论文笔记(综述):Deep Learning-based Multi-focus Image Fusion: A Survey and A Comparative Study
- 论文链接:https://ieeexplore.ieee.org/abstract/document/9428544/
- 以下为原文内容的整理与翻译
摘要(Abstract)
- 背景
多聚焦图像融合(Multi-focus image fusion (MFIF))是图像处理中的一个重要领域。自2017年以来,深度学习(deep learning has)已被引入MFIF领域,并提出了各种方法。然而,缺乏详细讨论基于深度学习的MFIF方法的调查论文。 - 本文工作
- 详细调查基于深度学习的MFIF算法,包括方法、数据集和评估指标
- 比较基于深度学习的MFIF算法(deep learning-based MFIF algorithms)与传统MFIF方法(conventional MFIF approaches)的性能
- 通过对定性和定量结果的分析,我们对MFIF的现状进行了一些观察,并讨论了该领域的一些未来前景
一、引言(Introduction)
- 背景:
由于摄像机的景深depth-of-field (DOF) 的限制,很难获得全部聚焦的图像。具体地说,DOF范围内的物体保持清晰,DOF范围外的场景内容模糊。然而,在实际应用中,清晰的图像是需要的。实现这一目标的一种方法是多焦点图像融合multi-focus image fusion (MFIF)。 - 多焦点图像融合(MFIF)
- 目的:将具有不同聚焦区域的多幅图像组合成一幅在所有位置都聚焦的图像。
- 传统的MFIF方法(Conventional MFIF algorithms)
- 基于空间域的方法(spatial domain-based methods)
可进一步划分为三类:基于像素的方法(pixel-based)、基于块的方法(block-based)、基于区域的方法(region-based)
- 基于变换域的方法(transform domain-based methods)
- 思想:首先将图像变换到另一个域中,然后在该域中使用变换后的系数执行融合。最后通过相应的逆变换得到融合图像。
到目前为止,已经提出了许多基于变换域的方法,如稀疏表示方法(sparse representation (SR) methods)、多尺度方法(multi-scale methods)、基于梯度域的方法(gradient domain-based methods)和混合方法(hybrid methods)。
- 基于空间域的方法(spatial domain-based methods)
- 基于深度学习的MFIF方法(deep learning-based MFIF methods)
- 方法分类:监督学习(supervised MFIF algorithms)、无监督学习(unsupervised MFIF algorithms)
- MFIF的深度学习模型:CNNs、GANs、ensemble learning
- 本文工作
- 出发点:
- 填补了基于深度学习的MFIF方法的调查文献的空缺。
- MFIF领域缺乏将传统算法与基于深度学习的MFIF算法进行比较和全面的性能评估。
- 贡献:
- 基于深度学习的MFIF方法、评估指标和数据集的系统调查。
- 综合性能评估。
使用19种评估方法在3个数据集上比较35种MFIF方法。
- 未来前景展望。
- 出发点:
二、基于深度学习的多聚焦图像融合方法(DEEP LEARNING-BASED MULTI-FOCUS IMAGE FUSION METHODS)
1、动机
- MFIF的两个关键任务:①焦点测量(Focus measurement (FM))或活动水平测量(Activity level measurement)②融合规则(fusion rule)
- 传统方法与深度学习方法对比
| 传统方法的不足 | 深度学习方法的优点 |
|---|---|
| 手工设计FM和融合规则,在复杂的情况下可能限制解空间 | 基于深度特征学习FM、自动学习融合规则 |
| 将FM和融合规则分开,进一步限制融合性能 | 通过学习将活动水平测量和融合规则一起处理 |
| 基于变换域的方法采用手工设计的变换,限制了对源图像的表示,并且对各种输入不鲁棒 | 深度学习模型可以视为自适应变换,鲁棒性优于基于变换域的传统方法 |
注: 并不是所有的基于深度学习 算法能够解决以上的所有不足,因为在大多方法中,深度学习仅作为方法的一部分。
2、基于深度学习的MFIF方法类别
- 监督学习、无监督学习
- 基于决策图的方法(decision map-based methods)
- 首先生成一个表示焦点级别(或活动级别)的决策图。然后根据该决策图进行图像融合。
- 在这些方法中,深度学习通常被用于生成决策地图,然后可能的后处理步骤,以获得更好的决策地图。
- 端到端的方法(end-to-end methods)
- 将源图像输入网络直接生成融合图像。
注:大多数基于决策映射的方法类似于基于空间域的算法,而端到端方法类似于基于转换域的方法。
An overview of main deep learning-based MFIF algorithms:

3、监督的深度学习方法(Supervised deep learning-based methods)
1)基于CNN的方法
- Liu et al.第一个提出了基于CNN的MFIF方法,该方法首先采用一个CNN学习源图像到focus map的映射,通过这种方式,可以联合学习传统方法中分别处理的活动级别测量和融合规则。经过一系列后处理步骤,得到最终的决策图,然后通过像素加权平均方法生成融合图像。

a)基于决策图的方法(Decision map-based methods)
此类方法的几个研究点如下:
-
①改进焦点测量(Improved focus measurement)
- 有了几项工作改进了MFIF中的FM。
- Tang等人[41]提出了一种像素级卷积神经网络(pixel-wise convolutional neural network (p-CNN)),这是一种学习的FM,与传统手工制作的FM相比,能够更好地识别源图像中的聚焦和散焦像素。
- Wang等人[23]提出了一种类似的方法,该方法利用基于具有非常深的卷积网络的Siamese CNN模型来识别聚焦和散焦像素。在这些方法中,FM是在训练过程中自动学习的,因此比手动设计的FM更具鲁棒性。
- 有了几项工作改进了MFIF中的FM。
-
②多层次特征(Multi-level features)
- 多层次特征可以用来使特征表示更加强大。
- 例如,Yang等人[45]为MFIF提出了一种多级特征卷积神经网络(MLFCNN)架构。主要的创新点是使用了不同层次的多层次特征,并采用了1×1卷积来降低特征空间的维数。
- 多层次特征可以用来使特征表示更加强大。
-
③多尺度特征(Multi-scale features)
- 在一些研究中,利用多尺度特征来提高性能。
- 例如,Du等人[30]将CNN方法[39]扩展到多尺度框架(MCNN)。MCNN使用多尺度输入进行训练以获得焦点图,然后对焦点图进行形态学和分水岭运算(morphological and watershed operations) 以获得理想的决策图。
- Lai等人[49]提出的多尺度视觉注意深度卷积神经网络(MADCNN) 也使用不同空间尺度的互补特征。
- 此外,Wang等人[48]在离散小波变换域提出了一种新的基于CNN的MFIF算法。具体来说,将小波 应用于源图像以获得高频和低频图像。然后将高频和低频图像馈送至相应的CNN以获得相应的分辨率图,然后利用这些分辨率图生成融合的高频和低频图像。最后通过小波逆变换(inverse wavelet transform) 得到融合图像。通过这种方式,该方法结合了基于空间域和基于变换域的方法的优点。
- 在一些研究中,利用多尺度特征来提高性能。
-
④注意力机制(Attention mechanism)
- 在Lai等人[49]提出的MADCNN中,视觉注意单元被用来帮助网络更准确地定位聚焦区域。
- 在郭等人[55]提出的SSAN中,注意机制也被利用,试图缓解卷积算子的局部感受野限制。
-
⑤聚焦和散焦边界的处理(Handling of the focused and defocused boundary)
- 聚焦和散焦边界(FDB)是一个重要的研究领域,许多算法在FDB附近表现不佳。
- Ma等人[50]提出利用两种不同的网络,即边界细化网络(boundary refinement net)和正规细化网络(normal refinement net),来处理从初始网络获得的初始得分图。
边界细化网络专门用于处理靠近FDB的面片,而正规细化网络应用于远离FDB的面片。
- 此外,在MMF-Net[54]中,设计了一个α-亚光边界散焦模型(α-matte boundary defocus model),通过精确模拟FDB附近的散焦扩散效应(defocus spread effect (DSE) ) 来生成真实的训练数据。据我们所知,这是第一个在为MFIF生成训练数据时考虑DSE的工作。
该方法设计了两个级联子网,即初始融合子网和边界融合子网。具体来说,初始融合子网首先生成guidance map,然后边界融合子网在FDB附近对融合结果进行细化。

