CV-Model【6】:Vision Transformer
系列文章目录
Transformer 系列网络(一):
CV-Model【5】:Transformer
Transformer 系列网络(二):
CV-Model【6】:Vision Transformer
Transformer 系列网络(三):
CV-Model【7】:Swin Transformer
文章目录
- 系列文章目录
- 前言
- 1. Abstract & Introduction
-
- 1.1. Abstract
- 1.2. Introduction
- 2. Vision Transformer
-
- 2.1. Model Architecture
-
- 2.1.1. Embedding Layer
-
-
- 2.1.1.1. Patch Embeddings
- 2.1.1.2. Learnable Embedding
- 2.1.1.3. Position Embedding
-
- 2.1.2. Transformer Encoder
- 2.2. Hyperparameters
- 2.3. Hybrid Architecture
- 总结
前言
Vision Transformer,或称 ViT,是一种用于图像分类的模型,在图像的补丁上采用了类似 Transformer 的结构。一幅图像被分割成固定大小的斑块,然后对每个斑块进行线性嵌入,添加位置嵌入,并将得到的向量序列送入一个标准的 Transformer 编码器。为了进行分类,使用了向序列添加额外的可学习"分类标记"的标准方法
原论文链接:
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
1. Abstract & Introduction
1.1. Abstract
虽然 Transformer 架构已成为 NLP 任务的事实标准,但它在 CV 中的应用仍然有限。在视觉上,注意力要么与卷积网络结合使用,要么用于替换卷积网络的某些组件,同时保持其整体结构。我们证明了这种对 CNNs 的依赖是不必要的,直接应用于图像块序列 ( sequences of image patches ) 的纯 Transformer 可以很好地执行 图像分类 任务。当对大量数据进行预训练并迁移到多个中小型图像识别基准时 ( ImageNet、CIFAR-100、VTAB 等 ),与 SOTA 的 CNN 相比,Vision Transformer ( ViT ) 可获得更优异的结果,同时仅需更少的训练资源
1.2. Introduction
受 NLP 中 Transformer 成功放缩 ( scaling ) 的启发,本文尝试将标准 Transformer 直接应用于图像,并尽可能减少修改。为此,本文将图像拆分为块 ( patch ),并将这些图像块的线性嵌入序列作为 Transformer 的输入。图像块 image patches 的处理方式与 NLP 应用中的标记 tokens (单词 words) 相同。本文以有监督方式训练图像分类模型。
