用自己的数据集跑CenterNet
文章目录
- 一、准备数据集
- 二、搭建pytorch0.4.1与cuda8环境
- 三、运行demo
- 四、训练模型
- 五、测试模型
参考:
https://blog.csdn.net/weixin_41765699/article/details/100118353
https://blog.csdn.net/weixin_42634342/article/details/97756458
一、准备数据集
将自己的数据集转成COCO格式:https://blog.csdn.net/weixin_41765699/article/details/100124689
修改相应文件:https://blog.csdn.net/weixin_41765699/article/details/100118353
二、搭建pytorch0.4.1与cuda8环境
由于学校服务器只能提供cuda8与cuda9,即使项目环境要求cuda9,为了保证服务器与pytorch的cuda一致,我还是用了cuda8,幸运的能跑通。
在anaconda中创建一个CenterNet环境,并激活。
conda create --name CenterNet python=3.6
conda activate CenterNet
删除环境,反正我删除了很多次环境,记上总没错。
conda env remove -n CenterNet
安装pytorch
conda install pytorch=0.4.1 cuda80 -c pytorch
更新pip,进入相关目录下载所需依赖
pip install --upgrade pip
cd myproject/CenterNet
pip install -r requirements.txt
编译环境
cd $CenterNet_ROOT/src/lib/models/networks/DCNv2
./make.sh
当前目录下,测试编译的环境
python test.py
配置好环境后,继续make,迎接我的却是下一个错误:“cffi.error.VerificationError:LinkError:command ‘gcc’ failed with exit status 1”
由于自己的服务器只提供cuda8或者cuda9,我的所以我编辑了.bashrc文件而不是make.sh文件,加入了:
export CUDA_PATH=/usr/local/cuda/
export CXXFLAGS="-std=c++11"
export CFLAGS="-std=c99"
export PATH=/usr/local/cuda-8.0/bin${PATH:+:${PATH}}
export CPATH=/usr/local/cuda-8.0/include${CPATH:+:${CPATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
修改完linux的配置文件后,即修改完 vi ~/.bashrc并保存退出后,需要source ~/.bashrc使修改生效。
cd myproject/CenterNet/src/lib/external
make
三、运行demo
下载权重:
链接:https://pan.baidu.com/s/1I1oW_l2Xe2-LV1gIjViPTg
提取码:2pt0
放在:
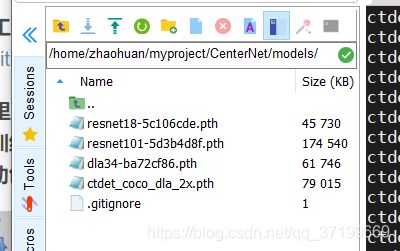
运行demo.py
cd myproject/CenterNet/src
python demo.py ctdet --demo /home/zhaohuan/myproject/CenterNet/images/ --load_model /home/zhaohuan/myproject/CenterNet/models/ctdet_coco_dla_2x.pth
要注意的是,当弹出第一站图片的时候,按esc除外的任意键可以继续检测下一张图,想要保存检测结果的话,只需要在src/lib/detectors/cdet.py文件中:
def show_results(self, debugger, image, results): # demo文件會調用這個函數,本函`python main.py ctdet --exp_id coco_dla --batch_size 32 --master_batch 1 --lr 1.25e-4 --gpus 0,1`數是demo時顯示圖片並保存圖片
debugger.add_img(image, img_id='ctdet')
for j in range(1, self.num_classes + 1):
for bbox in results[j]:
if bbox[4] > self.opt.vis_thresh:
debugger.add_coco_bbox(bbox[:4], j - 1, bbox[4], img_id='ctdet')
debugger.show_all_imgs(pause=self.pause)
debugger.save_all_imgs(path='/home/czb/CenterNet-master/output/', genID=True)
加上一行代码,就是最后一行debugger.save_all_imgs(path=’/home/CenterNet/output/’, genID=True) ,path是输出路径,需要在CenterNet文件夹下新建一个文件夹output,然后再运行一遍发现检测后的图片就会保存在这个文件夹里面了。当然,去掉倒数第二行show_all_imgs,那么运行的时候就不会弹出照片了。
四、训练模型
- 定位一下发现前面自己建立的ped.py文件(修改下面的代码):
if split == 'val':
self.annot_path = os.path.join(
self.data_dir, 'annotations',
'val.json').format(split) # 修改test的json文件位置
else:
if opt.task == 'exdet':
self.annot_path = os.path.join(
self.data_dir, 'annotations',
'train.json').format(split)
else:
self.annot_path = os.path.join(
self.data_dir, 'annotations',
'train.json').format(split) # 这才是train文件
要把第一行if split 改为 ==‘val’,这样validate时就会调用val.json文件。把最后一行要调用的文件改为‘train.json’,这样训练的时候才会调用train.json文件。改完之后数据集导入就正常了。
2. 运行main.py
python main.py ctdet --exp_id coco_dla --batch_size 2 --master_batch 1 --lr 1.25e-4 --gpus 1
如果显示显存不够之类的那种错误,需要在opts.py文件中将–num_workers改成0,batch_size改成16或者更小

五、测试模型
- 在我们之前建立的ped.py中修改如下部分,加入if split == ‘test’:…,作用是当test时指定标签文件为之前建立的测试文件test.json

- 运行test.py
cd myproject/CenterNet/src
python test.py --exp_id coco_dla --not_prefetch_test ctdet --load_model /home/zhaohuan/myproject/CenterNet/exp/ctdet/coco_dla/model_best.pth