知识图谱从0到-1的笔记——4.知识抽取与知识挖掘
开始知识图谱从0到-1,用的书是《知识图谱方法、实践与应用》,做些阅读笔记,如有错误内容,望各位指正。
知识抽取与知识挖掘
- 知识抽取与知识挖掘
-
- 1.知识抽取问题
-
- 1.1 知识抽取的场景(数据源):
- 1.2 信息抽取、知识抽取的区别与联系
- 1.3 知识抽取的基本流程及相关任务
- 2.面向结构化数据的知识抽取
-
- 1.2.1 直接映射DM
- 1.2.2 R2RML
- 3.面向非结构化数据的知识抽取
-
- 3.1 实体抽取
-
- 3.3.1 语料标注
- 3.1.2 基于规则的方法
- 3.1.3 基于统计学习的方法
-
- 3.1.3.1 隐马尔可夫模型
- 3.1.3.2 条件随机场
- 3.1.4 基于深度学习的方法
- 3.2 关系抽取
-
- 3.2.1 基于模板的关系抽取方法
- 3.2.1 基于监督学习的关系抽取方法
- 3.2.1 基于弱监督学习的关系抽取方法
- 3.3 事件抽取
-
- 3.3.1 事件抽取的流水线的方法
- 3.3.2 事件的联合抽取方法
- 4.知识挖掘
-
- 4.1 实体链接
-
- 4.1.1 实体指称识别
- 4.1.2 候选实体生成
- 4.1.3 候选实体消歧
- 参考
知识抽取与知识挖掘
知识抽取是构建大规模知识图谱的重要环节,而知识挖掘则是在已有知识图谱的基础上发现其隐藏的知识。
1.知识抽取问题
1.1 知识抽取的场景(数据源):
- 半(结构化)文本数据:百科知识中的Infobox、规范的表格、数据库、社交网络等

- 非结构化文本数据:网页、新闻、社交媒体、论文等
- 多媒体数据:图片、视频

1.2 信息抽取、知识抽取的区别与联系
| 信息抽取 | 知识抽取 | |
|---|---|---|
| 区别 | 信息抽取获得结构化数据 | 知识抽取获得机器可理解和处理的知识(知识表示) |
| 联系 | 知识抽取建立在信息抽取基础上,普遍利用到自然语言处理处理技术、基于规则的包装器和机器学习等技术 |
1.3 知识抽取的基本流程及相关任务
- 知识抽取的总体流程:是自动化地从文本中发现和抽取相关信息,并将多个文本碎片的信息进行合并,将非结构化数据转换为结构化数据,包括某一特定领域的模型、实体关系或RDF三元组
在从文本抽取信息时,一般会涉及到以下一些任务:
- 命名实体识别:从文本中检测出预定义的类别:人物、组织、地点、时间等
- 关系抽取:从文本中识别出实体与实体之间的关系
- 事件抽取:从文本中识别出事件信息,如何时何地发生了什么事情
2.面向结构化数据的知识抽取
垂直领域的知识往往来源于支撑企业业务系统的关系数据库,因此从数据库这种结构化数据中抽取知识也是一类重要的知识抽取方法。以下将介绍直接映射(Direct Mapping,DM),R2RMI两种映射语言,用于定义关系数据库中的数据如何转换为RDF数据的各种规则(URI的生成、RDF类和属性的定义、空节点的处理、数据间关联关系的表达等)
1.2.1 直接映射DM
直接映射定义了一个从关系数据库到RDF图数据的简单转换,即将关系数据库表结构和数据直接转换为RDF图,关系数据库的数据结构直接反映在RDF图中。
- 直接映射的规则主要如下:
| 抽取对象 | 映射为 |
|---|---|
| 表(Table) | 类(Class) |
