mmdetection源码分析,以FCOS训练流程为例
目录
- 简介
- FCOS简介
- 训练
-
- train.py
- 训练流程
- build_model
-
- FCOS配置文件
- builder.py
- registry.py
- FCOS类
- SingleStageDetector
- 继承关系
- Registry
- build_dataset
-
- 数据集的cfg
- builder.py
- CocoDataset类
- 继承关系
- train_detector
-
- EpochBasedRunner
- BaseDetector中的train_step和val_step
- _call_impl
- 参考
-
- [轻松掌握 MMDetection 整体构建流程(一)](https://zhuanlan.zhihu.com/p/337375549)
- [轻松掌握 MMDetection 整体构建流程(二)](https://zhuanlan.zhihu.com/p/341954021)
- [MMCV 核心组件分析(一):整体概述](https://zhuanlan.zhihu.com/p/336081587)
- [MMCV 核心组件分析(二)](https://zhuanlan.zhihu.com/p/336097883)
- [MMCV 核心组件分析(三): FileClient](https://zhuanlan.zhihu.com/p/339190576)
- [MMCV 核心组件分析(四): Config](https://zhuanlan.zhihu.com/p/346203167)
- [轻松掌握 MMDetection 中常用算法(一):RetinaNet 及配置详解](https://zhuanlan.zhihu.com/p/346198300)
- [轻松掌握 MMDetection 中常用算法(二):Faster R-CNN|Mask R-CNN](https://zhuanlan.zhihu.com/p/349807581)
简介
mmdetection的源码分析——以FCOS为例
本文参考我“大师兄”的博客(八)深度学习实战 | MMDetection之FCOS(1)_Skies_的博客-CSDN博客,参照他的文章思路,本文将从mmdetection的配置文件,和训练文件入手梳理训练的整个流程。
本文以训练流程未主线,重点在于梳理mmdetection 的运作机制,为之后自己构造新的模型做准备。
FCOS简介
FCOS是一种one-stage的anchor free、proposal free的全卷积网络,该网络能够以像素级的水平做目标检测,同时也能应用到实例分割等其他instance level的视觉任务上,此外,FCOS也可单独作为Region Proposal Networks来为two-stage的检测器服务,由于其是anchor-free的,避免了anchor box的一系列复杂问题,如计算和尺度大小设置等,仅通过一个NMS后处理就能达到很好的性能,简单而性能强大。第一次实现了简单的全卷积检测器但是却有着比那些anchor-based 检测器更好的性能
有关FCOS的详情可以参考我的论文阅读笔记:论文阅读|FCOS_yanghao201607030101的博客-CSDN博客
其网络架构如下:
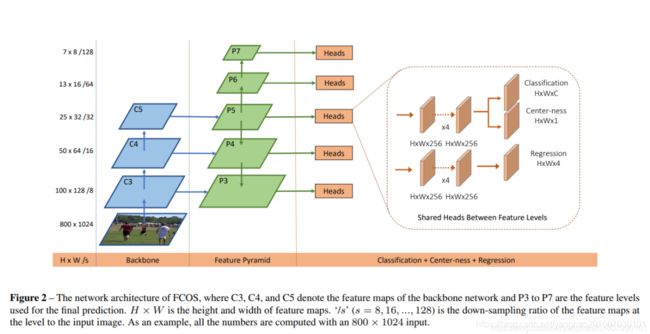
网络由三部分组成,骨干网,特征金字塔和头部网络。
训练
train.py
mmdetection训练时直接使用tools文件夹下的train.py即可,使用命令行的方式加上各种参数即可开始训练,train.py的代码。训练时,会以检测器的配置文件名在work_dirs下创建文件夹,然后存放当前模型的配置以及日志,当然也可以指定将输出存放在此。
python tools/train.py \
${CONFIG_FILE} \
[optional arguments]
其中可选参数包括:
--no-validate(not suggested): Disable evaluation during training.--work-dir ${WORK_DIR}: Override the working directory.--resume-from ${CHECKPOINT_FILE}: Resume from a previous checkpoint file.--options 'Key=value': Overrides other settings in the used config.
