keras推荐算法--矩阵分解实战
(实践操作过程中,如果数据量超大,单机会出现内存溢出报错,无法正常运行,建议先用少量进行测试实现)
当今这个信息爆炸的社会,每个人都会面对无数的商品,无数的选择。而推荐算法的目的帮助大家解决选择困难症的问题,在大千世界中推荐专属于你的商品。
推荐系统算法简介
这里简单介绍下推荐系统中最为主要的协同过滤算法,大致分为如下几类:
- 基于用户的协同过滤(给用户推荐与他相似的人购买的物品)
- 基于商品的协同过滤(给用户推荐和他之前喜欢的物品相似的物品)
- 基于模型的协同过滤:关联算法,聚类算法,分类算法,回归算法,矩阵分解,神经网络,图模型以及隐语义模型都属于这个范畴。
而本次实战使用的是矩阵分解算法。
矩阵分解其实是数学上的一个经典问题。大家从线性代数中可以知道,矩阵可以做SVD分解、Cholesky分解等,就好比任何大于1的正整数都可以分解成若干质数的乘积,矩阵分解可以认为是一种信息压缩。下图是一个用户电影评分矩阵。矩阵的每行表示一个用户,每列表示一部电影,矩阵中每个位置的值,代表某个用户对某个电影的评分值。
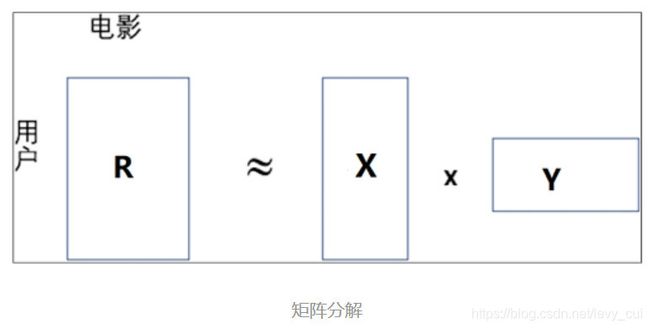
- R矩阵:用户对电影的评分组合矩阵,用户矩阵,
- 每一个被压缩的行向量代表一个用户的信息向量,
- 电影矩阵,每一个被压缩列向量代表一个电影的信息向量。
而这样的矩阵分解压缩过程,使得用户矩阵和电影矩阵都具有了一定的语义信息,必须强调的是用户矩阵行向量的维数和电影矩阵列向量维数是相等的。所以本质上就是将每个用户和每个电影通过已有的打分信息Embedding到同一维度的信息向量空间。
接下来我们就学习一下如何使用keras对R矩阵进行矩阵分解,获得每个电影和每个用户的信息向量。
推荐系统实战
数据载入
import pandas as pd
import numpy as np
rating = pd.read_csv("./ml-latest-small/ratings.csv",sep=",")
num_user = np.max(rating["userId"])
num_movie = np.max(rating["movieId"])
print(num_user,num_movie,len(rating))数据格式如下,第一列是index,第二列是用户ID,第三列是电影ID,第四列示评分。(userId是排序过的数字)
userId movieId rating
0 1 1 4.0
1 1 3 4.0
2 1 6 4.0
3 1 47 5.0
......
100831 610 166534 4.0
100832 610 168248 5.0
100833 610 168250 5.0
100834 610 168252 5.0
100835 610 170875 3.0其中num_user = 610, num_movie = 193609 len(rating)=100836。意味着我的数据中有610为观众,193609 部电影,得到了100836个评分数据。从这些我们可以计算出上图用户电影组合的R矩阵的填充率。
100836/(610*193609)=0.008
这说明只有0.8%的用户电影组合有评分,当然这和实际情况是相符的,毕竟一个人只会给很少部分的电影评分,所以我们发现用户对电影的评分组合矩阵R极其稀疏。所以接下来我们要做的就是预测那些没有评分的用户电影组合可能的得分,填充R矩阵,这样就可以为用户推荐模型预测得分较高的电影。
模型搭建
from keras import Model
import keras.backend as K
from keras.layers import Embedding,Reshape,Input,Dot
