CV-Model【5】:Transformer
系列文章目录
Transformer 系列网络(一):
CV-Model【5】:Transformer
Transformer 系列网络(二):
CV-Model【6】:Vision Transformer
Transformer 系列网络(三):
CV-Model【7】:Swin Transformer
文章目录
- 系列文章目录
- 前言
- 1. Self Attention
- 1.1. Scaled Dot-Product Attention
-
-
- 1.1.1. Scaled Inner-Product (Dot-Product)
- 1.1.2. Considering the whole sequence
- 1.1.3. Calculate with matrix
- 1.2. Multi - Head Attention
- 1.3. Positional Encoding
-
- 2. Transformer
-
- 2.1. Encoder Block
- 2.2. Decoder Block
-
- 2.2.1. Masked Multi-Head Self-attention
- 总结
前言
Transformer 是一种模型架构,它摒弃了递归,而是完全依靠注意力机制来得出输入和输出之间的全局依赖关系。在 Transformer 之前,主流的序列转换模型是基于复杂的递归或卷积神经网络,包括一个编码器和一个解码器。Transformer 也采用了编码器和解码器,但去除递归而采用注意力机制,可以比 RNN 和 CNN 等方法明显地实现更多的并行化。
原论文侧重于在 NLP 领域的贡献,所以本文主要针对其提出的 Self - Attention 和 Multi-Head Attention 进行分析
原论文链接:
Attention Is All You Need
1. Self Attention
1.1. Scaled Dot-Product Attention
1.1.1. Scaled Inner-Product (Dot-Product)

假设现在有一串蓝色的 Input Vector x 1 , x 2 , x 3 , x 4 x^1, x^2, x^3, x^4 x1,x2,x3,x4,每个 Input Vector 先各乘一个权重参数矩阵 W W W 得到一串绿色的 Embedding Vector a 1 , a 2 , a 3 , a 4 a^1, a^2, a^3, a^4 a1,a2,a3,a4,然后通过 Self-attention 层,即令每个 Embedding Vector a 1 , a 2 , a 3 , a 4 a^1, a^2, a^3, a^4 a1,a2,a3,a4 分别乘上 3 个不同的 Transformation Matrix W q − Q u e r y , W k − K e y , W v − V a l u e W_q - Query, W_k - Key, W_v - Value Wq−Query,Wk−Key,Wv−Value(这三个参数是可训练的,对于所有 a 而言是共享的),得到 3 个不同的 Vector q i , k i , v i q^i, k^i, v^i qi,ki,vi。

