Python爬取CCTV视频
文章目录
- 前言
- 一、需求
- 二、分析
-
- 微视频
- 长视频
- 三、处理
- 四、运行效果
前言
为了更好的掌握数据处理的能力,因而开启Python网络爬虫系列小项目文章。
- 小项目小需求驱动,每篇文章会使用两种以上的方式(Xpath、Bs4、PyQuery、正则等)获取想要的数据。
- 博客系列完结后,将会总结各种方式。
一、需求
- 爬取微视频
- 爬取长视频
二、分析
微视频
1、进入微视频首页
https://tv.cctv.com/wsp/m/index.shtml?spm=C55953877151.PPxD9oncpP6r.E2PQtIunpEaz.70
2、打开浏览器F12抓包工具
3、重新刷新微视频首页
4、分析getHttpVideoInfo.do接口
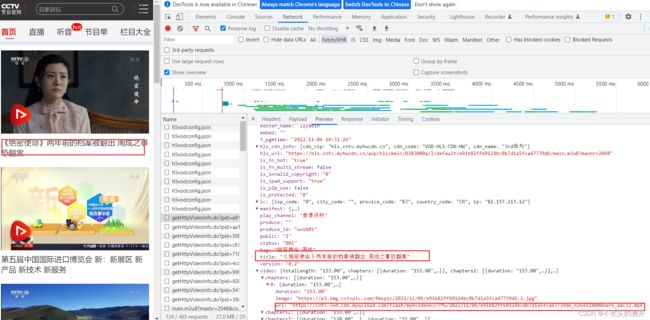
照猫画虎,根据getHttpVideoInfo.do请求参数,Python通过requests请求,即可拿到视频的mp4下载的地址。
长视频
1、进入要爬取长视频的首页
2、打开浏览器F12抓包工具
3、重新刷新该首页
4、分析getHttpVideoInfo.do接口

- 接口中有视频mp4下载地址,被切成一个个小视频
-异步协程下载mp4资源
-利用第三方库natsort排序下载的mp4文件
-通过第三方库 moviepy合成视频
1、进入要爬取长视频的首页
2、打开浏览器F12抓包工具
3、重新刷新该首页
4、分析1200.m3u8文件,以及一个个.ts文件资源


看到m3u8文件没有加密,又有ts下载地址,觉得很轻松就可以获取资源,但是最后爬取一个个ts文件时,发现是雪花的视频,说明资源地址有问题(迷惑操作)
| 抓包显示地址 | |
|---|---|
| https://dh5.cntv.myhwcdn.cn/asp/h5e/hls/2000/0303000a/3/default/a69b6421640c4dd69ac5c5c4a33ea316/0.ts |

