Prompt Learning - 1:继 Fine-Tuning 之后的最新范式不再神秘
本文内容主要参考刘鹏飞博士在 Big Model Meetup 上的报告内容以及其发表的关于 Prompt Learning 的综述论文 《Pre-train, Prompt, and Predict A Systematic Survey of Prompting Methods in Natural Language Processing》
Big Model Meetup 报告链接:智源社区活动
论文链接:https://arxiv.org/pdf/2107.13586.pdf
本文目前算法工程师一枚,重点关注 预训练语言模型、文本语义相似性检测、命名实体识别、Prompt Learning 领域研究,后续会陆续更新更多文章,欢迎关注 ^_^
如果对于本文章的内容存在疑问或问题,欢迎留言或发邮件,看到后会第一时间回复,Email:[email protected]
1. 什么是 Prompt?
在过去很长一段时间,预训练模型均是采用的 Pretrain+Fine-Tuning 的方式来适配下游任务,但是采用这种方式所带来的问题是对于每一项下游任务来说,都需要重新 Fine-Tune 一个新的模型,且具体任务的模型之间无法共用,这对于预训练语言模型来说,相当于对于每一个任务都进行了定制化,十分低效;而 Prompt Tuning 则是一种新的训练模式,即可以将预训练模型看做是电源,不同的下游任务则相当于用电器,此时依据下游任务的不同,只需要为预训练模型插入不同的插座(下游任务特定的 Prompt 参数),即可使预训练模型适配下游任务;
上述 Prompt Tuning 的方式极大地提升了预训练模型的使用效率,如下图所示:

- 左侧的图表示基于 Pretrain+Fine-Tuning 的训练范式,即对于不同的下游任务来说,均需要训练不同的模型,每个任务都会有一套完全独立的模型参数,任务模型之间相互独立;
- 右侧的图表示基于 Prompt Tuning 的训练范式,即对于不同的任务来说,只需要插入不同的 Prompt 参数,在训练期间可以灵活选择是否对预训练语言模型的参数进行调整,可以极大地缩短训练时间,提升模型使用率;
所谓 Prompt,从字面意思上来讲翻译为 “提示”,联想人类的思维过程,假如我们某一天忘记了某件事情,如果此时能够得到某种特定的提示,就可以轻松想起来对应的事情,比如给出我们提示 “白日依山尽”,我们自然而然的就会联想到下一句 “黄河入海流”;再比如,我们玩儿 “你画我猜” 这样的游戏,假如直接让我们猜一幅画,这对于我们来说很困难,但是如果给出别人画的提示呢?如果再进一步给出一个与这幅画相关的提示词呢?是不是就变得越来越容易啦?
那么在 NLP 的领域研究中,Prompt 就是指根据输入文本,给予预训练语言模型一个任务相关的线索或提示,以帮助模型能够更好的理解或记忆特定的人类问题; 比如,BERT、BART、ERINE 均为近些年饱受关注的预训练模型,其对于某些特定的人类问题,根据给出的线索均可以给出正确的答案,如下图所示:
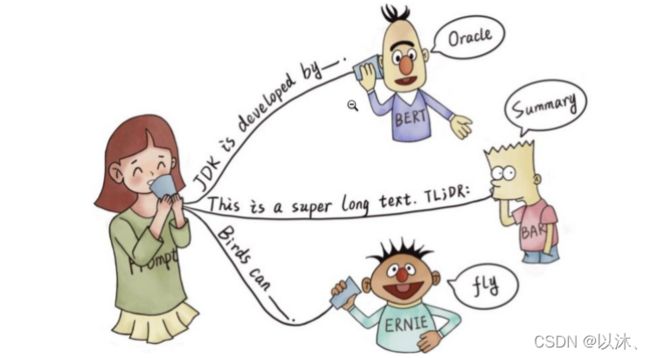
在上图的示例中,根据提示,BERT 可以准确的给出答案: JDK 是由 Oracle 研发的;根据 TL;DR: 提示,BART 可以知道当前任务需要给出文章的摘要信息,另外,根据提示 ERINE 可以知道当前 Query 想问的是鸟类的能力;
除了上述较为形象的表述之外,Prompt 更加严谨的表述方式如下:
Prompt is the technique of making better use of the knowledge from the pre-trained model by adding additional texts to the input.