训练流程
#构建detector
model = build_detector(
cfg.model, train_cfg=cfg.train_cfg, test_cfg=cfg.test_cfg)
#构建训练数据集,如果工作流中有验证则数据集中会append验证集
datasets = [build_dataset(cfg.data.train)]
#通过train_detector函数开启训练
train_detector(
model,
datasets,
cfg,
distributed=distributed,
validate=(not args.no_validate),
timestamp=timestamp,
meta=meta)
其中,重点是build_detector,build_dataset,train_detector,三部分。build_detector,build_dataset是通过各自的build函数mmdet/datasets/builder.py和 实现的,train_detector则是通过mmdet/apis/train.py实现的。
build_model
FCOS配置文件
mmdetction中的配置文件都位于config文件夹下,检测器的配置文件一般由四个部分组成,模型的配置文件,学习率相关配置文件,数据集配置文件,以及运行时配置文件。编写一个检测器模型完整的配置文件时,可以选择从基本的数据集、学习率和运行时配置文件中继承配置,对于修改的部分可以在该文件中编写以覆盖继承的配置,此外还有编写模型的配置(一般一个文件夹内只有一个跟配置文件,其它配置文件继承自它)。
以下是FCOS的一个基础配置文件,如果需要修改,可以基础自它,然后覆盖部分配置。
_base_ = [
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# model settings
model = dict(
type='FCOS',
pretrained='open-mmlab://detectron/resnet50_caffe',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='caffe'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs=True,
extra_convs_on_inputs=False, # use P5
num_outs=5,
relu_before_extra_convs=True),
bbox_head=dict(
type='FCOSHead',
num_classes=80,
in_channels=256,
stacked_convs=4,
feat_channels=256,
strides=[8, 16, 32, 64, 128],
norm_cfg=None,
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='IoULoss', loss_weight=1.0),
loss_centerness=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)))
# training and testing settings
train_cfg = dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.4,
min_pos_iou=0,
ignore_iof_thr=-1),
allowed_border=-1,
pos_weight=-1,
debug=False)
test_cfg = dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100)
img_norm_cfg = dict(
mean=[102.9801, 115.9465, 122.7717], std=[1.0, 1.0, 1.0], to_rgb=False)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=4,
workers_per_gpu=4,
train=dict(pipeline=train_pipeline),
val=dict(pipeline=test_pipeline),
test=dict(pipeline=test_pipeline))
# optimizer
optimizer = dict(
lr=0.01, paramwise_cfg=dict(bias_lr_mult=2., bias_decay_mult=0.))
optimizer_config = dict(
_delete_=True, grad_clip=dict(max_norm=35, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
warmup='constant',
warmup_iters=500,
warmup_ratio=1.0 / 3,
step=[8, 11])
total_epochs = 12
builder.py
下面以详细分析模型的构造。build_detector通过调用mmdet/models/builder.py实现,该builder内部如下:
#首先创建每个部分的Registry对象
BACKBONES = Registry('backbone')
NECKS = Registry('neck')
ROI_EXTRACTORS = Registry('roi_extractor')
SHARED_HEADS = Registry('shared_head')
HEADS = Registry('head')
LOSSES = Registry('loss')
DETECTORS = Registry('detector')
#其它部分也是这样调用build创建
def build_detector(cfg, train_cfg=None, test_cfg=None):
"""Build detector."""
return build(cfg, DETECTORS, dict(train_cfg=train_cfg, test_cfg=test_cfg))
#内部有个创建方法,根据配置文件创建各个部分
def build(cfg, registry, default_args=None):
"""Build a module.
Args:
cfg (dict, list[dict]): The config of modules, is is either a dict
or a list of configs.
registry (:obj:`Registry`): A registry the module belongs to.
default_args (dict, optional): Default arguments to build the module.
Defaults to None.
Returns:
nn.Module: A built nn module.
"""
if isinstance(cfg, list):
modules = [
build_from_cfg(cfg_, registry, default_args) for cfg_ in cfg
]
return nn.Sequential(*modules)
else:
return build_from_cfg(cfg, registry, default_args)
registry.py
build_from_cfg构造模型的每个模块,而build_from_cfg则来自…/Anaconda3/envs/mmd2/Lib/site-packages/mmcv/utils/registry.py,根据配置文件中的type返回一个注册为检测器的模块中的名为该type的检测器对象。
def build_from_cfg(cfg, registry, default_args=None):
"""Build a module from config dict.