回到getHttpVideoInfo.do接口
找到hls_url(即真实的m3u8地址)
访问该url,再获取一个个ts文件地址

| 真实的地址 | |
|---|---|
| https://hlswx.cntv.kcdnvip.com/asp/hls/1200/0303000a/3/default/a69b6421640c4dd69ac5c5c4a33ea316/0.ts |
- 异步协程获取一个个ts文件
- 合并一个个ts文件(copy 方法)
三、处理
微视频下载
# -*- encoding:utf-8 -*-
__author__ = "Nick"
__created_date__ = "2022/11/06"
import requests
import json
HEADERS = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"}
def get_video_url(url):
r = requests.request("GET",url=url,headers=HEADERS)
res = json.loads(r.text,encoding="utf-8")
video_list = []
video_dict = res['video']
# print(video_dict)
for k,v in video_dict.items():
# 处理值,保留list类型
if type(v) is list:
# chapters内含video处理
for i in range(len(v)):
# 去重
if v[i]["url"] not in video_list:
video_list.append(v[i]["url"])
return video_list
def download_video(video_list):
for url in video_list:
url_name = url.split("_")[-1]
res = requests.request("GET",url,headers=HEADERS).content
with open(f"video/{url_name}","wb") as f:
f.write(res)
print(f"{url_name}下载中....")
print("下载完!")
if __name__ == '__main__':
url = "https://vdn.apps.cntv.cn/api/getHttpVideoInfo.do?pid=6c824582e5dd44d6a92018613da15b9d&client=flash&im=0&tsp=1667481442&vn=2049&vc=DAD250B0679F5E3539126FCA3F272FC2&uid=F9DD59FD4EF9A4EEB7C0E83B8F83CDD1&wlan="
url_list = get_video_url(url=url)
长视频解决思路一(通过合并mp4文件)
第三方库(aiofiles、aiohttp、moviepy 、natsort)
"""
异步协程下载mp4资源
"""
import asyncio
import aiohttp
import aiofiles
HEADERS = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"}
async def download_video(url,sem):
try:
async with sem:
file_name = url.split("a69b6421640c4dd69ac5c5c4a33ea316")[-1]
async with aiohttp.ClientSession() as session:
# 发送请求
async with session.get(url,headers=HEADERS) as res:
content = await res.content.read()
# 异步写入文件
async with aiofiles.open(f"video/{file_name}",mode='wb') as f:
await f.write(content)
print(f"{file_name}下载成功")
except Exception as e:
print("出错了",e)
async def main(video_list):
# 添加信号线
sem = asyncio.Semaphore(100)
tasks= []
for url in video_list:
task = asyncio.create_task(download_video(url,sem))
tasks.append(task)
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main(url_list))
from moviepy.editor import *
import os
from natsort import natsorted
def filter_matching_files(path, start=None, end=None):
'''
path-文件夹路径;
start—以某种字符开头的字符串;
end—以某种字符结尾的字符串'''
files_list = []
for root, dirs, files in os.walk(path):
for file in files:
file_abs_path = os.path.join(root, file)
if start is None:
if end:
if file.endswith(end):
files_list.append(file_abs_path)
elif start:
if end is None:
if file.startswith(start):
files_list.append(file_abs_path)
elif end:
if file.startswith(start) & file.endswith(end):
files_list.append(file_abs_path)
else:
continue
return files_list
#定义合并的视频
def concat_video(in_path, out_path, file_name=None, start=None, end=None):
'''
in_path—输入的文件夹路径;
out_path—输出的文件夹路径;
file_name—合并后的文件名称(需要加后缀);
start—以某种字符开头的字符串;
end—以某种字符结尾的字符串'''
video_list = []
files_list = filter_matching_files(in_path, start, end)
# 对文件进行排序
files_list = natsorted(files_list)
for file in files_list:
video = VideoFileClip(file)
video_list.append(video)
video_result = concatenate_videoclips(video_list)
# 输出的完整路径
if file_name is None:
file_name = "video.mp4"
file_abs_path = os.path.join(out_path, file_name)
video_result.write_videofile(file_abs_path,codec="mpeg4",bitrate='4000k')
长视频解决思路二(通过合并ts文件)
"""
异步下载ts资源文件
"""
import asyncio
import aiohttp
import aiofiles
HEADERS = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
"referer":"https://tv.cctv.com/"}
async def download_one(url,sem):
try:
async with sem:
file_name = url.split("/")[-1]
async with aiohttp.ClientSession() as session:
# 发送请求
async with session.get(url,headers=HEADERS) as res:
content = await res.content.read()
# 异步写入文件
async with aiofiles.open(f"video1/{file_name}",mode="wb") as f:
await f.write(content)
print(f"{file_name}下载成功")
except Exception as e:
print(e)
async def download_all():
# 信号量
sem = asyncio.Semaphore(100)
tasks = []
for i in range(462):
url = f"https://hlswx.cntv.kcdnvip.com/asp/hls/1200/0303000a/3/default/a69b6421640c4dd69ac5c5c4a33ea316/{i}.ts"
task = asyncio.create_task(download_one(url,sem))
tasks.append(task)
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(download_all())
import os
"""
合并ts文件的方法
"""
# 合并ts
def merge():
# 列表生成器生成文件名列表
movie_list = [ f"{i}.ts" for i in range(462)]
# 进入文件夹内
os.chdir("./video1")
# 分段合并
n = 462
temp = []
for i in range(len(movie_list)):
file_name = movie_list[i]
temp.append(file_name)
if i != 0 and i % 20 == 0:
# 可以合并一次了
cmd = f"copy /b {'+'.join(temp)} {n}.ts"
r = os.popen(cmd)
print(r.read())
temp = [] # 新列表
n = n + 1
# 需要把剩余的ts进行合并
cmd = f"copy /b {'+'.join(temp)} {n}.ts"
r = os.popen(cmd)
print(r.read())
n = n + 1
# 第二次大合并
last_temp = []
for i in range(462, n):
last_temp.append(f"{i}.ts")
# 最后一次合并
cmd = f"copy /b {'+'.join(last_temp)} 开学第一课.mp4"
r = os.popen(cmd)
print(r.read())
# 回来
os.chdir("../")
四、运行效果
合并mp4文件效果
1、比较慢(三分钟合并)
2、合成的视频受损(1多个G)
合并ts效果
快(30s不到)
受损小(722Mb并还原了高清画质)
完整的源码在免费知识星球中获取
我正在「Print(“Hello Python”)」和朋友们讨论有趣的话题,你⼀起来吧?
https://t.zsxq.com/076uG3kOn