【AI视野·今日CV 计算机视觉论文速览 第228期】Tue, 29 Jun 2021
AI视野·今日CS.CV 计算机视觉论文速览
Tue, 29 Jun 2021 (showing first 100 of 120 entries)
Totally 100 papers
上期速览✈更多精彩请移步主页

Interesting:
*****提升Transformer训练稳定性与性能的早期卷积层, (from FAIR)

***CCS基于循环行列式的MLP视觉主干网络, (from 百度认知实验室)


****CLIPDraw文本到绘图的合成,语言图像编码器, (from Cross Labs JP MIT)
code:https://colab.research.google.com/github/kvfrans/clipdraw/blob/main/clipdraw.ipynb
cross compass:https://github.com/xc-jp https://www.cross-compass.com/
Contrastive Language-Image Pre-training: CLIP
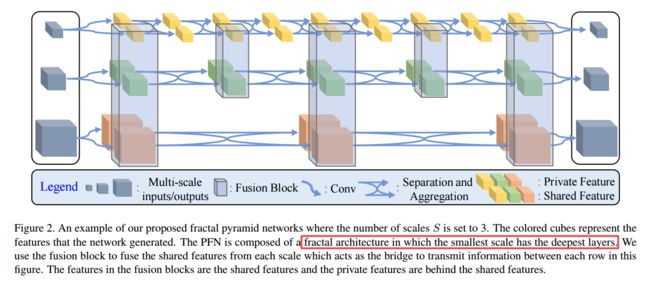
***Fractal Pyramid Networks, 多个信息处理通道和特征抽取分支的分数架构。(from 浙大)
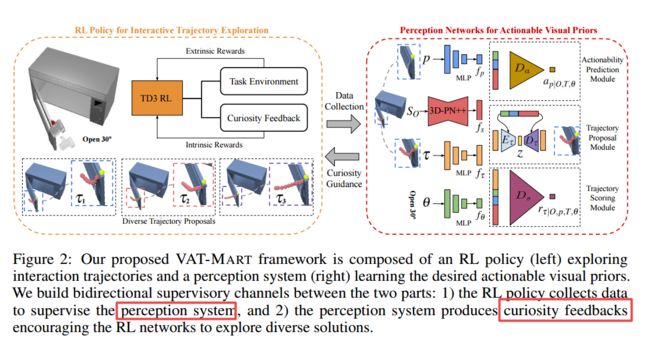
VAT-MART, 预测人工物体的操作轨迹。(from 北大)
web:https://hyperplane-lab.github.io/vat-mart
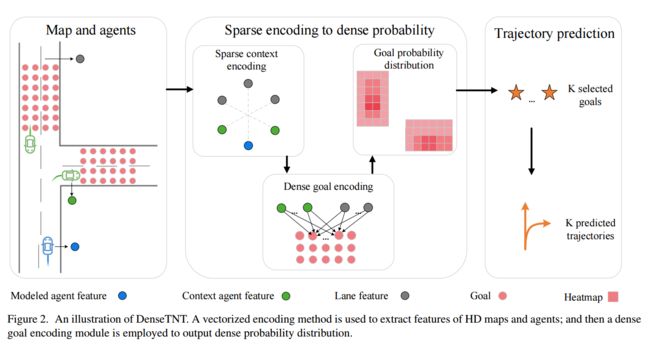
DenseTNT, 自动驾驶中的运动预测问题(from 清华 )

code:https://waymo.com/open/challenges
***Interflow,基于注意力机制的多层特征映射机制与聚合,用于注意力学习来聚合特征。(from 南京大学)


***3D Spherical Neurons用于点云学习的球神经元。(from 林雪平大学)

Daily Computer Vision Papers
| Rethinking Token-Mixing MLP for MLP-based Vision Backbone Authors Tan Yu, Xu Li, Yunfeng Cai, Mingming Sun, Ping Li 在过去的十年中,我们在机器视觉骨干中迅速进展。通过从图像处理中引入电感偏差,卷积神经网络CNN在许多计算机视觉任务中取得了优异的性能,并且已经建立为Emph de骨干。近年来,通过变压器在NLP任务中取得的巨大成功的启发,视觉变压器模型出现。与CNN对应物相比,使用较少的归纳偏差,在计算机视觉任务中取得了有希望的表现。最近,研究人员使用纯MLP架构调查,以建立视觉骨干,以进一步降低电感偏差,实现良好的性能。纯MLP骨架基于频道混合MLPS,以使通道和令牌混合MLP熔合在贴片之间的通信。在本文中,我们认为令牌混合MLP的设计。我们发现现有的MLP骨干中的令牌混合MLP是空间特异性的,因此它对空间翻译敏感。同时,现有令牌混合MLP的通道不可知性质将其能力限制在混合令牌中。为了克服这些限制,我们提出了一种称为循环通道特异性CCS令牌混合MLP的改进结构,其是空间不变和特定的通道。它需要更少的参数,但在ImageNet1k基准上实现了更高的分类准确性。 |
| Early Convolutions Help Transformers See Better Authors Tete Xiao, Mannat Singh, Eric Mintun, Trevor Darrell, Piotr Doll r, Ross Girshick 视觉变压器Vit模型具有不合格的优化性。特别是,它们对优化器Adamw与SGD,优化器超参数和培训计划长度的选择敏感。相比之下,现代卷积神经网络更容易优化。为什么如此在这项工作中,我们猜测该问题借助于vit模型的打包杆,其默认应用于输入图像的默认情况下由步幅P PXP卷积P 16实现。这个大核加上大步卷积与神经网络中的卷积层的典型设计选择进行计数器。为了测试这个非典型设计选择是否导致问题,我们将vit模型的优化行为与原来的涂装茎相比,通过少数堆叠的卷曲,我们通过少量堆叠的步伐更换vit阀门。虽然两种Vit设计中的绝大多数计算是相同的,但我们发现早期视觉处理的这种小变化导致对优化设置的敏感性以及最终模型精度的敏感性明显不同。在VIT中使用卷积杆显着提高优化稳定性,并且在Imagenet 1K上通过12前1个精度提高了峰值性能,同时保持拖鞋和运行时。可以在从1G到36G拖伏的宽范围的模型复杂性横跨从Imagenet 1K到Imagenet 21k的数据集尺度观察到改进。这些调查结果引导我们建议使用标准的轻质卷积阀,用于与原始Vit模型设计相比更强大的建筑选择。 |
| HDMapGen: A Hierarchical Graph Generative Model of High Definition Maps Authors Lu Mi, Hang Zhao, Charlie Nash, Xiaohan Jin, Jiyang Gao, Chen Sun, Cordelia Schmid, Nir Shavit, Yuning Chai, Dragomir Anguelov 高定义高清地图是具有精确定义的地图,具有丰富的交通规则的语义。它们对于自主驾驶系统中的几个关键阶段至关重要,包括运动预测和规划。然而,只有少量的现实世界道路拓扑和几何形状,这显着限制了我们测试自动驾驶堆的能力,以概括到新的看不见的场景。要解决此问题,我们介绍了一个新的具有挑战性的任务来生成高清地图。在这项工作中,我们使用不同的数据表示来探索几种自回归模型,包括序列,纯图和分层图。我们提出了HDMAPGEN,一种能够通过粗糙的方法产生高质量和多样化高清地图的等级图形生成模型。在协会数据集和房屋数据集中的实验表明,HDMAPGEN明显优于基线方法。此外,我们证明HDMAPGEN实现了高可扩展性和效率。 |
| Explicit Clothing Modeling for an Animatable Full-Body Avatar Authors Donglai Xiang, Fabian Andres Prada, Timur Bagautdinov, Weipeng Xu, Yuan Dong, He Wen, Jessica Hodgins, Chenglei Wu 最近的工作在建设质地的动画全身编解码器头像中表现出巨大的进步,但这些化身仍然面临困难,在发电的衣服的高保真动画方面仍然面临困难。为了解决困难,我们提出了一种制造一个动画披身身体头像的方法,从多视图捕获的视频中的上半身上的衣服显式表示。我们使用两层网格表示来单独注册3D扫描的模板。为了改善不同帧的光度对应,然后通过逆转录的衣服几何形状和由变形自动码器预测的纹理来执行纹理对准。然后,我们用上衣和内部主体层的单独建模训练新的两层编解码器头像。为了了解身体动态和服装状态之间的互动,我们使用时间卷积网络基于一系列输入骨架姿势来预测服装潜像。我们为三个不同的演员表示光致动画输出,并展示穿着身体头像在上一个工作中的单层化身上的优势。我们还展示了一种明确服装模型的好处,它可以在动画输出中编辑服装纹理。 |
| K-Net: Towards Unified Image Segmentation Authors Wenwei Zhang, Jiangmiao Pang, Kai Chen, Chen Change Loy 尽管有不同的相关框架,已经通过不同的和专门的框架解决了语义,实例和Panoptic分段。本文为这些基本相似的任务提供了一个统一,简单,有效的框架。该框架,名为K NET,段落的一组被学习内核的实例和语义类别,其中每个内核负责为潜在实例或填充类生成掩码。为了解决区分各种实例的困难,我们提出了一个内核更新策略,它使每个内核动态和条件在输入图像中的其有意义的组上。 K NET可以在结束时培训,以与二分匹配为止,其培训和推论自然是免费的,盒子免费。如果没有钟声和口哨,K网超越了先前的所有先前状态的艺术单一模型,分别在ADE20K上与52.1 PQ和54.3 miou的ADE20K上的COCO和语义分段上的PANoptic Semonation结果。其实例分段性能也与级联掩模R CNNON MS COCO相同,具有60 90升的推理速度。代码和模型将被释放 |
| Iris Presentation Attack Detection by Attention-based and Deep Pixel-wise Binary Supervision Network Authors Meiling Fang, Naser Damer, Fadi Boutros, Florian Kirchbuchner, Arjan Kuijper 虹膜呈现攻击检测垫在虹膜识别系统中起着重要作用。基于CNN的最现有的CNN IRIS PAD解决方案1仅在CNNS培训期间执行二进制标签监控,服务全球信息学习但削弱局部鉴别特征的捕获,2更喜欢堆叠更深层次的卷曲或专家设计的网络,提高了过度装备的风险,3保险丝多垫系统或各种类型的功能,越来越难以在移动设备上部署。因此,我们提出了一种基于深度的深度引起的深映射二进制监控PBS方法。像素明智的监督首先能够捕获细粒度像素补丁级别提示。然后,注意机制指导网络自动找到最多有助于准确的焊盘决定的区域。在Livdet Iris 2017和其他三个公开数据库上进行了广泛的实验,以显示提出的PBS方法的有效性和稳健性。例如,PBS模型在IITD WVU数据库上实现了6.50的HTER,现有技术的表现优势。 |
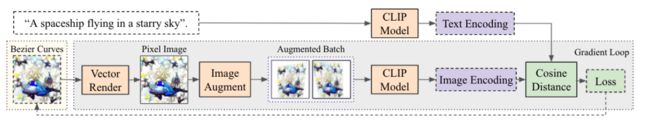
| CLIPDraw: Exploring Text-to-Drawing Synthesis through Language-Image Encoders Authors Kevin Frans, L.B. Soros, Olaf Witkowski 这项工作提出了ClipDraw,这是一种算法,其基于自然语言输入综合新颖绘图。 ClipDraw不需要任何培训,而是将预先训练的剪辑语言图像编码器用作度量标准,以便最大化给定描述和生成的图形之间的相似性。 Clipeally,ClipDraw在向量中进行操作,而不是像素图像,这是一个对更简单的人类可识别形状偏置图的约束。结果通过优化方法突出ClipDraw和其他综合,以及突出ClipDraw的各种有趣行为,例如以多种方式满足模糊文本,可靠地在不同的艺术风格中制作图纸,并且从简单到复杂的视觉表示,作为笔划计数增加。有关该方法的试验代码可供选择 |
| Dataset Bias Mitigation Through Analysis of CNN Training Scores Authors Ekberjan Derman 训练数据集对于基于卷积神经网络的算法至关重要,直接影响其整体性能。因此,始终需要使用具有最小偏差水平的井结构数据集。在本文中,我们提出了一种新颖的域独立方法,称为基于分数的重采样SBR,以基于使用该训练集获得的模型预测分数来定位原始训练数据集的表示样本。在我们的方法中,一旦接受培训,我们使用相同的CNN模型来推断自己的训练样本,获得预测分数,并基于预测和地面真理之间的距离,我们识别远离地面真相并增加它们的样本在原始培训集中。 S形函数的温度术语降低以更好地区分得分。对于实验评估,我们为性别分类选择了一个摇臂数据集。我们首先使用基于CNN的分类器,具有相对标准的结构,在训练图像上培训,并在原始数据集的提供的验证样本上进行评估。然后,我们在完全新的测试数据集中评估它,包括轻型男性,轻的女性,黑雄性和黑色女性团体。获得的精度变化,揭示了对原始数据集中的某些组的分类偏差的存在。随后,根据我们提出的方法,我们在重新采样后培训了模型。我们将我们的方法与先前提出的变分性AutoEncoder VAE算法进行了比较。所获得的结果证实了我们建议的方法对原始数据集之间代表样本的识别识别的有效性,以减少分类某些组的分类偏差。虽然测试了性别分类,但是所提出的算法可用于调查基于CNN的任意CNN的数据集结构。 |
| Hyperspectral Remote Sensing Image Classification Based on Multi-scale Cross Graphic Convolution Authors Yunsong Zhao, Yin Li, Zhihan Chen, Tianchong Qiu, Guojin Liu 特征的挖掘和利用直接影响了对高光谱遥感图像分类和识别的模型的分类性能。传统模型通常从单一的角度进行特征开采,其中特征在于被挖掘有限,并且它们之间的内部关系被忽略。因此,有用的特征丢失,分类结果不满意。为了完全挖掘并利用图像特征,提出了一种新的多尺度特征挖掘学习算法MGRNet。该模型使用主成分分析来降低原始高光谱图像HSI的维度,以保留其语义信息的99.99并提取维度减少特征。使用多尺度卷积算法,开采输入维数减少特征,以获得浅的特征,然后送入多尺度图卷积算法的输入,以构造不同尺度的特征值之间的内部关系。然后,我们在通过图表卷积获得的多尺度信息的交叉融合,在输入为深度特征挖掘的残余网络算法中获得的新信息之前。最后,使用灵活的最大传输函数分类器来预测最终特征并完成分类。三个常见的高光谱数据集的实验显示了本文提出的MGRNET算法,以识别准确性优于传统方法。 |
| A Theory-Driven Self-Labeling Refinement Method for Contrastive Representation Learning Authors Pan Zhou, Caiming Xiong, Xiao Tong Yuan, Steven Hoi 对于图像查询,无监督的对比学习标签与阳性相同图像的作物,以及其他图像作物作为否定。虽然直观,但原生标签分配策略不能揭示查询及其阳性和否定之间的潜在语义相似性,并且损害性能,因为一些否定是语义上类似于查询甚至与查询共享相同的语义类。在这项工作中,我们首先证明,对于对比学习,不准确的标签分配严重损害其对语义实例歧视的泛化,而准确的标签则有利于其泛化。受到这个理论的启发,我们提出了一种新颖的自我标签对比学习的细化方法。它通过两个互补模块改善了标签质量,即可自行标记炼油厂SLR,以产生准确的标签和II动量混合MM,以增强查询与其正的相似性。 SLR使用阳性查询来估计查询和积极和否定之间的语义相似性,并将估计的相似性与Vanilla标签分配相结合,以便迭代地生成更准确和信息丰富的软标签。理论上我们显示我们的SLR可以完全恢复标签损坏数据的真正语义标签,并监督网络以实现分类任务的零预测错误。 MM随机结合查询和阳性,以增加所生成的虚拟查询和它们的阳性之间的语义相似性,以提高标签精度。 CIFAR10,Imagenet,VOC和Coco的实验结果表明了我们方法的有效性。 Pytorch码和模型将在线发布。 |