Args:
cfg (dict): Config dict. It should at least contain the key "type".
registry (:obj:`Registry`): The registry to search the type from.
default_args (dict, optional): Default initialization arguments.
Returns:
object: The constructed object.
"""
if not isinstance(cfg, dict):
raise TypeError(f'cfg must be a dict, but got {type(cfg)}')
if 'type' not in cfg:
if default_args is None or 'type' not in default_args:
raise KeyError(
'`cfg` or `default_args` must contain the key "type", '
f'but got {cfg}\n{default_args}')
if not isinstance(registry, Registry):
raise TypeError('registry must be an mmcv.Registry object, '
f'but got {type(registry)}')
if not (isinstance(default_args, dict) or default_args is None):
raise TypeError('default_args must be a dict or None, '
f'but got {type(default_args)}')
args = cfg.copy()
if default_args is not None:
for name, value in default_args.items():
args.setdefault(name, value)
#找到type的值,即该module 的类型
obj_type = args.pop('type')
if is_str(obj_type):
obj_cls = registry.get(obj_type)
if obj_cls is None:
raise KeyError(
f'{obj_type} is not in the {registry.name} registry')
elif inspect.isclass(obj_type):
obj_cls = obj_type
else:
raise TypeError(
f'type must be a str or valid type, but got {type(obj_type)}')
# 根据module类名调用相应的构造函数构造模块
return obj_cls(**args)
上面的obj_type = args.pop(‘type’)会到mmdet/models/detectors下去寻找注册为args.pop(‘type’) 的检测器。例如FCOS的配置文件cfg中的type为
_base_ = [
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
# model settings
model = dict(
type='FCOS',
pretrained='open-mmlab://detectron/resnet50_caffe',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='caffe'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
.....
以下省略
FCOS类
所以要找注册为DETECTORS,且名字叫“FCOS”的检测器,也就是mmdet/models/detectors/fcos.py中的FCOS类,然后会通过这个类的构造函数实例化我们的检测器,而其具体实例化的细节需要分析它的父类SingleStageDetector。
#注册为DETECTORS中的成员
@DETECTORS.register_module()
class FCOS(SingleStageDetector):
"""Implementation of `FCOS `_"""
def __init__(self,
backbone,
neck,
bbox_head,
train_cfg=None,
test_cfg=None,
pretrained=None):
super(FCOS, self).__init__(backbone, neck, bbox_head, train_cfg,
test_cfg, pretrained)
SingleStageDetector
上面说到了FCOS类继承自mmdet/models/detectors/single_stage.py中的SingleStageDetector
@DETECTORS.register_module()
class SingleStageDetector(BaseDetector):
"""Base class for single-stage detectors.
Single-stage detectors directly and densely predict bounding boxes on the
output features of the backbone+neck.