用每个 Query q 去对每个 Key k 做 Attention,以衡量任意 2 个 Vector 的相似程度(即计算两者的相关性,相关性越大对应 v 的权重也就越大)。
接着对刚刚得到的 Vector q i , k i q^i, k^i qi,ki 做 Scaled Inner-Product (Dot-Product) 得到 α j , i \alpha_{j, i} αj,i。以 q 1 q^1 q1 为例,Scaled Inner-Product 计算公式如下所示:
α 1 , i = q 1 ⋅ k i d \alpha_{1, i} = q^1 \cdot \frac{k^i}{\sqrt{d}} α1,i=q1⋅dki
其中,d 是 q i q^i qi 和 k i k^i ki 的维度 dimension 大小。因为 q i ⋅ k i q^i \cdot k^i qi⋅ki 的数值会随 dimension 的增大而增大,导致通过 softmax 后梯度变的很小,所以通过除以 d \sqrt{d} d 来进行缩放(归一化)。
举个例子:
假设 a 1 = ( 1 , 1 ) a_1=(1, 1) a1=(1,1), a 2 = ( 1 , 0 ) a_2=(1,0) a2=(1,0), W q = ( 1 1 0 1 ) W^q= \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix} Wq=(1011),那么:
q 1 = ( 1 , 1 ) ( 1 1 0 1 ) = ( 1 , 2 ) , q 2 = ( 1 , 0 ) ( 1 1 0 1 ) = ( 1 , 1 ) q^1 = (1, 1) \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix} = (1, 2), \\ q^2 = (1, 0) \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix} = (1, 1) q1=(1,1)(1011)=(1,2),q2=(1,0)(1011)=(1,1)
因为Transformer可以并行化处理,所以上式可以直接写成:
( q 1 q 2 ) = ( 1 1 1 0 ) ( 1 1 0 1 ) = ( 1 2 1 1 ) \begin{pmatrix} q^1 \\ q^2 \end{pmatrix} = \begin{pmatrix} 1 & 1 \\ 1 & 0 \end{pmatrix} \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix} = \begin{pmatrix} 1 & 2 \\ 1 & 1 \end{pmatrix} (q1q2)=(1110)(1011)=(1121)
需要注意的是,此处的 a 1 , a 2 a_1, a_2 a1,a2 是上下拼接
同理我们可以得到 ( k 1 k 2 ) \begin{pmatrix} k^1\\ k^2 \end{pmatrix} (k1k2) 以及 ( v 1 v 2 ) \begin{pmatrix} v^1\\ v^2 \end{pmatrix} (v1v2)
所以,求得的 ( q 1 q 2 ) \begin{pmatrix} q^1\\ q^2 \end{pmatrix} (q1q2) 就是原论文中的 Q Q Q, ( k 1 k 2 ) \begin{pmatrix} k^1\\ k^2 \end{pmatrix} (k1k2) 就是原论文中的 K K K, ( v 1 v 2 ) \begin{pmatrix} v^1\\ v^2 \end{pmatrix} (v1v2) 就是原论文中的 V V V
1.1.2. Considering the whole sequence
接下来,对所有 Attention 结果 α i , i ∈ { 1 , 2 , 3 , 4 } \alpha_i, i \in \{1,2,3,4\} αi,i∈{1,2,3,4} 执行 Softmax 操作,如下所示:
α ^ 1 , i = e α 1 , i ∑ j α 1 , i \hat{\alpha}_{1,i} = \frac{e^{\alpha_{1,i}}}{\sum_j \alpha_{1,i}} α^1,i=∑jα1,ieα1,i
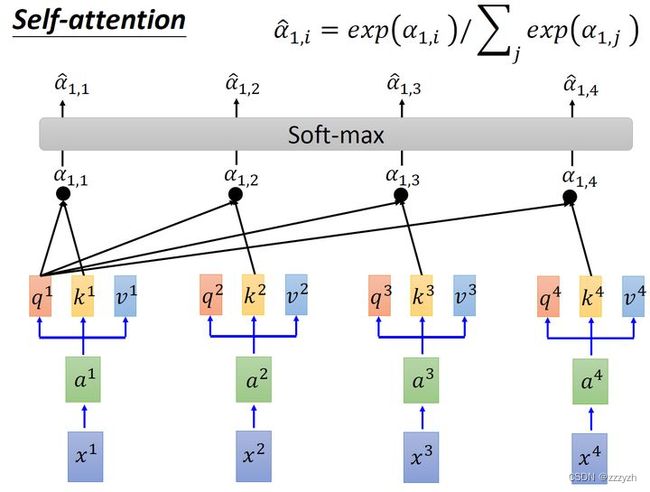
执行 Softmax 操作后得到了 α ^ 1 , i , i ∈ { 1 , 2 , 3 , 4 } \hat{ \alpha } _{1,i} , i \in \{1, 2, 3, 4 \} α^1,i,i∈{1,2,3,4},这里的 α ^ \hat{\alpha} α^ 相当于计算得到针对每个 v v v 的权重,到这我们就完成了 A t t e n t i o n ( Q , K , V ) Attention(Q, K, V) Attention(Q,K,V) 公式中 s o f t m a x ( Q K T d k ) softmax(\frac{QK^T}{\sqrt{d_k}}) softmax(dkQKT) 部分。
令 α ^ 1 , i \hat{ \alpha } _{1,i} α^1,i 与各 v i v^i vi 相乘并求和,得到 b i b^i bi,如下所示:
b i = ∑ i α ^ 1 , i v i b^i = \displaystyle\sum_i \hat{\alpha}_{1, i} v^i bi=i∑α^1,ivi

