【机器学习】聚类【Ⅲ】高斯混合模型讲解
主要来自周志华《机器学习》一书,数学推导主要来自简书博主“形式运算”的原创博客,包含自己的理解。
有任何的书写错误、排版错误、概念错误等,希望大家包含指正。
由于字数限制,分成五篇博客。
【机器学习】聚类【Ⅰ】基础知识与距离度量
【机器学习】聚类【Ⅱ】原型聚类经典算法
【机器学习】聚类【Ⅲ】高斯混合模型讲解
【机器学习】聚类【Ⅳ】高斯混合模型数学推导
【机器学习】聚类【Ⅴ】密度聚类与层次聚类
4.6 高斯混合聚类
4.6.1 一元高斯分布
高斯分布(Gaussian distribution),也称正态分布(Normal distribution),又名“常态分布”。若一维随机变量 x x x 服从一个位置参数为 μ \mu μ、尺度参数为 σ \sigma σ 的正态分布,则其概率密度函数为
p ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 (34) p(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\tag{34} p(x)=2πσ1e−2σ2(x−μ)2(34)
特别地,当 μ = 0 \mu=0 μ=0, σ = 1 \sigma=1 σ=1 时,正态分布为标准正态分布
p ( x ) = 1 2 π e − x 2 2 (35) p(x)=\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}}\tag{35} p(x)=2π1e−2x2(35)
4.6.2 多元高斯分布
多元高斯分布亦称为多元正态分布,是单维正态分布向多维的推广。假设 n n n 维随机变量 x = ( x 1 ; x 2 ; ⋅ ⋅ ⋅ ; x n ) \pmb x= (x_1;x_2;···;x_n) xx=(x1;x2;⋅⋅⋅;xn) 的每一维互不相关且服从正态分布,则其概率密度函数为
p ( x ) = 1 ( 2 π ) n 2 ∣ Σ ∣ 1 2 e − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) (36) p(\pmb x)=\frac{1}{(2\pi)^\frac{n}{2}\vert \pmb \Sigma \vert^\frac{1}{2}} e^{-\frac{1}{2} (\pmb x-\pmb \mu)^T\pmb \Sigma^{-1}(\pmb x-\pmb \mu)}\tag{36} p(xx)=(2π)2n∣ΣΣ∣211e−21(xx−μμ)TΣΣ−1(xx−μμ)(36)
其中 μ \pmb \mu μμ 是 n n n 维均值向量, Σ \pmb \Sigma ΣΣ 是 n × n n×n n×n 的协方差矩阵。由式 ( 36 ) (36) (36) 可看出,高斯分布完全由均值向量 μ \pmb \mu μμ 和协方差矩阵 Σ \pmb \Sigma ΣΣ 这两个参数确定。为了明确显示高斯分布与相应参数的依赖关系,将概率密度函数记为 p ( x ∣ μ , Σ ) p(\pmb x \mid \pmb \mu ,\pmb \Sigma) p(xx∣μμ,ΣΣ) 。
一元高斯分布到多元高斯分布的推导:
为了区分一元高斯分布和多元高斯分布的概率密度函数,分别用符号 p ( ) p() p() 和 f ( ) f() f() 表示。
各个维度的均值 μ = ( μ 1 ; μ 2 ; ⋅ ⋅ ⋅ ; μ n ) \pmb \mu=(\mu_1;\mu_2;···;\mu_n) μμ=(μ1;μ2;⋅⋅⋅;μn),方差 σ = ( σ 1 ; σ 2 ; ⋅ ⋅ ⋅ ; σ n ) \pmb \sigma=(\sigma_1;\sigma_2;···;\sigma_n) σσ=(σ1;σ2;⋅⋅⋅;σn) 。根据联合概率密度公式
f ( x ) = f ( x 1 , x 2 , ⋅ ⋅ ⋅ , x n ) = p ( x 1 ) p ( x 2 ) ⋅ ⋅ ⋅ p ( x n ) = 1 ( 2 π ) n σ 1 σ 2 ⋅ ⋅ ⋅ σ n e − ( x 1 − μ 1 ) 2 2 σ 1 2 − ( x 2 − μ 2 ) 2 2 σ 2 2 ⋅ ⋅ ⋅ − ( x n − μ n ) 2 2 σ n 2 (37) f(\pmb x)=f(x_1,x_2,···,x_n)=p(x_1)p(x_2)···p(x_n)=\frac{1}{(\sqrt{2\pi})^n\sigma_1\sigma_2···\sigma_n}e^{-\frac{(x_1-\mu_1)^2}{2\sigma_1^2}-\frac{(x_2-\mu_2)^2}{2\sigma_2^2}···-\frac{(x_n-\mu_n)^2}{2\sigma_n^2}}\tag{37} f(xx)=f(x1,x2,⋅⋅⋅,xn)=p(x1)p(x2)⋅⋅⋅p(xn)=(2π)nσ1σ2⋅⋅⋅σn1e−2σ12(x1−μ1)2−2σ22(x2−μ2)2⋅⋅⋅−2σn2(xn−μn)2(37)
令 z 2 = ( x 1 − μ 1 ) 2 2 σ 1 2 + ( x 2 − μ 2 ) 2 2 σ 2 2 + ⋅ ⋅ ⋅ + ( x n − μ n ) 2 2 σ n 2 z^2=\frac{(x_1-\mu_1)^2}{2\sigma_1^2}+\frac{(x_2-\mu_2)^2}{2\sigma_2^2}+···+\frac{(x_n-\mu_n)^2}{2\sigma_n^2} z2=2σ12(x1−μ1)2+2σ22(x2−μ2)2+⋅⋅⋅+2σn2(xn−μn)2, σ z = σ 1 σ 2 ⋅ ⋅ ⋅ σ n \sigma_z=\sigma_1\sigma_2···\sigma_n σz=σ1σ2⋅⋅⋅σn,如此将多元高斯分布转换为与一元高斯分布比较接近的形式
f ( z ) = 1 ( 2 π ) n σ z e − z 2 2 (38) f(z)=\frac{1}{(\sqrt{2\pi})^n\sigma_z}e^{-\frac{z^2}{2}}\tag{38} f(z)=(2π)nσz1e−2z2(38)
因为多元高斯分布有着很强的几何思想,单纯从代数的角度看待 z z z 很难看出 z z z 的概率分布规律,这里需要转换成矩阵形式