"""
def __init__(self,
backbone,
neck=None,
bbox_head=None,
train_cfg=None,
test_cfg=None,
pretrained=None):
super(SingleStageDetector, self).__init__()
#调用mmdet/models/builder.py中的build_backbone构造骨干网
self.backbone = build_backbone(backbone)
if neck is not None:
#调用mmdet/models/builder.py中的build_neck构造neck
self.neck = build_neck(neck)
bbox_head.update(train_cfg=train_cfg)
bbox_head.update(test_cfg=test_cfg)
#调用mmdet/models/builder.py中的build_head构造head
self.bbox_head = build_head(bbox_head)
self.train_cfg = train_cfg
self.test_cfg = test_cfg
#初始化权重
self.init_weights(pretrained=pretrained)
以上就是,整个model的构造过程。
观察到SingleStageDetector又继承自mmdet/models/detectors/base.py中的BaseDetector,BaseDetector的hierarchy结构发现它是所有检测器的基类,下面分为two-stage和one-stage的检测器,层次结构见下图:
继承关系

最终,我们的模型通过其继承自SingleStageDetector的构造方法实例化,也就是在构造函数中调用model的build_backbone等函数构造各个部分,就如build-detector函数一样,会调用build函数,然后再调用registry中的build_from_cfg函数完成。FCOS的配置文件中中model里面有哪些组成部分,那么这里构造的时候就会对应的到mmdet/models/下的各个部分找对应的类构造相应实例。
Registry
注意,上面的DETECTORS这些实际上就是通过Registry类注册了一个字典,即一个类别和类名的字典,将字典的管理简化了,当需要新添加一个模块时,我们仅需维护注册代码的路径而不需要手动修改字典。这部分改自开头提到的“大师兄”的博客。
这里分析下Registry类,它的核心如下:
class Registry:
def __init__(self, name):
self._name = name
# self._module_dict用于存放表示模块名称的字符串到模块类的映射
self._module_dict = dict()
@property
def name(self):
return self._name
@property
def module_dict(self):
return self._module_dict
def get(self, key):
# 根据字符串取相应的类
return self._module_dict.get(key, None)
def _register_module(self, module_class, module_name=None, force=False):
# 判断是否为类
if not inspect.isclass(module_class):
raise TypeError('module must be a class, '
f'but got {type(module_class)}')
# 开始注册模块
if module_name is None:
module_name = module_class.__name__
if not force and module_name in self._module_dict:
raise KeyError(f'{module_name} is already registered '
f'in {self.name}')
# 将该模块信息加入字典内完成注册
self._module_dict[module_name] = module_class
def register_module(self, name=None, force=False, module=None):
if not isinstance(force, bool):
raise TypeError(f'force must be a boolean, but got {type(force)}')
if isinstance(name, type):
return self.deprecated_register_module(name, force=force)
# 注册模块,形式为x.register_module(module=SomeClass)
if module is not None:
self._register_module(
module_class=module, module_name=name, force=force)
return module
# 模块名必须为字符串
if not (name is None or isinstance(name, str)):
raise TypeError(f'name must be a str, but got {type(name)}')
# 注册模块,形式为使用Python的装饰器,@x.register_module()
def _register(cls):
self._register_module(
module_class=cls, module_name=name, force=force)
return cls
return _register
下面是注册模块的两种形式:一种是函数式,一种是语法糖的方式(利用了python中的装饰器)
# 函数调用
backbones = Registry("backbone")
class MyBackbone:
pass
backbones.register_module(MyBackbone)
# 语法糖
backbones = Register("backbone")
@backbones.register_module()
class MyBackbone:
pass
然后如果想要自己创造某种结构,也可以像下面这样,model/build.py中新增NEWPART = Register(“newpart”),然后新增对应的config部分,mmdet/models下面也新增对应的类MyBackbone,
# 新加自创的模块
NEWPART = Register("newpart")
@NEWPART.register_module()
class MyBackbone:
pass
mmdetection中的框架中的模块除直接来自nn.module模块的,其它大多是这种模式生成的,即Registry的字典中注册类,然后通过和Registry类在一个文件夹内的build_from_cfg函数构造实例。所以build_from_cfg函数挺重要的。
build_dataset
前面提到了训练时数据集的构建传入的是配置文件中的训练数据集部分,如果工作流包括验证集,则会把验证集也加入数据集。
数据集的cfg
datasets = [build_dataset(cfg.data.train)] ,FCOS的数据集部分配置继承自coco_detection,其训练数据部分如下:
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='bbox')
builder.py
和模型的构造类似,数据集的构造build_dataset也是调用一个build函数实现的,该build函数位于mmdet/datasets/builder.py,完成数据集相关的构建工作,该文件内的主要内容如下:
#注册字典
DATASETS = Registry('dataset')
PIPELINES = Registry('pipeline')
#构造数据集
def build_dataset(cfg, default_args=None):
from .dataset_wrappers import (ConcatDataset, RepeatDataset,
ClassBalancedDataset)
if isinstance(cfg, (list, tuple)):
dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg])
elif cfg['type'] == 'ConcatDataset':
dataset = ConcatDataset(
[build_dataset(c, default_args) for c in cfg['datasets']],
cfg.get('separate_eval', True))
elif cfg['type'] == 'RepeatDataset':
dataset = RepeatDataset(
build_dataset(cfg['dataset'], default_args), cfg['times'])
elif cfg['type'] == 'ClassBalancedDataset':
dataset = ClassBalancedDataset(
build_dataset(cfg['dataset'], default_args), cfg['oversample_thr'])
elif isinstance(cfg.get('ann_file'), (list, tuple)):
dataset = _concat_dataset(cfg, default_args)
else:
#和模型的构造一样,最终调用build_from_cfg构造出类别为DATASETS,名称为args.pop('type')的数据集实例
dataset = build_from_cfg(cfg, DATASETS, default_args)
return dataset
#构造dataloder
def build_dataloader(dataset,
samples_per_gpu,
workers_per_gpu,
num_gpus=1,
dist=True,
shuffle=True,
seed=None,
**kwargs):
"""Build PyTorch DataLoader.