- Ma等人[50]提出利用两种不同的网络,即边界细化网络(boundary refinement net)和正规细化网络(normal refinement net),来处理从初始网络获得的初始得分图。
- 聚焦和散焦边界(FDB)是一个重要的研究领域,许多算法在FDB附近表现不佳。
-
⑥全卷积算法(Fully-convolutional algorithms)
- 背景:
在上述基于决策图的方法中,除了MADCNN[49]和MMF Net[54]之外,网络中使用了全连接的层,因此测试图像的输入大小被限制为训练图像的大小。 回避此问题的一种方法是在图像上使用窗口,以获得与融合贴图大小匹配的面片[23]、[39]、[45]。在这些方法中,FM是在面片级计算的,然后平均得到与源图像大小相同的最终聚焦图。然而,这种方法类似于传统的基于块级空间域的方法。因此,这些方法具有基于块的方法的缺点,即可能在FDB附近引入伪影。此外,这些工作中使用的完全连接的层消耗了大量存储资源.。 - 解决方法:更合适的方法是使用对输入图像大小没有要求的完全卷积网络,因此不需要将输入图像分割成小块。
Guo等人提出了第一个基于全卷积决策映射的方法。随后,开发了一些其他的完全卷积方法[19],[49],[54]。
具体而言,Li等人[19]提出了DRPL,它直接将整个图像转换为二值掩码(加权贴图),而无需任何补片操作。然后根据这些加权映射生成融合图像。
存在问题:该方法通过对源图像对施加互补约束,假设两个源图像是互补的。然而,正如[54]所指出的,前景和背景区域之间并不总是存在清晰的边界。因此,该方法在处理FDB时可能存在问题。

- 背景:
b)端到端方法(End-to-end methods)
端到端方法的关键优势是通过训练直接学习源图像和融合图像之间的映射,因此无需进行后处理步骤。
-
模型架构(ecoder-decoder架构)
-
two-stream结构
- Xu等人[42]提出了第一种双流MFIF方法,该方法各使用一个分支处理一个源图像,如下图所示。
该方法采用卷积层提取特征,然后由融合层进行融合,再由反卷积层进行恢复。

- Zhange等人[22]提出的IFCNN,如下图所示。IFCNN在几个方面与Xu等人[42]的方法不同。
①首先,特征尺寸保持与源图像相同,而在[42]中,特征尺寸在卷积层中减小,并在反卷积层中恢复。
②其次,在IFCNN中使用了感知损失 (perceptual loss),而在[42]中使用了均方误差(mean squared error (MSE) loss)损失。
③第三,Zhang等人[22]证明,尽管IFCNN使用MFIF数据集进行训练,但它对其他图像融合任务具有良好的泛化能力。
- Xu等人[42]提出了第一种双流MFIF方法,该方法各使用一个分支处理一个源图像,如下图所示。
-
one-stream结构(多通道模型)
- Li等人[51]提出U-net。
该方法首先将源图像转换为YCbCr颜色空间,然后利用U形网络对亮度分量进行融合。Cb和Cr组件采用加权融合方法进行融合。

- Pena等人[53]提出了一种用于MFIF的多源沙漏深度网络(multiple source hourglass deep network for MFIF)
该方法直接处理RGB图像,如图6(b)所示。实际上,Pena等人[53]使用相同的框架提出了两种方法,即HF-Reg(端到端算法)和HR-Seg(基于决策图的方法)

- Li等人[51]提出U-net。
-
-
其他方法
- 基于CNN的多层次MFIF方法(multi-level method MFIF method, ML-CNN)
ML-CNN从两幅源图像中提取并融合每一层特征,在此基础上为每一层重构图像,最终的融合图像是通过一个卷积层对不同层次的图像进行融合得到的。
优点:
①由于低级特征可以捕获低频内容,而高级特征可以捕获高频细节,因此利用多级特征可以提高融合性能。
②在训练过程中对多级输出进行同时监督,以提高图像融合的性能。 - 小波变换域的MFIF方法(CNN- based MFIF method in the wavelet domain)
Li等人[47]在小波域提出了一种基于CNN的MFIF方法。该方法类似于[48],但在该方法中,子带网络直接输出融合子带图像,而不是子带决策图。
- 基于CNN的多层次MFIF方法(multi-level method MFIF method, ML-CNN)
2)基于GAN的方法(GAN-based methods)
-
FuseGAN:将MFIF作为一个图像到图像的转换问题,并利用最小二乘GAN目标增强FuseGAN的训练稳定性。GAN生成如下图所示的置信图,然后通过高级卷积条件随机场重新细化。
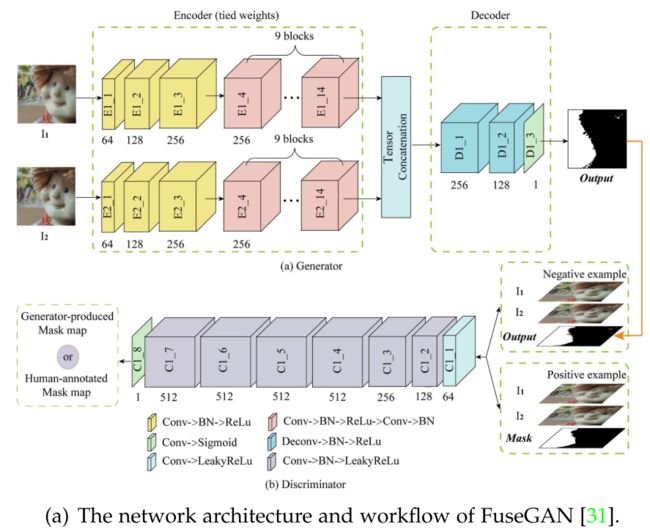
-
ACGAN:Huang等人[57]提出了ACGAN,这是一种基于GAN的端到端MFIF方法。
ACGAN和FuseGAN之间存在一些差异。
① 首先,ACGAN是一种端到端的方法,可以直接输出融合图像,而FuseGAN需要后处理步骤。
② 其次,ACGAN使用了由强度损失、梯度损失和结构相似性指数度量(SSIM)损失组成的发生器损失(generator loss)[57],[64],而FuseGAN使用了最小二乘GAN目标(the least square GAN objective)。
③ 第三,ACGAN训练用于融合灰度图像,因此在融合彩色图像时需要进一步处理,而FuseGAN可以直接融合彩色图像