z 2 = z T z = ( x 1 − μ 1 , x 2 − μ 2 , ⋅ ⋅ ⋅ , x n − μ n ) ( 1 σ 1 2 0 ⋯ 0 0 1 σ 2 2 ⋯ 0 ⋮ ⋮ ⋮ 0 0 ⋯ 1 σ n 2 ) ( x 1 − μ 1 , x 2 − μ 2 , ⋅ ⋅ ⋅ , x n − μ n ) T (39) z^2=z^Tz=(x_1-\mu_1,x_2-\mu_2,···,x_n-\mu_n) \left( \begin{matrix} \frac{1}{\sigma_1^2} & 0 & \cdots & 0 \\ 0 & \frac{1}{\sigma_2^2} & \cdots & 0 \\ \vdots & \vdots &&\vdots\\ 0 & 0 & \cdots & \frac{1}{\sigma_n^2} \\ \end{matrix} \right) (x_1-\mu_1,x_2-\mu_2,···,x_n-\mu_n)^T\tag{39} z2=zTz=(x1−μ1,x2−μ2,⋅⋅⋅,xn−μn)⎝ ⎛σ1210⋮00σ221⋮0⋯⋯⋯00⋮σn21⎠ ⎞(x1−μ1,x2−μ2,⋅⋅⋅,xn−μn)T(39)
定义符号
Σ = ( σ 1 2 0 ⋯ 0 0 σ 2 2 ⋯ 0 ⋮ ⋮ ⋮ 0 0 ⋯ σ n 2 ) \pmb \Sigma= \left( \begin{matrix} \sigma_1^2 & 0 & \cdots & 0 \\ 0 & \sigma_2^2 & \cdots & 0 \\ \vdots & \vdots & & \vdots \\ 0 & 0 & \cdots & \sigma_n^2 \end{matrix} \right) ΣΣ=⎝ ⎛σ120⋮00σ22⋮0⋯⋯⋯00⋮σn2⎠ ⎞
Σ \pmb \Sigma ΣΣ 代表变量 x \pmb x xx 的协方差矩阵, i i i 行 j j j 列的元素值表示 x i x_i xi 与 x j xj xj 的协方差。因为现在变量之间是相互独立的,所以只有对角线上( i = j i=j i=j)存在元素,其它位置都是 0 0 0,且 x i x_i xi 与它本身的协方差就等于方差。Σ \pmb \Sigma ΣΣ 是一个对角阵,根据对角矩阵的性质,若 Σ \pmb \Sigma ΣΣ 为非奇异阵,则其逆矩阵为
Σ − 1 = ( 1 σ 1 2 0 ⋯ 0 0 1 σ 2 2 ⋯ 0 ⋮ ⋮ ⋮ 0 0 ⋯ 1 σ n 2 ) \pmb \Sigma^{-1}= \left( \begin{matrix} \frac{1}{\sigma_1^2} & 0 & \cdots & 0 \\ 0 & \frac{1}{\sigma_2^2} & \cdots & 0 \\ \vdots & \vdots &&\vdots\\ 0 & 0 & \cdots & \frac{1}{\sigma_n^2} \\ \end{matrix} \right) ΣΣ−1=⎝ ⎛σ1210⋮00σ221⋮0⋯⋯⋯00⋮σn21⎠ ⎞
另外, σ z \sigma_z σz 也可以通过 Σ \pmb \Sigma ΣΣ 表示
σ z = ∣ Σ ∣ 1 2 = σ 1 σ 2 ⋅ ⋅ ⋅ σ n (40) \sigma_z=\vert \pmb \Sigma \vert^{\frac{1}{2}}=\sigma_1\sigma_2···\sigma_n\tag{40} σz=∣ΣΣ∣21=σ1σ2⋅⋅⋅σn(40)
式 ( 39 ) (39) (39) 可简化为
z T z = ( x − μ ) T Σ − 1 ( x − μ ) (41) z^Tz=(\pmb x - \pmb \mu)^T\pmb \Sigma^{-1} (\pmb x - \pmb \mu)\tag{41} zTz=(xx−μμ)TΣΣ−1(xx−μμ)(41)
将式 ( 40 ) (40) (40) 和式 ( 41 ) (41) (41) 代回式 ( 38 ) (38) (38) 得
f ( x ) = 1 ( 2 π ) n 2 ∣ Σ ∣ 1 2 e − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) f(\pmb x)=\frac{1}{(2\pi)^\frac{n}{2}\vert \pmb \Sigma \vert^\frac{1}{2}} e^{-\frac{1}{2} (\pmb x-\pmb \mu)^T\pmb \Sigma^{-1}(\pmb x-\pmb \mu)} f(xx)=(2π)2n∣ΣΣ∣211e−21(xx−μμ)TΣΣ−1(xx−μμ)
即等价于式 ( 36 ) (36) (36),推导完毕。
4.6.3 单高斯分布模型
单高斯分布模型(Gaussian Single Model,简称 GSM)就是正态分布。因此, GSM 只能用于计算样本属于该模型的概率,设定阈值进而判断样本是否属于该模型。
以一维样本为例,假设存在一组男生身高和女生身高如下
| 男生 | 176.17 | 176.89 | 172.73 | 180.28 | 173.41 | 175.32 | 178.01 | 174.51 | 174.88 | 175.18 | 178.10 | 181.58 | 177.08 | 174.76 | 178.08 | 175.81 | 176.96 | 179.35 | 175.50 | 177.02 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 女生 | 161.24 | 162.69 | 163.51 | 161.02 | 162.32 | 162.53 | 161.72 | 160.62 | 160.16 | 162.69 | 162.46 | 167.46 | 158.13 | 163.23 | 163.74 | 165.72 | 164.00 | 161.31 | 163.00 | 164.08 |
表 3 男女身高
绘制散点图与频次柱状图如图 6 6 6 所示。
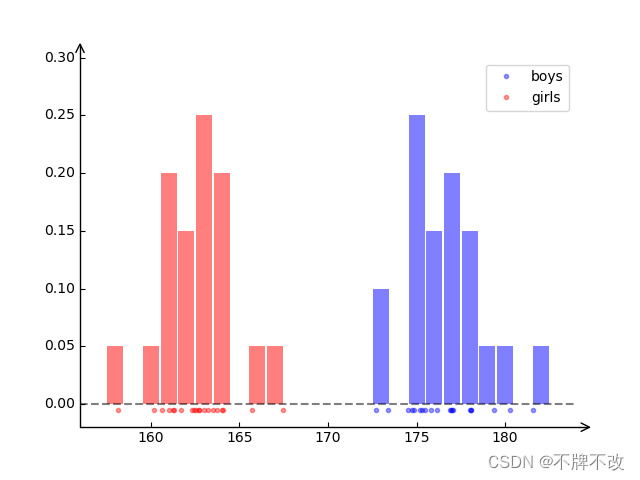
图 6 男女身高频次柱状图
显然,用一个高斯分布是无法准确表达男生女生身高分布,对于这组数据最起码应该用两个高斯分布来描述。可见,GSM 无法实现多分类,所以引入了混合高斯模型(Gaussian Mixture Model,简称 GMM,也译为 Mixture-of-Gaussian,简称MOG)。
4.6.4 高斯混合模型
可定义高斯混合分布
p M ( x ) = ∑ i = 1 k α i ⋅ p ( x ∣ μ i , Σ i ) (42) p_{\mathcal M}(\pmb x)=\sum_{i=1}^k \alpha_i\space·\space p(\pmb x\mid\pmb \mu_i,\pmb \Sigma_i)\tag{42} pM(xx)=i=1∑kαi ⋅ p(xx∣μμi,ΣΣi)(42)