K.clear_session()
def Recmand_model(num_user,num_movie,k):
input_uer = Input(shape=[None,],dtype="int32")
model_uer = Embedding(num_user+1,k,input_length = 1)(input_uer)
model_uer = Reshape((k,))(model_uer)
input_movie = Input(shape=[None,],dtype="int32")
model_movie = Embedding(num_movie+1,k,input_length = 1)(input_movie)
model_movie = Reshape((k,))(model_movie)
out = Dot(1)([model_uer,model_movie])
model = Model(inputs=[input_uer,input_movie], outputs=out)
model.compile(loss='mse', optimizer='Adam')
model.summary()
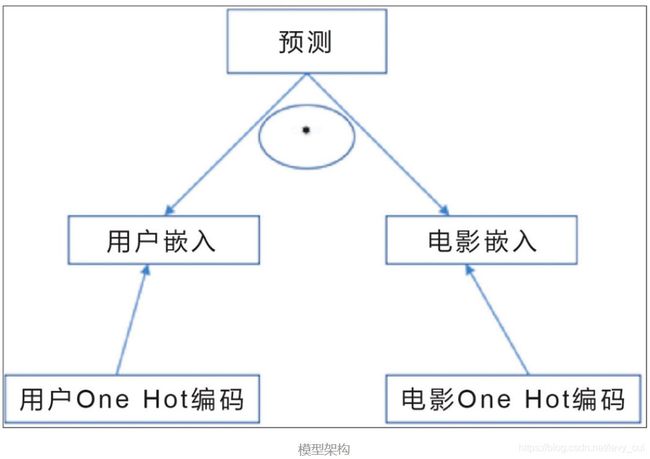
return model这里就是矩阵分解的部分,模型的架构图如下图所示:将用户和电影通过Eembdding层压缩到k维度向量,然后简单粗暴直接向量点乘,得到用户对电影的预测评分。这里误差采用平方误差MSE,优化器采用的是Adam。
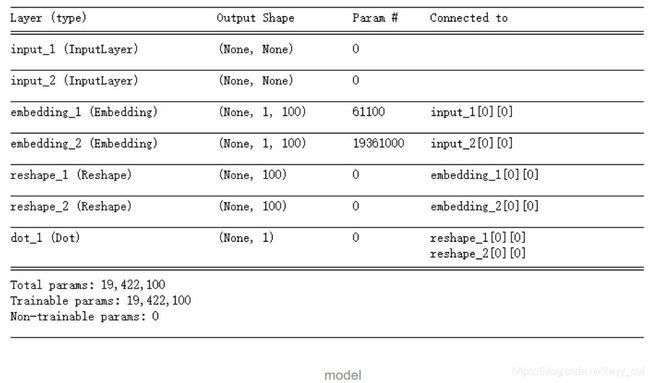
model = Recmand_model(num_user,num_movie,100)运行上方代码就可以构建好模型,这里笔者将用户和电影都embedding的100维的向量空间中。
数据准备
将数据准备成( [用户ID, 电影ID] , 用户ID对电影ID的评分 )这种格式。接下来就可以把数据喂给模型了。
train_user = rating["userId"].values
train_movie = rating["movieId"].values
train_x = [train_user,train_movie]
train_y = rating["rating"].values拿到输入数据之后,设置好batch_size,epoch,就可以进行训练了。运行下面代码让模型跑起来。
模型训练
model.fit(train_x,train_y,batch_size = 100,epochs =10)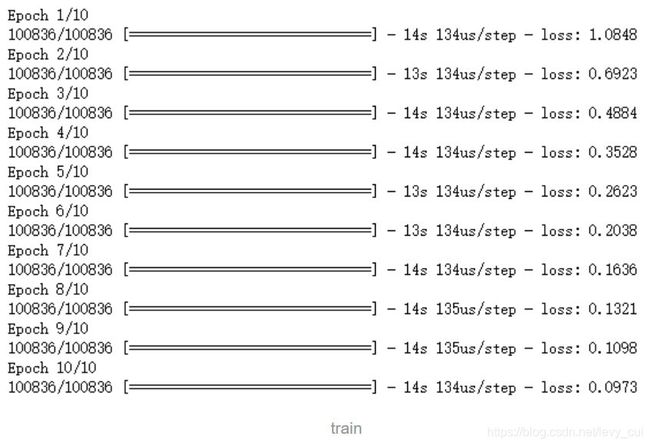
十个epoch之后loss只有0.09,这样我们就可以不严谨的下结论:模型的预测误差不超出0.1,接下来是预测部分。
模型预测
从之前读入数据中可以得知,userId为1的用户,没有对movieId为2的电影评分。我们就用模型试试userId为1的用户会为movieId为2的电影打多少数分呢?运行下方代码,便能知晓。
model.predict([[1],[2]])
输出结果:array([[3.9732044]], dtype=float32)模型预测为3.9,而评分的总分为5分,意味着userId为1的用户很有可能会喜欢movieId为2的电影。可以考虑将movieId为2的电影推荐给userId为1的用户。
结语
这里只是采用了最简单的方式做了一个简单的推荐系统,而且此方式很难解决新的电影和新的用户的推荐问题。推荐系统是门很深的学问,算法不仅需要考虑到推荐的准确率,覆盖率,还要考虑到推荐内容的丰富性和新颖性。
参考:https://www.jianshu.com/p/822274ce05e4