当在没有强正则化的中型数据集(如 ImageNet)上进行训练时,这些模型产生的准确率比同等大小的 ResNet 低几个百分点。 这种看似令人沮丧的结果可能是意料之中的 Transformers 缺乏 CNN 固有的一些归纳偏置 ( inductive biases ),例如平移等效性和局部性 ( translation equivariance and locality ),因此在数据量不足的情况下训练时不能很好地泛化。
2. Vision Transformer
Vision Transformer 网络结构如下所示(以 ViT-B/16 为例):
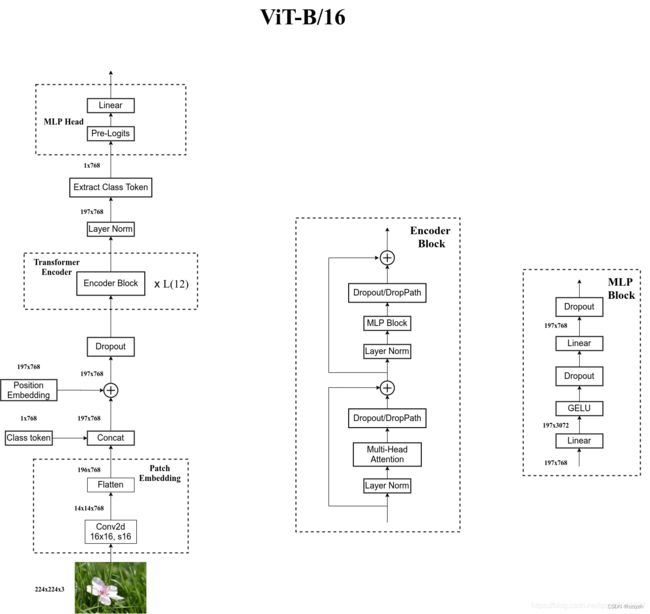
2.1. Model Architecture
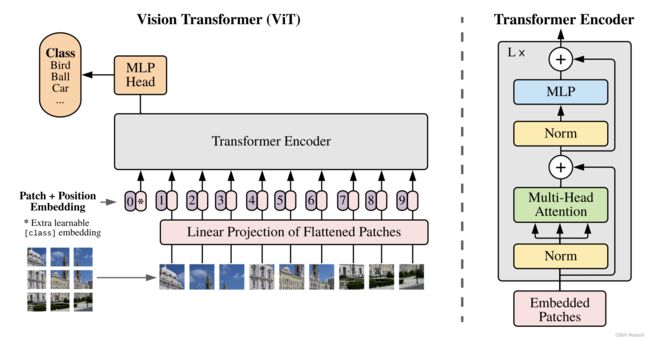
模型由三个模块组成:
- Linear Projection of Flattened Patches(Embedding 层)
- Transformer Encoder(图右侧给出的更加详细的结构)
- MLP Head(最终用于分类的层结构)
2.1.1. Embedding Layer
2.1.1.1. Patch Embeddings
标准 Transformer 接受一维标记嵌入序列 ( Sequence of token embeddings ) 作为输入(token 序列),即二维矩阵 [num_token, token_dim]
为处理 2D 图像,我们将图像 x ∈ R H × W × C x \in \mathbb{R}^{H \times W \times C} x∈RH×W×C reshape 为一个展平 ( flatten ) 的 2D 块序列 x p ∈ R N × ( P 2 ⋅ C ) x_p \in \mathbb{R}^{N \times (P^2 \cdot C) } xp∈RN×(P2⋅C)
- ( H , W ) (H, W) (H,W) 是原始图像的分辨率
- C C C 是通道数(RGB 图像 C = 3)
- ( P , P ) (P, P) (P,P) 是每个图像块的分辨率
- N = H W / P 2 N = HW / P^2 N=HW/P2 是产生的图像块数,即 Transformer 的有效输入序列长度
Transformer 在其所有层中使用恒定的隐向量 (latent vector) 大小 D D D(即 token 序列的长度),因此我们将图像块展平,并使用可训练的线性投影(FC 层)将维度 P 2 ⋅ C P^2 \cdot C P2⋅C 映射为 D D D 维,同时保持图像块数 N N N 不变。
此投影输出称为图像块嵌入 (Patch Embeddings),本质就是对每一个展平后的 patch vector x p ∈ R N × ( P 2 ⋅ C ) x_p \in \mathbb{R}^{N \times (P^2 \cdot C) } xp∈RN×(P2⋅C) 做一个线性变换 / 全连接层 E ∈ R ( P 2 ⋅ C ) × D E \in \mathbb{R}^{(P^2 \cdot C) \times D} E∈R(P2⋅C)×D,由 P 2 ⋅ C P^2 \cdot C P2⋅C 维降维至 D D D 维,得到 x p E ∈ R N × D x_pE \in \mathbb{R}^{N \times D} xpE∈RN×D