该分布共由 k k k 个混合成分组成,每个混合成分对应一个高斯分布。其中 μ i \pmb \mu_i μμi 与 Σ i \pmb \Sigma_i ΣΣi 是第 i i i 个高斯混合成分的参数,而 α i > 0 \alpha_i >0 αi>0 为相应的“混合系数”(mixture coefficient), ∑ i = 1 k α i = 1 \sum_{i=1}^k\alpha_i=1 ∑i=1kαi=1 。
直观上,高斯混合模型就是将多个高斯分布加权,使模型能够描述满足不同高斯分布的数据。假设男生身高满足 ( μ b o y s , σ b o y s ) = ( 177 , 2 ) (\mu_{boys},\sigma_{boys})=(177,2) (μboys,σboys)=(177,2),女生身高满足 ( μ g i r l s , σ g i r l s ) = ( 163 , 2 ) (\mu_{girls},\sigma_{girls})=(163,2) (μgirls,σgirls)=(163,2),男生和女生的高斯分布曲线图如图 7 7 7 所示。

图 7 男女身高高斯分布曲线
图 8 8 8 左图所示为直接将两个分布相加和两个分布带权相加,我们知道男女比例大致为 1 : 1 1:1 1:1,所以假设权重 α b o y s = α g i r l s = 1 2 \alpha_{boys}=\alpha_{girls}=\frac{1}{2} αboys=αgirls=21 。

图 8 高斯混合分布曲线
当满足 ∑ i = 1 k α i = 1 \sum_{i=1}^k\alpha_i=1 ∑i=1kαi=1 时, p M ( ⋅ ) p_{\mathcal M}(·) pM(⋅) 也是概率密度函数,即 ∫ p M ( x ) d x = 1 \int p_{\mathcal M}(\pmb x)d\pmb x=1 ∫pM(xx)dxx=1 。
我觉得设定权重且规定权重和为 1 1 1 的原因有四点。
第一点是凑概率密度函数,保证积分值为 1 1 1,更贴近概率模型。
第二点是用权重表示先验概率,即 α i \alpha_i αi 表示属于(任何)样本属于第 i i i 个簇的概率,或者说满足第 i i i 个混合成分分布的概率,如此便可以将高斯混合分布 p M ( x , μ , Σ ) p_{\mathcal M}(\pmb x,\pmb \mu, \pmb \Sigma) pM(xx,μμ,ΣΣ) (更详细准确的模型表达形式,其中 μ = ( μ 1 , μ 2 , ⋅ ⋅ ⋅ , μ k ) \pmb \mu=(\pmb \mu_1,\pmb \mu_2,···,\pmb \mu_k) μμ=(μμ1,μμ2,⋅⋅⋅,μμk) , Σ \pmb \Sigma ΣΣ 同理)理解为全概率,即将对样本 x \pmb x xx 在参数为 ( μ , Σ ) (\pmb\mu,\pmb \Sigma) (μμ,ΣΣ) 的模型中出现的概率求解问题转化为了在不同混合成分(参数为 ( μ i , Σ i ) (\pmb \mu_i, \pmb \Sigma_i) (μμi,ΣΣi) 的高斯分布)中样本 x \pmb x xx 出现概率求和的简单问题。这样可以认为是对高斯混合分布函数,即式 ( 42 ) (42) (42) 的另一种理解。
剩下两点暂时不讲,最后进行说明。
高斯混合分布中的每个混合成分都对应着一个簇,混合成分函数值表示样本属于该簇的概率,那么高斯混合分布函数值就表示样本属于各个簇概率的加权,即样本属于这些簇的概率,或者说样本满足这个模型的概率。
一般是认为高斯混合分布在混合成分足够多的时候可以模拟任何分布。注意这里的关键在于「混合」而不是「高斯」,也就是说,重要的是各个分量之间的位置关系,而不是每个分量的形状。每个混合成分取为高斯,只是因为它的性质比较良好(比如密度函数处处可导),计算也相对简单。另外,根据中心极限定理的推广,可以认为自然界的很多现象都是由无数微小因素的叠加而产生的,而无论这种因素服从何种分布,在大尺度上来观察,其结果都应大致符合正态分布。因此,采用正态分布可能更加合理。
4.6.5 高斯混合模型的 EM 算法
我们知道 EM 算法用于含有隐变量概率模型参数的极大似然估计。存在隐变量可以理解为存在相互依赖关系,比如 k k k-means 聚类使用 EM 算法,因为计算模型参数(均值向量)需要依赖于样本类别的划分(可以理解为隐变量),而样本类别的划分又反过来依赖于模型参数的选取,这就是相互依赖关系,正是因为存在这种关系,所以我们采用 EM 算法迭代更新模型参数和隐变量。
狭义上的隐变量定义在不同书籍或博客中大不一样,但是广义上的隐变量都是指「样本类别的划分结果」,也就是上面描述 EM 算法时提到的。在我们整体把握模型的 EM 算法流程时,将隐变量认为是「样本类别的划分结果」非常有助于理解;但是涉及具体公式时,仍然需要具体问题具体指明。
既然 EM 算法离不开隐变量的计算,那么我们先定义隐变量,即规定如何对样本进行划分。
训练集 D = { x 1 , x 2 , ⋅ ⋅ ⋅ , x m } D= \{\pmb x_1, \pmb x_2,··· ,\pmb x_m\} D={xx1,xx2,⋅⋅⋅,xxm} ,令随机变量 z j ∈ { 1 , 2 , ⋅ ⋅ ⋅ , k } z_j\in\{1,2,···,k\} zj∈{1,2,⋅⋅⋅,k} 表示样本 x j \pmb x_j xxj 的高斯混合成分,其取值未知。显然, z j z_j zj 的先验概率 P ( z j = i ) P(z_j=i) P(zj=i) 对应于 α i \alpha_i αi ( i = 1 , 2 , ⋅ ⋅ ⋅ , k ) (i=1,2,···,k) (i=1,2,⋅⋅⋅,k) 。根据贝叶斯定理, z j z_j zj 的后验分布对应于
p M ( z j = i ∣ x j ) = P ( z j = i ) ⋅ p M ( x j ∣ z j = i ) p M ( x j ) = α i ⋅ p ( x j ∣ μ i , Σ i ) ∑ l = 1 k α l ⋅ p ( x j ∣ μ l , Σ l ) \begin{align} p_\mathcal{M}(z_j=i\mid \pmb x_j)& = \frac{P(z_j=i)\space·\space p_\mathcal{M}(\pmb x_j\mid z_j=i)}{p_\mathcal{M}(\pmb x_j)}\notag \\ &=\frac{\alpha_i\space ·\space p(\pmb x_j\mid \pmb \mu_i,\pmb \Sigma_i)}{\sum \limits_{l=1}^k\alpha_l\space · \space p(\pmb x_j\mid \pmb \mu_l,\pmb \Sigma_l)}\tag{43} \end{align} pM(zj=i∣xxj)=pM(xxj)P(zj=i) ⋅ pM(xxj∣zj=i)=l=1∑kαl ⋅ p(xxj∣μμl,ΣΣl)αi ⋅ p(xxj∣μμi,ΣΣi)(43)
