盘点 | 单目视觉3-D目标检测经典论文(附解读)
2020年以来出现的一些单目视觉3-D目标检测的论文。本文针对部分典型的论文要点进行要点解读,仅供参考。
Towards Generalization Across Depth for Monocular 3D Object Detection
arXiv 1912.08035,v3,4,2020

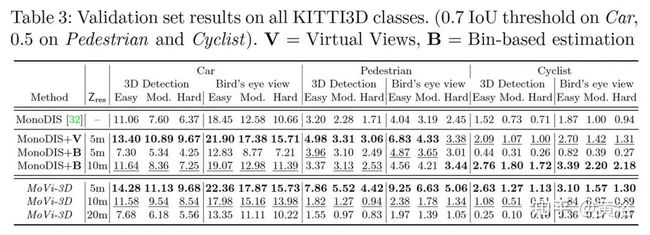
介绍单步法,MoVi-3D,在训练和测试中,利用几何信息,生成目标外观被距离规范化的虚拟视角。结果是,模型减轻学习深度图特定的表示,复杂度降低。
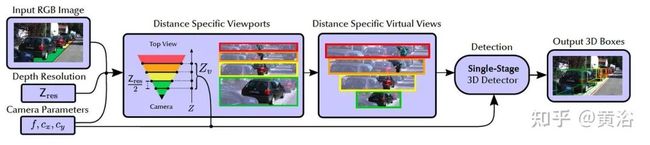
如图所示:不直接在原图进行检测,而是在虚拟图像,并且距离规范化。
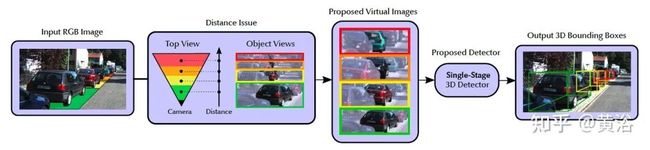
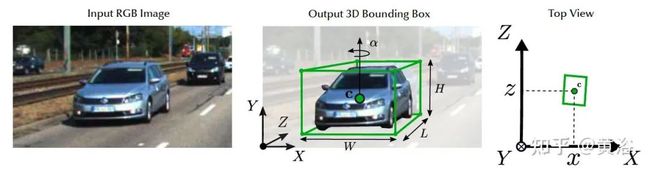
如下是单目3D目标检测的示意图:3D边框参数估计
这样需要阐述的是图像变换如何定义,如图所示是先定义一个3D视角口(3D viewport):和图像平面平行,基于深度而设置。
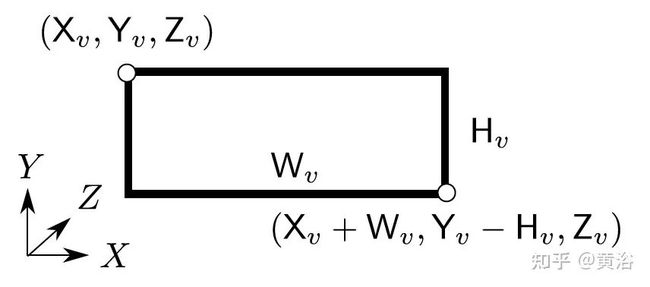
那么虚拟图像的产生是这样过程:给定使用上述摄像头和视角口捕获的图像,分别计算视角口的左上角和右下角,即(Xv,Yv,Zv)和(Xv + Wv,Yv-Hv,Zv),并将它们投影到相机的图像平面,从而产生 2D视角口的左上角和右下角。将其裁剪并重新缩放为所需的分辨率wv x hv,获取最终输出,即给定3D视角口生成的虚拟图像。
其中视角口的宽度为 (f是焦距,高度是预定义)

训练过程中虚拟图像的产生过程如图:
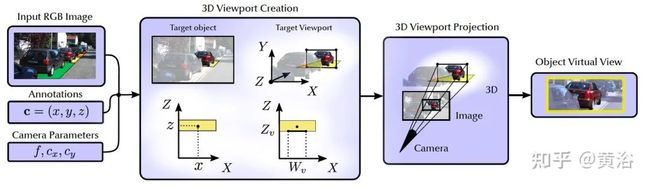
而测试过程的流水线如下:给定图像、深度分辨率Zres和摄像头参数,沿着Z轴每隔Zres/2米设置,产生一系列的3D视角口(Yv = 0),投影到图像平面(如同训练过程),最后的虚拟视图送入模型检测目标。
这里虚拟图像分辨率:
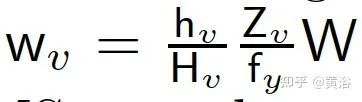
其中W是图像宽度。
最后看看MoVi-3D,主干是ResNet34,带FPN,检测头在RetinaNet修改,其架构图如下:

文章定义的参考目标大小是:宽-高-长
-
Car W0 = 1:63m, H0 = 1:53m, D0 = 3:84m,
-
Pedestrian W0 = 0:63m, H0 = 1:77m, D0 = 0:83m
-
Cyclist W0 =0:57m, H0 = 1:73m, D0 = 1:78m
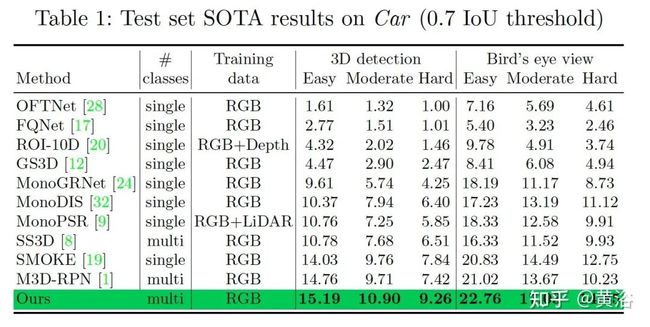
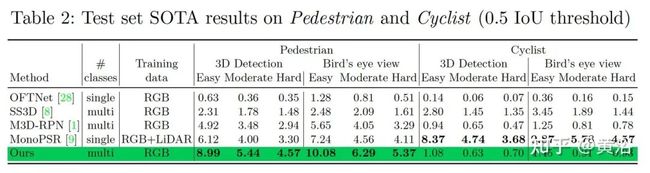
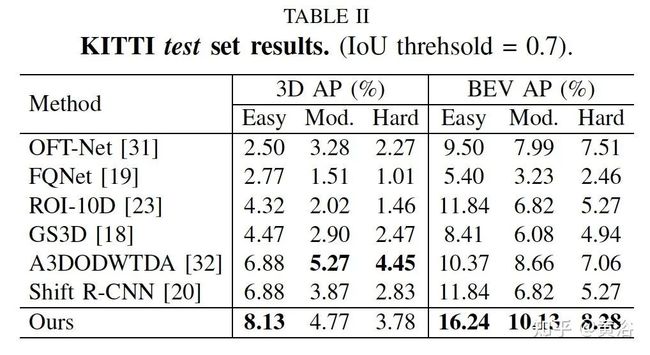
结果比较如下表所示:
RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving
arXiv 2001.03343,1,2020

单步法,利用3D边框的9个keypoints图像透视投影预测,以及3D-2D投影的几何关系,来恢复目标的大小、位置、朝向。不过,训练不需要额外的网络或者监督数据。
代码将上线:Banconxuan/RTM3D
如图是该方法的概览:8个框点和1个中心点,预测其图像投影。

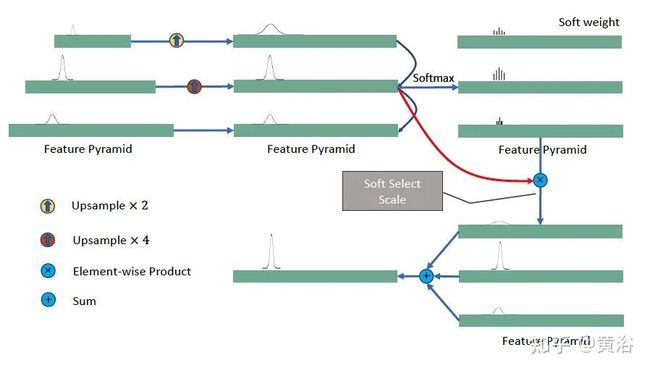
首先是keypoint 检测网络:主干、keypoint特征金字塔(KFPN)、检测头。基本上是一步法,类似无锚框的架构。输出各个点的热图(9个)。检测头类似CenterNet。