3)基于集成学习方法(Ensemble learning-based methods)
- Naji等人提出了基于三个CNN(ECNN)集合的融合算法[32]。其主要思想是使用各种模型和数据集,而不仅仅是一个,以减少训练数据集的过度拟合问题。
- Naji等人也提出了类似的方法HCNN。
- 基于集成学习的方法的主要新颖之处在于它可以结合多种模型的优点
4)其他监督方法(Other supervised methods)
- Zhai等人[21]提出了一种基于去噪自编码器(DAE)和深度神经网络(DNN)的MFIF方法。
- Deshmukh等人[40]提出了一种算法,在深度信念网络(DBN)的帮助下,计算表明输入图像清晰区域的权重。
- Lahoud等人[52]提出使用预训练的神经网络提取特征,从而缓解了训练阶段。
4、无监督的深度学习方法(Unsupervised deep learning-based methods)
- 背景:监督方法需要大量的标记训练数据。然而,基准图像在MFIF任务中通常不可获得,因此几乎所有受监督的方法都使用实际不真实的合成数据集。
- 无监督方法:现有的所有无监督MFIF方法都是完全卷积的,而且大多数是端到端算法。
1)基于CNN的方法(CNN-based methods
a)端到端方法(End-to-end methods)
-
MFNet
- 实现无监督训练的关键是使用基于非参考SSIM[64]的损失函数,这是一种广泛使用的图像融合评估指标,用于测量源图像和融合图像之间的结构相似性。
- 损失函数:


x1、x2、ˆy分别是源图像和融合图像,w是局部窗口
SSIM:structural similarity index measure loss
std(x | w)是局部窗口w上图像块x的标准偏差(SD)- 模型训练目标:优化参数,降低SSIM值,增强源图像与融合图像的结构相似性。
- 模型结构:
- 输入输出:MFNet以一对多聚焦图像作为输入,可以直接输出全聚焦图像。MFNet的网络体系结构如下图。
- 组成:四个子网络:三个特征提取子网络(feature extraction sub-networks)、一个特征重构子网络(reconstruction sub-network)。
- 子网络作用:特征提取子网络负责从源图像和两个输入图像的平均值中提取特征。重建子网络用于产生基于特征的融合图像。

-
MFFNet(与MFNet相似)
- 损失函数:SSIM loss+pixel loss term
- 模型特点:MFFNet特征提取网络中的所有层以前馈方式连接,以从多聚焦图像对中提取更有用的公共低层特征。
-
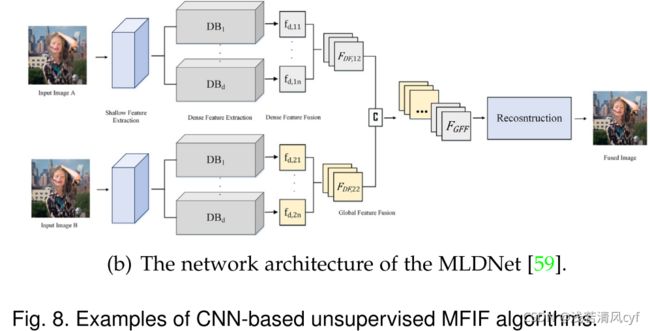
MLDNet
- MFFNet只使用一个密集块(one dense block)来提取源图像的特征,而MLD-Net有多个不同核大小的密集块(several dense blocks with various kernel sizes.)。
- MLDNet引入了两个额外的卷积层来提取源图像的浅层特征(shallow features),然后将其与从密集块获得的深层特征相结合。
-
MSCNN
- 特点:MSCNN采用多尺度特征提取和多尺度重建
- 损失函数:SSIM loss+pixel loss
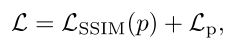