因而,产生 b i b^i bi 的过程中用到了 整个 Input Vector 的信息:
- 若要考虑局部 (local) 信息,则只需学习出相应的 α ^ 1 , i = 0 , b 1 \hat{ \alpha } _{1,i} = 0,b^1 α^1,i=0,b1 就不再带有那个对应分支的信息了
- 若要考虑全局 (global) 信息,则只需学习所有的 α ^ 1 , i ≠ 0 , b 1 \hat{ \alpha } _{1,i} \neq 0,b^1 α^1,i=0,b1 就带有全部的对应分支的信息了
相当于每个向量都等于原来所有向量(包括它自己)的加权平均和,也就相当于注意力。就完成了论文中有关注意力的一个公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}}) V Attention(Q,K,V)=softmax(dkQKT)V
举个例子:
计算 α 1 , i \alpha_{1, i} α1,i:
α 1 , 1 = q 1 ⋅ k 1 d = 1 × 1 + 2 × 0 2 = 0.71 α 1 , 2 = q 1 ⋅ k 2 d = 1 × 0 + 2 × 1 2 = 1.41 \alpha_{1, 1} = \frac{q^1 \cdot k^1}{\sqrt{d}} = \frac{1 \times 1 + 2 \times 0}{\sqrt{2}} = 0.71 \\ \alpha_{1, 2} = \frac{q^1 \cdot k^2}{\sqrt{d}} = \frac{1 \times 0 + 2 \times 1}{\sqrt{2}} = 1.41 α1,1=dq1⋅k1=21×1+2×0=0.71α1,2=dq1⋅k2=21×0+2×1=1.41
同理使用 q 2 q^2 q2 去匹配所有的 k k k 能得到 α 2 , i \alpha_{2, i} α2,i,统一写成矩阵乘法形式:
( α 1 , 1 α 1 , 2 α 2 , 1 α 2 , 2 ) = ( q 1 q 2 ) ( k 1 k 2 ) T d \begin{pmatrix} \alpha_{1, 1} & \alpha_{1, 2} \\ \alpha_{2, 1} & \alpha_{2, 2} \end{pmatrix} = \frac{\begin{pmatrix} q^1\\ q^2 \end{pmatrix}\begin{pmatrix} k^1\\ k^2 \end{pmatrix}^T}{\sqrt{d}} (α1,1α2,1α1,2α2,2)=d(q1q2)(k1k2)T
接着对每一行即 ( α 1 , 1 , α 1 , 2 ) (\alpha_{1, 1}, \alpha_{1, 2}) (α1,1,α1,2) 和 ( α 2 , 1 , α 2 , 2 ) (\alpha_{2, 1}, \alpha_{2, 2}) (α2,1,α2,2) 分别进行softmax处理得到 ( α ^ 1 , 1 , α ^ 1 , 2 ) (\hat\alpha_{1, 1}, \hat\alpha_{1, 2}) (α^1,1,α^1,2) 和 ( α ^ 2 , 1 , α ^ 2 , 2 ) (\hat\alpha_{2, 1}, \hat\alpha_{2, 2}) (α^2,1,α^2,2)
