Zero-shot Learning零样本学习 论文阅读(一)——Learning to detect unseen object classes by between-class attribute
Zero-shot Learning零样本学习 论文阅读(一)——Learning to detect unseen object classes by between-class attribute transfer
- 算法概要
-
- 前提
- 目标
- 思路
- 具体原理
-
- DAP(Directed attribute prediction)
- IAP(Indirected attribute prediction)
Learning to detect unseen object classes by between-class attribute这篇文章首次提出了Zero-shot Learning这一问题的概念,并给出了基于物体属性的解决方法。
算法概要
前提
( x 1 , l 1 ) , ⋯ , ( x n , l n ) (x_1,l_1),\cdots,(x_n,l_n) (x1,l1),⋯,(xn,ln)为训练样本 x x x和相应类别标签 l l l,这样的成对数据共有 n n n组, l l l中一共有 K K K类,用 Y = { y 1 , ⋯ , y K } Y=\{y_1,\cdots,y_K\} Y={y1,⋯,yK}表示, Z = { z 1 , ⋯ , z L } Z=\{z_1,\cdots,z_L\} Z={z1,⋯,zL} 为测试集中所包含的 L L L个类别,这里 Y Y Y和 Z Z Z就分别是可见类和不可见类,二者之间没有交集.
目标
学习一个分类器: f : X → Z f:X\rightarrow Z f:X→Z,也就是通过学习分类器,找到训练数据 x x x和相应可见类别标签 l l l与位置类别标签 Z Z Z之间的关系。
思路
通过建立一个人工定义的属性层A,这个属性层是高维的、可以表征训练样本的各项特征,比如颜色、条纹等,目的是将基于图片的低维特征分类器转化到一个表征高维语义特征的属性层。这样可以使得分类器分类能力更广,具备突破类别边界的可能。
基于这个思路,作者提出了两种方法,分别是DAP和IAP.
具体原理
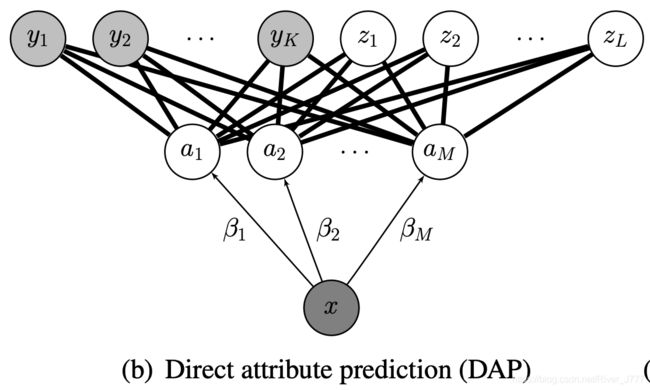
DAP(Directed attribute prediction)
如下图,DAP在样本和训练类别标签之间加入了一个属性表示层A, a a a为 M M M维属性向量 ( a 1 , ⋯ , a M ) (a_1,\cdots,a_M) (a1,⋯,aM),每一维代表一个属性,且在 { 0 , 1 } \{0,1\} {0,1}之间取值,对于每个标签都对应一个M维向量作为其属性向量(原型)。通过训练集 X X X的对应属性进行训练,学习得到属性层的参数 β \beta β,之后便可以得到 P ( a ∣ x ) P(a|x) P(a∣x),
将输入测试实例x输出的标签作为待估计的参数,对于测试实例x,即可利用MAP的思想,找出概率最大的类为输出的估计类。
MAP的原理见此链接https://blog.csdn.net/River_J777/article/details/111500068
z的后验概率为:
p ( z ∣ x ) = ∑ a ∈ { 0 , 1 } M p ( z ∣ a ) p ( a ∣ x ) p(z \mid x)=\sum_{a \in\{0,1\}^{M}} p(z \mid a) p(a \mid x) p(z∣x)=a∈{0,1}M∑p(z∣a)p(a∣x)
根据贝叶斯公式:
= ∑ a ∈ { 0 , 1 } M p ( a ∣ z ) p ( z ) p ( a ) p ( a ∣ x ) =\sum_{a \in\{0,1\}^{M}} \frac{p(a \mid z) p(z)}{p(a)} p(a \mid x) =a∈{0,1}M∑p(a)p(a∣z)p(z)p(a∣x)
根据文章中的假设前提各个维度属性条件独立(这个假设有点过强也是DAP主要问题所在)
= ∑ a ∈ { 0 , 1 } M p ( a ∣ z ) p ( z ) p ( a ) ∏ m = 1 M p ( a m ∣ x ) =\sum_{a \in\{0,1\}^{M}} \frac{p(a \mid z) p(z)}{p(a)} \prod_{m=1}^{M} p\left(a_{m} \mid x\right) =a∈{0,1}M∑p(a)p(a∣z)p(z)m=1∏Mp(am∣x)
根据Iverson bracket [ [ x ] ] [[x]] [[x]],若其中语句为真则为1,否则为0,得 p ( a ∣ z ) = [ [ a = a z ] ] p(a \mid z)=\left[\left[a=a^{z}\right]\right] p(a∣z)=[[a=az]] ,可得:
= ∑ a ∈ { 0 , 1 } M p ( z ) p ( a ) [ [ a = a z ] ] ∏ m = 1 M p ( a m ∣ x ) =\sum_{a \in\{0,1\}^{M}} \frac{p(z)}{p(a)}\left[\left[a=a^{z}\right]\right] \prod_{m=1}^{M} p\left(a_{m} \mid x\right) =a∈{0,1}M∑p(a)p(z)[[a=az]]m=1∏Mp(am∣x)
由DAP的图模型知 p ( a z ) = p ( a ) p\left(a^{z}\right)=p(a) p(az)=p(a),可得:
= ∑ a ∈ { 0 , 1 } M p ( z ) p ( a z ) [ [ a = a z ] ] ∏ m = 1 M p ( a m ∣ x ) =\sum_{a \in\{0,1\}^{M}} \frac{p(z)}{p\left(a^{z}\right)}\left[\left[a=a^{z}\right]\right] \prod_{m=1}^{M} p\left(a_{m} \mid x\right) =a∈{0,1}M∑p(az)p(z)[[a=az]]m=1∏Mp(am∣x)
整理得:
= p ( z ) p ( a z ) ∑ a ∈ { 0 , 1 } M [ [ a = a z ] ] ∏ m = 1 M p ( a m ∣ x ) =\frac{p(z)}{p\left(a^{z}\right)} \sum_{a \in\{0,1\}^{M}}\left[\left[a=a^{z}\right]\right] \prod_{m=1}^{M} p\left(a_{m} \mid x\right) =p(az)p(z)a∈{0,1}M∑[[a=az]]m=1∏Mp(am∣x)
省略掉为零的项:
= p ( z ) p ( a z ) ∏ m = 1 M p ( a m z ∣ x ) =\frac{p(z)}{p\left(a^{z}\right)} \prod_{m=1}^{M} p\left(a_{m}^{z} \mid x\right) =p(az)p(z)m=1∏Mp(amz∣x)
表示出z的后验概率后,对于输入测试实例x进入分类器后,分别测试不可见标签集 z 1 , ⋯ , z l z_1,\cdots,z_l z1,⋯,zl,求最大:
f ( x ) = argmax l = 1 , 2 , … … L p ( z ) p ( a z l ) ∏ m = 1 M p ( a m z l ∣ x ) f(x)=\operatorname{argmax}_{l=1,2, \ldots \ldots L \frac{p(z)}{p\left(a^{z_{l}}\right)}} \prod_{m=1}^{M} p\left(a_{m}^{z_{l}} \mid x\right) f(x)=argmaxl=1,2,……Lp(azl)p(z)m=1∏Mp(amzl∣x)
根据属性之间独立:
= argmax l = 1 , 2 , … . . L ∏ m = 1 M p ( a m z l ∣ x ) ∏ m = 1 M p ( a m z l ) =\operatorname{argmax}_{l=1,2, \ldots . . L} \frac{\prod_{m=1}^{M}p\left(a_{m}^{z_{l}} \mid x\right)}{\prod_{m=1}^{M}p\left(a_{m}^{z_{l}}\right)} =argmaxl=1,2,…..L∏m=1Mp(amzl)∏m=1Mp(amzl∣x)
= argmax l = 1 , 2 , … . . L ∏ m = 1 M p ( a m z l ∣ x ) p ( a m z l ) =\operatorname{argmax}_{l=1,2, \ldots . . L} \prod_{m=1}^{M} \frac{p\left(a_{m}^{z_{l}} \mid x\right)}{p\left(a_{m}^{z_{l}}\right)} =argmaxl=1,2,…..Lm=1∏Mp(amzl)p(amzl∣x)
f ( x ) f(x) f(x) 的输出即为对于输入x的预测标签.
IAP(Indirected attribute prediction)
区别于DAP,DAP的PGM中属性层是在实例层和标签层(包括可见和不可见)之间,而IAP则是将属性层置于可见标签层与不可见标签层之间,用来迁移可见类标签与实例的信息到不可见标签层。

原理和DAP类似,此时的后验概率为:
p ( a m ∣ x ) = ∑ i = 1 K p ( a m ∣ y k ) p ( y k ∣ x ) p\left(a_{m} \mid x\right)=\sum_{i=1}^{K} p\left(a_{m} \mid y_{k}\right) p\left(y_{k} \mid x\right) p(am∣x)=i=1∑Kp(am∣yk)p(yk∣x)
得到这个后验后,再求出z的后验,即可如同DAP中一样应用MAP即可.