O和I是输出和输入图像
-
DIF-Net
- 背景:一些无监督算法[28]、[60]、[61]被设计用于执行多个图像融合任务,如可见光和红外图像融合、MFIF和多曝光图像融合。
- 损失函数:使用基于多通道图像对比度结构张量表示的无监督损失函数。
- 其他特点:在一些图像融合任务(如可见光-红外图像融合)中,DIF网络还考虑了源图像和融合图像之间可能存在的不同通道数。
-
FusionDN
- Xu等人[60]提出了一种方法(Fusionn)来将不同的图像融合任务组织到一个统一的密集连接网络中
- 优点:他们采用弹性权重整合,以避免在顺序训练多个任务时忘记从以前的任务中学到的东西。通过这种方式,获得了适用于多个融合任务的单一模型。
- 损失函数:SSIM+perceptual loss+gradient loss 【该损失函数更适合于图像融合任务】
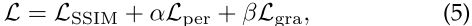
-
U2Fusion(针对FusionDN的修改)
- 特点:信息保存度分配是基于对提取的特征而不是源图像进行的信息度量。【有助于捕获源图像的基本特征】
- 损失函数:SSIM+MES 【有助于减少融合图像中的亮度偏差】
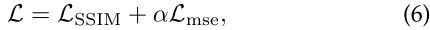
-
PMGI
- 思想:PMGI将图像融合任务统一到源图像的纹理和强度比例保持问题中
- 损失函数:两幅图的intensity loss+gradient loss
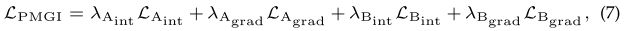
b)基于决策图的方法(Decision map-based methods)
-
SESF
- 基于encoder-decoder network
- 步骤:①编码器:特征提取;②特征图+空间频率→获得focus map;③获得最终决策图:采用一致性验证(consistency verificatio)方法
- 损失函数:SSIM loss+pixel loss
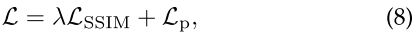
- 特点:SESF不需要多聚焦图像对来训练。相反,它只使用MS COCO[66]来训练编码器-解码器网络

-
GCF
- 基于梯度(gradients)和连通区域(connected regions)的基于决策图的无监督MFIF算法
- 步骤:
- ①使用encoder-decoder network生成map M 0 M_0 M0 和初始的二分掩码图 M 1 M_1 M1,用来计算梯度损失和连通区域损失【需要使用多聚焦图像对作为训练数据】
- ②后处理步骤:使用一致性验证(consistency verificatio)生成最终的决策图 M F M_F MF
2)基于GAN的方法(GAN-based methods)
- MFF-GAN
- 基于GAN的无监督MFIF方法
- 首先根据重复模糊原理,利用自适应决策块对源图像的每个像素进行锐度评估。
具体地说,如果像素具有更高的清晰度,则添加模糊后像素值的变化更大。
- 然后,内容损失(content loss)被专门设计为强制生成器(generator)生成与聚焦源图像具有相同分布的融合结果。
- 最后,使用鉴别器(discriminator)与生成器(generator)建立对抗游戏,使融合图像的梯度图与基于源图像构建的联合梯度图相似。这可以进一步增强纹理细节。
5、总结
- 从以上调查可以看出,许多基于深度学习的MFIF算法可以同时学习活动水平度量和融合规则,避免了单独和手工设计。
- 关于监督方法,有些是端到端方法,但大多数不是。
- 相比之下,所有已发表的无监督MFIF方法都是完全卷积的,大多数无监督方法都是端到端方法。此外,在大多数无监督方法中,SSIM是损失函数的关键部分
三、数据集(DATASET)
1、Multi-focus image fusion datasets

- 特点:图像对的数量不是很大,大多数数据集用于测试,需要进行数据增强才能用于训练
- 三种生成不同聚焦区域的图像对的方法:
| 序号 | 方法描述 | 特点 | 应用 |
|---|---|---|---|
| 1 、多景深拍摄法 | 用不同的景深(DOFs)捕获相同场景的图像 | 真实拍摄 | - |
| 2 、合成法 | 即通过将模糊添加到全清图像来生成模糊图像 | 在合成生成的图像中,所谓的DSE并不明显 | Aymaz et al.[69]、Tsai、MFI-WHU |
| 3 、重新聚焦法 | 对光场数据应用重新聚焦来生成多聚焦图像 | 这种方法很少使用,但它是最有前途的方法,因为它有可能提供具有地面真实性的多聚焦图像。 | Lytro、Real-MFIF |
2、Training data for deep learning-based methods