当样本类别已知时, p M ( x j ∣ z j = i ) {p_\mathcal{M}(\pmb x_j \mid z_j=i)} pM(xxj∣zj=i) 退化为 p ( x j ∣ μ i , Σ i ) p(\pmb x_j\mid \pmb \mu_i,\pmb \Sigma_i) p(xxj∣μμi,ΣΣi) ,即确定了样本所属的混合成分,高斯混合分布退化为单高斯分布。
换言之, p M ( z j = i ∣ x j ) p_\mathcal{M}(z_j = i\mid \pmb x_j) pM(zj=i∣xxj) 给出了样本 x j \pmb x_j xxj 由第 i i i 个高斯混合成分生成的后验概率。为方便叙述,将其简记为 γ j i \gamma_{ji} γji ( i = 1 , 2 , ⋅ ⋅ ⋅ , k ) (i= 1,2,···, k) (i=1,2,⋅⋅⋅,k) 。
当高斯混合分布式 ( 42 ) (42) (42) 已知时,即参数 ( μ , Σ ) (\pmb \mu,\pmb \Sigma) (μμ,ΣΣ) 已知时,高斯混合聚类将把样本集 D D D 划分为 k k k 个簇 C = { C 1 , C 2 , ⋅ ⋅ ⋅ , C k } \mathcal C=\{C_1,C_2,··· ,C_k\} C={C1,C2,⋅⋅⋅,Ck},每个样本 x j \pmb x_j xxj 的簇标记 λ j \lambda_j λj 如下确定:
λ j = a r g max i ∈ { 1 , 2 , ⋅ ⋅ ⋅ , k } γ j i (44) \lambda_j=\mathop{{\rm arg} \max}_{i∈\{1,2,···,k\}}\space \gamma_{ji}\tag{44} λj=argmaxi∈{1,2,⋅⋅⋅,k} γji(44)
我们认为后验概率 γ j i \gamma_{ji} γji 就是 EM 算法中的隐变量。这主要是因为推导得到的参数更新公式(式 ( 47 ) (47) (47)、 ( 48 ) (48) (48) 和 ( 51 ) (51) (51))全都可以转换为依赖于后验概率 γ j i \gamma_{ji} γji 的形式。
根据式 ( 43 ) (43) (43),我们可以通过已知的模型参数 { ( α i , μ i , Σ i ) ∣ 1 ≤ i ≤ k } \{(\alpha_i,\pmb \mu_i,\pmb \Sigma_i)\mid 1 \le i\le k\} {(αi,μμi,ΣΣi)∣1≤i≤k} 计算出隐变量 γ j i \gamma_{ji} γji ,对应 EM 算法中的 E \rm E E 步。而已知隐变量求解模型参数的 M \rm M M 步,给定样本集 D D D,我们采用极大似然估计,即最大化(对数)似然
似然函数可以理解为目标函数或损失函数。
L L ( D ) = l n ( ∏ j = 1 m p M ( x j ) ) = ∑ j = 1 m l n ( ∑ i = 1 k α i ⋅ p ( x j ∣ μ i , Σ i ) ) \begin{align} LL(D)&={\rm ln}\left(\prod_{j=1}^mp_{\mathcal M}(\pmb x_j)\right) \notag \\ &=\sum_{j=1}^m{\rm ln}\left(\sum_{i=1}^k\alpha_i\space·\space p(\pmb x_j\mid \pmb \mu_i,\pmb \Sigma_i)\right)\tag{45} \end{align} LL(D)=ln(j=1∏mpM(xxj))=j=1∑mln(i=1∑kαi ⋅ p(xxj∣μμi,ΣΣi))(45)
下面对模型参数更新公式进行推导。
提醒一点,高斯混合分布的模型参数是 { ( α i , μ i , Σ i ) ∣ 1 ≤ i ≤ k } \{(\alpha_i,\pmb \mu_i,\pmb \Sigma_i)\mid 1\le i\le k\} {(αi,μμi,ΣΣi)∣1≤i≤k} ,即可学习参数,而每个混合成分的参数是 { ( μ i , Σ i ) ∣ 1 ≤ i ≤ k } \{(\pmb \mu_i,\pmb \Sigma_i)\mid 1\le i\le k\} {(μμi,ΣΣi)∣1≤i≤k} 。
若模型参数 { ( α i , μ i , Σ i ) ∣ 1 ≤ i ≤ k } \{(\alpha_i,\pmb \mu_i,\pmb \Sigma_i)\mid 1\le i\le k\} {(αi,μμi,ΣΣi)∣1≤i≤k} 能使式 ( 45 ) (45) (45) 最大化,则由 ∂ L L ( D ) ∂ μ i = 0 \frac{\partial LL(D)}{\partial \pmb \mu_i}=0 ∂μμi∂LL(D)=0 有
∑ j = 1 m α i ⋅ p ( x j ∣ μ i , Σ i ) ∑ l = 1 k α l ⋅ p ( x j ∣ μ l , Σ l ) ( x j − μ i ) = 0 (46) \sum_{j=1}^m\frac{\alpha_i\space ·\space p(\pmb x_j\mid \pmb \mu_i,\pmb \Sigma_i)}{\sum \limits_{l=1}^k \alpha_l\space·\space p(\pmb x_j\mid \pmb \mu_l,\pmb \Sigma_l)} (\pmb x_j-\pmb \mu_i)=0\tag{46} j=1∑ml=1∑kαl ⋅ p(xxj∣μμl,ΣΣl)αi ⋅ p(xxj∣μμi,ΣΣi)(xxj−μμi)=0(46)
由式 ( 43 ) (43) (43) 以及 γ j i = p M ( z j = i ∣ x j ) \gamma_{ji} =p_\mathcal M(z_j =i\mid \pmb x_j) γji=pM(zj=i∣xxj),有
μ i = ∑ j = 1 m γ j i x j ∑ j = 1 m γ j i (47) \pmb \mu_i=\frac{\sum \limits_{j=1}^m\gamma_{ji}\pmb x_j}{\sum\limits_{j=1}^m\gamma_{ji}}\tag{47} μμi=j=1∑mγjij=1∑mγjixxj(47)
另附 μ i \pmb \mu_i μμi 的求解过程。
