机器学习学习笔记—正则化的理解
这几天在学习李航的统计学习方法,来谈谈我对于机器学习中正则化的理解:
- 什么是正则化
- 如何理解正则化
- 正则化的作用
第一个问题,什么是正则化?
正则化就是在损失函数后加上一个正则化项(惩罚项),其实就是常说的结构风险最小化策略,即经验风险(损失函数)加上正则化。一般模型越复杂,正则化值越大。
正则化项是用来对模型中某些参数进行约束
正则化的一般形式:
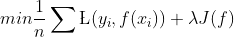
其中,第一项是损失函数(经验风险),第二项是正则化项,lamda>=0,是调整损失函数和正则化项的系数
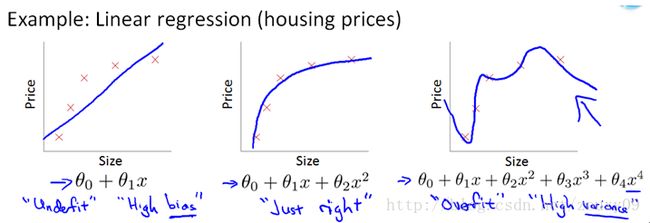
正则化一般是用于防止模型出现过拟合的现象,过拟合是指学习时模型的参数过多,模型过于复杂。模型对于训练数据预测得很好,但对于未知数据预测效果很差,即训练误差小,预测误差大,过拟合时,模型系数会很大,因为模型要顾及每一个点,在很小的空间里函数值变化剧烈,可见偏导数会很大,模型系数大。过拟合时,一般模型的参数(特征)较多,模型会千方百计的去拟合训练集,损失函数较小,但会导致模型的泛化能力较差。一般样本较少而特征较多时容易产生过拟合现象。左图显示的是欠拟合,也称作高偏差(high bias),右图显示的是过拟合,也称作高方差(high variance)
解决过拟合的两个思路:
- 一是过滤掉部分特征(减少特征的数量)即特征选择,会损失掉一些信息
- 二是正则,使用正则减小参数的值,保留所有的特征
由可以看出,加上惩罚项后损失函数的值会增大,要想损失函数最小,惩罚项的值要尽可能的小,模型参数就要尽可能的小,这样就能减小模型参数,使得模型更加简单
在回归问题中,常见的正则化有L1正则化和L2正则化,无论是L1还是L2都能够防止过拟合
- L1正则化(L1范数)指的是权重参数W的各项元素绝对值之和,即
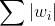 ,记作
,记作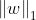
- L2正则化(L2范数)权重参数W的各项元素的平方和的开方,即
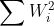 ,记作
,记作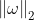
对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)
第二个问题,如何理解正则化?
正则化其实就是带约束条件的优化问题,为什么要正则化,就是对目标函数加上一个约束条件,这类似于带约束条件的朗格拉日乘数法。
即目标函数为:
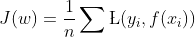
s.t. ![]()
结构风险最小化策略转化为求目标函数的最小值问题
第三个问题,正则化有什么作用
- L1正则化可以产生稀疏权重矩阵,即大部分w为0,只有少数w非0,可以用于特征选择
- L2正则化可以防止模型过拟合
接下来将解释原因:
- L1正则化可以产生稀疏权重矩阵,用于特征选择
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0. 通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。例如患某种病的概率是y,然后我们收集到的数据x是1000维的,也就是我们需要寻找这1000种因素到底是怎么影响患上这种病的概率的。假设我们这个是个回归模型:y=w1*x1+w2*x2+…+w1000*x1000+b(当然了,为了让y限定在[0,1]的范围,一般还得加个Logistic函数)。通过学习,如果最后学习到的w*就只有很少的非零元素,例如只有5个非零的wi,那么我们就有理由相信,这些对应的特征在患病分析上面提供的信息是巨大的,决策性的。也就是说,患不患这种病只和这5个因素有关,那医生就好分析多了。
假设有如下带L1正则化的损失函数:

其中J0是原始的损失函数,加号后面的一项是L1正则化项, 是正则化系数。当我们在原始损失函数J0后添加L1正则化项时,相当于对J0做了一个约束。令L=∑w|w|,则J=J0+L,此时我们的任务变成在L约束下求出J0取最小值的解(w,b)。考虑二维的情况,即只有两个权值w1和w2,此时L=|w1|+|w2|对于梯度下降法,求解J0的过程可以画出等值线,同时L1正则化的函数L也可以在w1w2的二维平面上画出来。如下图:
是正则化系数。当我们在原始损失函数J0后添加L1正则化项时,相当于对J0做了一个约束。令L=∑w|w|,则J=J0+L,此时我们的任务变成在L约束下求出J0取最小值的解(w,b)。考虑二维的情况,即只有两个权值w1和w2,此时L=|w1|+|w2|对于梯度下降法,求解J0的过程可以画出等值线,同时L1正则化的函数L也可以在w1w2的二维平面上画出来。如下图:
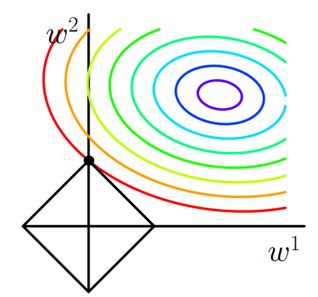
这里的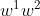 都是模型的参数,是要优化的目标参数,那个四边形边框,其实就是解空间,正如上面所说,这个时候,解空间“缩小了”(被约束啦),你只能在这个缩小了的空间中,寻找使得目标函数最小的。再看看那些圆圈,每一个圆圈上,可以取无数个,这些有个共同的特点,用它们计算的目标函数的值是相等的。注意L1构成的区域一定是个四边形。自己在纸上画画
都是模型的参数,是要优化的目标参数,那个四边形边框,其实就是解空间,正如上面所说,这个时候,解空间“缩小了”(被约束啦),你只能在这个缩小了的空间中,寻找使得目标函数最小的。再看看那些圆圈,每一个圆圈上,可以取无数个,这些有个共同的特点,用它们计算的目标函数的值是相等的。注意L1构成的区域一定是个四边形。自己在纸上画画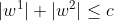
在图中,当J0等值线与L图形首次相交的地方就是最优解。上图中J0与L在L的一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是(w1,w2)=(0,w)。可以直观想象,因为L函数有很多『突出的角』(二维情况下四个,多维情况下更多),J0与这些角接触的机率会远大于与L其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
2.L2可以防止模型过拟合(L2正则化也叫权重衰减)
L2正则化也叫权重衰减,减小模型系数,减小模型复杂度,防止过拟合现象。
L2 正则化的损失函数:
C0代表原始的损失函数,后面那一项就是L2正则化项,它是这样来的:所有参数w的平方的和,除以训练集的样本大小n。λ就是正则项系数,权衡正则项与C0项的比重。另外还有一个系数1/2,1/2经常会看到,主要是为了后面求导的结果方便,后面那一项求导会产生一个2,与1/2相乘刚好凑整。
同样可以画出他们在二维平面上的图形,如下:

二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此C0与L相交时使得w1或w2等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
L2正则项为什么可以拟制过拟合overfiting呢
因为L2正则化项可以获得很小的权重系数,减小模型的复杂度
L2正则化项是怎么避免overfitting的呢?我们推导一下看看,先求导:

可以发现L2正则化项对b的更新没有影响,但是对于w的更新有影响:
在不使用L2正则化时,求导结果中w前系数为1,现在w前面系数为 1−ηλ/n ,因为η、λ、n都是正的,所以 1−ηλ/n小于1(因为学习率很小,样本量n很大,1−ηλ/n很小,可能想象为0.99),它的效果是减小w,这也就是权重衰减(weight decay)的由来。当然考虑到后面的导数项,w最终的值可能增大也可能减小。
此外,我们注意,正则化因子,也就是里面的那个lamda,是用来平衡第一项和第二项的取舍,即是模型的损失函数更小,更好的去拟合数据还是模型的参数尽可能的小,避免过拟合的出现。如果它变大了,说明目标函数的作用变小了,正则化项的作用变大了,对参数的限制能力加强了,这会使得参数的变化不那么剧烈,直接的好处就是避免模型过拟合。λ越大,由推导公式可知,权重系数w越小,其实就是图中解空间越小,四边形/圆 越来越小,越来越靠近原点,值也就越小,如果lambda过大,会导致模型的参数接近于0,模型就会过于简单,会导致出现欠拟合。