四、评估指标(EVALUATION METRICS)
- 两种评估方式:主观评价(定性评价)、客观评价(定量评价)
- 主观评价:不能自动化(耗时)、不同标准(偏差)→ 通常结合客观评价
- 客观评价:数十项指标。每个指标主要从一个方面评估MFIF算法。因此,重要的是使用不同类型的度量来评估MFIF算法。
- 客观评价的四种类型:
- 基于信息论的度量(Information theory-based metrics)
- 基于图像特征的度量(Image feature-based metrics)
- 基于图像结构相似性的度量方法(Image structural similarity-based metrics)
- 基于人类感知的度量(Human perception inspired metrics)
1、Information theory-based metrics
符号说明:M是图像的宽度,N是图像的高度。A和B分别指示第一源图像(图像A)和第二源图像(图像B)。X表示源图像,F表示融合图像。

2、Image feature-based metrics

3、Image structural similarity-based metrics

4、Human perception inspired fusion metrics

5、总结
- 这些指标是用来检验图像融合性能,而不是产生融合图像。因此,在应用这些指标之前,融合图像F已经由mif算法产生。
- 所有的MIFI算法都将源图像A和B的信息以某种形式组合在一起,因此在实际中通常不会出现A=F或B=F的情况。
- 两种源图像都包含重要信息,因此设计了许多评价指标来衡量融合图像F与源图像之间的相似性。
- 一个好的图像融合算法应该将两幅源图像的重要信息传递给融合图像。
五、实验和结果(EXPERIMENTS AND RESULTS)
1、MFIF方法比较(Compared MFIF methods)
测试算法:35 MFIF algorithms(包含12 deep learning-based MFIF methods)

2、数据集(Datasets)
| 数据集 | 特点 |
|---|---|
| The Lytro dataset | Lytro数据集广泛应用于MFIF领域。它由20对多焦点图像组成,这些图像是用光场摄像机拍摄的。 |
| The MFI-WHU dataset | MFI-WHU数据集是基于公共COCO数据集[66]和[121]中提供的数据集,使用高斯模糊和手工制作的决策图构建的。它由120对图像组成,其中30对用于测试,90对用于训练。 |
| The MFFW dataset | Xu等[68]认为Lytro数据集DSE不高,因此创建了包含13对具有强DSE的真实多焦点图像对的MFFW数据集。 |
3、评价指标(Evaluation metrics)
- 19个评价指标
- 对于CE和QCV,值越小表示性能越好,而对于其余17个指标,值越大表示性能越好
4、定量性能比较(Quantitative performance comparison)
1)算法整体排名
-
算法数量:35个算法
-
排名方法:首先计算每个算法在每个度量上的排名,然后根据Borda计数计算这些算法的总体排名
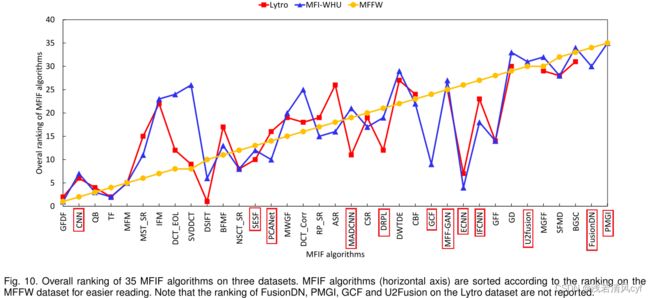
-
四种传统方法,即GFDF、QB、TF和MFM,通过在所有三个数据集上显示前五名性能
-
基于深度学习的方法,CNN取得了最佳的整体排名(第5位)
-
基于深度学习的MFIF方法在Lytro、MFI-WHU和MFFW上的最佳排名分别为6、4和2。
- 在MFFW数据集上,只有CNN位列前十。
- 在Lytro和MFI-WHU数据集上,只有三种基于深度学习的方法实现了前十名的性能。
- 这意味着,与传统方法相比,基于深度学习的MFIF方法没有表现出非常有竞争力的定量性能。