即各混合成分的均值可通过样本加权平均来估计,样本权重是每个样本属于该成分的后验概率。类似地,由 ∂ L L ( D ) ∂ Σ i = 0 \frac{\partial LL(D)}{\partial \pmb \Sigma_i}=0 ∂ΣΣi∂LL(D)=0 可得
Σ i = ∑ j = 1 m γ j i ( x j − μ i ) ( x j − μ i ) T ∑ j = 1 m γ j i (48) \pmb \Sigma_i=\frac{\sum \limits_{j=1}^m\gamma_{ji} (\pmb x_j-\pmb \mu_i)(\pmb x_j-\pmb \mu_i)^T}{\sum\limits_{j=1}^m\gamma_{ji}}\tag{48} ΣΣi=j=1∑mγjij=1∑mγji(xxj−μμi)(xxj−μμi)T(48)
另附 Σ i \pmb \Sigma_i ΣΣi 的求解过程。
对于混合系数 α i \alpha_i αi,除了要最大化 L L ( D ) LL(D) LL(D),还需满足 α i ≥ 0 \alpha_i ≥0 αi≥0, ∑ i = 1 k α i = 1 \sum_{i=1}^k\alpha_i= 1 ∑i=1kαi=1,考虑 L L ( D ) LL(D) LL(D) 的拉格朗日形式
L L ( D ) + λ ( ∑ i = 1 k α i − 1 ) (49) LL(D)+\lambda\left(\sum_{i=1}^k\alpha_i - 1\right)\tag{49} LL(D)+λ(i=1∑kαi−1)(49)
其中 λ \lambda λ 为拉格朗日乘子。由式 ( 48 ) (48) (48) 对 α i \alpha_i αi 的导数为 0 0 0,有
∑ j = 1 m p ( x j ∣ μ i , Σ i ) ∑ l = 1 k α l ⋅ p ( x j ∣ μ l , Σ l ) + λ = 0 (50) \sum_{j=1}^m\frac{ p(\pmb x_j\mid \pmb \mu_i,\pmb \Sigma_i)}{\sum \limits_{l=1}^k \alpha_l\space·\space p(\pmb x_j\mid \pmb \mu_l,\pmb \Sigma_l)}+\lambda=0\tag{50} j=1∑ml=1∑kαl ⋅ p(xxj∣μμl,ΣΣl)p(xxj∣μμi,ΣΣi)+λ=0(50)
式 ( 50 ) (50) (50) 两边同乘以 α i \alpha_i αi,对 k k k 个类别求和,由 ∑ i = 1 k α i = 1 \sum_{i=1}^k\alpha_i=1 ∑i=1kαi=1 有
∑ i = 1 k ∑ j = 1 m α i ⋅ p ( x j ∣ μ i , Σ i ) ∑ l = 1 k α l ⋅ p ( x j ∣ μ l , Σ i ) + λ ∑ i = 1 k α i = 0 ∑ j = 1 m ∑ i = 1 k α i ⋅ p ( x j ∣ μ i , Σ i ) ∑ l = 1 k α l ⋅ p ( x j ∣ μ l , Σ i ) + λ = 0 m + λ = 0 λ = − m \sum_{i=1}^k\sum_{j=1}^m\frac{\alpha_i\space·\space p(\pmb x_j\mid \pmb \mu_i,\pmb \Sigma_i)}{\sum \limits_{l=1}^k \alpha_l\space·\space p(\pmb x_j\mid \pmb \mu_l,\pmb \Sigma_i)}+\lambda\sum_{i=1}^k\alpha_i=0\\ \sum_{j=1}^m\sum_{i=1}^k\frac{\alpha_i\space·\space p(\pmb x_j\mid \pmb \mu_i,\pmb \Sigma_i)}{\sum \limits_{l=1}^k \alpha_l\space·\space p(\pmb x_j\mid \pmb \mu_l,\pmb \Sigma_i)}+\lambda=0\\ m+\lambda=0\\ \lambda=-m i=1∑kj=1∑ml=1∑kαl ⋅ p(xxj∣μμl,ΣΣi)αi ⋅ p(xxj∣μμi,ΣΣi)+λi=1∑kαi=0j=1∑mi=1∑kl=1∑kαl ⋅ p(xxj∣μμl,ΣΣi)αi ⋅ p(xxj∣μμi,ΣΣi)+λ=0m+λ=0λ=−m
已知 λ = − m \lambda=-m λ=−m,式 ( 50 ) (50) (50) 两边同乘以 α i \alpha_i αi,有
α i = 1 m ∑ j = 1 m γ j i (51) \alpha_i=\frac{1}{m}\sum_{j=1}^m\gamma_{ji}\tag{51} αi=m1j=1∑mγji(51)
即每个高斯成分的混合系数由样本属于该成分的平均后验概率确定。
这样一来,高斯混合分布的 EM 算法就确定了:在每步迭代中,先根据当前参数和式 ( 43 ) (43) (43) 来计算每个样本属于每个高斯成分的后验概率 γ j i \gamma_{ji} γji ( E \rm E E 步),再根据式 ( 47 ) (47) (47)、 ( 48 ) (48) (48) 和 ( 51 ) (51) (51) 更新模型参数 { ( α i , μ i , Σ i ) ∣ 1 ≤ i ≤ k } \{(\alpha_i,\pmb \mu_i,\pmb \Sigma_i)\mid 1\le i\le k\} {(αi,μμi,ΣΣi)∣1≤i≤k} ( M \rm M M 步)。
高斯混合聚类算法描述如算法 3 3 3 所示。算法第 1 1 1 行对高斯混合分布的模型参数进行初始化。然后,在第 2 ∼ 12 2\sim12 2∼12 行基于 EM 算法对模型参数进行迭代更新。若 EM 算法的停止条件满足(例如已达到最大迭代轮数,或似然函数 L L ( D ) LL(D) LL(D) 增长很少甚至不再增长),则在第 14 ∼ 17 14\sim17 14∼17 行根据高斯混合分布确定簇划分,在第 18 18 18 行返回最终结果。
输入: 样本集 D = { x 1 , x 2 , , ⋅ ⋅ ⋅ , x m } ; 高斯混合成分个数 k ; 过程: \begin{array}{ll} \textbf{输入:}&\space样本集\space D = \{\pmb x_1,\pmb x_2,,···,\pmb x_m\}\space ;&&&&&&&&&&&&&&&&\\ &\space 高斯混合成分个数 \space k\space ;\\ \textbf{过程:} \end{array} 输入:过程: 样本集 D={xx1,xx2,,⋅⋅⋅,xxm} ; 高斯混合成分个数 k ;