上面已经计算得到 α \alpha α,即针对每个 v v v 的权重,接着进行加权得到最终结果:
b 1 = α ^ 1 , 1 × v 1 + α ^ 1 , 2 × v 2 = ( 0.33 , 0.67 ) b 2 = α ^ 2 , 1 × v 1 + α ^ 2 , 2 × v 2 = ( 0.50 , 0.50 ) b_1 = \hat\alpha_{1, 1} \times v^1 + \hat\alpha_{1, 2} \times v^2 = (0.33, 0.67) \\ b_2 = \hat\alpha_{2, 1} \times v^1 + \hat\alpha_{2, 2} \times v^2 = (0.50, 0.50) b1=α^1,1×v1+α^1,2×v2=(0.33,0.67)b2=α^2,1×v1+α^2,2×v2=(0.50,0.50)
统一写成矩阵乘法形式:
( b 1 b 2 ) = ( α ^ 1 , 1 α ^ 1 , 2 α ^ 2 , 1 α ^ 2 , 2 ) ( v 1 v 2 ) \begin{pmatrix} b^1\\ b^2 \end{pmatrix} = \begin{pmatrix} \hat\alpha_{1, 1} & \hat\alpha_{1, 2} \\ \hat\alpha_{2, 1} & \hat\alpha_{2, 2} \end{pmatrix} \begin{pmatrix} v^1\\ v^2 \end{pmatrix} (b1b2)=(α^1,1α^2,1α^1,2α^2,2)(v1v2)
1.1.3. Calculate with matrix
用矩阵表示上述计算过程。
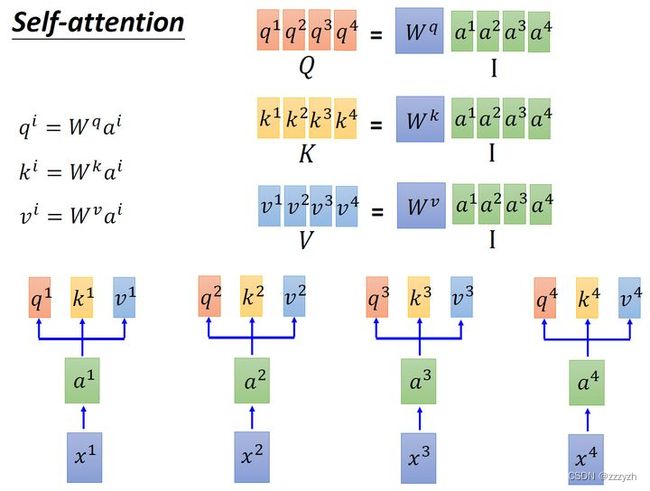
首先输入 Embedding I = [ a 1 , a 2 , a 3 , a 4 ] I = [a^1, a^2, a^3, a^4] I=[a1,a2,a3,a4]:
- 用 I I I 乘
Transformation MatrixW q W^q Wq 得到 Q = [ q 1 , q 2 , q 3 , q 4 ] Q = [q^1, q^2, q^3, q^4] Q=[q1,q2,q3,q4],其每一列代表一个 Vector q; - 用 I I I 乘
Transformation MatrixW k W^k Wk 得到 K = [ k 1 , k 2 , k 3 , k 4 ] K = [k^1, k^2, k^3, k^4] K=[k1,k2,k3,k4],其每一列代表一个 Vector k。 - 用 I I I 乘
Transformation MatrixW v W^v Wv 得到 V = [ v 1 , v 2 , v 3 , v 4 ] V = [v^1, v^2, v^3, v^4] V=[v1,v2,v3,v4],其每一列代表一个 Vector v
接下来用得到的vector q 去匹配 vector k:

- 把 Vector k 转置为行向量与列向量 q 做内积得到标量 α \alpha α(计算时还需要除以 d \sqrt{d} d 进行归一化)
- 整体上看,由 4 个行向量 k T k^T kT 拼成的矩阵 K T K^T KT 和 4 个列向量 q q q 拼成的矩阵 Q Q Q 做内积将得到由标量 α \alpha α 构成的 4 × 4 4 \times 4 4×4 矩阵 A A A,并对其取 Softmax 得到 A ^ \hat{A} A^

- 要得到 b i b^i bi,就要用 α ^ 1 , i \hat{\alpha}_{1,i} α^1,i 分别与 v i v^i vi 相乘并求和,故整体上 A ^ \hat{A} A^ 要再左乘 V V V 矩阵

即公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}}) V Attention(Q,K,V)=softmax(dkQKT)V
1.2. Multi - Head Attention
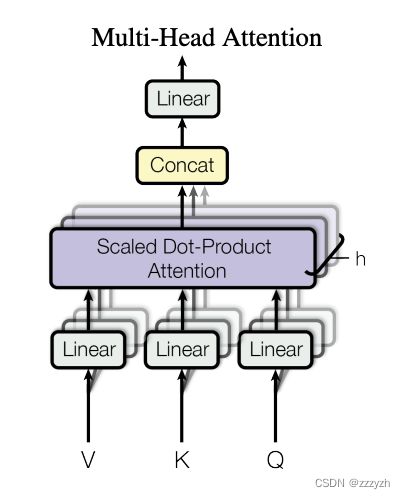
MHA 通过 Linear 线性投影来初始化多组不同的 ( Q , K , V ) (Q, K, V) (Q,K,V),并将多个 (图中表示为 h 个) 单头的自注意力结果 Concat 后,再经一个全连接层降维输出。可以联合初始化不同的 ( Q , K , V ) (Q, K, V) (Q,K,V) 部分学习到的信息
以 2 个 head 的情况为例:
首先和 Self-Attention 模块一样将 a i a_i ai 分别通过 W q , W k , W v W^q, W^k, W^v Wq,Wk,Wv 得到对应的 q i , k i , v i q^i, k^i, v^i qi,ki,vi,然后再根据使用的 head 的数目 h h h 进一步把得到的 q i , k i , v i q^i, k^i, v^i qi,ki,vi 均分成 h h h 份:
- 由 a i a^i ai 生成的 q i q^i qi 进一步乘上 2 个转移矩阵 W q , 1 W^{q, 1} Wq,1 和 W q , 2 W^{q, 2} Wq,2 变为 q i , 1 q^{i, 1} qi,1 和 q i , 2 q^{i, 2} qi,2
- 由 a i a^i ai 生成的 k i k^i ki 进一步乘上 2 个转移矩阵 W k , 1 W^{k, 1} Wk,1 和 W k , 2 W^{k, 2} Wk,2 变为 k i , 1 k^{i, 1} ki,1 和 k i , 2 k^{i, 2} ki,2
- 由 a i a^i ai 生成的 v i v^i vi 进一步乘上 2 个转移矩阵 W v , 1 W^{v, 1} Wv,1 和 W v , 2 W^{v, 2} Wv,2 变为 v i , 1 v^{i, 1} vi,1 和 v i , 2 v^{i, 2} vi,2
h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) head_i = Attention (QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
令 q i , 1 q^{i, 1} qi,1 与 k i , 1 k^{i, 1} ki,1 做 Attention 再与 v i , 1 v^{i, 1} vi,1 相乘、 q i , 1 q^{i, 1} qi,1 与 k j , 1 k^{j, 1} kj,1 做 Attention 再与 v j , 1 v^{j, 1} vj,1 相乘,二者做 Weighted-sum 得到最终的 b i , 1 , i ∈ 1 , 2 , . . . , N ∈ R d , 1 b^{i, 1}, i \in {1, 2, ..., N} \in R^{d,1} bi,1,i∈1,2,...,N∈Rd,1。同理可得 b i , 2 ∈ R d , 1 b ^ {i, 2} \in R^{d,1} bi,2∈Rd,1。
即针对每个 head 使用和 Self-Attention 中相同的方法即可得到对应的结果:
A t t e n t i o n ( Q i , K i , V i ) = s o f t m a x ( Q i K i T d k ) V i Attention(Q_i, K_i, V_i) = softmax(\frac{Q_i K_i^T}{\sqrt{d_k}}) V_i Attention(Qi,Ki,Vi)=softmax(dkQiKiT)Vi

把 b i , 1 b ^ {i, 1} bi,1, b i , 2 b ^ {i, 2} bi,2 Concat 起来,再通过一个 Transformation Matrix W O W^O WO (可学习参数)调整维度, W O W^O WO 的 shape 为 h d v × d m o d e l = d m o d e l × d m o d e l hd_v \times d_{model} = d_{model} \times d_{model} hdv×dmodel=dmodel×dmodel,这里是为了保证输入输出 Multi-head Attention 的向量长度保持不变。

Multi-head Attention 的公式总结如下:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O w h e r e h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) MultiHead(Q, K, V) = Concat(head_1, ..., head_h) W^O \\ where head_i = Attention (QW_i^Q, KW_i^K, VW_i^V) MultiHead(Q,K,V)=Concat(head1,...,headh)WOwhereheadi=Attention(QWiQ,KWiK,VWiV)
1.3. Positional Encoding
上面讲的 Self-Attention 和 Multi-Head Attention 模块,在计算中是没有考虑到位置信息的。假设在Self-Attention模块中,输入 a 1 , a 2 , a 3 a_1, a_2, a_3 a1,a2,a3 得到 b 1 , b 2 , b 3 b_1, b_2, b_3 b1,b2,b3。对于 a 1 a_1 a1 而言, a 2 a_2 a2 和 a 3 a_3 a3 离它都是一样近的而且没有先后顺序。假设将输入的顺序改为 a 1 , a 3 , a 2 a_1, a_3, a_2 a1,a3,a2,对结果 b 1 b_1 b1 是没有任何影响的。