即通过为输入内容添加额外的文本(重新定义任务)的方式,来更好的挖掘预训练语言模型本身能力的一种方法;
2. Prompt 工作流
通常来说,Prompt Tuning 的工作流主要分为四个部分:模板构造、答案空间映射关系构造、将输入带入至模板并预测、预测结果映射; 以情感分析任务为例,Prompt Tuning 的不同工作模块如下图所示:
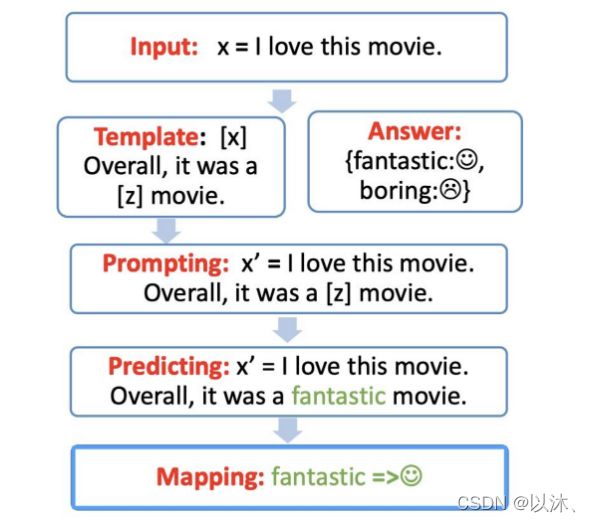
上图展示了在情感分析任务中,Prompt Tuning 范式在情感分析任务中的具体工作模块,下面将会将各个模块拆解进行说明:
2.1 Prompt 模板构造
在进行 Prompt 之前,需要先为下游任务构造一个模板(Template),其作用主要是对输入和输出进行重新构造,使其变成一个新的、带有 mask slots 的文本,即对应的模板中带有 2 处填入的 slots:[x] 和 [z],其中 [x] 位置用来填入输入文本,[z] 位置则用来填入预训练语言模型预测的结果;
例如,在电影评论分析任务中,输入 x = “我喜欢这个电影”,模板就可以定义为:“[x] 总而言之,它是一个 [z] 电影”,将输入 x 带入上述模板,即可得到 “我喜欢这个电影,总而言之,它是一个 [z] 电影”,如下图所示:
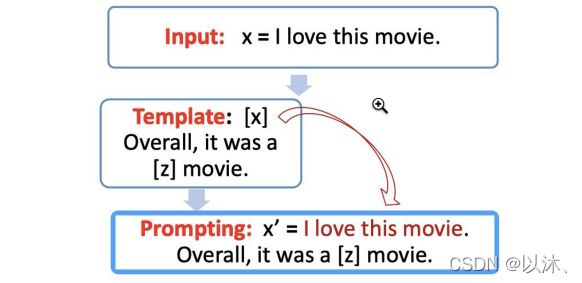
2.2 Prompt 答案空间映射关系构造
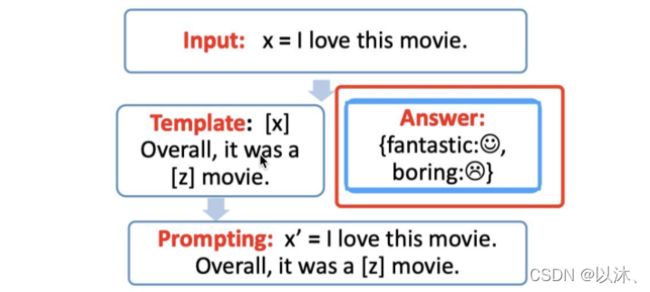
在利用 Prompt Tuning 的手段执行特定的下游任务过程中,任务的标签空间是固定的,而预训练语言模型预测的空间更大,但也不可能定义 [z] 位置的预测结果是任意词,所以需要一个映射关系将模型在位置 [z] 得到的预测结果和任务的标签集合联系起来,比如在上述情感分析任务中,任务的标签集合为:”positive” 和 “negative”,此时即可定义模型的输出结果和标签集合存在映射关系:”fantastic → positive”,”boring → negative”;当然,这里的映射关系也可以是多对一的,如下图所示:
2.3 利用预训练模型预测结果
针对下游任务定义完 Template 和 答案映射关系 后,即可选择合适的预训练语言模型对 [z] 位置的词汇进行预测,比如在下图的例子中,模型给出的结果为 “fantastic”,此时将这一结果带入 [z] 位置;

2.4 预测结果映射
在这一步骤中,需要根据第二步中定义的映射关系,将预训练语言模型给出的预测结果映射回对应的任务标签,即在上面的例子中,将预训练模型预测的结果 “fantastic” 映射回任务集合中的 “positive” 标签;
总体来说,在 Prompt Learning 的过程中,总共包含如下信息:

3. 关于 Prompt Tuning 比 Fine Tuning 更加繁琐的讨论
针对这一问题,实际情况是,Fine-Tuning 范式无需使用任何人工特征构造过程,即特征工程;而 Prompt-based 方法无疑是增加了许多人工参与的过程,回顾 Prompt Learning 的整个过程,可以发现其需要人工参与的部分主要包括:(1) Template 的构造;(2) Answer 映射关系构造;(3) 预训练模型选择;(4) Prompt 组合问题选择;(5) 训练策略选择;下面将会针对上述各个不同的部分进行独立分析;