1 : 初始化高斯混合分布的模型参数 { ( α i , μ i , Σ i ) ∣ 1 ≤ i ≤ k } 2 : repeat 3 : for j = 1 , 2 , ⋅ ⋅ ⋅ , m do 4 : 根据式 ( 43 ) 计算 x j 由各混合成分生成的后验概率,即 γ j i = p M ( z j = i ∣ x j ) ( 1 ≤ i ≤ k ) 5 : end for 6 : for i = 1 , 2 , ⋅ ⋅ ⋅ , k do 7 : 计算新均值向量 : μ i ′ = ∑ j = 1 m γ j i x j ∑ j = 1 m γ j i ; 8 : 计算新协方差矩阵 : Σ i ′ = ∑ j = 1 m γ j i ( x j − μ i ) ( x j − μ i ) T ∑ j = 1 m γ j i ; 9 : 计算新混合系数 : α i ′ = ∑ j = 1 m γ j i m ; 10 : end for 11 : 将模型参数 { ( α i , μ i , Σ i ) ∣ 1 ≤ i ≤ k } 更新为 { ( α i ′ , μ i ′ , Σ i ′ ) ∣ 1 ≤ i ≤ k } 12 : until 满足停止条件 13 : C i = ∅ ( 1 ≤ i ≤ k ) 14 : for j = 1 , 2 , ⋅ ⋅ ⋅ , m do 15 : 根据式 ( 44 ) 确定 x j 的簇标记入 λ j ; 16 : 将 x j 划入相应的簇 : C λ j = C λ j ⋃ { x j } 17 : end for \begin{array}{rl} 1:&初始化高斯混合分布的模型参数\space \{(\alpha_i,\pmb \mu_i,\pmb \Sigma_i)\mid 1\le i\le k\}\\ % 2:&\textbf{repeat}\\ % 3:&\space\space\space\space \textbf{for}\space j=1,2,···,m\space \textbf{do} \\ % 4:&\space\space\space\space\space\space\space\space 根据式 \space (43)\space 计算\space\pmb x_j\space由各混合成分生成的后验概率,即\\ % &\space\space\space\space\space\space\space\space\gamma_{ji}=p_{\mathcal M}(z_j=i\mid \pmb x_j)\space(1\le i\le k) \\ % 5:&\space\space\space\space \textbf{end}\space \textbf {for}\\ % 6:&\space\space\space\space \textbf{for}\space i=1,2,···,k\space \textbf{do} \\ % 7:&\space\space \space\space\space\space\space\space 计算新均值向量:\pmb \mu_i'=\frac{\sum _{j=1}^m\gamma_{ji}\pmb x_j}{\sum_{j=1}^m\gamma_{ji}}\space;\\ % 8:&\space\space \space\space\space\space\space\space 计算新协方差矩阵:\pmb \Sigma_i'=\frac{\sum _{j=1}^m\gamma_{ji} (\pmb x_j-\pmb \mu_i)(\pmb x_j-\pmb \mu_i)^T}{\sum_{j=1}^m\gamma_{ji}}\space;\\ % 9:&\space\space\space\space\space\space\space\space 计算新混合系数:\alpha_i'=\frac{\sum_{j=1}^m\gamma_{ji}}{m}\space;\\ % 10:&\space\space \space\space \textbf{end}\space \textbf{for}\\ % 11:&\space\space\space\space将模型参数\space\{(\alpha_i,\pmb \mu_i,\pmb \Sigma_i)\mid 1\le i\le k\}\space 更新为 \space\{(\alpha_i',\pmb \mu_i',\pmb \Sigma_i')\mid 1\le i\le k\} \\ % 12:& \textbf{until}\space 满足停止条件\\ % 13:& C_i=\varnothing \space (1\le i \le k) \\ % 14:& \textbf{for}\space j=1,2,···,m\space \textbf{do} \\ % 15:&\space\space\space\space根据式\space (44)\space确定\space\pmb x_j\space 的簇标记入\space \lambda_j\space ;\\ % 16:&\space\space\space\space将\space \pmb x_j\space 划入相应的簇:C_{\lambda_j}=C_{\lambda_j}\bigcup\space\{\pmb x_j\}\\ % 17:& \textbf{end}\space \textbf{for}\\ \end{array} 1:2:3:4:5:6:7:8:9:10:11:12:13:14:15:16:17:初始化高斯混合分布的模型参数 {(αi,μμi,ΣΣi)∣1≤i≤k}repeat for j=1,2,⋅⋅⋅,m do 根据式 (43) 计算 xxj 由各混合成分生成的后验概率,即 γji=pM(zj=i∣xxj) (1≤i≤k) end for for i=1,2,⋅⋅⋅,k do 计算新均值向量:μμi′=∑j=1mγji∑j=1mγjixxj ; 计算新协方差矩阵:ΣΣi′=∑j=1mγji∑j=1mγji(xxj−μμi)(xxj−μμi)T ; 计算新混合系数:αi′=m∑j=1mγji ; end for 将模型参数 {(αi,μμi,ΣΣi)∣1≤i≤k} 更新为 {(αi′,μμi′,ΣΣi′)∣1≤i≤k}until 满足停止条件Ci=∅ (1≤i≤k)for j=1,2,⋅⋅⋅,m do 根据式 (44) 确定 xxj 的簇标记入 λj ; 将 xxj 划入相应的簇:Cλj=Cλj⋃ {xxj}end for
输出: 簇划分 C = { C 1 , C 2 , ⋅ ⋅ ⋅ , C k } \begin{array}{l} \textbf{输出:}\space 簇划分 \space \mathcal C=\{C_1,C_2,···,C_k\} &&&&&&&&&&&&&&&&&& \end{array} 输出: 簇划分 C={C1,C2,⋅⋅⋅,Ck}