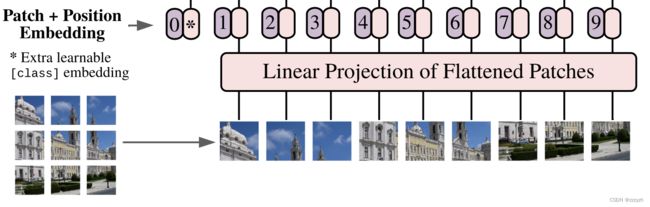
以 ViT-B/16 为例,每个 token 向量长度为 768:
- 首先将一张图片按给定大小分成一堆 patches
- 将输入图片 224 × 224 224 \times 224 224×224 按照 16 × 16 16 \times 16 16×16 大小的
patch进行划分,划分后会得到 ( 224 / 16 ) 2 = 196 (224/16)^2=196 (224/16)2=196 个 patches
- 将输入图片 224 × 224 224 \times 224 224×224 按照 16 × 16 16 \times 16 16×16 大小的
- 接着通过线性映射将每个
patch映射到一维向量中- 每个
patch数据 shape 为 [ 16 , 16 , 3 ] [16, 16, 3] [16,16,3] 通过映射得到一个长度为 768 的向量 (token)
- 每个
在代码中,上述步骤直接通过一个卷积层来实现。直接使用一个卷积核大小为 16 × 16 16 \times 16 16×16,步距为 16,卷积核个数为 768 的卷积来实现。通过卷积 [ 224 , 224 , 3 ] → [ 14 , 14 , 768 ] [224, 224, 3] \rightarrow [14, 14, 768] [224,224,3]→[14,14,768],然后把 H 以及 W 两个维度展平即可 [ 14 , 14 , 768 ] → [ 196 , 768 ] [14, 14, 768] \rightarrow [196, 768] [14,14,768]→[196,768],此时正好变成了一个二维矩阵。
2.1.1.2. Learnable Embedding
类似于 BERT 的 [ c l a s s ] t o k e n \mathrm{[class]} token [class]token,此处为图像块嵌入序列预设一个可学习的嵌入,数据格式和其他token一样都是一个向量(一个分类向量),用于训练 Transformer 时学习类别信息。
以 ViT-B/16 为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起: C a t ( [ 1 , 768 ] , [ 196 , 768 ] ) → [ 197 , 768 ] Cat([1, 768], [196, 768]) \rightarrow [197, 768] Cat([1,768],[196,768])→[197,768]
2.1.1.3. Position Embedding
位置嵌入 E p o s ∈ R ( N + 1 ) × D E_{pos} \in \mathbb{R}^{(N+1) \times D} Epos∈R(N+1)×D 也被加入图像块嵌入,以保留输入图像块之间的空间位置信息。不同于 CNN,Transformer 需要位置嵌入来编码 patch tokens 的位置信息,这主要是由于自注意力的扰动不变性 (Permutation-invariant),即打乱 Sequence 中 tokens 的顺序并不会改变结果。相反,若不给模型提供图像块的位置信息,那么模型就需要通过图像块的语义来学习拼图,这就额外增加了学习成本。