3.1 Prompt 模板工程
关于如何构造特定任务的 Template 是 Prompt Learning 是否有效的关键,即便是针对同一种任务,不同的人可能都会构造出不同的 Template 结果,如下图所示:
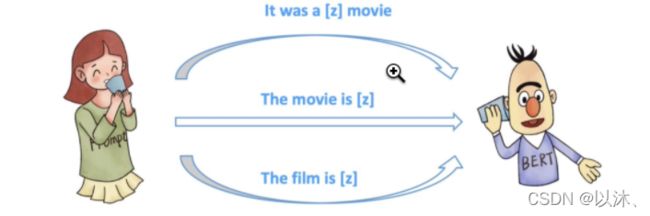
通常来说,人工构造出来的每一种模板基本都有其合理性,但是在实际使用中,Template 的选择对于 Prompt Learning 而言则起到了巨大的作用,即便是一个 word 的区别,也可能会导致巨大的效果差距,比如在论文 GPT Understands, Too 中,给出了如下实验结果:

从上述结果中,可以发现,即便是对于人类来说完全类似的模板,其作用在 Prompt Tuning 上,最终得到的结果也会具有巨大的差距;所以,Prompt 模板的定义对于 Prompt Learning 的工作至关重要,回顾之前的工作,Template 的设计主要可以从两个角度进行区分:
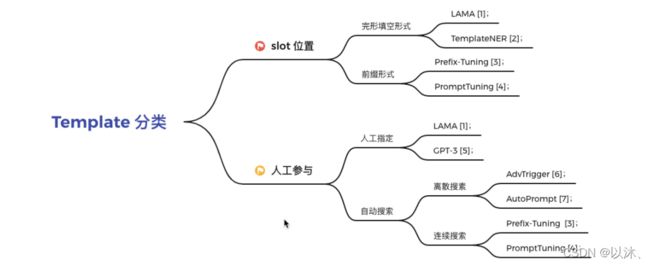
根据 slot 的位置进行区分
- 完形填空 (cloze) 模式:即未知的 slot 在 Template 中间等不定位置;
- 前缀 (prefix) 模式:即未知的 slot 在 Template 开头;
根据是否需要人工指定进行区分
- 人工指定:即由人工的方式根据下游任务的特点指定对应的 Template;
- 自动搜索:即无需人工定义,由模型来确定使用的 Template 形式,这种方式又可以分为离散的 Template 和连续的 Template;
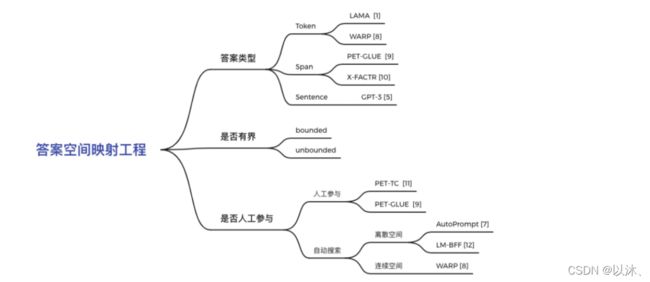
3.2 答案空间映射工程
除了上述 Template 工程之外,如何对下游任务的 Label 空间和 Answer 空间进行映射也包含许多不同的方法。比如在上述情感分析任务中,任务的 Label 空间 Y 为 {positive, negative},Prompt 的答案空间 Z 可以是表示 “positive” 和 “negative” 的词汇,比如:”interestring / fantastic / happy / boring / bad” 等,可以根据任务设计一个 y 对应 1~n 个答案词汇;
如果对答案空间映射方法进行分类,主要可以从如下几个角度进行分类:
根据答案的形状进行分类
1. 从 Token 的粒度进行构建; 2. 从 Span 的粒度进行构建; 3. 从 Sentence 的粒度进行构建;
根据答案的空间是否有界进行分类
1. 有界; 2. 无界;
根据是否有人工参与进行分类
1. 人工选择; 2. 自动搜索方法:分为离散空间搜索和连续空间搜索两类;
3.3 预训练模型的选择
在上述步骤定义完模板以及答案空间后,需要选择合适的预训练语言模型对 Prompt 进行预测,如何选择更加合适的预训练语言模型也需要人工经验进行判别,具体来说现有的预训练语言模型主要分为如下五类:
- Autoregressive Models,自回归语言模型:代表为 GPT,主要用于生成式任务;
- AutoEncoding Models,自编码语言模型:代表为 BERT,主要用于自然语言理解任务;