| One-Shot Affordance Detection Authors Hongchen Luo 1 , Wei Zhai 1 and 3 , Jing Zhang 2 , Yang Cao 1 , Dacheng Tao 3 1 University of Science and Technology of China, China, 2 The University of Sydney, Australia, 3 JD Explore Academy, JD.com, China 可用性检测是指识别图像中对象的潜在动作可能性,这是机器人感知和操纵的重要能力。为了使机器人能够在看不见的情景中具有这种能力,我们考虑了本文的挑战,即,给定描述动作目的的支持图像,应检测到具有共同带来的场景中的所有对象。为此,我们设计了一个拍摄的一拍了一拍了OS广告网络,首先估计目的,然后将其传送以帮助检测所有候选图像的共同承受。通过协作学习,OS AD可以捕获具有相同潜在可供性的对象之间的共同特征,并学习良好的适应能力,以感知看不见的能力。此外,我们通过从31带31次提供和标记4K图像和72个对象类别来构建一个目的驱动的无力数据集垫。实验结果表明,在客观指标和视觉质量方面,我们对以前代表性的模型的优越性。基准套件是ProjectPage。 |
| Real-Time Human Pose Estimation on a Smart Walker using Convolutional Neural Networks Authors Manuel Palermo, Sara Moccia, Lucia Migliorelli, Emanuele Frontoni, Cristina P. Santos 康复对于改善流动性障碍的生活质量是重要的。智能步行者是一个常用的解决方案,应该嵌入自动和客观工具,用于循环控制和监控中的数据驱动的人。但是,目前的解决方案专注于从专用传感器中提取少量特定指标,没有统一的全身方法。我们调查一般,实时,全身姿势估计框架,基于两个RGB D相机流,其安装在康复中使用的智能助行器设备上。使用两个阶段神经网络框架执行人的关键点估计。 2D阶段实现检测模块,该检测模块在2D图像帧中定位身体键点。 3D阶段实现了一个回归模块,其升级并将两个相机中的检测到的关键点相对于助行器涉及到3D空间。模型预测低通滤波以提高时间一致性。使用自定义采集方法来获取数据集,其中具有14个健康的科目,用于培训和评估拟议的框架离线,然后部署在真实的助行器设备上。报告了2D级的3.73像素的总体关键点检测误差和3D阶段44.05mm,推测时间为26.6ms,当时在步行者的受限硬件上部署。我们在智能步行者背景下提出了一种新的患者监测和数据驱动人员的方法。它能够实时提取完整和紧凑的身体表示以及从廉价的传感器中提取完整和紧凑的体表示,作为下游度量提取解决方案和人体机器人交互应用的公共基础。尽管结果有前途,但应对具有损伤的用户收集更多数据,以评估其作为现实世界情景中的康复工具的性能。 |
| Unsupervised Discovery of Actions in Instructional Videos Authors AJ Piergiovanni, Anelia Angelova, Michael S. Ryoo, Irfan Essa 在本文中,我们解决了从教学视频中自动发现无人监督的原子行为的问题。教学视频包含复杂的活动,是智能代理的丰富信息来源,例如,自主机器人或虚拟助手,例如,可以从教学视频中自动读取步骤并执行它们。但是,视频很少有原子活动,界限或持续时间注释。我们提出了一种无人监督的方法来从各种教学视频中学习结构化人类任务的原子行动。我们提出了一种序贯的随机自回归模型,用于视频的时间分割,从而了解任务的不同原子动作之间的顺序关系,并为视频提供自动和无监督的自我标记。我们的方法优于艺术艺术的状态无监督的方法。我们将开源代码。 |
| Real-Time Multi-View 3D Human Pose Estimation using Semantic Feedback to Smart Edge Sensors Authors Simon Bultmann, Sven Behnke 我们介绍了一种从多相机设置估计3D人类姿势的新方法,采用分布式智能边缘传感器,通过语义反馈回路与后端耦合。每个摄像机视图的2D接头检测在专用嵌入式推断处理器上本地执行。在网络上仅传输语义骨架表示,并在传感器板上保持原始图像。 3D姿势从中央后端的2D关节恢复,基于三角测量和一个人的模型,该模型包括人体骨架的先验知识。从后端到各个传感器的反馈通道在语义级别实现。将Allocentric 3D姿势倒置到传感器视图中,在那里它与2D联合检测融合。因此可以通过结合全局上下文信息来提高每个传感器上的局部语义模型。整个管道能够实时运行。我们在三个公共数据集中评估我们的方法,在那里我们实现了最先进的结果,并显示了我们的反馈架构的好处,以及我们自己的多人实验设置。使用反馈信号改善了2D联合检测,并且又估计的3D姿势。 |
| Motion Projection Consistency Based 3D Human Pose Estimation with Virtual Bones from Monocular Videos Authors Guangming Wang, Honghao Zeng, Ziliang Wang, Zhe Liu, Hesheng Wang 实时3D人类姿态估计对于人机互动至关重要。它是便宜且实用的是仅从单眼视频估计3D人类姿势。然而,近期基于骨剪接的3D人姿势估计方法带来了累积误差的问题。在本文中,提出了虚拟骨骼的概念来解决这种挑战。虚拟骨骼是非相邻关节之间的虚构骨骼。它们不存在于现实中,但它们为3D人类关节估计带来了新的循环约束。本文中所提出的网络同时预测真实的骨骼和虚拟骨骼。真实骨骼的最终长度被由预测的真实骨骼和虚拟骨骼构成的循环约束和学习。此外,考虑了连续框架中的关节的运动约束。通过网络预测的2D投影位置位移与相机捕获的真实2D位移之间的一致性被提出为3D人类姿势学习的新投影一致性损失。人体3.6M数据集的实验表明了该方法的良好性能。消融研究证明了所提出的帧间投影一致性约束和帧内帧间循环约束的有效性。 |
| Fast computation of mutual information in the frequency domain with applications to global multimodal image alignment Authors Johan fverstedt, Joakim Lindblad, Nata a Sladoje 多模式图像对齐是在不同成像技术或在不同条件下找到图像之间的空间对应的过程,以促进异构数据融合和相关分析。相互信息MI的信息理论概念被广泛用作引导多式联合对准过程的相似度措施,其中大多数作品专注于MI的局部最大化,通常仅适用于小型位移,这指出了对MI的全局最大化的需要,由于现有算法的高运行时间复杂性,这先前已经计算得不可行。我们提出了一种用于计算MI的高效算法,用于计算作为交叉互信息函数CMIF的所有离散位移,这基于频域中计算的跨相关性。我们表明该算法等同于直接方法,而在运行时的渐近上优越。此外,我们提出了一种用于多模式图像对准的方法,用于具有少量自由度的变换模型。基于所提出的CMIF算法刚性。我们评估所提出的方法对三个不同的基准数据集,空中图像,细胞学图像和组织学图像的功效,并且我们在恢复已知的刚性变换时观察出优异的成功率,总体优于替代方法,包括MI的局部优化以及MI的局部优化以及几种最近的基于深度学习的方法。与直接方法的GPU实现相比,我们还评估了所提出的算法的GPU实现的运行时间,并观察从100到超过100,000次的速度UPS为现实图像尺寸。代码以URL为开放源共享 |
| Fractal Pyramid Networks Authors Zhiqiang Deng, Huimin Yu, Yangqi Long 我们提出了一种新的网络架构,分形金字塔网络PFNS用于像素明智的预测任务作为广泛使用的编码器解码器结构的替代方案。在编码器解码器结构中,通过编码解码管道处理输入,该方法尝试获得语义大信道特征。与之不同,我们提出的PFNS保持多个信息处理路径,并将信息编码为多个单独的小信道特征。关于自我监督单眼深度估计的任务,即使没有想象成掠夺,我们的模型也可以竞争或胜过凯蒂数据集上的现有技术的状态,具有更少的参数。此外,预测的视觉质量显着提高。语义分割的实验提供了证据表明PFN可以应用于其他像素明智的预测任务,并表明我们的模型可以捕获更多的全局结构信息。 |
| Dataset and Benchmarking of Real-Time Embedded Object Detection for RoboCup SSL Authors Roberto Fernandes, Walber M. Rodrigues, Edna Barros 当在特定上下文中产生对象检测的模型时,第一个障碍是具有标记所需类的数据集。在Robocup中,一些联赛已经有多个数据集培训和评估模型。但是,在小型联盟SSL中,还没有这样的数据集。本文介绍了一个开源数据集,可用作SSL中实时对象检测的基准。这项工作还提出了一种管道,用于在低功耗嵌入式系统中培训,部署和评估卷积神经网络CNNS模型。该管道用于评估具有最佳优化模型的建议的数据集。在此数据集中,MobiLenet SSD V1在SSL机器人运行时在每秒94个FPS上实现44.88 AP 68.81 AP50。 |
| Privacy-Preserving Image Acquisition Using Trainable Optical Kernel Authors Yamin Sepehri, Pedram Pad, Pascal Frossard, L. Andrea Dunbar 保护隐私是我们社会的越来越令人担忧,其中传感器和摄像机普遍存在。在这项工作中,我们首次提出了一种可训练的图像获取方法,该方法可以在达到图像传感器之前去除光学域中的敏感标识信息。该方法来自可训练的光学卷积核,其在滤除敏感内容的同时发送所需信息。由于在到达图像传感器之前抑制了敏感内容,因此不会进入数字域,因此通过任何类型的隐私攻击是未进入的。这与当前的数字隐私保留方法相反,所有都容易直接访问攻击。此外,与无法接受培训的先前光学隐私保留方法相比,我们的方法是针对手头的特定应用程序的数据驱动和优化。此外,由于该处理在光学域中被动地发生了这种处理,因此在采集系统上没有额外的计算,存储器或电力负担,并且甚至可以一起使用并在全数字隐私保存系统的顶部。所提出的方法适用于不同的数字神经网络和内容。我们展示了几种场景,例如微笑检测作为所需属性,而性别被滤除为敏感内容。我们与两个对手神经网络一起培训了光学核,其中分析网络试图检测所需的属性和对手网络试图检测敏感内容。 We show that this method can reduce 65.1 of sensitive content when it is selected to be the gender and it only loses 7.3 of the desired content.此外,我们使用深度重建方法重建原始面,证实重建攻击的无效性以获得敏感内容。 |
| Contrastive Counterfactual Visual Explanations With Overdetermination Authors Adam White, Kwun Ho Ngan, James Phelan, Saman Sadeghi Afgeh, Kevin Ryan, Constantino Carlos Reyes Aldasoro, Artur d Avila Garcez 本文介绍了一种新颖的可解释的AI方法,称为清晰图像。清晰的图像是基于视图,即令人满意的解释应该是对比的,反事实和可测量的。通过通过对抗通过对抗学习将图像与自动生成的图像对比,清除图像通过对应于自动生成的图像来解释图像S分类概率。这使得能够忠实地确定每个分段的突出分割和扰动。清晰的图像成功应用于医学成像案例研究,其中使用新颖的指向游戏度量平均27个以27的方式表现出诸如毕业凸轮和石灰的方法。清除图像excel excels在识别图像中有多个贴片的因果过量确定的情况下,其中任何一个都足以使分类概率接近一个。 |
| A Diffeomorphic Aging Model for Adult Human Brain from Cross-Sectional Data Authors Alphin J Thottupattu, Jayanthi Sivaswamy, Venkateswaran P.Krishnan 大脑的规范性老化趋势可以作为评估神经结构障碍的重要参考。这些模型通常由纵向脑图像数据在不同的时间点上跟踪相同主题的数据。在实践中,获得这种纵向数据是困难的。我们提出了一种方法来开发给定群体的老化模型,在没有纵向数据的情况下,通过在不同时间点的不同对象的图像中使用来自不同的时间点的图像,所谓的横截面数据。我们将老化模型定义为源自数据的结构模板上的扩散模型,并提出一种方法,该方法开发了浅与自然老化的拓扑衰老模型的方法。在两个公共横截面数据集上成功验证了所提出的模型,提供由不同年龄点的不同主体组构成的模板。 |
| R2RNet: Low-light Image Enhancement via Real-low to Real-normal Network Authors Jiang Hai, Zhu Xuan, Ren Yang, Yutong Hao, Fengzhu Zou, Fang Lin, Songchen Han 在弱照明条件下捕获的图像将严重降低图像质量。求解一系列低光图像的降解可以有效地提高图像的视觉质量和高级视觉任务的性能。在本文中,我们提出了一种基于Retinex理论的低光图像增强的实际正常网络,包括三个子网,包括三个子网,一个denoise网和revight网。这三个子网分别用于分解,去噪和对比增强。与最先前的方法不同,我们收集第一个大型现实世界成对的低正常灯图像数据集LSRW数据集进行培训。我们的方法可以正确地改善对比度并同时抑制噪声。公开可用数据集的广泛实验表明,我们的方法在定量和视觉上通过大型裕度优于现有技术的现有状态。我们还表明,通过在低光条件下的方法获得的增强结果,可以有效地改善了高级视觉任务的性能。我们的代码和LSRW数据集可用 |