-
深度学习的方法性能对比【上图】:
- 就三个数据集的总体排名而言,CNN是最好的监督方法,SESF是最好的无监督算法。
CNN和SESF都不是端到端的方法。特别是,采用了后处理步骤(一致性验证),表明后处理步骤有助于基于深度学习的方法。
- 一般来说,有监督的方法比无监督的方法表现出更好的结果。
- 专门为MFIF任务设计的方法优于一般的图像融合方法。这对于有监督和无监督的方法都是正确的。
各种图像融合任务具有非常不同的关键点以实现良好的性能,因此最好设计特定的措施来处理不同的任务。
- 大多数有监督的方法在训练中使用合成的图像数据,而大部分无监督方法在训练中使用真实的多聚焦图像。
- 就三个数据集的总体排名而言,CNN是最好的监督方法,SESF是最好的无监督算法。
-
泛化能力(The generalization ability)
- 实验条件:本研究中选择的三个MFIF数据集具有不同的特征,并且与训练集不同。
- 实验结果【上方两幅图】:与有监督的方法相比,一般无监督方法具有更好的泛化能力。
- 在无监督方法中,只有GCF的性能在不同的数据集上存在显著差异。相比之下,几乎所有有监督的方法在三个数据集上表现出显著的性能差异。
主要原因是,有监督的MFIF方法使用合成数据集或ImageNet(PCANet)的所有清晰图像进行训练,但这些训练数据与真实多聚焦图像不一致[50]。因此,他们无法学习处理真实多焦点图像的良好能力。
- 尽管Lytro数据集和MFFW数据集都是真实的多聚焦图像融合数据集,但MFFW数据集具有训练数据集所不具备的强大散焦扩散效应(DSE),因此MFFW数据集上的5种算法(共8种)的性能比Lytro数据集上的差。
- 在所有的基于深度学习的方法中,SESF在总体排名和良好的泛化能力方面显示出第二好的总体性能。这有两个原因。首先,采用一致性验证作为后处理步骤来校正决策图。其次,SESF中使用的损失函数包括SSIM项和像素损失,因此训练模型对变化的源图像更具鲁棒性。
- 仅使用一个损失项(ECNN、MADCNN、PCANet)或不采用后处理步骤(DRPL、MADCNN、IFCNN)的方法通常不会表现出良好的泛化能力。
2)基于度量的结果

- 没有一种能够获得优异的性能
- GFDF在MFFW数据集上获得了最佳的整体定量性能,仅在1个指标上排名第一,在19个指标中的8个指标上排名前五。
- 不同的算法在不同的度量方面具有非常不同的性能。
例如:SFMD在MFFW数据集的2个度量上获得最佳值,但在所有35个算法中,它仅排名第32位。这是因为SFMD在基于图像特征的度量方面获得了良好的性能,而在其他度量方面表现不佳。

- 上图显示了MFFW数据集上每种方法在每种度量上的平均排名。
- 几乎每种算法在不同类型的度量上都表现出不同的性能,表明这些算法在处理不同信息方面的不同能力。这也发生在其他类型的图像融合任务中[38],[130]。每种方法在不同类型度量上的性能在一定程度上受所使用的损失函数的影响。
例如:
1、MFF-GAN在基于图像特征的度量上表现出比其他三种度量更好的性能。这是因为MFF-GAN的鉴别器设计用于强制融合图像具有与源图像的联合梯度图相似的梯度图,并且梯度是基于图像特征的度量的重要组成部分。
2、一个类似的例子是GCF,它在基于图像特征的度量上比在其他类型的度量上获得更好的性能。原因是梯度损失是GCF损失函数中的一个主要项。
5、定性性能比较(Qualitative performance comparison)
- 伪影:从融合图像和贪婪虚线框中放大的图中可以看出,许多算法在融合图像中产生明显的伪影。CSR、ECNN、GCF、PCANet和QB制作的融合图像中,雕塑的手部周围存在伪影。
- 模糊:FusionDN和PMGI给出了仍然存在某种模糊的融合图像。
- 颜色失真:RP-SR和LP-SR方法产生的融合图像在图像右上角的墙壁上有颜色失真,GD的融合图像在左侧有颜色失真(看起来像过度曝光)。
- 边缘:有些算法无法很好地处理边缘。
- 综上所述,在本例中,CNN、IFM和MWGF的融合效果都比较好。

- 结论:
- MFFW 02图像对的定性结果与定量结果(表6和图11)在一定程度上一致。
- 目前还没有一个指标能够准确地指示MFIF算法的视觉性能。因此,在这种情况下,一些在人类感知指标上表现出良好性能的算法无法生成良好的融合图像。
- 定量和定性结果之间的不一致不仅存在于MFIF中,而且也出现在其他图像融合任务中,如多曝光图像融合和可见红外图像融合。
- 大多数基于深度学习的MFIF算法不能提供令人满意的融合图像,这表明基于深度学习的MFIF方法与传统方法相比没有优势。
6、运行时间比较(Running time comparison)