其中KFPN的细节展示:
给定KFPN的keypoint结果,3D边框的估计是如下2Dkeypoint和3D边框投影之间的误差最小优化问题:求解最佳朝向R、位置T和大小D
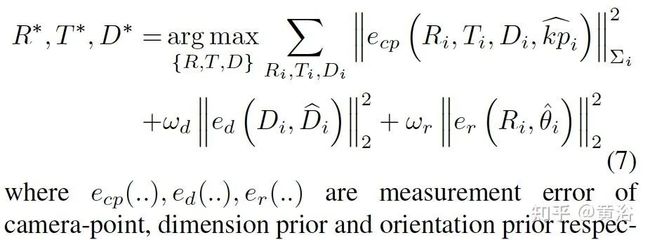
其中方差矩阵反应的是热图可信度:
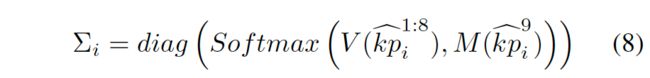
3D边框的顶点和中心定义为:
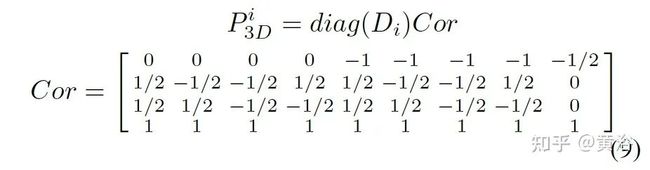
3D点的投影则是:

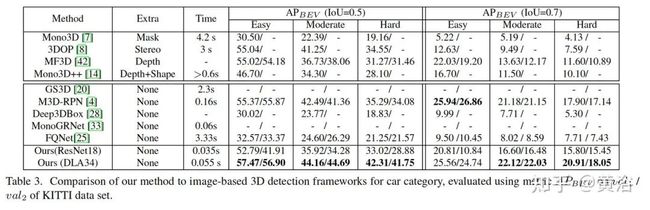
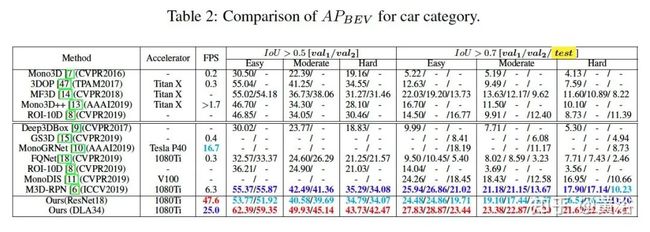
实验结果比较如下:

Monocular 3D Detection with Geometric Constraints Embedding and Semi-supervised Training
arXiv 2009.00764,9,2020
是上个方法的改进版,KM3D-Net,提出半监督训练。对同一个未标注图像,两个共享参数的KM3D-Net,不同输入增强和网络正则化条件下,强制实现一个一致性的预测。特别是,统一坐标相关的增强如仿射变换,提出keypoint dropout模块做网络正则化。

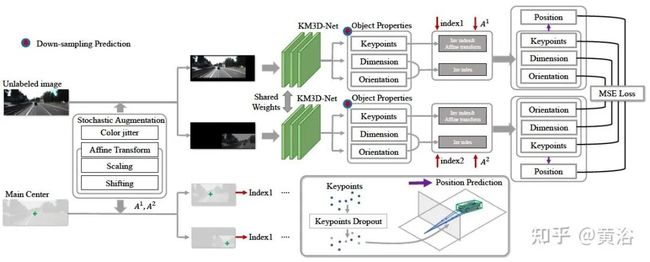
如图是KM3D-Net示意图:基本包括两个部分,一是全卷积网络,输出目标表观相关的特性,如keypoints、目标大小、局部朝向和3D可信度,接着二是几何推理模块,做位置预测的可微分几何一致性约束。