| Cheating Detection Pipeline for Online Interviews and Exams Authors Azmi Can zgen, Mahiye Uluya mur zt rk, Umut Bayraktar 由于流行病和远程工作环境的优势,远程审查和求职面试获得了普及,并变得不可或缺。大多数公司和学术机构利用这些系统为他们的招聘流程以及在线考试。然而,远程检查系统的一个关键问题是在可靠的环境中进行考试。在这项工作中,我们展示了一个作弊分析管道,用于在线访谈和考试。该系统仅需要候选人的视频,在考试期间记录。然后采用作弊检测管道来检测另一个人,电子设备使用和候选缺席状态。管道由面部检测,面部识别,对象检测和面部跟踪算法组成。为了评估管道的表现,我们收集了私人视频数据集。视频数据集包括作弊活动和清洁视频。最终,我们的管道提供了一种有效和快速的准则,可以检测和分析在线访谈和考试视频中的作弊活动。 |
| Adventurer's Treasure Hunt: A Transparent System for Visually Grounded Compositional Visual Question Answering based on Scene Graphs Authors Daniel Reich, Felix Putze, Tanja Schultz 随着在VQA的推理过程中提高系统透明度和视觉接地的表达目标,我们为基于场景图的组成VQA的任务提供了一种模块化系统。我们的系统被称为冒险家的宝藏狩猎或ATH,以类比命名,我们在我们的模型S搜索程序之间抽出答案和冒险家搜索宝藏。我们开发了三个特征特征的思想1.通过设计,Ath允许我们明确地量化每个子组件对整体VQA性能的影响,以及它们在各个子任务上的性能。 2.通过在宝藏狩猎之后建模搜索任务,Ath本质地为处理问题产生了明确的视觉接地推理路径。 3. Ath是第一个通过直接查询视觉知识库而动态提取答案的GQA培训的VQA系统,而不是通过预先固定的答案词汇表中从特殊学习的分类器输出分布中选择一个。我们在GQA数据集中报告了所有组件的详细结果以及对整体VQA性能的贡献,并显示ATH实现所有检查系统中最高的视觉接地分数。 |
| A More Compact Object Detector Head Network with Feature Enhancement and Relational Reasoning Authors Wen chao Zhang, Chong Fu, Xiang shi Chang, Teng fei Zhao, Xiang Li, Chiu Wing Sham 建模隐式功能交互模式对对象检测任务具有重要意义。然而,在两个阶段的探测器中,由于手工制作组件过度使用,非常难以理解实例特征的隐式关系。为了解决这个问题,我们分析了三个不同级别的特征交互关系,即裁剪本地特征与全局特征之间的依赖关系,实例内的特征自相关,以及实例之间的互相关关系。为此,我们提出了一种更紧凑的对象检测器头网络Codh,其不仅可以保留全局上下文信息并冷凝信息密度,而且还允许在更大的矩阵空间中进行实例明智的特征增强和关系推理。如果没有钟声和吹口哨,我们的方法可以有效地提高检测性能,同时显着减少模型的参数,例如,通过我们的方法,头部网络的参数比艺术级联R CNN的状态小0.6倍,但是COCO测试开发的性能提升为1.3。如果没有失去泛,我们也可以通过组装我们的方法来为其他多级探测器构建更轻的头网络。 |
| False Negative Reduction in Video Instance Segmentation using Uncertainty Estimates Authors Kira Maag 图像的实例分割是自动化场景了解的重要工具。通常培训神经网络,以在准确性方面优化它们的整体性能。同时,在自动驾驶等应用中,被忽视的行人似乎比虚假检测到的行人更有害。在这项工作中,我们给出了一种假阴性检测方法,其基于在线应用程序中的图像序列的可用性的时间序列的不一致性序列的图像序列。由于该算法可以大大增加实例的数量,我们使用在实例聚合的不确定性估计来应用假阳性剪枝。为此,构造实例明确度量标准,其表征给定实例的不确定性和几何体,或者在深度估计上进行预测。所提出的方法用作适用于任何可以在单帧上培训的神经网络的后处理步骤。在我们的测试中,我们通过融合检测方法获得了假阴性和假实例之间的改进折衷,与推断过程中实例分段网络提供的普通得分值相比,我们的融合检测方法在使用的普通得分值相比。 |
| Dizygotic Conditional Variational AutoEncoder for Multi-Modal and Partial Modality Absent Few-Shot Learning Authors Yi Zhang, Sheng Huang, Xi Peng, Dan Yang 数据增强是一种强大的技术,可以提高少数拍摄分类任务的性能。它会生成更多的样本作为补充,然后可以将此任务转换为解决方案的共同监督学习问题。然而,基于大多数主流数据增强的方法仅考虑单个模态信息,这导致产生的功能的低分集和质量。在本文中,我们提出了一种名为Dizygotic Comitional变形AutoEncoder DCVAE的新型多模态数据增强方法,用于解决上述问题。 DCVAE通过配对两种条件变分性自身的特征合成,其具有相同的种子但不同的模态条件以Dizygotic Symbiisis的方式。随后,自适应地组合两个CVAE的生成特征以产生最终特征,其可以转换回其配对条件,同时确保这些条件与原始条件相一致,不仅在表示中而且在功能中。 DCVAE通过利用不同模式先前信息的补充,基本上在各种多模态方案中提供了数据增强的新思想。广泛的实验结果表明,我们的工作在MiniimAgenet,CiFar FS和Cub数据集上实现了最新的表演,并且能够在部分模态缺席情况下工作。 |
| Recurrent neural network transducer for Japanese and Chinese offline handwritten text recognition Authors Trung Tan Ngo, Hung Tuan Nguyen, Nam Tuan Ly, Masaki Nakagawa 在本文中,我们提出了一个RNN传感器模型,用于识别日语和中国离线手写文本线图像。据我们所知,它是采用RNN传感器模型的第一种方法,用于离线手写文本识别。所提出的模型由三个主要组件组成了一个可视化特征编码器,它由CNN从输入图像中提取视觉特征,然后通过BLSTM通过嵌入层和LSTM从输入图像中提取和编码语言特征的语言上下文编码器来对视觉功能进行对视觉功能。通过完全连接和SoftMax层组合并将视觉功能和语言特征的联合解码器组合在最终标签序列中。所提出的模型利用来自输入图像的视觉和语言信息。在实验中,我们评估了拟议模型在两个数据集Kuzushiji和SCUT EPT上的表现。实验结果表明,该建议的模型在所有数据集上实现了最先进的性能。 |
| Feature Combination Meets Attention: Baidu Soccer Embeddings and Transformer based Temporal Detection Authors Xin Zhou, Le Kang, Zhiyu Cheng, Bo He, Jingyu Xin 随着迅速发展的互联网技术和新兴工具,在线生成的体育相关视频正在以前所未有的快速节奏增加。为了自动化体育视频编辑突出显示生成过程,一个关键任务是精确识别和定位长虚拟视频中的事件。在这个技术报告中,我们展示了两阶段范式来检测在足球广播视频中发生的事件和何时发生。具体而言,我们在足球数据上微调多个动作识别模型,以提取高电平语义特征,并设计基于变压器的时间检测模块来定位目标事件。在CVPR 2021 ActivityNet Workshop下,这种方法在Soccernet V2挑战中实现了两个任务,即Action Spotting和Replay接地的最先进状态。我们的足球嵌入功能释放出来 |
| VAT-Mart: Learning Visual Action Trajectory Proposals for Manipulating 3D ARTiculated Objects Authors Ruihai Wu, Yan Zhao, Kaichun Mo, Zizheng Guo, Yian Wang, Tianhao Wu, Qingnan Fan, Xuelin Chen, Leonidas Guibas, Hao Dong 感知和操纵3D铰接对象,例如,人类环境中的门是未来家庭助理机器人的重要又具有挑战性的任务。 3D关节物体的空间在其无数语义类别,不同的形状几何形状和复杂的零件功能方面非常丰富。以前的作品主要是抽象的运动结构,具有估计的关节参数和部分作为操纵3D铰接物体的视觉表示。在本文中,我们提出了以中心可操作的视觉前沿,作为一种新的感知交互握手,即感知系统通过预测致密几何意识,交互感知和任务意识的视觉动作可提供度和轨迹提案来输出比运动结构估计更可操作的引导。我们设计了感知框架VAT Mart的互动,以便通过同时培训探索各种交互轨迹的好奇心驱动强化学习政策以及概述各种形状中探讨预测的探索知识来了解这种可操作的互动轨迹和感知模块。实验证明了使用Sapien环境中的大规模Partnet Mobility DataSet的提出方法的有效性,并为新颖的测试形状,看不见的对象类别和现实世界数据显示了有前途的泛化能力。项目页面 |
| Prior-Induced Information Alignment for Image Matting Authors Yuhao Liu, Jiake Xie, Yu Qiao, Yong Tang and, Xin Yang 图像消光是一个不适的问题,旨在估计图像中的前景像素的不透明度。然而,大多数现有的基于深度学习的方法仍然遭受粗粒细节。通常,这些算法不能富有区分确定性域某些FG和BG像素之间的探测程度,并且在像素之间不确定的未确定域,或者在连续采样过程中不可避免地丢失信息,导致副最优结果。在本文中,我们提出了一种名为现有的诱导信息对齐光盘垫网络Piiamatting的新型网络,这可以有效地模拟像素明智的响应图的区别和层面特征图的相关性。它主要由动态高斯调制机制DGM和信息对齐策略IA组成。具体地,DGM可以动态获取从先前分发中获得的像素WISE域响应图。响应图可以在训练期间呈现不透明度变化与收敛过程之间的关系。另一方面,IA包括信息匹配模块IMM和信息聚合模块IAM,共同调度以自适应地匹配和聚合相邻的层明智的特征。此外,我们还开发了一个多尺度细化MSR模块,以在细化阶段集成多尺度接收场信息,以恢复波动外观细节。广泛的定量和定性评估表明,建议的Piiamatting对艺术图像消光方法的状态有利地表现出 |
| Progressive Class-based Expansion Learning For Image Classification Authors Hui Wang, Hanbin Zhao, Xi Li 在本文中,我们提出了一种新颖的图像过程方案,称为基于类的图像分类的扩展学习,旨在改善混淆类别的样本的监督刺激频率。基于班级的扩展学习采用基于班级的扩展优化时尚的自下而上的增长策略,从而更多地关注学习优先选择的课程的细粒度分类边界的质量。此外,我们开发了一个课堂混淆标准,以选择令人困惑的课程进行培训。以这种方式,经常刺激混乱等级的分类边界,导致细粒形成细粒。实验结果展示了拟议方案对几个基准的有效性。 |
| Multi-Compound Transformer for Accurate Biomedical Image Segmentation Authors Yuanfeng Ji, Ruimao Zhang, Huijie Wang, Zhen Li, Lingyun Wu, Shaoting Zhang, Ping Luo 最近的视觉变压器i.e.for Image Classifications学习不同补丁令牌的非本地细节互动。然而,现有技术未命中学习不同像素的横梁依赖性,不同标签的语义对应关系以及特征表示和语义嵌入的一致性,这对于生物医学分割至关重要。在本文中,我们通过提出一个统一的变压器网络,称为多种复合变压器MCTRANS的统一变压器网络,其中包含丰富的特征学习和语义结构挖掘到统一的框架中。具体而言,MCTRANS将多尺度卷积特性嵌入为令牌序列,并在以前的作品中执行帧内和间级别的自我注意力,而不是单一规模注意。此外,还引入了学习的代理嵌入来模拟语义关系和功能增强,分别使用自我关注和跨关注。 MCTRANS可以很容易地插入杂于网络中,并在六个标准基准中的生物医学图像分段中的现有技术状态下实现显着改进。例如,MCTRANS以3.64,3.71,4.34,2.8,1.88,1.34,2.8,1.88,1.34,2.8,1.88,1.57分别在Pannuke,CVC诊所,CVC冒号,ETIS,Kavirs,ISIC2018数据集中进行3.64,3.71,4.34,2.8,1.88,1.57。代码可用 |
| Rail-5k: a Real-World Dataset for Rail Surface Defects Detection Authors Zihao Zhang, Shaozuo Yu, Siwei Yang, Yu Zhou, Bingchen Zhao 本文介绍了导轨5K数据集,用于基准测试在真实世界应用场景中的视觉算法的性能,即轨道表面缺陷检测任务。我们从中国的铁路收集了超过5K的高质量图像,并借助于铁路专家的帮助,以确定最常见的13种轨道缺陷。 DataSet可用于两种设置,既具有独特的挑战,首先是使用1K标记图像进行训练的完全监督设置,缺陷类的细粒度性质和长尾分布使得可视算法难以解决。第二个是由4K未标记的图像促进的半监督学习设置,这些4K图像是未透明的包含图像损坏和与标记图像的域移位,这不能通过先前的半监督学习方法轻松解决。我们相信我们的数据集可能是评估视觉算法的稳健性和可靠性的有价值的基准。 |