- Seq-to-seq Models,端到端语言模型:代表为 BART、MASS,即序列到序列的结构,模型同时包含 Encoder 和 Decoder 结构,主要用于基于条件的生成式任务,如机器翻译、自动摘要生成等;
- MultiModal Models:即多模态模型;
- retrieval-based Models:基于召回的语言模型,主要用于开放域问答任务;
3.4 范式拓展
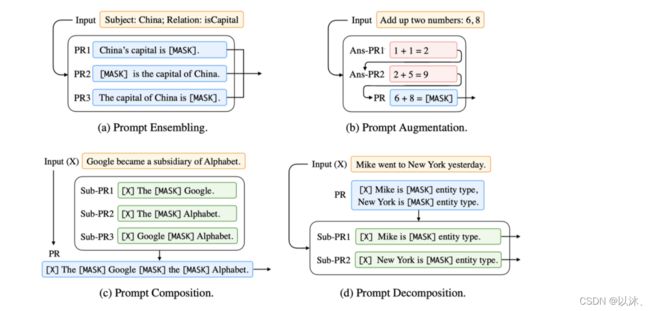
这部分的工作主要是探讨如何对已有的 Prompt 进行任务增强及拓展,具体可以从如下几个方面进行探讨:
- Prompt Ensemble:Prompt 集成方法,即采用多种方式询问同一种问题,如下图 (a) 所示;
- Prompt Augmentation:Prompt 增强方法,即采用类似的 Prompt 增强当前的 Prompt,如下图 (b) 所示;
- Prompt Composition:Prompt 组合方法,比如多个任务组合为一个Prompt,如下图 (c) 所示;
- Prompt Decomposition:Prompt 拆分方法,即将一个 Prompt 拆分为多个 Prompt,假如判别两个实体之间是否为父子关系,首先对于当前输入的每一个实体使用 Prompt 方法判定是否为人物,然后再进行实体关系预测,如下图 (d) 所示;
3.5 Prompt 的训练策略选择
在 Prompt Tuning 的训练过程中,具有多种不同的训练策略,比如可以根据训练数据的多少分为三类:
- Zero-shot Learning:即对于下游任务来说,没有任何训练数据;
- Few-shot Learning:对于下游任务来说只有很少的训练数据,比如只有 100 条;
- Full-data Learning:下游任务有很多训练数据;
除了上述分类方式之外,也可以根据参数更新的方式进行分类,即在 Prompt-based 模型中,主要分为两大块:预训练模型和Prompt参数,这两大部分均可以独立的训练参数,比如对于预训练模型来说,可以选择优化参数或不优化,再或者对于 Prompt 参数来说,可以是没有 Prompt 参数、固定的离散字符的 Prompt(无参数)、使用训练好的 Prompt 参数(不再优化Prompt参数)、继续训练 Prompt 参数,这一体系的分类如下图所示:
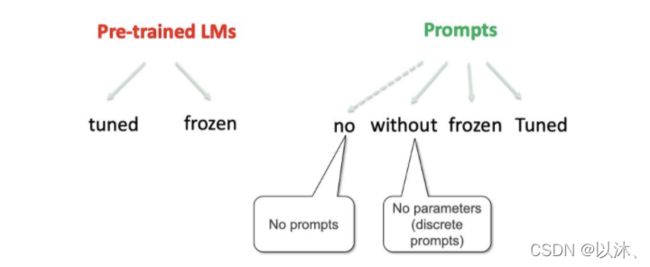
上述训练策略均可以两两进行组合,从而形成各种不同的参数优化策略,比如:
- Prompt-Less Fine-Tuning:即只有预训练模型,没有 Prompt 参数,在模型的训练过程中对预训练模型的参数进行 Fine-Tuning,即属于 BERT 的常规使用;
- Fixed-Prompt Tuning:这种方式包括两种组合形式,即在训练的过程中 Fine-Tuning 预训练模型的参数,然后 Prompt 的部分引入离散的固定 Prompt 或引入连续训练好的固定 Prompt 参数;
- Prompt + LM Fine-Tuning:即在训练的过程中 Fine-Tuning 预训练模型的参数并且 Prompt 部分的参数也同样进行更新;