| 列(Column) | 属性(Property) |
| 行(Row) | 资源/示例(Resource/Instance) |
| 单元(Cell) | 属性值(Property Value |
| 外键(Foreign Key) | 指代(Reference) |
- 映射例子:
例如从下面两个数据库表映射为RDF数据
People表
| PK | ->Address(ID) | |
|---|---|---|
| ID | fname | Address(ID) |
| 7 | Bob | 18 |
| 8 | Sue | NuLL |
Address表
| PK | ||
|---|---|---|
| ID | city | state |
| 18 | Cambridge | MA |
基于直接映射标准,上述的两个表可以映射为如下的RDF数据
@base .
@prefix xsd: .
rdf:type .
7 .
"Bob" .
18 .
.
rdf:type .
8 .
"Sue" .
rdf:type .
18 .
"Cambrifge" .
"MA".
1.2.2 R2RML
R2RML是一种用于表示从关系数据库到RDF数据集的自定义映射语言。
- 提供了在RDF数据模型下查看现有关系型数据的能力
- 基于用户自定义的结构和目标词汇表示原有的关系型数据
- 直接映射生成的RDF图结构直接反映了数据库的结构,目标RDF词汇直接反映了数据库模型元素的名称,结构目标词汇 都不能改变。
- R2RML映射是通过逻辑表(Logic Tables)丛数据库中检索数据。逻辑表突破了关系数据库的物理结构的限制,为不改变数据库原来的结构而灵活地按需生成RDF数据奠定了基础。
- R2RML的映射例子
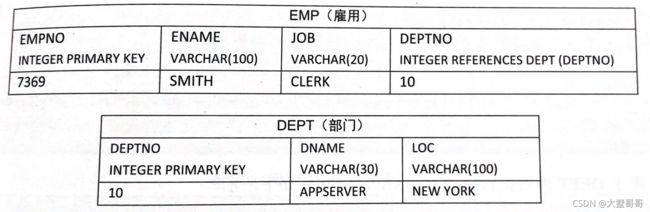
映射为RDF数据,期望输出结果如下:
rdf:type ex:Employee .
ex:name "SMITH".
ex:department
rdf:type ex:Department.
ex:name "APPSERVER".
ex:location "NEW YORK"
ex:staff 1.
R2RML的映射文档
@prefix rr:.
@prefix ex:.
<#TripleMap1>
rr:logicalTable [rr:tableName "EMP"];
rr:subjectMap[
rr:template “http://data/example.com/employee/{EMPNO}”;
rr:class ex:Employee;
];
rr:predicateObjectMap[
rr:predicate ex:name;
rr:objectMap[ rr: column "ENAME"];
].
3.面向非结构化数据的知识抽取
大量数据都是以非结构化数据(即自由文本)的形式存在,如新闻报道、科技文献等,而面向文本数据的知识抽取一直是广受关注的问题。是当前知识图谱构建的技术评价。其中关键的技术包括:实体识别,关系抽取,事件抽取
3.1 实体抽取
实体抽取有称为命名实体抽取,母的就是从文本汇总抽取实体信息元素,即文本中的人名、组织、地理位置、时间、字符、数值等等。总体上可以将方法分为:基于规则的方法、基于统计模型的方法和基于深度学习的方法下。图为实体抽取的示例。