| Blind Non-Uniform Motion Deblurring using Atrous Spatial Pyramid Deformable Convolution and Deblurring-Reblurring Consistency Authors Dong Huo, Abbas Masoumzadeh, Yee Hong Yang 基于深度学习的方法旨在拆下由物体运动和相机抖动引起的非均匀空间变体运动模糊,而不知道模糊内核。一些方法在一个阶段直接输出潜在的锐利图像,而其他方法利用多级策略,例如多级,多贴片或多时间逐渐恢复锐图像。然而,这些方法具有以下两个主要问题1,多阶段的计算成本是高2相同的卷积内核应用于不同地区,这不是非统一模糊的理想选择。因此,非统一运动脱棕色仍然是一个具有挑战性和开放的问题。在本文中,我们提出了一种新的架构,该架构包括多个不足的空间金字塔可变形卷积ASPDC模块,以使图像端DeBlur以更高的灵活性去除。多个ASPDC模块隐式地学习具有同一层中不同扩张速率的像素特定运动,以处理不同幅度的运动。为了改进培训,我们还提出了一种重新掩盖网络来将下孔输出映射回模糊的输入,这会限制溶液空间。我们的实验结果表明,所提出的方法优于基准数据集的现有技术的状态。 |
| Change Detection for Geodatabase Updating Authors Rongjun Qin 现在,地理数据库矢量化数据成为一个相当标准的数字城市基础设施,但有效地更新地理数据库,并且在经济上仍然是地理空间行业的基本和实际问题。建立地理数据库的成本非常高,劳动密集型,并且我们使用的地图通常有几个月甚至多年的延迟。一种解决方案是为矢量化地理空间数据生成开发更多自动化方法,这在过去几十年中已被证明是一项艰巨的任务。替代解决方案是首先检测新数据和现有地理空间数据之间的差异,然后仅更新被标识为更改的区域。由于其高实用性和灵活性,第二种方法变得越来越受欢迎。高度相关的技术是变化检测。本文旨在提供概述遥感和地理系统领域的最新变更检测方法,以支持更新地理数据库的任务。用于改变检测的数据是高度不同的,因此我们基于数据的维度直观地构建了我们的审查,是用3D数据2改变检测,使用3D数据进行改变检测。结论将根据该领域的审查努力绘制,我们将分享我们的展望更新地理数据库。 |
| Geometric Processing for Image-based 3D Object Modeling Authors Rongjun Qin, Xu Huang 基于图像的3D对象建模是指将原始光学图像转换为对象的3D数字表示的过程。通常,希望这种模型是尺寸为真,用基于光致型外观现实的建模的语义标记。激光扫描被认为是获得高精度的对象3D测量的标准和直接方法,而一个人必须遵守高采集成本及其在某些平台上的不可用。如今,由最近开发的高级密集图像匹配算法和Geo引用范例包销的基于图像的方法正在成为主导方法,这是由于其高度灵活性,可用性和低成本。从订购的无序原始图像到纹理网格的3D对象重建工作流程中的图像的主要自动化几何处理是基于现实的3D建模的关键部分。本文总结了整体几何处理工作流程,专注于引入几何处理的三个主要组件的现有技术方法1 Geo引用2图像密集匹配3纹理映射。最后,我们将得出结论并分享我们对本文讨论的主题的展望。 |
| 3D Reconstruction through Fusion of Cross-View Images Authors Rongjun Qin, Shuang Song, Xiao Ling, Mostafa Elhashash 从多立体声和立体图像中恢复,作为基于图像的透视几何的重要应用,在计算机视觉,遥感和地理系统中提供许多应用。在本章中,作者利用成像几何形状和现有方法,其在其视点中从横视图像中执行3D重建的方法。我们介绍了我们的框架,以完成地面视图图像和卫星图像以进行全3D恢复,这包括从图像,3D数据CO注册,融合和网格生成中产生的卫星和地面点云生成的必要方法。我们在数据集上展示了由第12颗卫星图像和通过车辆安装的Go Pro相机获取的150K视频帧组成的数据集,并演示了重建结果。我们还将结果与直观的处理管道产生的结果进行了比较,这涉及典型的地理登记和啮合方法。 |
| Darker than Black-Box: Face Reconstruction from Similarity Queries Authors Anton Razzhigaev, Klim Kireev, Igor Udovichenko, Aleksandr Petiushko 最近呈现了几种用于面部识别模型的反演方法,试图从深模板重建面部。虽然这些方法中的一些方法仅使用仅使用面部嵌入的黑匣子设置,但通常在最终用户侧,只提供相似度得分。因此,这些算法在这种情况下不可应用。我们提出了一种新颖的方法,允许重建仅重建黑盒模型的相似性得分。虽然我们的算法在更一般的设置中运行,但实验表明它是查询高效并优于现有方法。 |
| Learning without Forgetting for 3D Point Cloud Objects Authors Townim Chowdhury, Mahira Jalisha, Ali Cheraghian, Shafin Rahman 当我们微调一个训练有素的深度学习模型,为一组新的课程,网络了解新的概念,但逐渐忘记了旧培训的知识。在一些现实生活中,我们可能有兴趣在毫无遗忘的情况下学习新课程。通常使用2D图像识别任务来研究毫无遗忘问题的这种学习。在本文中,考虑到深度相机技术的增长,我们解决了3D点云对象数据的相同问题。由于大型数据集和强大的预磨削骨干型号,3D域中的3D域中的问题变得更具挑战性。我们研究了3D数据的知识蒸馏技术,以减少灾难性的遗忘之前的训练。此外,我们通过使用对象类的语义词向量来改善蒸馏过程。我们观察到探索训练期间的旧知识的相互关系有助于学习新概念而不会忘记旧的概念。尝试三维3D点云识别备用PointNet,DGCNN和PointConv和Synthetic ModelNET40,ModelNet10和Real Scanned ScanObjectnn数据集,我们在不忘记3D数据的情况下建立新的基线导致学习。这项研究将在这一领域进行许多未来的作品。 |
| Learning Mesh Representations via Binary Space Partitioning Tree Networks Authors Zhiqin Chen, Andrea Tagliasacchi, Hao Zhang 多边形网格普遍存在,但只在深入学习革命中发挥了相对较小的作用。用于3D形状的最先进的神经生成模型学习隐式功能并通过昂贵的ISO浮出来生成网格。我们通过从计算机图形学,二进制空间分区BSP中使用古典空间数据结构来克服这些挑战,以促进3D学习。 BSP的核心操作涉及3D空间的递归细分以获得凸集。通过利用此属性,我们设计了BSP网络,该网络学习通过凸分解而没有监控的凸分解表示3D形状。训练网络以使用从内置一组平面上的BSP树获得的一组凸面进行重建形状,其中平面和凸面都由学习网络权重定义。 BSP Net直接从推断的凸起输出多边形网格。所产生的网格是防水,紧凑的即,低聚,非常适合代表尖锐的几何形状。我们表明,BSP网的重建质量与最先进方法的竞争力竞争,同时使用更少的原语。我们还探讨了BSP网的变化,包括使用更通用的解码器来重建,比平面更通用的原语,以及使用变形自动编码器训练生成模型。代码可用 |
| SDOF-Tracker: Fast and Accurate Multiple Human Tracking by Skipped-Detection and Optical-Flow Authors Hitoshi Nishimura, Satoshi Komorita, Yasutomo Kawanishi, Hiroshi Murase 多人追踪是场景理解的根本问题。虽然在现实世界应用中需要精度和速度,但最近基于深度学习的跟踪方法专注于准确性,需要大量运行时间。本研究旨在通过在某种帧间隔执行人类检测来提高运行速度,因为它适用于大多数运行时间。问题是如何在跳过人类检测时保持准确性。在本文中,基于某人的外观在相邻框架之间不换多大程度的情况,我们提出了一种与光流量的检测结果补充的方法。为了保持跟踪准确性,我们在人类区域内引入强大的兴趣点选择以及通过兴趣点分布计算的跟踪终止度量。在Motchallenge中的MOT20数据集上,所提出的SDOF跟踪器在保持MOTA度量的同时实现了总运行速度的最佳性能。我们的代码可在HTTPS Anonymous.4open.scence r sdof跟踪器75ae提供。 |
| Representation Based Regression for Object Distance Estimation Authors Mete Ahishali, Mehmet Yamac, Serkan Kiranyaz, Moncef Gabbouj 在这项研究中,我们提出了一种新的方法来预测观察到的场景中检测到的对象的距离。建议的方法修改了最近提出的卷积支持估计网络CSENS。 CSENs旨在在基于表示的分类问题中计算支持估计SE任务的直接映射。我们进一步提出并证明基于表示的方法稀疏或协作表示可以在设计良好的回归问题中使用。据我们所知,这是通过利用修改的CSENS来执行回归任务的基于第一表示的方法,我们将这种新方法命名为基于表示的回归RBR。 CSENS的初始版本具有代理映射阶段I.E.,输入输入所需的支持集的粗略估计。在这项研究中,我们通过提出压缩学习CSEN CL CSEN来改善CSEN模型,该CSEN CL CSEN能够共同优化所谓的代理映射阶段以及卷积层。使用基提3D对象检测距离估计数据集的实验评估表明,该方法可以通过所有竞争方法实现显着提高的距离估计性能。最后,该方法的软件实现是公开分享的 |
| Learning to solve geometric construction problems from images Authors J. Macke, J. Sedlar, M. Olsak, J. Urban, J. Sivic 我们描述了一种基于纯图像的方法,用于在Euclidea几何游戏中用尺子和指南针找到几何结构。该方法基于调整艺术图像的掩模R CNN状态,并将基于树的搜索过程添加到其上。在监督的环境中,该方法学习从六级欧几里德的前六个级别的欧几里德群中解决所有68种几何施工问题,平均为92精度。在评估新的问题时,该方法可以解决68种Euclidea问题中的31个问题。我们认为这是第一次训练了纯粹的图像学习,以解决这种困难的几何施工问题。 |
| DONet: Learning Category-Level 6D Object Pose and Size Estimation from Depth Observation Authors Haitao Lin, Zichang Liu, Chilam Cheang, Lingwei Zhang, Yanwei Fu, Xiangyang Xue 我们提出了一种类别级别6d对象姿势和大小估计从单个深度图像的方法,没有外部姿势被引入的真实世界训练数据。虽然以前的作品在RGB D图像中利用视觉线索,但我们的方法基于单独的深度通道中对象的丰富几何信息进行推断。基本上,我们的框架通过学习统一的3D方向一致表示3D OCR模块来探讨这些几何信息,并通过几何约束的反射对称地墓地模块的属性进一步强制实施。物体大小和中心点的幅度信息最终通过镜像尺寸估计MPDE模块估计。对该类别NOCS基准的广泛实验表明,我们的框架与需要标有现实世界形象的艺术方法的竞争。我们还将我们的方法部署到物理Baxter Robot,以在看不见的情况下执行操作任务,而是已知的实例,结果进一步验证了我们提出的模型的效果。我们的视频可在补充材料中提供。 |
| Mitigating severe over-parameterization in deep convolutional neural networks through forced feature abstraction and compression with an entropy-based heuristic Authors Nidhi Gowdra, Roopak Sinha, Stephen MacDonell, Wei Qi Yan 诸如Reset 50,DenSenet 40和Resext 56的卷积神经网络CNNS诸如参数化的诸如参数化的CNN,因此需要随之而来的模型训练所需的计算资源,其在模型深度中呈指数为增量的尺度缩放。在本文中,我们提出了一种基于熵的卷积层估计eBCE启发式,其具有坚固且简单,但有效地解决了关于CNN模型的网络深度的参数化问题。 EBCE启发式旨在了解输入数据集的熵数据分布的先验知识,以确定卷积网络深度的上限,超出哪个身份变换普遍为提高模型性能而提供微不足道的贡献。通过强制特征压缩和抽象来限制深度冗余,在参数化上限制,同时减少培训时间,在24.99 78.59中毫无衰减,在模型性能下降。我们提出了经验证据来强调使用EBCE启发式培训的更广泛的相对效果,而且培训的较浅的型号,它维持或优于较为更深的模型的基线分类准确性。 eBCE启发式是亚麻布解和ebce基于的CNN模型限制了深度冗余,从而提高了可用计算资源的利用率。建议的eBCE启发式是一个令人信服的研究人员,用于分析他们的HyperParameter HP选择对CNNS的说法。在培训CNN模型中的eBCE启发式的经验验证是在五个基准测试数据集Imagenet32,CiFar 10 100,STL 10,Mnist和四个网络架构Densenet,Reset,Resnext和AbseralyNET B0 B2,具有适当的统计测试,用于推断出来的任何结论声称在本文中。 |
| Memory Guided Road Detection Authors Praveen Venkatesh, Rwik Rana, Varun Jain 在自动驾驶汽车应用中,需要预测通道的车道的位置,给出输入RGB前面的图像。在本文中,我们提出了一种架构,其允许我们通过引入随时间传播的底层共享特征空间来提高道路检测的速度和稳健性,而不会精确地重点击中,这用作流动的动态存储器。通过利用先前框架的主旨,我们训练网络以预测当前道路,具有更高的准确性和与前一帧的偏差更小。 |
| The Story in Your Eyes: An Individual-difference-aware Model for Cross-person Gaze Estimation Authors Jun Bao, Buyu Liu, Jun Yu 我们仅通过显式建模特定的差异来提出一种新的方法对眼睛面部图像的炼制交叉人凝视预测任务。具体而言,我们首先假设我们可以通过现有方法获得一些初始凝视预测结果,我们将其称为InitNet,然后引入三个模块,有效模块VM,自校准SC和人特定变换PT模块。通过预测当前眼面图像的可靠性,我们的VM能够识别无效的样本,例如,眼睛闪烁图像,并降低模拟过程中的效果。我们的SC和PT模块然后学会仅弥补有效样本的差异。前者通过弥合初始预测和数据集明智分发之间的差距来模拟翻译偏移。后者通过将信息从同一个人的现有初始预测中包含信息来了解更多的一般人员特定的转换。我们在三个公开可用的数据集,夏娃,Xgaze和Mpiigaze上验证我们的想法,并证明我们所提出的方法在所有这些中显着优于SOTA方法,例如,如此。分别为21.7,36.0和32.9相对性能改进。我们在夏娃数据集中赢得了凝视2021竞争。我们的代码可以在这里找到 |
