YOLO+PaddleOCR实现车牌检测识别
YOLO+PaddleOCR实现车牌检测识别
本篇文章将会使用Keras-YOLOV3来训练自己的车牌检测的模型,结合PaddleOCR来识别车牌,最终使用OpenCV将其整体进行串联。
技术简介
Keras
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
Keras中文网
YOLOV3
YOLO是“You Only Look Once”的简称,它虽然不是最精确的算法,但在精确度和速度之间选择的折中,效果也是相当不错。YOLOv3借鉴了YOLOv1和YOLOv2,虽然没有太多的创新点,但在保持YOLO家族速度的优势的同时,提升了检测精度,尤其对于小物体的检测能力。YOLOv3算法使用一个单独神经网络作用在图像上,将图像划分多个区域并且预测边界框和每个区域的概率。
Keras-YOLOV3 GitHub地址
PaddleOCR
PaddleOCR是百度飞桨下的一款OCR工具库,使用简单,识别率高。
飞桨PaddleOCR官网地址
实现过程
整体的实现过程大致为,克隆Keras-YOLOV3源代码–>下载YOLOV3预训练权重–>将YOLOV3预训练权重转为Keras所需要的.h5类型的模型文件–>标注数据集–>训练模型–>测试模型。以下将为大家详细介绍实现过程。
环境搭建
Python环境
我这里使用的是Anaconda3,Python3.6的版本,可以在Anaconda官网上根据不同的系统环境,下载相应的软件版本。基本上都是一键安装,所以安装过程就不在这里赘述了。
安装完成后,可以使用
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
添加清华源,方便后面下载依赖使用。
克隆Keras-YOLOV3
Keras-YOLOV3 GitHub地址如果无法使用Github克隆的话,这里我已经将完整的Keras-YOLOV3的代码拷贝到了Gitee上,方便大家克隆:Keras-YOLOV3 Gitee地址
git clone https://github.com/qqwweee/keras-yolo3.git
安装所需依赖
首先我们需要进入到上一步克隆下来的keras-yolo3目录中:
cd keras-yolo3
使用conda创建虚拟环境
conda create -n keras-yolov3 python==3.7
# 激活虚拟环境
conda activate keras-yolov3
安装所需依赖
如果有GPU的同学请下载tensorflow-gpu的版本
pip install tensorflow==1.13.1 keras==2.2 pillow opencv-python==3.4.2.17 matplotlib==2.2.2 numpy==1.16.4 pyparsing==2.4.7 'h5py<3.0.0' -i https://pypi.douban.com/simple
下载yolov3权重,转换成.h5文件
wget https://pjreddie.com/media/files/yolov3.weights
# 下载完后执行,将yolov3文件转换成.h5文件
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
转换完成后,会在model_data/下生成一个yolo.h5的文件
使用PyCharm打开
配置项目的Interpreter
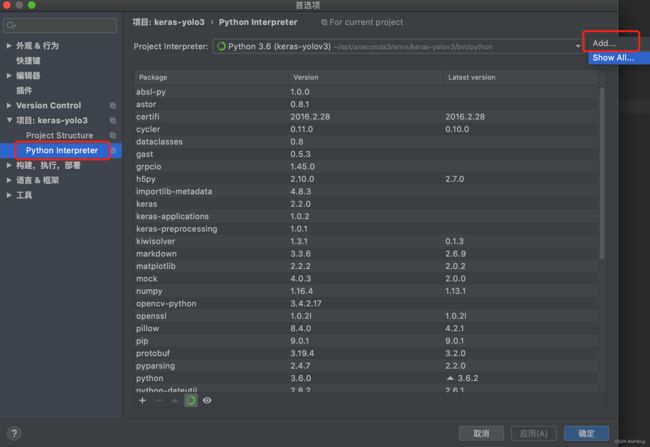
选择刚刚创建的虚拟环境,一般情况下会在anaconda3/envs目录下,根据实际情况进行配置。

目前的目录结构,且没有任何报错,如果依赖报错,请查验以上步骤

环境测试
在keras-yolo3跟目录下创建一个img目录,并放上一张自己的图片,yolov3,目前已有检测的对象包括:
飞机,自行车,汽车,马,牛等等。
在这里,我放了一张马的图片,进行环境的测试。

在根目录下编写一个测试文件:yolo_test.py
from yolo import YOLO
from PIL import Image
yolo = YOLO()
image = Image.open('img/horse.jpeg')
rel_image = yolo.detect_image(image)
rel_image.show()
yolo.close_session()
测试结果:
可以看到以下测试结果,检测出了两匹马,并且置信度都为1,很准确。
训练数据集
创建目录结构
mkdir -p VOCdevkit/VOC2007/Annotations VOCdevkit/VOC2007/ImageSets/Main VOCdevkit/VOC2007/JPEGImages

准备数据集
可以在百度图片中下载汽车并且带有车牌的图片,并将图片放到VOCdevkit/VOC2007/JPEGImages目录下。
编写脚本对图片数据预处理,把所有图片的后缀改成.jpg格式,并将图片统一转为(416, 416)的大小格式,因为yolov3模型默认输入的图片尺寸为(416, 416)。
convert_img.py
import os
import glob
import cv2
img_paths = glob.glob('VOCdevkit/VOC2007/JPEGImages/*')
for (index, img_path) in enumerate(img_paths):
img = cv2.imread(img_path)
resize = cv2.resize(img, (416, 416), cv2.INTER_AREA)
img_dir = img_path[:img_path.rindex('/') + 1]
resize_img_path = '{}car_{}.jpg'.format(img_dir, index)
cv2.imwrite(resize_img_path, resize)
os.remove(img_path)
数据标注
使用labelImg对数据进行标注,安装过程就不再赘述了,请自行查找。
使用快捷键w,快速创建选区,并填写label的名称
使用快捷键d,对标注存储并且下一张,将标注文件保存到VOCdevkit/VOC2007/Annotations目录下