- Adapter Tuning:即在训练的过程中固定住预训练模型的参数,并且不引入 Prompt 参数,只是插入 task-specific 模块到预训练模型中;
- Tuning-free Prompting:同样包含两种组合形式,即使用固定住的预训练模型参数并引入离散的固定 Prompt 或引入连续训练好的固定 Prompt 参数;
- Fix-LM Prompt Tuning:即使用固定住的预训练模型参数以及可训练的 Prompt 参数;
对于不同的策略来说,需要进行不同的选择,一般需要考虑如下两点:
- 数据量级的大小;
- 是否有一个超大的 left-to-right 语言模型
即如果有很少的训练数据,一般来说我们希望不要 Fine-Tuning 预训练语言模型,而是使用超强的 LM 能力来调整 Prompt 参数;当数据量比较多的时候,则可以去精调语言模型;
4. Prompt 的优势
Prompt Learning 的优势主要可以从四个角度进行分析,即:1. Prompt Learning 的角度;2. Prompt Learning 和 Fine-Tuning 的区别;3. 现代 NLP 历史; 4. 超越 NLP 的角度;
4.1 Prompt Learning 的角度:使所有下游任务统一为一个语言模型问题
Prompt Learning 范式可以将几乎所有的下游任务均统一为预训练语言模型任务,从而避免了预训练模型和下游任务之间存在的 gap,几乎所有的下游 NLP 任务均可以使用,不需要训练数据,在小样本数据集的基础上也可以取得超越 Fine-Tuning 的效果,使得所有任务在使用方法上变得更加一致;
4.2 Prompt Learning 和 Fine-Tuning 方法的区别
- Fine-Tuning 的方法使得预训练语言模型更加适配特定的下游任务,即可以理解为预训练模型向下游任务靠拢的过程;
- Prompt Learning 可以理解为一种下游任务的重定义方法,即可以更好的利用预训练模型的能力,使得下游任务更加贴近于语言模型;
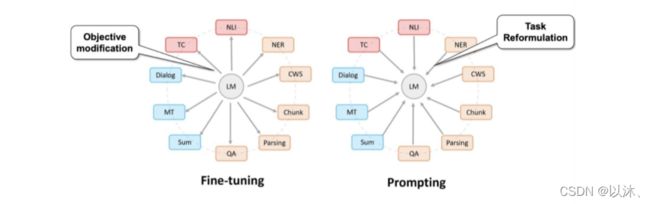
4.3 现代 NLP 的历史角度
Prompt Learning 的方法可以作为现代 NLP 领域的第四范式,四种范式包括:
1. 基于特征工程的传统模型:即使用文本特征,比如词性、长度等,使用机器学习的方法进行模型训练;
2. 基于神经网络的模型:即基于预训练的词向量特征,利用神经网络模型,在下游任务数据的基础上进行模型训练;
3. 基于预训练模型的 Fine-Tuning 模型:即在预训练模型的基础上,在下游任务数据的基础上对模型参数进行微调训练;
4. 基于 Prompt 的模型:直接根据下游任务设计 Prompt,辅助以特定的预训练模型,拉进下游任务和预训练模型之间的 gap;
即在上述范式中,预训练语言模型和下游任务之间的距离变得越来越近,直到最终的 Prompt 方法令下游任务完全利用预训练语言模型的能力;
4.4 从超越 NLP 领域的角度
Prompt Learning 方法可以作为连接多模态的一个契机,比如 CLIP 模型,连接了文本和图像,相信在未来还可以连接声音和视频;
5. 参考文献
[1] Language models as knowledge bases?, In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP);