In distributed training, each GPU/process has a dataloader.
In non-distributed training, there is only one dataloader for all GPUs.
Args:
dataset (Dataset): A PyTorch dataset.
samples_per_gpu (int): Number of training samples on each GPU, i.e.,
batch size of each GPU.
workers_per_gpu (int): How many subprocesses to use for data loading
for each GPU.
num_gpus (int): Number of GPUs. Only used in non-distributed training.
dist (bool): Distributed training/test or not. Default: True.
shuffle (bool): Whether to shuffle the data at every epoch.
Default: True.
kwargs: any keyword argument to be used to initialize DataLoader
Returns:
DataLoader: A PyTorch dataloader.
"""
rank, world_size = get_dist_info()
if dist:
# DistributedGroupSampler will definitely shuffle the data to satisfy
# that images on each GPU are in the same group
if shuffle:
sampler = DistributedGroupSampler(dataset, samples_per_gpu,
world_size, rank)
else:
sampler = DistributedSampler(
dataset, world_size, rank, shuffle=False)
batch_size = samples_per_gpu
num_workers = workers_per_gpu
else:
sampler = GroupSampler(dataset, samples_per_gpu) if shuffle else None
batch_size = num_gpus * samples_per_gpu
num_workers = num_gpus * workers_per_gpu
init_fn = partial(
worker_init_fn, num_workers=num_workers, rank=rank,
seed=seed) if seed is not None else None
data_loader = DataLoader(
dataset,
batch_size=batch_size,
sampler=sampler,
num_workers=num_workers,
collate_fn=partial(collate, samples_per_gpu=samples_per_gpu),
pin_memory=False,
worker_init_fn=init_fn,
**kwargs)
return data_loader
可见其内容和模型的builder.py文件很相似,数据集和流程都在这里组测了字典类别,之后数据集就可以加入这些类别。对于COCO主要的数据集,最后还是会和模型的构造一样通过build_from_cfg构造出其实例,对应的实例类位于mmdet/datasets/coco.py。
CocoDataset类
@DATASETS.register_module()
class CocoDataset(CustomDataset):
CLASSES = ('person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog',
'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe',
'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat',
'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot',
'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop',
'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock',
'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush')
def load_annotations(self, ann_file):
"""Load annotation from COCO style annotation file.
Args:
ann_file (str): Path of annotation file.
Returns:
list[dict]: Annotation info from COCO api.