以下数据以此类推,我这里准备了84张汽车的图片,进行标注。
划分数据文件
编写脚本划分train.txt,test.txt,val.txt数据label,只包含图片文件名部分,8:1:1;生成完之后放到VOCdevkit\VOC2007\ImageSets\Main目录下
import glob
def gen_data_txt(data_list, file_name):
with open('VOCdevkit/VOC2007/ImageSets/Main/{}'.format(file_name), 'w') as f:
for data in data_list:
f.write('{}\n'.format(data[data.rindex('/') + 1:data.rindex('.')]))
img_paths = glob.glob('/Users/junweiwang/workerspace/keras-yolo3/VOCdevkit/VOC2007/JPEGImages/*')
train_data_paths = img_paths[:int(len(img_paths) * 0.8)]
test_data_paths = img_paths[
len(train_data_paths):len(train_data_paths) + int((len(img_paths) - len(train_data_paths)) / 2)]
val_data_paths = img_paths[len(train_data_paths) + len(test_data_paths):]
gen_data_txt(train_data_paths, 'train.txt')
gen_data_txt(test_data_paths, 'test.txt')
gen_data_txt(val_data_paths, 'val.txt')
文件生成后,将文件末尾的空行删掉。
运行voc_annotation.py文件注意在训练自己的数据集时,需要将里面的classes换成自己的,例如,“classes = [“car_license”]”,其他的不需要改变。

执行完成后会在根目录下,生成2007_train.txt,2007_test.txt,2007_val.txt三个文件,需要将文件名中的2007_部分删除,如:


修改model_data
1.修改“根目录下\model_data”的目录中“coco_classes.txt、
voc_classes.txt”这两个文件,将 car_license 类别填入进去,并且删除其它的label。
开始训练
由于我的机器没有GPU,所以是租用了GPU的服务器,来训练车牌检测的模型。
也是我意外发现,找到了这个GPU租用服务的平台。矩池云官网,有需要的可以看看,在此声明,没有任何利益关系。
在根目录下创建logs\000目录,用来存放训练完成的权重文件
将model_data下的yolo.h5文件重命名为yolo_weights.h5
调整训练参数batch_size,epochs,由于我这里的数据集只有八十多张,比较少,所以把batch_size=1,这里的epochs暂时就不做调整了。
最后执行根目录下的train.py进行训练,这个过程比较长,请耐心等待。

最终达到loss:13.1307–val_loss:13.5433不再下降,提前结束训练,在logs/000目录下有每个阶段和最终的权重文件,将trained_weights_final.h5放到跟目录的model_data中
模型测试
找一张带有车牌的汽车图片进行测试,需要将yolo.py文件中的model_path改为刚刚训练好的模型。
_defaults = {
"model_path": 'model_data/trained_weights_final.h5',
"anchors_path": 'model_data/yolo_anchors.txt',
"classes_path": 'model_data/coco_classes.txt',
"score" : 0.3,
"iou" : 0.45,
"model_image_size" : (416, 416),
"gpu_num" : 1,
}
创建一个测试脚本
from yolo import YOLO
from PIL import Image
yolo = YOLO()
image = Image.open('img/car02.jpeg')
rel_image = yolo.detect_image(image)
rel_image.show()
yolo.close_session()
可以看到车牌位置已经被检测出来了,由于训练的数据集数量有限,其检测的置信度不是特别高。
车牌识别
车牌识别使用的是飞桨PaddleOCR。首先我们先安装PaddleOCR的依赖。
pip install --upgrade pip -i https://pypi.douban.com/simple
pip install paddlepaddle -i https://pypi.douban.com/simple
pip install PaddleOCR -i https://pypi.douban.com/simple
修改一下yolo.py文件中的detect_image方法,将外接矩形框的四个点返回,以便截取车牌位置

编写识别脚本:
from yolo import YOLO
from PIL import Image
from paddleocr import PaddleOCR
import cv2
import numpy as np
yolo = YOLO()
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
def show(image):
cv2.namedWindow('test', 0)
cv2.imshow('test', image)
# 0任意键终止窗口
cv2.waitKey(0)
cv2.destroyAllWindows()
image = cv2.imread('img/car01.jpeg')
img_copy = image.copy()
detect_image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_RGB2BGR))
rel_image, (label, (left, top), (right, bottom)) = yolo.detect_image(detect_image)
target_img = img_copy[top:bottom, left:right]
result = ocr.ocr(target_img)
print(result)
show(cv2.cvtColor(np.asarray(rel_image), cv2.COLOR_RGB2BGR))
yolo.close_session()
可以看到,识别的效果还是很不错的,如果训练的数据集更多一些,效果当然会更好,车牌的检测也会更准确。


结语
当然也可以用PaddleOCR中的文字检测模型来训练车牌检测,不过其PaddleOCR底层也有一些模型用到了YOLO,所以,在此,使用的YOLO进行车牌检测训练的。可以根据此流程举一反三,通过YOLO做更多内容的检测。
最后放上完整项目的网盘链接:
链接: https://pan.baidu.com/s/1pC3aEjBCL-74o9EbJDZtjw 提取码: q68n