为了引入位置信息,原论文中引入了位置编码 positional encodings。如下图所示,位置编码是直接加在输入的 a = { a 1 , . . . , a n } a=\{a_1,...,a_n\} a={a1,...,an} 中的,即 p e = { p e 1 , . . . , p e n } pe=\{pe_1,...,pe_n\} pe={pe1,...,pen} 和 a = { a 1 , . . . , a n } a=\{a_1,...,a_n\} a={a1,...,an} 拥有相同的维度大小。
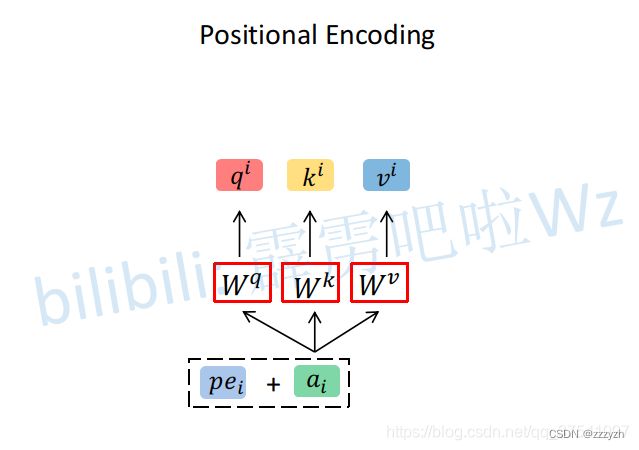
具体做法是:给每个位置人工设定一个表示位置信息的位置向量 e i e^i ei (不是神经网络学出来的),每个位置 (如第 i 个) 都有一个不同的位置向量 e i e^i ei,令其与输入 Embedding a i a^i ai 相加 作为新 a i a^i ai 参与后续运算过程。
先给每个 输入向量 x i ∈ R d , 1 x^i \in R^{d, 1} xi∈Rd,1 加上一个 独热编码的位置向量 p i ∈ R d , 1 p^i \in R^{d, 1} pi∈Rd,1 得到新向量 x p i x^i_{p} xpi 作为输入,乘上一个 Transformation Matrix W = [ W I , W P ] ∈ R d , d + N W = [W^I, W^P] \in R^ {d, d+N} W=[WI,WP]∈Rd,d+N。此时有:
![]()
可见,位置向量 e i e^i ei 与 输入 Embedding a i a^i ai 直接相加 等同于 先原输入向量 x i x^i xi 拼接一个表示位置的独热编码 p i p^i pi 再做 Transformation 得到 Embedding。
Transformer 中除了需要 单词 Embedding 表示输入的内容主题,还需要 位置 Embedding 表示单词出现在句子中的位置。因为 Transformer 不采用 RNN 结构,而是使用全局信息,无法捕获或利用到单词的位置顺序信息,而这部分信息对于 NLP 而言非常重要 (事实上对 CV 也很重要)。所以 Transformer 中 使用位置 Embedding 保存单词在序列中的相对或绝对位置。
2. Transformer

Transformer 的网络机构中,左侧为 Encoder Block,右侧为 Decoder Block。Multi-Head Attention(简称 MHA) 由多个 Self-Attention 组成,其中 Encoder block 包含一个 MHA,Decoder block 包含两个 MHA(其中有一个还用到了 Mask)。MHA 上方还包括一个 Add & Norm 层,Add 表示 Residual Connection 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值归一化。
2.1. Encoder Block
简单来说,Encoder 的作用就是将输入转变成适合网络学习的数据格式,通过上面讲解的 Multi-Head Attention 结构,可以提取某些关键特征,在考虑这些特征的上下文后整合成新的向量,输入 Decoder 中进行预测。
输入向量 X ∈ R ( n x , N ) X \in R(n_x,N) X∈R(nx,N) 通过一个 Input Embedding 转移矩阵 W X ∈ R ( d , n x ) W^X \in R(d,n_x) WX∈R(d,nx) 得到一个张量 I ∈ R ( d , N ) I \in R(d,N) I∈R(d,N),再加上一个表示位置的 Positional Encoding E ∈ R ( d , N ) E \in R(d,N) E∈R(d,N) 得到新的张量 I ∈ R ( d , N ) I \in R(d,N) I∈R(d,N),然后进入重复 N 次的 Encoder Block。
Encoder Block 中,张量 I ∈ R ( d , N ) I \in R(d,N) I∈R(d,N) 先经过一个 MHA 输出 O ∈ R ( d , N ) O \in R(d,N) O∈R(d,N)。然后,通过 Add & Norm 层将 MHA 的输入 I ∈ R ( d , N ) I \in R(d,N) I∈R(d,N) 和输出 O ∈ R ( d , N ) O \in R(d,N) O∈R(d,N) 按元素相加,并进行 Layer Normalization。
- Layer Normalization 令 batch 内各 samples / features 的所有 channel 的 μ = 0 , σ = 1 \mu = 0, \sigma=1 μ=0,σ=1 (对 batch 内所有数据沿 sample 归一化)
接着,是一个 Feed Forward 前馈网络和一个 Add & Norm 层。
Transformer 的 Encoder Block 表达式为:
- 前 2 个 Layer 操作表达式为:

- 后 2 个 Layer 操作表达式为:
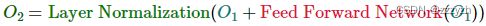
- 所有 Layer 简写为:

- Encoder Block 表达式为:

2.2. Decoder Block
Key, Value 和 Query 通过 Multi-Head Self-attention 结合在一起的过程,就相当于是 把需要的内容信息指导表达出来:
Key和Value来自Encoder的输出,所以可看做句子(Sequence)/图片 (Image)等的内容信息 (Content,比如句子含义是:“我有一只猫” / 图片内容是:“有几辆车,几个人等等”)。Query表达了一种诉求:希望得到 / 了解 / 寻求什么,可看做引导信息 (Guide)
Decoder Block 的输入包括 2 个来源,来自 Decoder Block 下方的输入是前一个 Time Step 的 Input Embedding,即前一个 Time Step 的 I ∈ R ( d , N ) I \in R(d,N) I∈R(d,N) 加上一个表示位置的 Positional Encoding E ∈ R ( d , N ) E \in R(d,N) E∈R(d,N) 所得的张量。然后,该张量进入了重复 N 次的 Decoder Block。
- Decoder 输出: (当前 Time Step) 对应位置 i i i 的输出词的概率分布。
- Decoder 输入: (当前 Time Step) 对应位置 i i i 的 Encoder 输出 + (前一 Time Step) 对应位置 i − 1 i-1 i−1 的 Decoder 输出。
- 所以中间的 Attention 不是 Self-attention,其 Key 和 Value 来自 Encoder 的输出,Query 来自上一位置 Decoder 的输出。
- Decoding 串行:
- 编码可并行计算,一次性全部 Encoding 出来
- 但解码不同,它是像 RNN 一样一个一个 Decoding 的,因为要用上一位置 Decoder 的输出当作当前位置 Attention 的 Query。
Decoder 包含的两个 Multi-Head Attention 层:
- 第一个 Multi-Head Attention 层采用了 Masked 操作
- Mask 旨在使注意力只关注已产生的 Sequence 而不含未产生的部分
- 因为训练时的 Output 都是 Ground Truth,这样可以确保预测第 i i i 个位置时不会接触到未来 i + 1 , i + 2 , . . . i+1, i+2, ... i+1,i+2,... 个位置的信息。
- Mask 旨在使注意力只关注已产生的 Sequence 而不含未产生的部分
- 第二个 Multi-Head Attention 层的 Key,Value 矩阵使用 Encoder 的编码信息矩阵 C 进行计算,而 Query 使用上一个 Decoder block 的输出计算
2.2.1. Masked Multi-Head Self-attention
Decoder 在组成上的主要的区别是:新增了 Masked Multi-Head Self-attention,在 Scale 操作后、Softmax 操作前。
训练时的 Output 都是 Ground Truth,这样可以确保预测第 i i i 个位置时不会接触到未来 i + 1 , i + 2 , . . . i+1, i+2, ... i+1,i+2,... 个位置的信息(因为不可能利用理论上未知的信息去训练已知的信息)。
在解码器中,Self-attention 层只被允许处理输出序列中更靠前的那些位置,在 Softmax 步骤前,它会把后面的位置给隐去。
在翻译任务中,翻译是按顺序的 —— 翻译完第 i i i 个单词,才可翻译第 i + 1 i+1 i+1 个单词。通过 Masked 操作可防止第 i i i 个单词不切实际地了解/接触到第 i + 1 i+1 i+1 个单词及之后的信息。下面以将 “我有一只猫” 翻译成 “I have a cat” 为例,说明 Masked 操作。Decoder 时,需根据之前的翻译,求解当前最可能的翻译(当前位置最大概率输)。