- 首先,MFIF方法的运行时间因方法而异。例如,运行时间最慢(ASR)的是最快的(IFCNN)的22800多倍。对于同一类别中的方法也是如此。
例如,在深度学习方法中,CNN的运行时间是IFCNN的7000多倍。值得一提的是,CNN和PCANet是在MATLAB中实现的,而所有其他基于深度学习的方法都是在PyTorch或TensorFlow中实现的。因此,在PyTorch或TensorFlow中实现基于深度学习的方法通常比使用MATLAB更有效。
- 其次,基于SR的方法是计算成本最高的方法,融合图像对需要6分钟以上的时间。
- 第三,一般来说,基于空间域的方法和基于变换域的方法(不包括基于SR的方法)的计算成本是相同的数量级,除了一些算法,如CBF和DWTDE。
- 最后,大多数MFIF算法的效率应进一步提高,以应用于实时应用。
六、讨论(DISCUSSION)
1、结果分析(Analysis of results)
- 基于深度学习的方法在MFFW数据集上的性能比传统方法差
- 可能原因:
- 首先,大多数基于深度学习的MFIF方法在训练中使用了Lytro数据集或合成数据集的一部分。然而,Lytro数据集相对容易,因为它不包含太多DSE,并且合成数据集不具有真实多聚焦图像的关键特征。因此,使用这些数据集训练的深度学习模型无法学习处理具有强DSE的具有挑战性的真实单词多焦点图像的能力。
- 第二,远离聚焦和散焦边界(FDB)和靠近FDB的区域情况不同。因此,最好采取一些具体措施来应对FDB。然而,大多数基于深度学习的方法使用单个网络来同时处理这两种情况。
2、基于深度学习方法的研究进展(The progress of deep learning-based methods)
- 自2017年以来,已经提出了70多种基于深度学习的MFIF方法。然而,根据我们的实验结果,性能改进是有限的。
- 限制性能的几个挑战:
- 缺乏在聚焦和散焦边界(FDB)附近具有强DSE的大规模真实训练数据集。
- FDB是基于深度学习的方法面临挑战的领域。实际上,很少有研究采取具体措施来处理FDB。
- 现有MFIF数据集中,ground truth不存在。这给MFIF算法的训练和性能评估带来了困难。
- MFIF任务中损失函数的有效设计仍然是一个挑战
七、总结(CONCLUSIONS)
-
本文详细介绍了基于深度学习的多聚焦图像融合算法。据我们所知,这是第一次针对基于深度学习的MFIF方法的调查。我们还详细总结了MFIF数据集和客观评估指标。
-
在详细调查之后,进行了大量实验,使用3个不同的数据集和19个评估指标综合评估35个MFIF算法的性能。实验结果表明,基于深度学习的MFIF方法没有显示出传统方法的优势。此外,尽管已经提出了70多种基于深度学习的MFIF方法,但自2017年以来,基于深度学习的MFIF方法的性能改进有限。
-
基于调查和比较研究,我们发现一些方法可能有助于提高基于深度学习的MFIF方法的性能。
- 首先,开发具有强大DSE的大规模真实世界训练数据集以填补合成数据和真实数据之间的差距至关重要。
- 第二,在大规模真实世界的训练数据集中获得基本事实是可取的。实现这一点的一种可能方法是从光场数据生成具有地面真实性的训练数据。
- 第三,重要的是在损失函数中包含不同的指标,其中每个指标从不同的方面评估性能。这样,损失函数可以更好地反映深度学习模型的性能,从而为通过反向传播改进训练过程中的参数提供更好的指导。
- 第四,尽管深度学习技术可以为MFIF任务提供端到端的解决方案,但实验结果表明,一致性验证等后处理步骤有助于提高性能。这是因为现有的训练数据集不够好,因此端到端模型的性能受到限制。
- 最后,重要的是使用不同类型的度量来评估MFIF方法,以获得适当的反馈,这对于改进深度学习模型的设计至关重要。
-
值得一提的是,已经设计了一些算法来执行多个图像融合任务。然而,根据我们的实验结果,与专门为MFIF设计的方法相比,通用的图像融合方法(general image fusion methods)几乎始终显示出较差的量化性能。这是因为与其他图像融合任务相比,MFIF具有独特的特性,因此应采取具体措施。因此,我们建议专门为MFIF任务设计基于深度学习的方法。
-
名词总结:
- defocus spread effect (DSE):散焦扩散效应(DSE)
- focused and defocused boundary:远离聚焦和散焦边界(FDB)