算法 3 高斯混合聚类算法
以表 1 1 1 的西瓜数据集为例,令高斯混合成分的个数 k = 3 k=3 k=3 。算法开始时,假定将高斯混合分布的模型参数初始化为: α 1 = α 2 = α 3 = 1 3 \alpha_1= \alpha_2= \alpha_3 = \frac{1}{3} α1=α2=α3=31; μ 1 = x 6 , μ 2 = x 22 , μ 3 = x 27 \pmb \mu_1=\pmb x_6,\space \pmb \mu_2=\pmb x_{22},\space \pmb \mu_3=\pmb x_{27} μμ1=xx6, μμ2=xx22, μμ3=xx27; Σ 1 = Σ 2 = Σ 3 = ( 0.1 0.0 0.0 0.1 ) \pmb \Sigma_1=\pmb \Sigma_2=\pmb \Sigma_3=\left(\begin{matrix} 0.1 & 0.0 \\ 0.0 & 0.1 \end{matrix}\right) ΣΣ1=ΣΣ2=ΣΣ3=(0.10.00.00.1) 。
在第一轮迭代中,先计算样本由各混合成分生成的后验概率。以 x 1 \pmb x_1 xx1 为例,由式 ( 43 ) (43) (43) 算出后验概率 γ 11 = 0.219 , γ 12 = 0.404 , γ 13 = 0.377 \gamma_{11}= 0.219,\space \gamma_{12}= 0.404,\space \gamma_{13}=0.377 γ11=0.219, γ12=0.404, γ13=0.377 。所有样本的后验概率算完后,得到如下新的模型参数:
α 1 ′ = 0.361 , α 2 ′ = 0.323 , α 3 ′ = 0.316 μ 1 ′ = ( 0.491 ; 0.251 ) , μ 2 ′ = ( 0.571 ; 0.281 ) , μ 3 ′ = ( 0.534 ; 0.295 ) Σ 1 ′ = ( 0.025 0.004 0.004 0.016 ) , Σ 2 ′ = ( 0.023 0.004 0.004 0.017 ) , Σ 1 ′ = ( 0.024 0.005 0.005 0.016 ) \alpha_1'=0.361,\space \alpha_2'=0.323,\space \alpha_3'=0.316\\\\ \pmb \mu_1'= (0.491;0.251),\space \pmb \mu_2'= (0.571;0.281),\space \pmb \mu_3'= (0.534;0.295)\\\\ \pmb \Sigma_1'=\left(\begin{matrix} 0.025 & 0.004 \\ 0.004 & 0.016 \end{matrix}\right),\space \pmb \Sigma_2'=\left(\begin{matrix} 0.023 & 0.004 \\ 0.004 & 0.017 \end{matrix}\right),\space \pmb \Sigma_1'=\left(\begin{matrix} 0.024 & 0.005 \\ 0.005 & 0.016 \end{matrix}\right) α1′=0.361, α2′=0.323, α3′=0.316μμ1′=(0.491;0.251), μμ2′=(0.571;0.281), μμ3′=(0.534;0.295)ΣΣ1′=(0.0250.0040.0040.016), ΣΣ2′=(0.0230.0040.0040.017), ΣΣ1′=(0.0240.0050.0050.016)
模型参数更新后,不断重复上述过程,不同轮数之后的聚类结果如图 9 9 9 所示。

图 9 高斯混合聚类(k=3)在不同轮数迭代后的聚类结果。其中样本簇 C1,C2与C3中的样本点分别用“○”,“■”与“▲”表示,各高斯混合成分的均值向量用“+”表示。
4.6.6 生成模型
高斯混合模型是一种生成模型,所谓生成模型是指,通过数据集确定模型参数后,可以用于随机生成其他样本的模型。
假设样本的生成过程由高斯混合分布给出:首先,根据 α 1 , α 2 , ⋅ ⋅ ⋅ , α k \alpha_1, \alpha_2,··· , \alpha_k α1,α2,⋅⋅⋅,αk 定义的先验分布选择高斯混合成分,其中 α i \alpha_i αi 为选择第 i i i 个混合成分的概率;然后,根据被选择的混合成分的概率密度函数进行采样,从而生成相应的样本。
4.6.7 混合系数的意义
先重复一遍上面提到的前两点。
第一点是凑概率密度函数,保证积分值为 1 1 1,更贴近概率模型。
第二点是用权重表示先验概率,即 α i \alpha_i αi 表示属于(任何)样本属于第 i i i 个簇的概率,或者说满足第 i i i 个混合成分分布的概率,如此便可以将高斯混合分布 p M ( x , μ , Σ ) p_{\mathcal M}(\pmb x,\pmb \mu, \pmb \Sigma) pM(xx,μμ,ΣΣ) (更详细准确的模型表达形式,其中 μ = ( μ 1 , μ 2 , ⋅ ⋅ ⋅ , μ k ) \pmb \mu=(\pmb \mu_1,\pmb \mu_2,···,\pmb \mu_k) μμ=(μμ1,μμ2,⋅⋅⋅,μμk) , Σ \pmb \Sigma ΣΣ 同理)理解为全概率,即将对样本 x \pmb x xx 在参数为 ( μ , Σ ) (\pmb\mu,\pmb \Sigma) (μμ,ΣΣ) 的模型中出现的概率求解问题转化为了在不同混合成分(参数为 ( μ i , Σ i ) (\pmb \mu_i, \pmb \Sigma_i) (μμi,ΣΣi) 的高斯分布)中样本 x \pmb x xx 出现概率求和的简单问题。这样可以认为是对高斯混合分布函数,即式 ( 42 ) (42) (42) 的另一种理解。
第三点是从生成模型的角度来看,当我们引入了先验概率后,生成样本的过程中会先依据先验概率随机选择一个混合成分,再根据混合成分的分布进行采样。如果不引入先验概率,相当于没有提出选择混合分类的方法,或者说选择任何一个混合分类的概率相同,可行但可解释性不如引入先验概率的模型。
第四点,首先明确,即使 ∑ i = 1 k α i ≠ 1 \sum_{i=1}^k\alpha_i\ne1 ∑i=1kαi=1,甚至不定义混合系数,即 α i = 1 \alpha_i=1 αi=1 ( 1 ≤ i ≤ k ) (1\le i \le k) (1≤i≤k) ,都是可行的。下面讨论混合系数全为 1 1 1 时的可行性。