ViT 论文中对比了几种不同的位置编码方案:
- 无位置嵌入
- 1-D 位置嵌入:考虑把 2-D 图像块视为 1-D 序列
- 2-D 位置嵌入:考虑图像块的 2-D 位置 (x, y)
- 相对位置嵌入:考虑图像块的相对位置
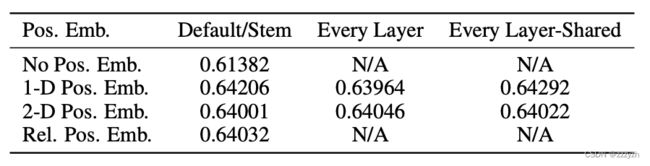
最后发现如果不提供位置编码效果会差,但其它各种类型的编码效果效果都接近,这主要是因为 ViT 的输入是相对较大的图像块而非像素,所以学习位置信息相对容易很多。在源代码当中默认使用 1-D 位置嵌入,因为相对来说参数较少。
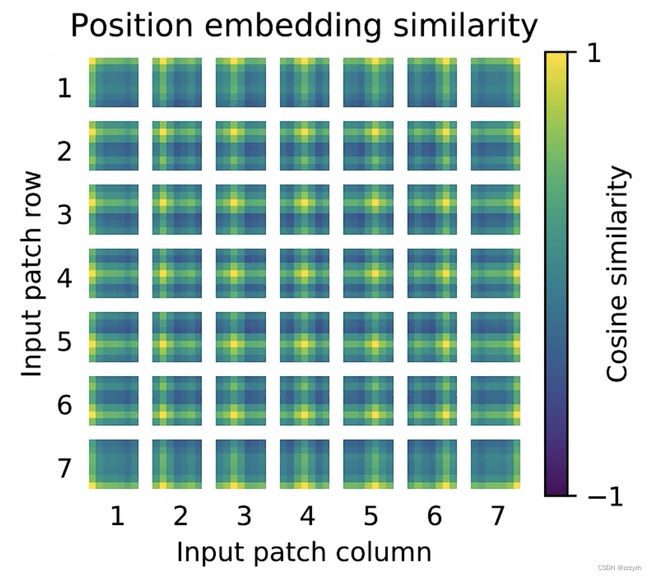
对学习到的位置编码进行了可视化,发现相近的图像块的位置编码较相似,且同行或列的位置编码也相近:
- 计算每个 patch 的位置编码与其他 patch 位置编码之间的余弦相似度,即 cos 的值
- 对于每个 patch 的位置编码与它自身的余弦相似度,即 cos(0) = 1,对应的最相似
2.1.2. Transformer Encoder
Transformer 编码器 由交替的多头自注意力层 (MHA) 和多层感知机块 (MLP) 构成。在每个块前应用层归一化 (Layer Norm),在每个块后应用残差连接 (Residual Connection)。
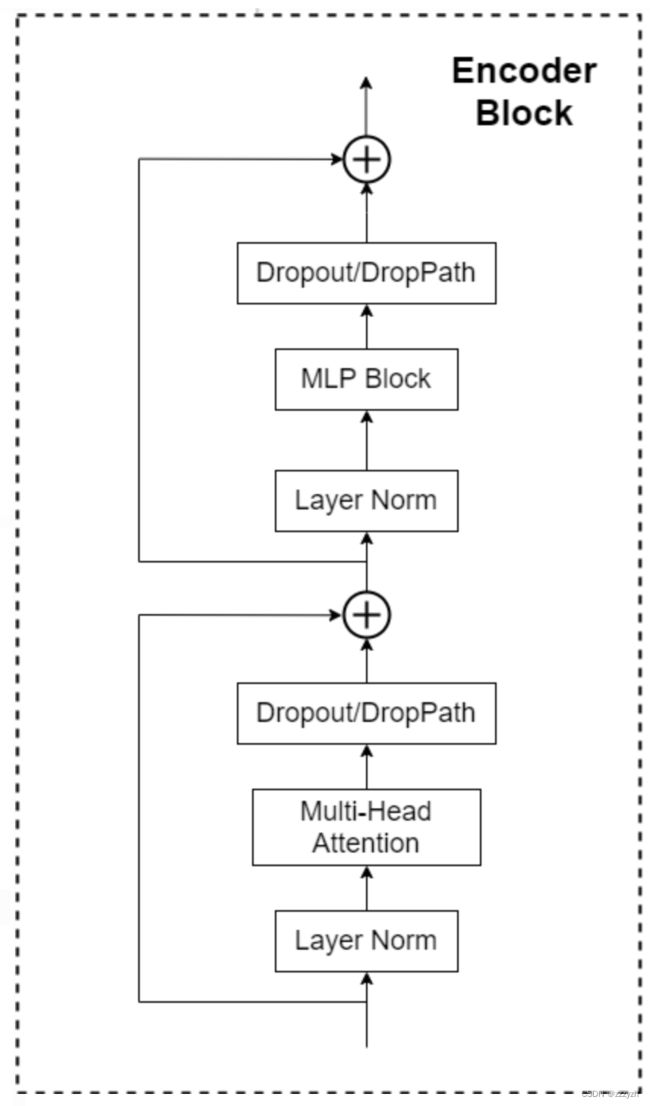
- Layer Norm,这种 Normalization 方法主要是针对 NLP 领域提出的,这里是对每个 token 进行 Norm 处理
- Multi-Head Attention,可以参考我的另一篇blog:CV-Model【5】:Transformer
- Dropout / DropPath
- MLP Head

- 包含两个
FC层,- 第一个 FC 将特征从维度 D 变换成 4D
- 第二个 FC 将特征从维度 4D 恢复成 D
- 中间的非线性激活函数均采用
GeLU(Gaussian Error Linear Unit,高斯误差线性单元)
- 包含两个
集合了类别向量、图像块嵌入和位置编码三者到一体的输入嵌入向量后,即可馈入Transformer Encoder。ViT 类似于 CNN,不断前向通过由 Transformer Encoder Blocks 串行堆叠构成的 Transformer Encoder,最后提取可学习的类别嵌入向量 —— class token 对应的特征用于 图像分类。整体前向计算过程如下:
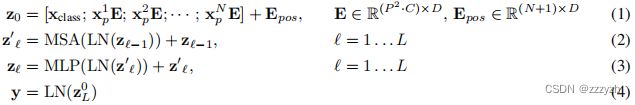
- 等式 1:由图像块嵌入、类别向量和位置编码构成的嵌入输入向量
- 等式 2:由多头注意力机制、层归一化和跳跃连接 (Layer Norm & Add) 构成的 MSA Block,可重复 L L L 个,其中第 l l l 个输出为 z l ′ z_l' zl′
- 等式 3:由前馈网络 (FFN)、层归一化和跳跃连接 (Layer Norm & Add) 构成的MLP Block,可重复 L L L 个,其中第 l l l 个输出为 z l z_l zl