"""
。。。略
继承关系
这里发现CocoDataset继承自CustomDataset然后对load_annotations等方法做了重写,CustomDataset继承自torch.utils.data.Dataset并实现“len”和“getitem”方法,数据集整体的hierarchy结构如下:
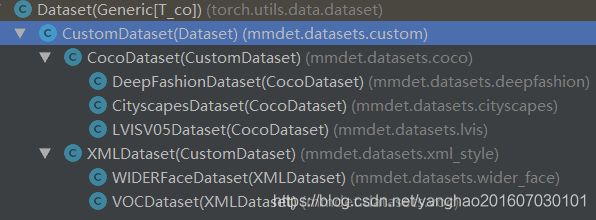
可见VOCDataset大致也是这样的构造。
以上是训练流程中三个关键部分的前两个,即数据集的构造和检测器的构造,接下来就是第三部分训练部分。
train_detector
train_detector(
model,
datasets,
cfg,
distributed=distributed,
validate=(not args.no_validate),
timestamp=timestamp,
meta=meta)
train_detector来自mmdet/apis/train.py,其内部主要内容如下:
def train_detector(model,
dataset,
cfg,
distributed=False,
validate=False,
timestamp=None,
meta=None):
# prepare data loaders
data_loaders = [
build_dataloader(
ds,
cfg.data.samples_per_gpu,
cfg.data.workers_per_gpu,
# cfg.gpus will be ignored if distributed
len(cfg.gpu_ids),
dist=distributed,
seed=cfg.seed) for ds in dataset
]
# put model on gpus
。。。
# build runner
optimizer = build_optimizer(model, cfg.optimizer)
runner = EpochBasedRunner(
model,
optimizer=optimizer,
work_dir=cfg.work_dir,
logger=logger,
meta=meta)
# an ugly workaround to make .log and .log.json filenames the same
runner.timestamp = timestamp
中间省略了一些设置
#
if cfg.resume_from:
runner.resume(cfg.resume_from)
elif cfg.load_from:
runner.load_checkpoint(cfg.load_from)
runner.run(data_loaders, cfg.workflow, cfg.total_epochs)
可以看见这里实际是通过EpochBasedRunner的一个实例runner实现的训练,最后调用 runner.run(data_loaders, cfg.workflow, cfg.total_epochs)来训练的,EpochBasedRunner继承自BaseRunner,其构造方法直接沿用的BaseRunner。
下面是EpochBasedRunner的代码,首先进入run方法,打印一些日志信息后,执行cfg.total_epochs(max_epochs)次下列步骤:
判断每个epoch的workflow的mode是"train"还是"val",然后通过epoch_runner = getattr(self, mode)给epoch_runner赋值函数train()或val()。
train或val的函数中加载dataloader,将每个iteration的数据送入run_iter()中运行;
run_iter则通过检测器模型的train_step或val_step。
train_step或val_step中会通过losses = self(**data),等价于启动了__call__,__call__又会启动_call_impl,最终在_call_impl中将一个batch的data传入模型的forward中,得到结果。
下面会分别展示上述步骤的代码:
EpochBasedRunner
class EpochBasedRunner(BaseRunner):
"""Epoch-based Runner.
This runner train models epoch by epoch.
"""
# 封装了每个iter的具体运行
def run_iter(self, data_batch, train_mode, **kwargs):
if self.batch_processor is not None:
outputs = self.batch_processor(
self.model, data_batch, train_mode=train_mode, **kwargs)
elif train_mode:
outputs = self.model.train_step(data_batch, self.optimizer,
**kwargs)
else:
outputs = self.model.val_step(data_batch, self.optimizer, **kwargs)
if not isinstance(outputs, dict):
raise TypeError('"batch_processor()" or "model.train_step()"'
'and "model.val_step()" must return a dict')
if 'log_vars' in outputs:
self.log_buffer.update(outputs['log_vars'], outputs['num_samples'])
self.outputs = outputs
# 执行一个epoch的训练
def train(self, data_loader, **kwargs):
self.model.train()
self.mode = 'train'
self.data_loader = data_loader
self._max_iters = self._max_epochs * len(self.data_loader)
self.call_hook('before_train_epoch')
time.sleep(2) # Prevent possible deadlock during epoch transition
for i, data_batch in enumerate(self.data_loader):
self._inner_iter = i
self.call_hook('before_train_iter')
self.run_iter(data_batch, train_mode=True)
self.call_hook('after_train_iter')
self._iter += 1
self.call_hook('after_train_epoch')
self._epoch += 1
# 执行一个epoch的验证操作
def val(self, data_loader, **kwargs):
self.model.eval()
self.mode = 'val'
self.data_loader = data_loader
self.call_hook('before_val_epoch')
time.sleep(2) # Prevent possible deadlock during epoch transition
for i, data_batch in enumerate(self.data_loader):
self._inner_iter = i
self.call_hook('before_val_iter')
with torch.no_grad():
self.run_iter(data_batch, train_mode=False)
self.call_hook('after_val_iter')
self.call_hook('after_val_epoch')
def run(self, data_loaders, workflow, max_epochs=None, **kwargs):
"""Start running.