Transformer 测试 时的解码过程:
- 输入解码开始标志位 ,Decoder 输出 I
- 输入已解码的 , I,Decoder 输出 have
- 以此类推 …
- 输入已解码的 , I, have, a, cat,Decoder 输出解码结束标志位
- 总之,每次解码都会到利用先前已解码的所有单词嵌入信息
Masked Multi-Head Self-attention 的计算:
- Step1:
Input MatrixX ∈ R N , d x X\in R_{N,d_x} X∈RN,dx 包含 "I have a cat" (0, 1, 2, 3, 4) Mask Matrix是一个 5 × 5 5 \times 5 5×5 矩阵。在 其中可见解码单词 0 0 0 时只能使用单词 0 0 0 的信息,而解码单词 1 1 1 时可使用单词 0 , 1 0, 1 0,1 的信息 —— 只能使用先前的信息。Input MatrixX ∈ R N , d x X\in R_{N,d_x} X∈RN,dx 经过 3 个Transformation Matrix得到 3 个Matrix:QueryQ ∈ R N , d Q \in R_{N,d} Q∈RN,d,KeyK ∈ R N , d K \in R_{N,d} K∈RN,d 和ValueV ∈ R N , d V \in R_{N,d} V∈RN,d。 - Step2: Q T ⋅ K Q^T \cdot K QT⋅K 得到
Attention MatrixA ∈ R N , N A\in R_{N,N} A∈RN,N,此时先不进行 Softmax 操作,而是与一个 M a s k ∈ R N , N Mask \in R_{N, N} Mask∈RN,N 矩阵相乘,使Attention Matrix的部分位置(即相对当前位置的未来位置)为 0,得到Masked Attention MatrixM a s k A t t e n t i o n ∈ R N , N Mask \; Attention \in R_{N, N} MaskAttention∈RN,N。Masked Attention Matrix是个下三角矩阵,使得计算 Z 矩阵的某一行时,只考虑其前面token的作用 (即相对当前位置的先前位置) 。- 例如,在计算
Z的第一行时,刻意地把Attention Matrix第一行的后面所有元素屏蔽掉,只考虑 A 0 , 0 A_{0, 0} A0,0。在产生单词have时,则只考虑之前的I,不考虑之后的have、a、cat,即只attend on已产生的Sequence。这很合理,因为还没有产生出来的东西不存在,就无法做 Attention。
- 例如,在计算
- Step3:
Masked Attention Matrix进行 Softmax,所得矩阵的每一行之和都为 1(沿列方向按行归一化)。注意,单词 0 0 0 在单词 1 , 2 , 3 , 4 1, 2, 3, 4 1,2,3,4 上的Attention Score都为 0 0 0。所得矩阵再与矩阵 V V V 相乘得到最终的 Self-attention 层的输出结果 Z 1 ∈ R N , d Z_1 \in R_{N, d} Z1∈RN,d。 - Step4: Z 1 ∈ R N , d Z_1 \in R_{N, d} Z1∈RN,d 只是第 1 个
Head的结果,将多个Head的结果 Concat 一起后,再进行 Linear Transformation 得到最终的 Masked Multi-Head Self-attention 结果 L i n e a r T r a n s f o r m a i o n ( C o n c a t ( Z 1 , Z 2 , . . . , Z n ) ) = Z ∈ R N , d Linear \; Transformaion (Concat (Z_1, Z_2, ... , Z_n)) = Z \in R_{N, d} LinearTransformaion(Concat(Z1,Z2,...,Zn))=Z∈RN,d。

此外,需注意的是:第 1 个 Masked Multi-Head Self-attention 的 Query,Key,Value 均来自 Output Embedding;
而第 2 个 Multi-Head Self-attention 的 Query 来自第 1 个 Self-attention 层的输出,Key 和 Value 来自 Encoder 的输出。
总结
对 Self-Attention 来说,它跟每一个 input vector 都做 attention,所以没有考虑到 input sequence 的顺序,虽然引入了 Positional Encoding 来解决问题,但仍有不足。同时,它需要的运算量是十分庞大的。本文主要在于介绍有关 Self-Attention 的知识,为后面的模型学习做铺垫。
参考视频