| Indoor Panorama Planar 3D Reconstruction via Divide and Conquer Authors Cheng Sun, Chi Wei Hsiao, Ning Hsu Wang, Min Sun, Hwann Tzong Chen 室内全景通常由人造结构平行或垂直于重力组成。我们利用这种现象来近似与H露天平面和v元素平面的360度图像中的场景。为此,我们提出了一种有效的划分和征服基于它们的平面方向估计的像素的有效划分和征服策略,然后,后续实例分割模块在每个平面方向组中更容易地征收平面聚类的任务。此外,V平面的参数取决于相机偏航旋转,但转换不变的CNN不太了解偏航变化。因此,我们为CNNS提出了一个偏航不变的V平面Reparameterization来学习。我们通过将现有的360深度数据集扩展到PANOH V Dataset的地面真理H V平面并采用艺术平面重建方法来预测H V平面作为我们的基准,通过延伸现有的360深度数据集来创建一个基准。我们的方法在所提出的数据集上通过大边缘表达基线。 |
| Few-Shot Domain Expansion for Face Anti-Spoofing Authors Bowen Yang, Jing Zhang, Zhenfei Yin, Jing Shao 面部反欺骗FAS是面部识别系统中不可或缺的和广泛使用的模块。虽然已经实现了高精度,但由于非静止应用环境和现实世界应用中新型呈现攻击的潜在出现,FAS系统永远不会完美。实际上,在现有源域中的新部署方案目标域和丰富标记的面部图像中给出了一些标记的样本,预计FAS系统将在新场景中表现良好,而不会牺牲原始域上的性能。为此,我们识别并解决更实际的问题,对于面部反欺骗FSDE FAS的镜头域扩展更加实际的问题。由于目标域训练样本不足,因此该问题具有挑战性,该模型可能遭受对目标域的过度装备和源域的灾难性忘记。为了解决问题,本文提出了一种基于Syry Transfer的语义对齐SASA框架的增强。我们建议通过基于质感式风格转移产生辅助样品来增加目标数据。通过增强数据的助手,我们进一步提出了一个精心设计的机制,以使不同域与实例级别和分配级别对齐,然后用较少的遗忘约束稳定源域上的性能。提出了两个基准,以模拟FSDE FAS场景,实验结果表明,所提出的SASA方法优于现有技术的状态。 |
| DenseTNT: Waymo Open Dataset Motion Prediction Challenge 1st Place Solution Authors Junru Gu, Qiao Sun, Hang Zhao 在自动驾驶中,基于目标的多轨迹预测方法最近被证明是有效的,在那里他们首先得分目标候选者,然后选择最终的目标集,最后完成基于所选目标的轨迹。然而,这些方法通常涉及基于稀疏预定锚的目标预测。在这项工作中,我们提出了一个名为Densetnt的锚定自由模型,其执行轨迹预测的致密目标概率估计。我们的模型实现了最先进的性能,并在Waymo Open DataSet Motion Protection挑战上排名第一。 |
| Post-Training Quantization for Vision Transformer Authors Zhenhua Liu, Yunhe Wang, Kai Han, Siwei Ma, Wen Gao 最近,变压器在各种计算机视觉应用中取得了显着性能。与主流卷积神经网络相比,视觉变压器通常是复杂的架构,用于提取强大的特征表示,这更难以在移动设备上开发。在本文中,我们提出了一种有效的训练量化算法,用于降低视觉变压器的存储器存储和计算成本。基本上,量化任务分别可以分别被认为分别找到权重和输入的最佳低位量化间隔。为了保留注意力机制的功能,我们将排名损失引入传统量化目标,该目标旨在在量化之后保持自我注意结果的相对阶数。此外,我们彻底分析了不同层的量化损失与特征分集之间的关系,并通过利用每个关注图和输出特征的核标准来探索混合精密量化方案。所提出的方法的有效性在几个基准模型和数据集上验证,这优于训练训练量化算法的状态。例如,我们可以使用大约8比特量化的Imagenet DataSet上的Deit B型号获得81.29前1个精度。 |
| Image content dependent semi-fragile watermarking with localized tamper detection Authors Samira Hosseini, Mojtaba Mahdavi 内容独立的水印和阻止明智的独立性可以被视为半脆弱水印方法中的漏洞。在本文中,为了实现半脆弱的水印技术的目的,提出了一种方法,没有提到的缺点。在所提出的方法中,通过依赖于图像内容和键来生成水印。此外,使用钥匙使嵌入方案导致水印块相互依赖于彼此。在嵌入阶段,图像被划分为非重叠块。为了更准确地检测和分离不同类型的攻击,所提出的方法将每个水印比特的三个副本嵌入每个4x4块的LWT系数。在认证阶段,通过在提取的比特之间投票,创建错误映射这些地图表示图像真实性并显示修改区域。此外,为了自动执行认证,将图像分为四个类别,使用七个功能。实验中的分类准确性为97.97%。应注意,我们的实验表明,该方法对JPEG压缩具有稳健性,并且在鲁棒性和半脆弱性方面具有艺术半脆弱水印方法的状态。 |
| Building a Video-and-Language Dataset with Human Actions for Multimodal Logical Inference Authors Riko Suzuki, Hitomi Yanaka, Koji Mineshima, Daisuke Bekki 本文介绍了一种新的视频和语言数据集,具有用于多模式逻辑推理的人为动作,其侧重于描述动态人类行为的故意和方面表达。数据集由200个视频,5,554个操作标签和1,942个动作三元组成的表单主题,谓词,可以转换为逻辑语义表示的对象。预计数据集将用于评估视频和语义复杂句子之间的多模式推理系统,包括否定和量化。 |
| Semi-supervised Semantic Segmentation with Directional Context-aware Consistency Authors Xin Lai, Zhuotao Tian, Li Jiang, Shu Liu, Hengshuang Zhao, Liwei Wang, Jiaya Jia 近年来,语义细分已经取得了巨大进展。然而,满足性能高度取决于大量的像素级注释。因此,在本文中,我们专注于半监督分割问题,其中只有一小组标记的数据提供了更大的完全未标记的图像集合。然而,由于有限的注释,模型可能会依赖于培训数据中可用的上下文,这导致之前的景观差。优选的高级表示应该捕捉上下文信息,同时不会失去自我意识。因此,我们建议在相同身份的特征之间保持上下文意识一致性,而是用不同的上下文,使得表示对不同环境的鲁棒。此外,我们呈现了方向性对比损耗DC损耗以实现像素的稠度,仅需要具有较低质量的特征朝向其对方对准。此外,为了避免虚假的阴性样本和过滤不确定的阳性样本,我们提出了两种采样策略。广泛的实验表明,我们的简单且有效的方法通过大的余量超越了现有技术的当前状态,并且还概括了额外的图像级注释。 |
| Robust Pose Transfer with Dynamic Details using Neural Video Rendering Authors Yang tian Sun, Hao zhi Huang, Xuan Wang, Yu kun Lai, Wei Liu, Lin Gao 人类视频的姿势转移旨在生成一个模仿源人的目标人员的高保真视频。通过具有深层潜在特征的图像转换或具有明确的3D特征的神经渲染,一些研究取得了很大进展。然而,他们都依靠大量的训练数据来产生现实的结果,并且由于训练框架不足而在更可访问的互联网视频上降低。在本文中,我们证明了动态细节甚至可以从短单眼视频培训。总体而言,我们提出了一种神经视频渲染框架,其基于图像转换的动态细节生成网络D2G网络,它充分利用了显式3D特征的稳定性和学习组件的容量。具体地,提出了一种新颖的纹理表示来编码静态和姿势变化的外观特征,然后将其映射到图像空间并作为神经渲染阶段中的富帧细节呈现。此外,我们在训练阶段介绍了一种简洁的时间损失,以抑制由于我们的方法产生的高质量动态细节而变得更加明显的细节闪烁。通过广泛的比较,我们证明我们的神经人体视频渲染器能够实现更清晰的动态细节和更强大的性能,即使在具有2K 4K帧的可访问的短视频上也是如此。 |
| Attention-guided Progressive Mapping for Profile Face Recognition Authors Junyang Huang, Changxing Ding 过去几年目睹了面部认可领域的巨大进展,因为深入学习的进步。然而,交叉构成面部识别仍然是一个重大挑战。许多深入学习算法很难缩小由姿势变化引起的性能差距,这与不同姿势的面部图像与训练数据集的姿势不平衡有关的主要原因。学习姿势强大的特征通过遍历正面面的特征空间提供了一种有效且便宜的方式来缓解这个问题。在本文中,我们介绍了一种用细心的一对明智损失逐渐将轮廓面表示转换为规范姿势的方法。首先,为了减少直接将轮廓面特征转换为正面姿势的难度,我们建议在块插入时尚中学习源姿势和其附近的姿势之间的特征残差,从而遍历较小姿势的特征空间通过添加学习的残差。其次,我们提出了一对明智的损失,以引导特征变换在最有效的方向上进展。最后,我们提出的渐进式模块和细心的一对明智的损失是重量轻且易于实现的,仅增加约7个额外参数。 CFP和CPLFW数据集的评估表明了我们提出的方法的优越性。代码可用 |
| Hear Me Out: Fusional Approaches for Audio Augmented Temporal Action Localization Authors Anurag Bagchi, Jazib Mahmood, Dolton Fernandes, Ravi Kiran Sarvadevabhatla 未经监控的视频时间动作定位的最先进的架构只考虑了RGB和流量模当,留下了丰富的音频模型完全未开发的信息。探讨了音频融合的相关但是可以说的修剪剪辑级别动作识别的问题。然而,TAL构成了一系列独特的挑战。本文提出了简单但有效的基于融合方法的Tal。据我们所知,我们的作品是第一个共同考虑监督的音频和视频方式的工作。我们通过实验表明我们的计划始终如一地改善艺术视频唯一方法的绩效。具体而言,它们有助于在大型基准数据集ActivityNET 1.3 52.73 Map 0.5和Thumos14 57.18 Map 0.5上实现新的最新状态。我们的实验包括涉及多个融合方案,模态组合和算法的消融。我们的代码,模型和关联数据将可用。 |
| An Image Classifier Can Suffice Video Understanding Authors Quanfu Fan, Chun Fu Richard Chen, Rameswar Panda 通过将视频识别问题作为图像识别任务施放视频识别问题,我们提出了一种新的视角。我们表明,单独的图像分类器可以足以进行视频理解,而没有时间建模。我们的方法很简单而普遍。它将输入帧组成为超级图像以训练图像分类器以满足操作识别的任务,以与分类图像的方式完全相同。我们通过在包括Kinetics400的四个公共数据集中展示强大和有希望的性能,使用最近开发的视觉变压器来证明在包括Kinetics400,MIT和JEST的某些东西的强大和有希望的表现来证明这种想法的可行性。我们还在计算机愿景中尝试普遍的Reset Image分类器,以进一步验证我们的想法。 KINETICS400的结果与基于时空时间建模的一些最佳CNN方法相当。我们的代码和型号将可用 |
| Image Classification with CondenseNeXt for ARM-Based Computing Platforms Authors Priyank Kalgaonkar, Mohamed El Sharkawy 在本文中,我们展示了在为自动驾驶车辆开发的自主驾驶开发平台上实现了我们超高效的深度卷积神经网络架构Condensenext。我们表明CondenSenext在拖鞋方面非常有效,专为具有有限的计算资源的ARM的嵌入式计算平台而设计,并且可以在不需要CUDA的GPU的情况下执行图像分类。 CONDENSENEXT利用艺术的艺术的状态深度可分离卷积和模型压缩技术,以实现显着的计算效率。广泛的分析是在CiFar 10,CiFar 100和Imagenet数据集上进行的,以验证CondenSenext卷积神经网络CNN架构的性能。它在三个基准数据集中实现了艺术图像分类性能的状态,包括CIFAR 10 4.79前1个错误,CiFar 100 21.98前1个错误和Imagenet 7.91单一型号,单一裁剪前5个错误。 CONDENSENEXT与CONTENENET相比,最终培训的模型尺寸提高为2.9 MB,高达59.98倍,最高拖鞋,并且可以在基于ARM的计算平台上执行图像分类,而无需支持CUDA,具有出色的效率。 |
| Real-time 3D Object Detection using Feature Map Flow Authors Youshaa Murhij, Dmitry Yudin 在本文中,我们介绍了考虑时间空间特征映射聚集的实时3D检测方法,从不同时间步长命名为特征映射流,FMF。提出的方法提高了基于3D检测中心的基线的质量,并在NUSCENES和WAYMO基准上提供实时性能。代码可用 |