Args:
data_loaders (list[:obj:`DataLoader`]): Dataloaders for training
and validation.
workflow (list[tuple]): A list of (phase, epochs) to specify the
running order and epochs. E.g, [('train', 2), ('val', 1)] means
running 2 epochs for training and 1 epoch for validation,
iteratively.
"""
assert isinstance(data_loaders, list)
assert mmcv.is_list_of(workflow, tuple)
assert len(data_loaders) == len(workflow)
if max_epochs is not None:
warnings.warn(
'setting max_epochs in run is deprecated, '
'please set max_epochs in runner_config', DeprecationWarning)
self._max_epochs = max_epochs
assert self._max_epochs is not None, (
'max_epochs must be specified during instantiation')
for i, flow in enumerate(workflow):
mode, epochs = flow
if mode == 'train':
self._max_iters = self._max_epochs * len(data_loaders[i])
break
work_dir = self.work_dir if self.work_dir is not None else 'NONE'
self.logger.info('Start running, host: %s, work_dir: %s',
get_host_info(), work_dir)
self.logger.info('workflow: %s, max: %d epochs', workflow,
self._max_epochs)
self.call_hook('before_run')
while self.epoch < self._max_epochs:
for i, flow in enumerate(workflow):
#mode 是train 或val
mode, epochs = flow
if isinstance(mode, str): # self.train()
if not hasattr(self, mode):
raise ValueError(
f'runner has no method named "{mode}" to run an '
'epoch')
#如果是"train",则epoch_runner=train,如果是"val"则为val
epoch_runner = getattr(self, mode)
else:
raise TypeError(
'mode in workflow must be a str, but got {}'.format(
type(mode)))
for _ in range(epochs):
if mode == 'train' and self.epoch >= self._max_epochs:
break
epoch_runner(data_loaders[i], **kwargs)
time.sleep(1) # wait for some hooks like loggers to finish
self.call_hook('after_run')
然后iter会按照每个iter的执行模式调用模型对应的方法:model.train_step()或者model.val_step(),这两个方法是所有检测器模型的最顶层基类BaseDetector中定义的。
BaseDetector中的train_step和val_step
def train_step(self, data, optimizer):
"""The iteration step during training.
This method defines an iteration step during training, except for the
back propagation and optimizer updating, which are done in an optimizer
hook. Note that in some complicated cases or models, the whole process
including back propagation and optimizer updating is also defined in
this method, such as GAN.
Args:
data (dict): The output of dataloader.
optimizer (:obj:`torch.optim.Optimizer` | dict): The optimizer of
runner is passed to ``train_step()``. This argument is unused
and reserved.
Returns:
dict: It should contain at least 3 keys: ``loss``, ``log_vars``, \
``num_samples``.
- ``loss`` is a tensor for back propagation, which can be a \
weighted sum of multiple losses.
- ``log_vars`` contains all the variables to be sent to the
logger.
- ``num_samples`` indicates the batch size (when the model is \
DDP, it means the batch size on each GPU), which is used for \
averaging the logs.
"""
losses = self(**data)
loss, log_vars = self._parse_losses(losses)
outputs = dict(
loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
return outputs
def val_step(self, data, optimizer):
"""The iteration step during validation.
This method shares the same signature as :func:`train_step`, but used
during val epochs. Note that the evaluation after training epochs is
not implemented with this method, but an evaluation hook.
"""
losses = self(**data)
loss, log_vars = self._parse_losses(losses)
outputs = dict(
loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
return outputs
_call_impl
def _call_impl(self, *input, **kwargs):
省略部分。。。
#这里将数据传入了forward中
if torch._C._get_tracing_state():
result = self._slow_forward(*input, **kwargs)
else:
result = self.forward(*input, **kwargs)
for hook in itertools.chain(
_global_forward_hooks.values(),
self._forward_hooks.values()):
hook_result = hook(self, input, result)
if hook_result is not None:
result = hook_result
省略。。。
return result
到此就把训练的流程基本梳理了一遍,通过以上分析,我已经对mmdetection的运作比较清晰了,test部分按照这个思路应该也能顺利理解。
参考
写完这篇文章后我再知乎上找到了OpenMMLab官方写的一个mmdetection介绍,发现很通俗易懂,这里贴上链接。