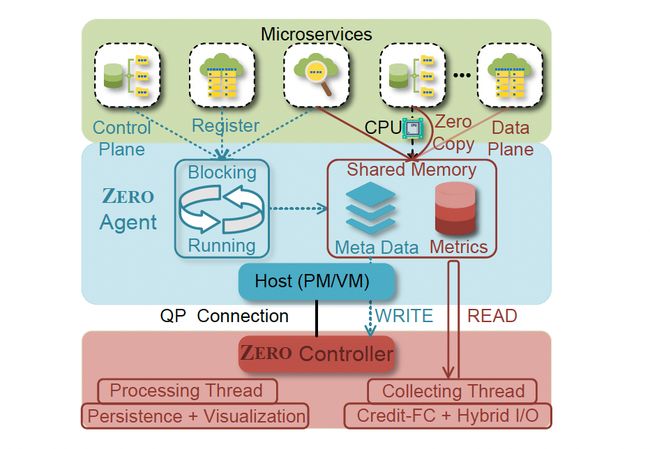
2. 基于RDMA的零开销云原生监控
USENIX ATC 2022:Zero Overhead Monitoring for Cloud-native Infrastructure using RDMA
论文摘要:监测系统被广泛部署在云原生基础设施上的云服务。然而,传统的监控系统已经不能满足云原生监控的需求,这一点从阿里云的实践经验中可以看出。具体来说,监控器占用了被监控基础设施的资源(如CPU),干扰了在其上运行的服务。例如,在阿里巴巴的 "双十一 "购物节中,启用监控器会导致高负载的在线服务的抖动。另一方面,监控本身的服务质量(QoS)对于跟踪和确保SLA至关重要,但在高负载的系统中却得不到保证。
在本文中,我们设计并实现了ZERO,用于云原生监控。首先,ZERO使用单边远程直接内存访问(RDMA)操作实现了从被监控主机收集原始指标的零开销,从而避免了对云服务的干扰。第二,ZERO采用接收器驱动模型来收集具有高服务质量的监测指标,其中提出了基于信用的流量控制和混合I/O模型来缓解网络拥堵/干扰和CPU瓶颈。这项突破相较目前业界开源方案Netdata实现时延降低10倍,有效减少了RDMA网络运维带来的性能开销。
只看论文介绍意犹未尽?我们为大家准备了2022阿里顶会论文精选合集
✪ 计算机视觉领域
https://files.alicdn.com/tpsservice/0626bbfed439cc4fc3193ffad437e19f.zip
✪ 自然语言处理领域
https://files.alicdn.com/tpsservice/6e7928711bb7cf36d8dc69b08338dea4.zip
✪ 机器学习领域
https://files.alicdn.com/tpsservice/34a77af22e6bbd31a5c4104df132d1fc.zip
✪ 数据库领域
https://files.alicdn.com/tpsservice/78f86c3ee3e19ba9301728b8fb4f7f30.zip
✪ 计算机系统领域
https://files.alicdn.com/tpsservice/e0cb64f6a3fad2212a28054270338820.zip