| Radar Voxel Fusion for 3D Object Detection Authors Felix Nobis, Ehsan Shafiei, Phillip Karle, Johannes Betz, Markus Lienkamp 由于需要处理的可能场景,物体和天气条件,汽车交通场景很复杂。与更多约束环境相比,例如自动地下列车,汽车感知系统无法对特定任务的狭窄领域量身定制,但必须使用无法预见的事件处理曾更换的环境。由于目前没有单个传感器能够可靠地在周围环境中感知所有相关活动,因此应用传感器数据融合以使尽可能多的信息感知。在低抽象水平上的不同传感器和传感器模式的数据融合使得能够补偿传感器之间的传感器弱点和误差在信息富传感器数据被压缩之前,从而在传感器个体对象检测后丢失信息。本文开发了一个用于3D对象检测的低级传感器融合网络,包括LIDAR,CAMERA和RADAR数据。融合网络培训并在NUSCENES数据集上进行培训。在测试集上,与基线激光雷达网络相比,雷达数据的融合将导致的AP平均精度检测得分提高约5.1。雷达传感器融合在诸如雨夜场景之类的恶劣条件下证明特别有益。融合额外的摄像机数据仅与雷达融合结合呈积极贡献,这表明传感器的相互依存性对检测结果很重要。另外,本文提出了一种新的损失来处理对象检测的简单偏航表示的不连续性。我们的更新损失会增加所有传感器输入配置的检测和方向估计性能。本研究的代码已在GitHub上提供。 |
| Generalized Zero-Shot Learning using Multimodal Variational Auto-Encoder with Semantic Concepts Authors Nihar Bendre, Kevin Desai, Peyman Najafirad 随着数据的增加,多式化学习中的中央挑战涉及标记样本的局限性。对于分类的任务,诸如META学习,零射击学习等技术,以及很少的镜头学习展示了基于先前知识学习关于新颖类别信息的能力。最近的技术试图学习语义空间和图像空间之间的跨模型映射。然而,他们倾向于忽视本地和全球语义知识。为了克服这个问题,我们提出了一个多模式变分自动编码器M VAE,其可以学习图像特征和语义空间的共享潜空间。在我们的方法中,我们将多模式数据连接到单个嵌入,然后将其传递给VAE以学习潜在空间。我们提出在通过解码器嵌入的特征重建期间使用多模态损耗。我们的方法能够关联模态并利用本地和全球语义知识进行新型样本预测。我们在四个基准数据集上使用MLP分类器的实验结果表明,我们所提出的模型优于广义零射击学习的最新状态。 |
| Interflow: Aggregating Multi-layer Feature Mappings with Attention Mechanism Authors Zhicheng Cai 传统上,CNN模型具有分层结构并利用最后一层的特征映射来获得预测输出。但是,它可能难以解决最佳的网络深度,并使中间层学习杰出功能。本文提出了专门用于传统CNN模型的交互算法。 Interflow根据深度将CNN分成几个阶段,并通过每个阶段中的特征映射进行预测。随后,我们将这些预测分支输入到设计良好的注意力模块中,该模块学习这些预测分支的权重,聚合它们并获得最终输出。交换权重和融合在较浅和更深层层中学到的特征,使每个阶段的特征信息合理且有效地处理,使中间层能够了解更多的特征,并提高模型表示能力。此外,交流可以减轻梯度消失问题,降低网络深度选择的难度,通过引入注意机制来减轻拟合问题。此外,它可以避免网络劣化作为副产品。与原始模型相比,具有交流的CNN模型在多个基准数据集中实现了更高的测试准确性。 |
| Saying the Unseen: Video Descriptions via Dialog Agents Authors Ye Zhu, Yu Wu, Yi Yang, Yan Yan 当前的视觉和语言任务通常采用完整的视觉数据,例如,原始图像或视频作为输入,但是,实际方案通常可以包括由于各种原因而无法访问的视觉信息的某一部分无法访问的情况,例如,具有固定相机或故意视觉的限制视图阻止安全问题。作为迈向更实际的应用方案的一步,我们介绍了一种新的任务,该任务旨在描述使用两个代理之间的自然语言对话的视频,作为给定不完整的视觉数据的补充信息源。不同于最现有的视觉语言任务,其中AI系统可以完全访问图像或视频剪辑,这可能会揭示诸如可识别的人类面或声音等敏感信息,我们有意限制AI系统的视觉输入并寻求更安全且透明的信息介质,即自然语言对话框,用于补充缺少的视觉信息。具体地,其中一个智能代理Q Bot从视频的开始和结尾给出了两个语义分段帧,以及在描述看不见的视频之前提出相关的自然语言问题的有限机会。 BOT,另一个可以访问整个视频的代理商,协助Q BOT通过回答所述问题来实现目标。我们介绍了两种不同的实验设置,即生成剂,即代理商自由地生成问题和答案,或者是代理商从候选内部对话生成过程中选择问题和答案。通过拟议的统一QA合作网络,我们通过实验证明了两个对话代理商之间的知识转移过程和使用自然语言对话的有效性作为不完整隐性愿景的补充。 |
| A Graph-based approach to derive the geodesic distance on Statistical manifolds: Application to Multimedia Information Retrieval Authors Zakariae Abbad, Ahmed Drissi El Maliani, Said Ouatik El Alaoui, Mohammed El Hassouni 在本文中,我们利用非欧几里德几何形状的特性来在统计歧管空间上定义测地距Gd。测地距离是一个真实而直观的相似度测量,这是纯粹统计和广泛使用的kullback Leibler分发KLD的替代方案。尽管GD的有效性,但许多歧管的闭合形式不存在,因为测地方程很难解决。这解释说,主要研究已经满足于使用数值近似。尽管如此,大多数人都不考虑歧管属性,这导致信息丢失,从而导致低性能。我们提出了通过基于曲线图的方法近似测地距离。这种后一种允许良好代表统计歧管的结构,并尊重其几何特性。我们的主要目的是将基于图形的近似值与最新的近似值进行比较。因此,考虑到在不同数据库上的基于内容的纹理检索应用程序,评估所提出的方法,即,考虑到基于内容的纹理检索应用程序,评估了两个统计歧管,即Weibull歧管和伽马歧管。 |
| Identifying High Accuracy Regions in Traffic Camera Images to Enhance the Estimation of Road Traffic Metrics: A Quadtree Based Method Authors Yue Lin, Nningchuan Xiao 城市地区越来越多的实时相机饲料使得能够为有效的运输计划,运营和管理提供高质量的交通数据。然而,由于当前车辆检测技术的局限性以及诸如高度和分辨率之类的各种相机条件,从这些相机馈送中获取可靠的交通指标是挑战。在这项工作中,开发了一种基于四足基于Quadtree的算法,以连续分区图像范围,直到剩余高检测精度的区域。这些区域被称为本文中的高精度识别区域。我们展示了头发的使用如何通过在俄亥俄州的不同高度和分辨率下,使用来自交通摄像机的图像使用来自交通摄像机的图像的准确性。我们的实验表明,所提出的算法可用于导出稳健的头发,其中车辆检测精度比原始图像范围高的41%。头发的使用也显着提高了流量密度估计,整体下降了49%的根部平均平方误差。 |
| Semi-Supervised Deep Ensembles for Blind Image Quality Assessment Authors Zhihua Wang, Dingquan Li, Kede Ma 如果基本学习者被认为是准确和多样化,则集合方法通常被认为比单个模型更好。在这里,我们调查了一个半监督的集合学习策略,以产生更广泛的盲目图像质量评估模型。我们通过最大化集合的准确性以及标记数据的基础学习者以及在未标记数据上实现的分歧,培训一个多头卷积网络的质量预测。我们进行广泛的实验,以展示采用BIQA的未标记数据的优势,特别是在模型泛化和故障识别方面。 |
| Mining atmospheric data Authors Chaabane Djeraba, J r me Riedi 本文概述了对采矿遥感数据的两个相互依存问题,例如:从大气监测任务获得的图像。第一个问题涉及建立新的公共数据集和基准,这是遥感社区的热门优先级。第二个问题是根据没有注释的大量数据以及由表面稀疏观察网络提供的大量数据,对大气数据分类进行大气数据分类的深度学习方法调查。目标应用是空气质量评估和预测。空气质量被定义为与诸如气体和气溶胶等几种大气成分相关的污染水平。空气质量不足,空气污染和公共卫生之间存在依赖关系。目标应用是开发用于本地和区域空气质量评估和跟踪的快速预测模型。采矿数据的结果将通过提供快速预测和可靠的空气质量监测系统,通过基于原位测量网络的稀疏地面智能外推,通过提供快速预测和可靠的空气质量监测系统对公民和决策者产生重大影响。 |
| ShapeEditer: a StyleGAN Encoder for Face Swapping Authors Shuai Yang, Kai Qiao 在本文中,我们提出了一种新颖的编码器,称为成像器,用于高分辨率,现实和高保真面部交换。首先,为了确保足够的清晰度和真实性,我们的关键思想是使用先进的预制高质量随机性面膜图像发生器,即Stylegan,作为骨干。其次,我们设计成像器,两个步骤编码器,使交换面集成输入面的标识和属性。在第一步中,我们分别在第二步骤中提取源图像的标识矢量和目标图像的属性向量,我们将标识向量和属性向量的连接映射到Mathcal W潜在空间中。此外,为了学习映射到Stylegan的潜在空间,我们提出了一系列自我监督损失函数,其中不需要手动标记训练数据。在测试数据集上的广泛实验表明,我们的方法结果不仅具有比其他现有技术的清晰度和真实性具有很大的优势,而且还反映了身份和属性的充分集成。 |
| Descriptive Modeling of Textiles using FE Simulations and Deep Learning Authors Arturo Mendoza, Roger Trullo, Yanneck Wielhorski 在这项工作中,我们提出了一种用于在编织复合材料中提取纱线几何特征的新颖和全自动方法,从而实现了纺织加强件的直接参数化。,例如Fe网格。因此,我们的目的不仅是从断层图像执行纱线分割,而是提供完整的织物的描述性建模。因此,这种直接方法改善了先前的方法,该方法使用体素明智的掩模作为中间表示,然后进行啮合操作纱线包络估计。拟议的方法采用两个深神经网络架构U Net和Mask RCNN。首先,我们训练U网以产生来自相应的FE模拟的合成CT图像。这允许在不需要昂贵的手动注释的情况下生成大量注释数据。然后使用该数据来训练掩模R CNN,其专注于预测图像中的每个纱线周围的轮廓点。实验结果表明,我们的方法对于在CT图像上执行纱线实例分割是准确和鲁棒的,这通过定量和定性分析进一步验证。 |
| Semantics-aware Multi-modal Domain Translation:From LiDAR Point Clouds to Panoramic Color Images Authors Tiago Cortinhal, Fatih Kurnaz, Eren Aksoy 在这项工作中,我们展示了一个简单而有效的框架,以解决不同传感器模式之间的域翻译问题,具有唯一的数据格式。通过仅依赖现场的语义,我们的模块化生成框架可以是从给定的完整3D LIDAR点云合成全景彩色图像。该框架从点云的语义分割开始,该云初始被投射到球面上。相同的语义分割应用于相应的相机图像。接下来,我们的新条件生成模型对抗将预测的LIDAR段映射转换为相机图像对应物。最后,处理生成的图像段以呈现全景场景图像。我们对Semantickitti DataSet提供彻底的定量评估,并显示我们所提出的框架优于其他强大的基线模型。 |
| Exploring Temporal Context and Human Movement Dynamics for Online Action Detection in Videos Authors Vasiliki I. Vasileiou, Nikolaos Kardaris, Petros Maragos 如今,人和机器人之间的相互作用是不断扩展的,需要越来越多的人类运动识别应用程序实时运行。然而,大多数作品在时间动作检测和识别上以离线方式执行这些任务,即,时间分段视频被归类为整体。本文基于最近提出的时间复发网络框架,我们探讨了如何有效地用于在线动作检测的时间背景和人体运动动态。我们的方法使用本领域的各种状态,并适当地结合提取的特征以改善动作检测。我们对挑战但广泛使用的数据集进行了挑战但广泛使用的数据集,Thumos 14.我们的实验表现出对基线方法的显着改善,实现了最新的拇指14的结果。 |
| OffRoadTranSeg: Semi-Supervised Segmentation using Transformers on OffRoad environments Authors Anukriti Singh, Kartikeya Singh, P.B. Sujit 我们在非结构化的户外环境中使用offroadtranseg,是使用变压器和标签的自动数据选择在非结构化室外环境中的半监控分段结束框架。越野分割是一种现场了解方法,可广泛用于自主驾驶。流行的越野分割方法是使用完全连接的卷积层和大标记数据,但是,由于类不平衡,将有几种不匹配,也可能无法检测到某些类别。我们的方法是以半监督方式执行越野分割的任务。目的是提供一种模型,其中自我监控视觉变换器用于微调越野数据集,具有自我监督数据收集,用于使用深度估计标记。所提出的方法在Rellis 3D和Rugd越野数据集上验证。实验表明,Offrooadtranseg优于其他最新的艺术模型,也解决了Rellis 3D类不平衡问题。 |
| In-N-Out: Towards Good Initialization for Inpainting and Outpainting Authors Changho Jo, Woobin Im, Sung Eui Yoon 在计算机视觉中,通过填充蒙面区域,例如染色,恢复空间信息已被广泛调查其可用性和对其他各种应用图像修复,图像推断和环境图估计的可用性和广泛适用性。其中大多数是根据应用单独研究的。然而,我们的焦点是在适应相反的任务,例如,图像突出,这将使目标应用有益,例如图像染色。我们的自我监督方法在n外,总结为一种培训方法,利用对目标模型的相反任务的知识。我们经验证明,在N OUT中探讨了互补信息,有效地利用了传统管道,只有在训练中进行任务特定学习。在实验中,我们将我们的方法与传统程序进行比较,并分析我们对不同应用图像修复,图像推断和环境图估计的方法的有效性。对于这些任务,我们证明,在n out始终如一地提高最近有效的性能,以对他们的培训程序进行自我监督。此外,我们表明我们的方法比现有的培训方法达到了更好的结果。 |