- 等式 4:由层归一化 (Layer Norm) 和分类头 (MLP or FC) 输出图像表示 y y y
2.2. Hyperparameters

- Patch Size 是模型输入的 patch size,ViT 中共有两个设置:14x14 和 16x16,该参数仅影响计算量
- Layers 是 Transformer Encoder 中重复堆叠 Encoder Block 的次数
- Hidden Size 是通过 Embedding 层后每个 token 的 dim(向量的长度)
- MLP size 是 Transformer Encoder 中 MLP Block 第一个全连接的节点个数(是 Hidden Size 的 4 倍)
- Heads 代表 Transformer 中 Multi-Head Attention 的 heads 数
2.3. Hybrid Architecture
首先使用传统的卷积神经网络提取特征,再利用上述的 ViT 模型进一步进行图像分类
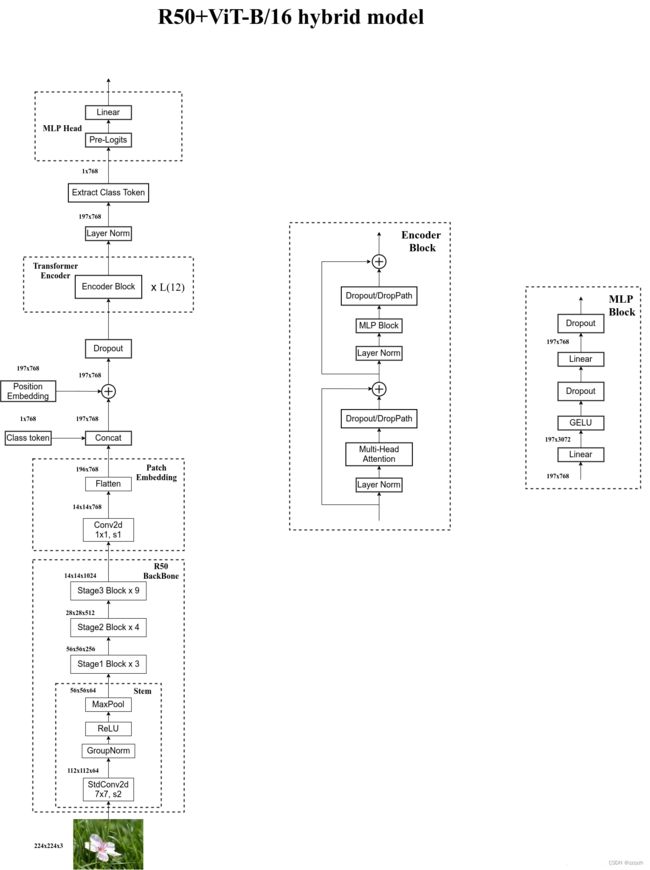
特征提取网络采用 Res50,并做出一下更改:
- Res50 的卷积层采用的是 StdConv2d,而不是传统的 Conv2d
- 将所有的 BatchNorm 层替换成 GroupNorm 层
- 把 stage 4 中的 3 个 block 移至 stage 3 中
- 存在 stage 4 的话下采样率为 32
- 只保留 3 个 stage 的话下采样率为 16
- 网络通过改进后的 Res50 输入 ViT 结构之前,会经过一个 1 × 1 1 \times 1 1×1 的卷积层,用于将特征矩阵的
channel调整为合适的大小
Hybrid Architecture 作为原始图像块的替代方案,输入序列可由 CNN 的特征图构成。在这种混合模型中,图像块嵌入投影被用在经 CNN 特征提取的块而非原始输入图像块。
作为一种特殊情况,块的空间尺寸可以为 1 × 1 1 \times 1 1×1,这意味着输入序列是通过简单地将特征图的空间维度展平并投影到 Transformer 维度 获得的。然后,如上所述添加了分类输入嵌入和位置嵌入,再将三者组成的整体馈入 Transformer 编码器。
简单来说,就是先用 CNN 提取图像特征,然后由 CNN 提取的特征图构成图像块嵌入。由于 CNN 已经将图像下采样了,所以块尺寸可为 1 × 1 1 \times 1 1×1。
总结
至此,Vision Transformer 的原理及模型结构以及全部介绍完毕。从实验给出的结果,在当时也达到了 SOTA,但是相比于 CNN,它需要更多的数据集。在小数据集上训练出来的精度是不如 CNN 的,但在大数据集上 ViT 精度更高。
一个直观的解释是:ViT 因为 self-attention 独特的机制,更多的利用 token 与 token 跨像素之间的信息,而 CNN 只是对领域的像素进行计算,所以相同参数的情况下,ViT获得的信息更多,在某种程度上可以看成是模型深度更深。所以小数据集上ViT是欠拟合的。
实际开发中的做法是:基于大数据集上训练,得到一个预训练权重,然后再在小数据集上Fine-Tune。
参考博客
视频资料