当 α i = 1 \alpha_i=1 αi=1 ( 1 ≤ i ≤ k ) (1\le i \le k) (1≤i≤k) 时,高斯混合分布定义为
p M ( x ) = ∑ i = 1 k p ( x ∣ μ i , Σ i ) (52) p_{\mathcal M}(\pmb x)=\sum_{i=1}^k p(\pmb x\mid\pmb \mu_i,\pmb \Sigma_i)\tag{52} pM(xx)=i=1∑kp(xx∣μμi,ΣΣi)(52)
接下来将讨论 α i = 1 \alpha_i=1 αi=1 ( 1 ≤ i ≤ k ) (1\le i \le k) (1≤i≤k) 时的可行性。只要的 EM 算法可行,模型参数就可以更新,模型就是可行的。
-
E \rm E E 步
后验概率
p M ( z j = i ∣ x j ) = P ( z j = i ) ⋅ p ( x j ∣ μ i , Σ i ) ∑ l = 1 k p ( x j ∣ μ l , Σ l ) (53) p_\mathcal{M}(z_j=i\mid \pmb x_j) = \frac{P(z_j=i)\space ·\space p(\pmb x_j\mid \pmb \mu_i,\pmb \Sigma_i)}{\sum \limits_{l=1}^kp(\pmb x_j\mid \pmb \mu_l,\pmb \Sigma_l)}\tag{53} pM(zj=i∣xxj)=l=1∑kp(xxj∣μμl,ΣΣl)P(zj=i) ⋅ p(xxj∣μμi,ΣΣi)(53)
隐变量 t j i t_{ji} tji 为
t j i = p M ( z j = i ∣ x j ) P ( z j = i ) = p ( x j ∣ μ i , Σ i ) ∑ l = 1 k p ( x j ∣ μ l , Σ l ) (54) t_{ji}=\frac{p_\mathcal{M}(z_j=i\mid \pmb x_j)}{P(z_j=i)} = \frac{ p(\pmb x_j\mid \pmb \mu_i,\pmb \Sigma_i)}{\sum \limits_{l=1}^kp(\pmb x_j\mid \pmb \mu_l,\pmb \Sigma_l)}\tag{54} tji=P(zj=i)pM(zj=i∣xxj)=l=1∑kp(xxj∣μμl,ΣΣl)p(xxj∣μμi,ΣΣi)(54)
根据式 ( 54 ) (54) (54) 可以计算出隐变量。 -
M \rm M M 步
类似于式 ( 47 ) (47) (47) 和 ( 48 ) (48) (48) 的推导,可得
μ i = ∑ j = 1 m t j i x j m (55) \pmb \mu_i=\frac{\sum\limits_{j=1}^m t_{ji}\pmb x_j}{m}\tag{55} μμi=mj=1∑mtjixxj(55)Σ i = ∑ j = 1 m t j i ( x j − μ i ) ( x j − μ i ) T m (56) \pmb \Sigma_i=\frac{\sum \limits_{j=1}^m t_{ji}(\pmb x_j-\pmb \mu_i)(\pmb x_j-\pmb \mu_i)^T}{m}\tag{56} ΣΣi=mj=1∑mtji(xxj−μμi)(xxj−μμi)T(56)
由于没有混合系数,模型参数只有 { ( μ i , Σ i ) ∣ 1 ≤ i ≤ k } \{(\pmb \mu_i,\pmb \Sigma_i)\mid 1\le i\le k\} {(μμi,ΣΣi)∣1≤i≤k} ,因此不存在更新混合系数的步骤。
观察 EM 算法发现隐变量的计算和模型参数的更新过程都没有问题,说明即使不采用混合系数,高斯混合模型也是可行的。
但是如何对样本进行划分呢?由于我们不知道 P ( z j = i ) P(z_j=i) P(zj=i) ( i ≤ i ≤ k ) (i\le i\le k) (i≤i≤k) ,所以虽然能够计算出隐变量 t j i t_{ji} tji,但依然无法根据式 ( 54 ) (54) (54) 计算出后验概率 p M ( z j = i ∣ x j ) p_\mathcal{M}(z_j=i\mid \pmb x_j) pM(zj=i∣xxj),从而无法对样本进行划分。
以 λ j = a r g max i ∈ { 1 , 2 , ⋅ ⋅ ⋅ , k } t j i \lambda_j=\mathop{{\rm arg} \max}_{i∈\{1,2,···,k\}}\space t_{ji} λj=argmaxi∈{1,2,⋅⋅⋅,k} tji 作为划分规则是否可以?可以,但是可解释性差。后验概率能明确表达「在已知样本的情况下,样本属于某个分类的概率」,可是 t j i t_{ji} tji 的含义无法直观理解,也就没有说服性。如果我们想使用后验概率作为划分依据,那么就必须学习先验概率 P ( z j = i ) P(z_j=i) P(zj=i) ( i ≤ i ≤ k ) (i\le i\le k) (i≤i≤k) ,如此一来就又变回式 ( 42 ) (42) (42) 定义的高斯混合分布了。
以上这四点从可行性和可解释性两个方面对混合系数存在的意义进行说明。对于可解释性,完全可以从更多角度去理解。
4.6.8 与 k k k-means 对比
-
高斯混合模型假设数据点是由具有未知参数的高斯分布的混合生成的,目标是估计高斯分布的参数( μ \pmb \mu μμ 和 Σ \pmb \Sigma ΣΣ),以及来自每个分布的数据点的比例( α i \alpha_i αi);相比之下, k k k-means 聚类不对数据点的潜在分布做出任何假设,只是将数据点划分为 k k k 个集群,其中每个集群由其质心定义。
-
虽然高斯混合模型更灵活,但它们可能比 k k k-means 更难训练。 k k k-means 通常收敛速度更快,因此在运行时是一个重要考虑因素的情况下可能是首选。 一般来说,当数据集较大且聚类分离良好时, k k k-means 会更快、更准确。当数据集较小或聚类分离不充分时,高斯混合模型会更准确。
-
高斯混合模型在簇的形状方面更加灵活,而 k k k-means 仅限于球形簇。
-
高斯混合模型可以处理缺失数据,而 k k k-means 不能。这种差异可以使高斯混合模型在某些应用中更有效,例如具有大量噪声的数据或未明确定义的数据。
-
在 k k k-means方法中使用EM来训练高斯混合模型时对初始值的设置非常敏感。而对比 k k k-means,混合高斯模型有更多的初始条件要设置。实践中不仅初始类中心要指定,而且协方差矩阵和混合系数也要设置。可以运行 k k k-means来生成类中心,并以此作为高斯混合模型的初始条件。