| Spectral-Spatial Graph Reasoning Network for Hyperspectral Image Classification Authors Di Wang, Bo Du, Liangpei Zhang 在本文中,我们提出了一种用于高光谱图像HSI分类的光谱空间图形推理网络SSGRN。具体地,该网络包含两个部分,单独命名的空间图形推理Sagrn和Spectral图形推理Subnetwork Segrn分别捕获空间和光谱图上下文。不同于在原始图像上实现Superpixel分割的先前方法或试图在标签图像指南下获取类别特征,我们在网络的中间特征上执行Superpixel分段,以自适应地产生均匀区域以获得有效描述符。然后,我们在频谱部分中采用类似的想法,该频谱部分具有合理地聚合信道以产生频谱描述符的频谱图表上下文捕获。 Sagrn和Segrn中的所有图形推理过程通过图形卷积实现。为了保证所提出的方法的全球感知能力,在非局部自我注意机制的帮助下获得图表推理中的所有相邻矩阵。最后,通过组合提取的空间和光谱图上下文,我们获得了高精度分类的SSGRN。三个公共恒生公司基准的广泛定量和定性实验证明了与其他现有技术方法相比的拟议方法的竞争力。 |
| Domain Adaptive YOLO for One-Stage Cross-Domain Detection Authors Shizhao Zhang, Hongya Tuo, Jian Hu, Zhongliang Jing 域名是对象探测器概括到现实世界应用程序的主要挑战。用于两个阶段探测器的域改性的新兴技术有助于解决这个问题。然而,由于其长时间消耗,两级探测器不是工业应用的首选。本文提出了一种新型结构域自适应yoloDayolo,以改善一个阶段探测器的横域性能。图像级别特征对齐用于严格匹配纹理等本地功能,并松散地匹配,以符合照明等全局功能。提供多尺度实例级别特征对齐以有效地减少实例域移位,例如对象外观和视点的变化。采用对这些域分类器的共识正常化来帮助网络生成域不变的检测。我们评估我们在Citycapes,Kitti,SiM10K等的流行数据集上的建议方法。结果在不同跨域场景下测试时,结果表明了显着的改进。 |
| Inverting and Understanding Object Detectors Authors Ang Cao, Justin Johnson 作为计算机视觉中的核心问题,对象检测的性能在过去几年中大幅提升。尽管令人印象深刻的性能,但对象探测器患有缺乏可解释性。已经开发了可视化技术,并广泛应用于对其他类型的深度学习模型进行的决策,然而,可视化对象探测器已经过度曝光。在本文中,我们建议使用反转作为主要工具来理解现代对象探测器并开发基于优化的布局反演方法,允许我们通过培训的检测器产生识别的合成图像,如包含对象的所需配置。我们通过将布局反演技术应用于各种现代物体探测器来揭示探测器的有趣特性,并通过验证实验进一步研究它们,他们依赖于分类和回归的定性不同的特征,他们学习他们使用差异的常用同源的规范图案视觉提示识别不同大小的对象。我们希望我们的见解可以帮助从业者改善对象探测器。 |
| Dual-Stream Reciprocal Disentanglement Learning for Domain Adaption Person Re-Identification Authors Huafeng Li, Kaixiong Xu, Jinxing Li, Guangming Lu, Yong Xu, Zhengtao Yu, David Zhang 由于人类标记的样本是免费的目标集,因此近年来近年来识别的未经监督的人重新识别,通过此外,近年来吸引了很多关注。然而,由于相机样式,照明和背景的差异,源域和目标域之间存在很大的差距,对跨域匹配引入了巨大挑战。为了解决这个问题,在本文中,我们提出了一种名为双重流互惠脱离的新方法学习DRDL,这在学习域不变的功能中非常有效。在DRDL中,首先构造两个编码器,用于ID相关和ID不相关的特征提取,其分别由其相关联的分类器测量。此外,随后是对侵犯学习策略,两条流互相互相影响,使得ID相关特征和ID不相关的特征从给定图像完全脱离,允许编码器足够强大以获得识别但域不变特征。与现有方法相比,我们所提出的方法没有图像生成,这不仅可以显着降低计算复杂性,而且还可以从ID相关特征中删除冗余信息。与现有技术相比,广泛的实验证实了我们所提出的方法的优越性。源代码已被释放 |
| CAMS: Color-Aware Multi-Style Transfer Authors Mahmoud Afifi, Abdullah Abuolaim, Mostafa Hussien, Marcus A. Brubaker, Michael S. Brown 图像样式传输旨在操纵源图像或内容图像的外观,共享目标样式图像的类似纹理和颜色。理想情况下,风格传输操作还应保留源图像的语义内容。一种常用的方法来辅助传输样式是基于克矩阵优化。基于GRAM矩阵优化的一个问题是它不考虑颜色与其样式之间的相关性。具体地,某些纹理或结构应与特定颜色相关联。当目标样式图像呈现多种样式类型时,这尤其具有挑战性。在这项工作中,我们提出了一种颜色感知多样式传输方法,在美学上令人愉悦的结果,同时保留样式和生成的图像之间的风格色相关。我们通过对经典克基于CLAT矩阵的样式传输优化进行简单但有效的修改来实现这一期望的结果。我们的方法的一个很好的功能是它使用户能够手动选择目标样式和内容图像之间的颜色关联以获取更多的传输灵活性。我们验证了我们有几种定性比较的方法,包括使用30名参与者进行的用户学习。与现有工作相比,我们的方法很简单,易于实现,并在定位具有多种样式的图像时实现视觉上吸引人的结果。源代码可用 |
| Multimodal Few-Shot Learning with Frozen Language Models Authors Maria Tsimpoukelli, Jacob Menick, Serkan Cabi, S.M. Ali Eslami, Oriol Vinyals, Felix Hill 当以足够的规模培训时,自动回归语言模型在提示时显示出于几个示例后,展示了学习新语言任务的能力。在这里,我们展示了一种简单但有效的方法,用于将这几个射击学习能力转移到多峰设置视觉和语言。使用对齐图像和标题数据,我们培训视觉编码器,将每个图像表示为连续嵌入的序列,使得使用此前缀提示的预训练的冻结语言模型生成了相应的标题。由此产生的系统是一个多模式的镜头学习者,具有令人惊讶的能力,在调节示例时学习各种新任务,表示为多个交错图像和文本嵌入的序列。我们证明它可以迅速学习新对象和新颖的视觉类别的单词,通过仅通过测量各种建立和新的基准测试的单一模型来使用少数示例的视觉问题,并利用外部知识。 |
| Semi-Supervised Raw-to-Raw Mapping Authors Mahmoud Afifi, Abdullah Abuolaim 相机传感器的原始RGB颜色由于不同传感器的光谱灵敏度差异而变化,而模型。本文侧重于在不同传感器原始RGB颜色空间之间映射的任务。使用成对校准以实现准确的颜色映射来解决此问题。虽然准确,但这种方法不太实用,因为它需要通过两个摄像机设备捕获一对图像,其中两台颜色校准对象放置在每个新的场景2精确的图像对齐或手动注释的颜色校准对象。本文旨在通过更实用的设置解决原始空间中的颜色映射。具体而言,我们向沿着由每个相机设备捕获的未配对的图像组培训,向原始映射方法呈现了一小组配对图像的半导体映射方法。通过广泛的实验,我们表明,除了单一校准解决方案之外,我们的方法还可以与其他域适配替代方案相比实现更好的结果。我们从两个不同的智能手机相机中生成了一个新的原始图像数据集,作为这项工作的一部分。我们的数据集包括我们的半监督培训和评估的未配对和配对集。 |
| Scene Uncertainty and the Wellington Posterior of Deterministic Image Classifiers Authors Stephanie Tsuei, Aditya Golatkar, Stefano Soatto 我们提出了一种方法来估计在给定输入数据上的图像分类器的结果的不确定性。常用于图像分类的深神经网络是从输入图像到输出类的确定性映射。因此,它们在给定基准上的结果涉及不确定性,因此我们必须指定我们在定义,测量和解释信心时指的是什么可变性。为此,我们介绍了惠灵顿后验,这是响应于可以由产生给定图像的相同场景产生的数据而获得的结果的分布。由于有无数的场景可以生成给定的图像,因此惠灵顿后视需要从描绘的人物以外的场景感应。我们使用数据增强,合奏和模型线性化探索替代方法。其他替代方案包括生成的对抗性网络,条件现有网络和监督单视图重建。我们通过推断视频中的时间上相邻帧的类别来测试这些替代方案。这些开发只是一种小步骤,旨在以与安全关键应用兼容的方式评估深网络分类器的可靠性。 |
| Nonuniform Defocus Removal for Image Classification Authors Nguyen Hieu Thao, Oleg Soloviev, Jacques Noom, Michel Verhaegen 我们提出并研究了使用机器学习算法与图像分类相关联的单帧anisoplanatic解卷积问题,命名为非均匀散焦去除NDR问题。提出了对NDR问题的数学分析,提出了所谓的Defocus去除DR算法来解决它。建立了DR算法的全局收敛而不施加任何无法验证的假设。仿真数据上的数值结果显示了DR包括可解性,噪声稳健性,收敛性,模型不敏感性和计算效率的显着特征。在实验数据上测试了NDR问题和DR算法的实用性的物理相关性。回到最初激励对NDR问题调查的应用程序,我们表明DR算法可以使用卷积神经网络提高分类扭曲图像的准确性。本文的关键差异与大多数现有的单帧anIsoplanatic解卷积相比是新方法不要求数据图像可分解为Isoplanatic子区域。因此,将图像分区的解决方案方法不适用于NDR问题,并且需要开发和分析诸如DR算法之类的整个图像的NDR问题。 |
| Fully Steerable 3D Spherical Neurons Authors Pavlo Melnyk, Michael Felsberg, M rten Wadenb ck 从低级视觉理论中出现,可操纵过滤器在深度学习中找到了他们的对应物。早些时候的作品使用转向定理并呈现卷积网络等于僵化的变换。在我们的工作中,我们提出了一种基于球体决策表面的基于球体决策的方法,并在点云上运行。由于我们理论的固有的几何3D结构,我们为其原子零部件(Hyphersphersphere Neurons)推导了3D可操作性约束。利用旋转设备,我们展示了模型参数在推理时间内的完全可操作。所提出的球形滤波器银行能够使成本等值,并且在线优化之后,以未知的取向为已知的合成点集的不变等级预测。 |
| A CNN Segmentation-Based Approach to Object Detection and Tracking in Ultrasound Scans with Application to the Vagus Nerve Detection Authors Abdullah F. Al Battal, Yan Gong, Lu Xu, Timothy Morton, Chen Du, Yifeng Bu 1, Imanuel R Lerman, Radhika Madhavan, Truong Q. Nguyen 超声扫描对于几种医疗诊断和治疗应用是必不可少的。它用于可视化和分析影响治疗计划的解剖特征和结构。然而,它既是劳动密集型,其有效性是依赖的运营商。实时准确和稳健的自动检测和解剖结构的跟踪,同时扫描将显着影响诊断和治疗程序是一致和有效的。在本文中,我们提出了深度学习框架,以自动检测和跟踪超声扫描中的特定解剖目标结构。我们的框架旨在跨对象和成像设备准确和强大,实时运行,而不需要大型训练。当培训在原始训练集的大小的训练集上培训时,它保持了定位精度,召回高于90的召回。框架骨干是基于U网的弱训练分割神经网络。我们在两个不同的超声数据集上测试了框架,目的是检测和跟踪迷走神经,在那里它优于现有的实时对象检测网络的当前状态。 |
| EARLIN: Early Out-of-Distribution Detection for Resource-efficient Collaborative Inference Authors Sumaiya Tabassum Nimi, Md Adnan Arefeen, Md Yusuf Sarwar Uddin, Yugyung Lee 协作推断使资源受限的边缘设备能够通过上传输入例如服务器的图像来制作推断。,云,云的云。虽然该设置有效地用于成功推断,但是当模型面向未知培训的输入样本时,它会严重表现出型号的输入样本,而是已知出于分发OOD样本。如果边缘设备至少可以检测到输入样本是OOD,这可能会通过未将这些输入上载到推理工作负载的服务器来节省通信和计算资源。在本文中,我们提出了一种新颖的轻质IOOD检测方法,该方法从普拉的CNN模型的浅层中挖掘重要特征,并根据在减少的特征空间上定义的距离功能来检测输入样本作为ID的分布或ood。我们的技术A在预制模型上没有任何重新培训那些模型的型号,而B不会将其自身暴露于任何OOD数据集所有检测参数从ID训练数据集获得。为此,我们开发Earlin早期的检测,用于协作推断,采用预制模型,并在OOD检测层处分区模型,并在边缘设备和云上的其余部分部署相当小的OOD部分。通过使用真实数据集和原型实施来进行实验,我们表明我们的技术在对基准数据集预先追踪的流行深度学习模型之上测试的全面准确性和成本方面的结果比其他方法以及成本更好。 |
| Progressive Joint Low-light Enhancement and Noise Removal for Raw Images Authors Yucheng Lu, Seung Won Jung 由于通过相对小的孔径的入射光不足,移动设备上的低光成像通常是挑战的,导致噪声比率低信号。最重要的是,低光图像处理的工作焦点仅在单一的任务上,诸如照明调整,颜色增强或噪音或噪声调整和噪声调整和去噪任务,并依赖于特定相机收集的短的长曝光图像对模型,因此这些方法在现实世界环境中较不实用和更广泛,需要相机特定的联合增强和恢复。为了解决这个问题,在本文中,我们提出了一种低光图像处理框架,可执行关节照明调整,颜色增强和去噪。考虑到模型特定数据收集的困难和捕获图像的超高清,我们设计两个分支系数估计分支以及关节增强和去噪分支。系数估计分支在低分辨率空间中工作,并通过双边学习预测增强的系数,而关节增强和去噪分支在全分辨率空间中工作,并以逐步的方式执行关节增强和去噪。与现有方法相比,我们的框架不需要在适应另一个相机型号时重新调用大规模数据,这显着降低了微调我们实际使用方法所需的努力。通过广泛的实验,与现有技术的现有技术相比,我们在现实世界的低光成像应用中展示了它的巨大潜力。 |