[2] Template-based named entity recognition using bart, Leyang Cui, Yu Wu, Jian Liu, Sen Yang, and Yue Zhang. 2021.
[3] Prefix-tuning: Optimizing continuous prompts for generation, Xiang Lisa Li and Percy Liang. 2021.
[4] PromptTuning:The power of scale for parameter-efficient prompt tuning, Brian Lester, Rami Al-Rfou, and Noah Constant. 2021.
[5] GPT-3:Language models are few-shot learners, Tom B Brown, Benjamin Mann, Nick Ryder, etc. 2020.
[6] AdvTrigger:Universal adversarial triggers for attacking and analyzing NLP, Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, and Sameer Singh. 2019a.
[7] AutoPrompt:Eliciting knowledge from language models with automatically generated prompts, Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, and Sameer Singh. 2020.
[8] Warp: Word-level adversarial reprogramming, Karen Hambardzumyan, Hrant Khachatrian, and Jonathan May. 2021.
[9] It’s not just size that matters: Small language models are also few-shot learners, Timo Schick and Hinrich Schu ̈tze. 2021b.
[10] X-FACTR:Multilingual factual knowledge retrieval from pretrained language models, Zhengbao Jiang, Antonios Anastasopoulos, Jun Araki, Haibo Ding, and Graham Neubig. 2020a.
[11] Exploiting cloze questions for few shot text classification and natural language inference, Timo Schick and Hinrich Schu ̈tze. 2021a.
[12] Making pre-trained language models better few-shot learners, Tianyu Gao, Adam Fisch, and Danqi Chen. 2021.