3.3.1 语料标注
在进行预料标注时,通常采用Inside-Outside-Beginning(IOB)或Inside-Outside(IO)标注体系对文本进行人工标注。
即在IO体系中,“特朗普”、“白宫”是句子中的实体。在IOB体系中,“特朗普”、“白宫”是句子中的实体,其中“特”和“白”是实体词的起始词。

3.1.2 基于规则的方法
采用人工编写规则的方式进行实体抽取,首先需要构建大量的实体抽取规则,通常需要一定领域知识的专家手工构建。然后将规则和文本字符进行匹配进行实体的提取。
3.1.3 基于统计学习的方法
基于统计学习的方法主要包括:隐马尔科夫模型(HMM)、最大熵马尔科夫模型(MEMM)、条件随机场(CRF)、支持向量机(SVM)
3.1.3.1 隐马尔可夫模型
- 有向图模型
- 生成模型
- 特征分布独立假设

3.1.3.2 条件随机场
- 无向图模型
- 判别式模型
- 无特征分布独立假设
3.1.4 基于深度学习的方法
基于深度学习的方法直接以文本中词的向量为输入,通过神经网络实现端到端的命名实体识别,不再依赖人工构建的特征。目前主要使用卷积神经网络(CNN)、循环卷积网络(RNN)、以及引入注意力机制的方法。通过输入到作为编码器的神经网络得到新的词向量表示,最后再通过CRF模型对每个词进行标注。
3.2 关系抽取
关系抽取是从文本中取出两个或者多个实体之间的语义关系,主要分为:基于模板的关系抽取方法,基于监督学习的关系抽取方法,基于弱监督学习的关系抽取方法。
- 语义关系:
- 是指隐藏在句法结构后面由词语的语义范畴建立起来的关系
- 在句子中地位很重要
- 连接文本中的实体
- 与实体一起表达出文本中的含义
- 并不是很难识别
3.2.1 基于模板的关系抽取方法
早期的实体关系抽取方法大多是基于模板匹配实现的。
例如:
“【X】住在【Y】”即表示了住址的关系。
3.2.1 基于监督学习的关系抽取方法
基于监督学习的关系抽取将关系抽取转化为分类问题,在大量标注数据的基础上,训练有监督学习模型进行关系抽取。
- 一般流程:
- 标注数据
- 特征工程
- 选择分类模型
- 训练模型
- 评估模型
3.2.1 基于弱监督学习的关系抽取方法
由于基于监督学习的关系抽取方法需要大量的标注数据。当语料不足时,弱监督学习的方法可以利用少量的标注数据进行模型学习。其方法主要包括远程监督方法和Bootstrapping方法。
- 远程监督方法
通过将知识图谱与非结构化文本对齐的方式自动构建大量的训练数据,减少模型对人工标注数据的依赖。
远程监督的基本假设是如果两个实体在知识图谱中存在某种关系,则包含两个实体的句子均表达这种关系。
例如:在某知识图谱中存在实体关系创始人(乔布斯,苹果公司),则包含实体乔布斯和苹果公司的句子“乔布斯是苹果公司的联合创始人和CEO”则可用作关系创始人的训练正例。
一般步骤为:
- 从知识图谱中抽取存在的目标关系的实体对
- 从非结构化文本中抽取含有实体对的句子作为训练样例
- 训练监督学习模型进行关系抽取
- Bootstrapping
利用少量的示例作为初始种子集合,在种子集合上获得关系抽取模板,再利用模板抽取更多的实例,加入种子集合中,通过不断迭代,BootStrapping方法可以从文本中抽取出大量实例。
3.3 事件抽取
-事件:事件是发生在某个特定的时间点或时间段、某个特定的地域范围内,由一个或多个角色参与的一个或者多个动作组成的状态的改变
-事件抽取:从自然语言文本中抽取出用户感兴趣的事件并且以结构化的形式呈现出来,如什么人、组织,在什么时间,在什么地方,做了什么事情。

3.3.1 事件抽取的流水线的方法
流水线方法将事件抽取任务分解为一系列基于分类的子任务,包括事件识别、元素抽取、属性分类和可报告行判别。其中每一个子任务都有一个机器学习分类器负责实施。
3.3.2 事件的联合抽取方法
联合抽取方法首先建立事件抽取子任务的模型,然后将各个模型的目标函数进行组合,形成联合推断的目标函数
4.知识挖掘
知识挖掘是从已有的实体及实体的关系出发挖掘新的知识,具体包括知识内容挖掘和知识结构挖掘
4.1 实体链接
实体链接是一种知识内容挖掘的方法,是指将文本中的实体指称(Mention)链向其在给定知识库中目标实体的过程。
- 指称(Mention):自然文本中表达实体的语言片段
- 实体链接(Entity Linking):把文本中的Mention链接到KG里的Entity的任务

- 实体链接的基本流程如下:实体指称识别、候选实体生成、候选实体消歧

4.1.1 实体指称识别
实体链接的第一步就是要识别出实体的指称,主要是通过实体识别技术或者词典匹配技术。其中词典匹配技术需要首先构建问题领域的实体指称词典,通过直接与文本匹配识别指称。
4.1.2 候选实体生成
候选实体生成式确定文本中实体指称可能指向的实体集合。例如“乔丹”可能指向“NBA运动员乔丹”或是“深度学习的乔丹”
-
表层名字拓展
某些实体提及(Mention)是缩略词或者是全名的一部分,因此可以通过表层名字拓展技术,从实体提及识别到其他可能的变体(可能是实体全名)。例如:"University of Illinois at Urbana-Champaign(UIUC)" -
基于搜索引擎的方法
将实体提及和上下文文字提交至搜索引擎,可以根据搜索引擎返回的检索结果生成候选实体。 -
构建查询实体引用表
很多实体链接系统都基于维基百科数据构建查询实体引用表,建立实体提及与候选实体的对应关系。它可以看作是一个<键,值>对的映射

4.1.3 候选实体消歧
在确定文本的实体指称和它们的候选实体后,实体链接系统需要为每一个实体指称确定其指向的实体
- 基于图的方法
基于图的方法将实体指称、实体以及他们之间的关系通过图的形式表示出来,然后在图上对实体指称之间、候选实体之间、实体指称与候选实体之间的关联关系进行协同推理。 - 基于概率生成模型
基于概率生成模型对实体提及和实体的联合概率进行建模,可以通过模型的推理求解实体消歧问题 - 基于主题模型的方法
基于同一文本中出现的实体应该与文本表示的主题相关的思想,通过实体-主题模型,可以对实体在文本中的相容度,实体与话题的一致性进行联合建模,从而提升实体链接的结果。 - 基于深度学习的方法
在候选实体消歧的过程中,准确计算实体的相关度十分重要。因为在利用上下文中信息或进行协同实体消歧时,需要评价实体与实体的相关度。
参考
- https://github.com/npubird/KnowledgeGraphCourse