| Understanding Dynamics of Nonlinear Representation Learning and Its Application Authors Kenji Kawaguchi, Linjun Zhang, Zhun Deng 世界环境的代表在机器智能中发挥着至关重要的作用。直接在原始感觉表示的空间中进行推理和推理通常效率低下,例如图像的像素值。表示学习允许我们自动从原始感官数据发现合适的表示。例如,给定原始感觉数据,多层的Perceptron在其隐藏层中学习非线性表示,随后在其输出层上用于分类或回归。通过最大限度地减少监督或无监督的损失,这在培训期间隐含地发生这种情况。在本文中,我们研究了这种隐含非线性表示学习的动态。我们识别一对新的假设和新颖的条件,称为共同模型结构假设和数据架构对齐条件。在共模结构假设下,数据架构对齐条件被示出为全局收敛和全局最优性所必需的。我们的结果提供了设计模型结构的实际指导。,常见的模型结构假设可以用作使用特定模型结构而不是其他结构的理由。作为应用程序,我们将推导出一种新的训练框架,其满足数据架构对齐条件,而无需在依赖于每个数据和架构上自动修改任何给定的训练算法。鉴于标准培训算法,经验证明运行其修改版本的框架,以保持竞争实用的实际测试表演,同时为ResET 18提供包含卷曲,跳过连接和批量标准化的全球收敛保证,包括标准基准数据集,包括MNIST,CIFAR 10,CIFAR 100,hemeion,Kmnist和Svhn。 |
| Speech2Properties2Gestures: Gesture-Property Prediction as a Tool for Generating Representational Gestures from Speech Authors Taras Kucherenko, Rajmund Nagy, Patrik Jonell, Michael Neff, Hedvig Kjellstr m, Gustav Eje Henter 我们为姿态产生了新的框架,旨在允许数据驱动的方法产生更多的语义上丰富的手势。我们的方法首先预测是否姿态,然后是对手势属性的预测。然后将这些属性用作能够高质量输出的现代概率手势产生模型的特性。这使得能够生成既多样化和代表的手势的方法。 |
| Tiled sparse coding in eigenspaces for the COVID-19 diagnosis in chest X-ray images Authors Juan E. Arco, Andr s Ortiz, Javier Ram rez, Juan M Gorriz 2019年大流行的Covid 19冠状病毒疾病的持续危机改变了世界。根据世界卫生组织,400万人因这种疾病而死亡,而有超过1.8亿的Covid案件19.许多国家的卫生系统崩溃表明了开发工具自动化的需要医学成像诊断疾病。以前的研究已经为此目的使用了深入的学习。然而,这种替代方案的性能高度取决于用于训练算法的数据集的大小。在这项工作中,我们提出了一种基于稀疏编码的分类框架,以识别与不同病理相关的肺炎模式。具体地,每个胸部X射线CXR图像被划分为不同的瓦片。然后,从PCA提取的最相关的功能将用于在稀疏编码过程中构建字典。一旦从字典的元素转换并重建图像,就与与每个图像相关联的各个块的重建误差来执行分类。性能在实际情况下评估,其中四种不同病理控制与细菌肺炎vs病毒肺vs vs covid 19之间的同时分化。识别肺炎存在时的准确性为93.85,而88.11在4级分类上下文中获得。在这种情况下,稀疏编码的优异成果和开拓使用证据证明了这种方法在真实世界环境中对临床医生的援助。 |
| Weighted multi-level deep learning analysis and framework for processing breast cancer WSIs Authors Peter Bokor, Lukas Hudec, Ondrej Fabian, Wanda Benesova 预防和早期诊断乳腺癌BC是选择适当治疗的必要先决条件。由于对自动解决方案的更快和更精确的诊断结果的需求增加,由于需求的增加而导致的大量压力。在过去的十年中,深入学习技术已经证明了他们在几个域的功率,计算机辅助CAD诊断成为其中之一。但是,涉及到整个幻灯片图像的分析WSI,大多数现有的工程都在独立地计算来自级别的预测。然而,与需要在BC分类中看到重要的组织结构的全球结构的组织医学家专家方法相反。 |
| ACN: Adversarial Co-training Network for Brain Tumor Segmentation with Missing Modalities Authors Yixin Wang, Yang Zhang, Yang Liu, Zihao Lin, Jiang Tian, Cheng Zhong, Zhongchao Shi, Jianping Fan, Zhiqiang He 来自磁共振成像MRI的脑肿瘤的精确分割在诊断,预后和手术治疗中临床相关,这需要多种方式提供互补的形态和物理病理学信息。然而,由于在临床实践中的某些造影剂的图像损坏,文物,不同的采集协议或过敏因素而常见的模态通常发生。尽管现有的努力展示了所有缺失情况的统一模型的可能性,但大多数人在缺少多种态度时表现不佳。在本文中,我们提出了一种新的对抗性CO培训网络ACN来解决这个问题,其中一系列独立但相关模型的培训专用于每个缺失的情况,结果明显更好。具体而言,ACN采用新型CO训练网络,其使耦合的学习过程能够为全模态和缺少的模态提供彼此的域和特征表示,更重要的是,恢复非不前方式的缺失信息。然后,提出了两个无监督的模块,即熵和知识对抗性学习模块,以最小化域间隙,同时增强预测可靠性并鼓励潜在表示的对准。我们还调整模型互信息知识转移学习到ACN,以保留模式之间的富人信息。关于Brats2018数据集的广泛实验表明,我们所提出的方法在任何缺失情况下显着优于所有现有技术的所有状态。 |
| FreeTickets: Accurate, Robust and Efficient Deep Ensemble by Training with Dynamic Sparsity Authors Shiwei Liu, Tianlong Chen, Zahra Atashgahi, Xiaohan Chen, Ghada Sokar, Elena Mocanu, Mykola Pechenizkiy, Zhangyang Wang, Decebal Constantin Mocanu 最近在稀疏神经网络上的作品已经证明,可以隔离训练稀疏网络,以匹配相应的密集网络的性能与参数分数相匹配。然而,识别这些性能稀疏的神经网络获胜票证涉及昂贵的迭代火车训练,例如,彩票票假设或超过延长的稀疏训练时间,例如,具有动态稀疏性的培训,这两者都将提高财务和环境问题。在这项工作中,我们通过引入FreeTickets概念来解决这一成本还原问题,作为一种可以通过大边距提高稀疏卷积神经网络的第一种解决方案,以便仅使用完整的培训分数后者所需的计算资源。具体而言,我们通过提出具有动态稀疏性的两种新颖的高效集合方法来实例化FreeTickets Concept,这在稀疏训练过程中可以获得许多多样化和准确的门票。这些免费门票进入集合的组合展示了相应的密集集合网络上的准确性,不确定性估计,鲁棒性和效率的显着提高。我们的结果为稀疏神经网络的实力提供了新的见解,并提出了稀疏性的好处,超出了通常的培训推理预期效率。我们将释放所有代码 |
| Benchmarking convolutional neural networks for diagnosing Lyme disease from images Authors Sk Imran Hossain LIMOS , Jocelyn de Go r de Herve INRAE , Md Shahriar Hassan LIMOS , Delphine Martineau, Evelina Petrosyan, Violaine Corbain, Jean Beytout, Isabelle Lebert INRAE , Elisabeth Baux CHRU Nancy , C line Cazorla CHU de Saint Etienne , Carole Eldin IHU M diterran e Infection , Yves Hansmann, Solene Patrat Delon, Thierry Prazuck CHR , Alice Raffetin CHIV , Pierre Tattevin CHU Rennes , Gwena l Vourc H INRAE , Olivier Lesens, Engelbert Nguifo LIMOS 莱姆病是世界上最常见的传染性载体疾病之一。在早期阶段,在大多数情况下,该疾病表现出红斑迁移症em皮肤病变。由于适当的抗生素治疗,更好地诊断这些早期形式的诊断将使通过防止过渡到严重的后期形式来改善预后。最近的研究表明,卷积神经网络CNNS表现出从图像中识别皮肤病因子,但是从EM病变图像中没有多少工作。本研究的主要目的是广泛分析CNNS用于从图像诊断莱姆病的有效性,并为目的找出最佳的CNN架构。没有公开的EM图像数据集,用于莱姆病预测主要是因为隐私问题。在这项研究中,我们利用了由来自法国和互联网的克雷蒙佛兰达大学医院中心CF楚收集的图像组成的EM数据集。 CF Chu在法国的几家医院收集了图片。该数据集由来自CF楚的专家皮肤科医生和感染学家标记。首先,在预测性能指标,计算复杂度指标和统计显着性测试方面,我们将此数据集进行了二十三个公知的CNN架构。其次,为了提高CNNS的性能,我们使用从想象成预训练的模型的转移学习以及预先培训的CNN与皮肤病患者对机器有10000次训练图像HAM1000。在该过程中,我们在转移学习为每个CNNS的传输学习精细调整期间搜索最佳执行的层数以解冻。第三,对于模型解释性,我们利用梯度加权类激活映射来可视化对CNN的输入区域,以便进行预测。第四,我们根据预测性能和计算复杂性提供了模型选择指导。我们的研究证实了甚至用于莱姆病前扫描仪移动应用的一些轻量级CNN的有效性和潜力。我们还将所有训练有素的型号公开提供 |
| Co$^2$L: Contrastive Continual Learning Authors Hyuntak Cha, Jaeho Lee, Jinwoo Shin 最近在自我监督学习中的突破表明,这种算法学会了比依托任务特定监督的联合培训方法更好地转移到未经联合任务的视觉表现。在本文中,我们发现,在灾难性的遗忘之上,持续学习的持续学习和文本中的相似的持有对比灾难性的遗忘比接受训练的遗传更强。基于这种新颖的观察,我们提出了一种基于排练的持续学习算法,专注于不断学习和维持可转让的陈述。更具体地,所提出的方案1使用对比学学习目标来学习表示,2使用自我监督蒸馏步骤保留学习的表示。我们在流行的基准图像分类数据集下进行广泛的实验验证,我们的方法设置了最新的最新状态。 |
| A 3D CNN Network with BERT For Automatic COVID-19 Diagnosis From CT-Scan Images Authors Weijun Tan, Jingfeng Liu 我们提出了一种从肺CT扫描切片图像的自动Covid1 19诊断框架。在该框架中,CT扫描卷的切片图像首先使用分段技术进行预订,以滤除闭合肺的图像,并删除无用的背景。然后,重采样方法用于选择用于训练和验证的一个或多个固定数量的切片图像。使用BERT的3D CNN网络用于对这组选择的切片图像进行分类。在该网络中,还提取了嵌入功能。在体积中存在多个切片图像的情况下,提取所有集合的特征并汇集到全局特征向量中以进行整个CT扫描卷。简单的多层Perceptron MLP网络用于进一步对聚合特征向量进行分类。这些模型在提供的培训和验证数据集上进行培训和评估。在验证数据集上,准确性为0.9278,F1分数为0.9261。 |
| Kimera-Multi: Robust, Distributed, Dense Metric-Semantic SLAM for Multi-Robot Systems Authors Yulun Tian, Yun Chang, Fernando Herrera Arias, Carlos Nieto Granda, Jonathan P. How, Luca Carlone 本文介绍了金龙多功能系统,第一多个机器人系统,即我坚固,能够识别和拒绝由于感知混叠而产生的不正确和内部机器人循环闭合,II完全分布,并且仅依赖于本地对等通信以实现分布式本地化和映射,并且III实时构建环境的全球一致的度量语义3D网格模型,其中网格的面部用语义标签注释。 Kimera Multi由配备视觉惯性传感器的机器人团队实施。每个机器人都构建了局部轨迹估计和使用Kimera的本地网格。当通信可用时,机器人基于新颖的分布式刻度非凸性算法发起分布式地点识别和鲁棒姿态图优化协议。该协议允许机器人通过利用机器人循环闭合而鲁棒到异常值来改善其局部轨迹估计。最后,每个机器人使用其改进的轨迹估计来使用网格变形技术来校正本地网格。 |
| Deep Learning Image Recognition for Non-images Authors Boris Kovalerchuk, Divya Chandrika Kalla, Bedant Agarwal 强大的深度学习算法通过将这些问题转换为图像识别问题,开辟了解决非图像机器学习ML问题的机会。本章中所示的CPC R算法通过可视化非图像数据将非图像数据转换为图像。然后深入学习CNN算法解决了这些图像上的学习问题。 CPC R算法的设计允许在2D图像中保留所有高维信息。使用对值映射而不是在替代方法中使用的单值映射允许使用较少的可视元素的2倍编码每个n d点。 N D点的属性被分成其值对,并且每对可视化为同一2 D Cartesian坐标的2 D点。接下来,将灰度或颜色强度值分配给每对以进行编码对顺序。这导致了热图图像。 CPC R的计算实验是针对不同的CNN架构进行的,以及优化CPC R图像的方法,示出了组合的CPC R和深度学习CNN算法能够解决基准数据集上达到高精度的非图像ML问题。本章通过添加更多实验来扩展我们的先前工作来测试分类准确性,探索所发现的功能的显着性和信息性以测试其可解释性,并概括方法。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com