而无监督训练的示意图如下:利用仿射变换和keypoint -dropout。
基本思想是用KM3D-Net通过不同的增强和正则化两次评估同一输入图像。无监督损失通过取均方差(MSE损失)来惩罚图像中同一目标的不同估计。输入增强包括两个部分:坐标独立和坐标相关。第一个组件是随机颜色抖动。第二部分包括随机水平翻转、平移和缩放。将这些操作公式化为仿射变换,转换或恢复主要中心点和关键点的坐标。坐标相关的增强以矩阵形式的统一表达可以满足网络的可微分性。
此外,提出用于网络正则化的keypoint dropout方法。在位置预测中随机丢弃关键点。一个关键点可以提供两个几何约束,至少两个关键点可以计算三自由度的位置信息。因此,在计算位置信息时,删除9个关键点的一些是合理的。它有两个好处:1)使模型在预测非丢失关键点时更加准确;2)包含所有关键点的推断具有更强的泛化能力。输入增强和关键点dropout使相同的网络权重在训练步骤中输出一个随机变量。给定相同的输入,它们的差异可视为优化目标。
无监督损失定义为:

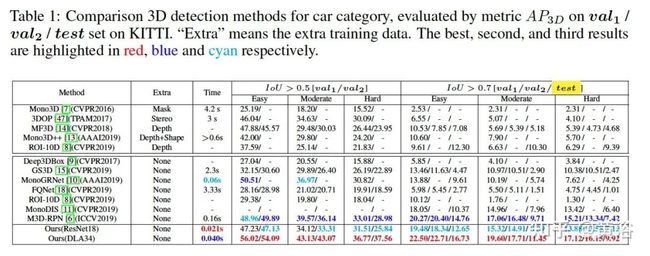
实验结果比较如下:
SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation
arXiv 2002.10111, 2, 2020

分析2D detection network冗余并且给3D detection带来噪声,故提议SMOKE, 直接结合回归3D变量的keypoint估计预测3D边框。此外,提出一个multi-step disentangling 变换法,改进了收敛性和检测精度。
SMOKE架构如图所示:hierarchical layer fusion network DLA-34做主干,其中类似地采用Deformable Convolution Network (DCN),BatchNorm (BN) 被 GroupNorm (GN)取代。主干从图像提取特征,原始图像下采样1/4,特征图的大小为1:4。两个单独分支连接到特征图,共同执行keypoint分类(粉红色)和3D框回归(绿色)。通过组合来自两个分支的信息来获得3D边框。
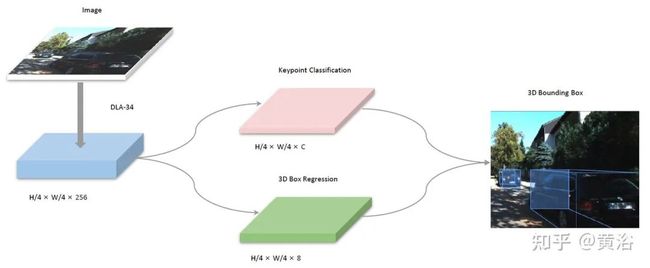
keypoint分类网络:每个目标都由一个特定的关键点表示;关键点不是定义2D边框的中心,而是定义为目标3D中心在图像平面的投影。
3D投影2D图像平面过程:
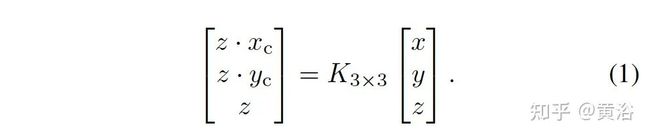
如图所示:2D中心(红色)和3D中心投影(橙色)的不同。

回归网络:回归分支负责预测3D边框所需的变量,取决于热图的每个关键点;受lifting transform想法(“ROI-10D:Monocular lifting of 2d detection to 6d pose and metric shape”)启发,加入类似操作将投影的3D点转换为3D边框。
3D目标信息编码为:

目标深度根据预定义尺度和移动参数计算:
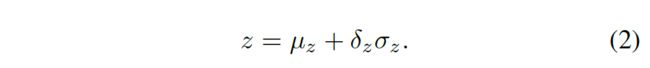
由此得到目标位置:

事先在整个数据集计算类别平均大小, 然后恢复每个目标大小:
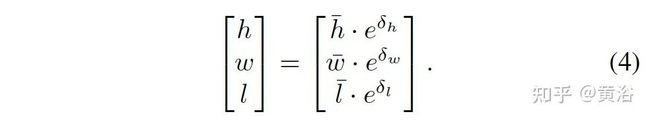
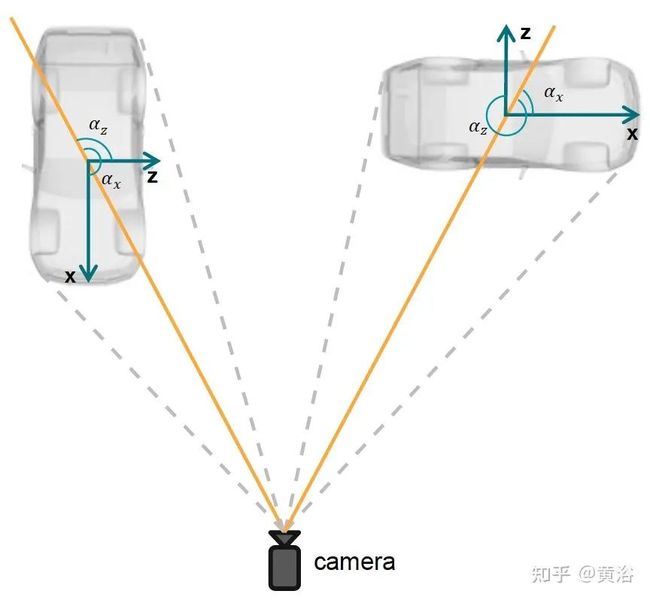
类似回归的是每个目标的观测角,而不是偏航角。另外,更改相对于目标头alpha x-轴的观察角度,而不是通常使用的相对于目标头alpha z-轴的观察角度值,二者区别如图所示:差90度。
偏航角根据观测角和目标位置得到:

最后3-D边框的8角点计算:

训练的损失函数也是分成两部分:分类和回归(略)。
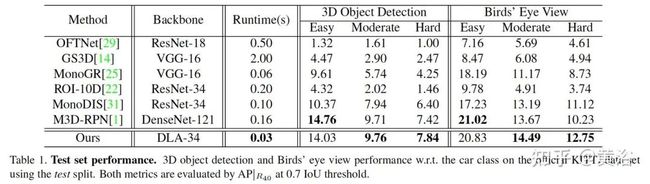
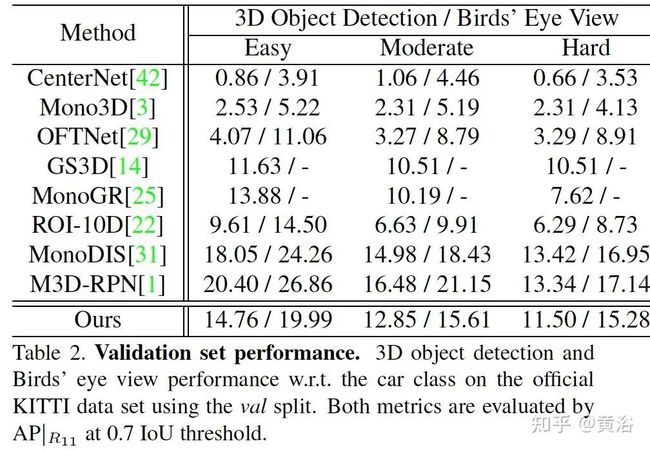
实验结果比较如下:
MonoPair: Monocular 3D Object Detection Using Pairwise Spatial Relationships
arXiv 2003.00504, 3, 2020

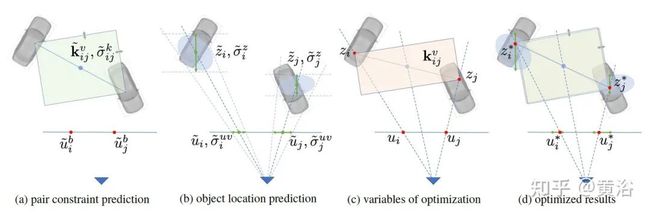
MonoPair考虑成对样本的联系。这样,对部分遮挡目标和其邻域的空间约束进行编码。特别是,计算相邻目标对的目标位置和3D距离的不确定性-觉察(uncertainty-aware)预测,并随后做非线性LS联合优化。这种预测结构和后优化模块能特别地集成在一起提高运行效率。
如图是架构概览图:单目RGB图像作为骨干的输入,在监督下进行训练。具有特征图 W x H x m (64)的11个不同预测分支,分为三个部分:2D检测、3D检测和成对约束预测。输出特征的宽度和高度(W,H)与骨干输出相同。虚线表示神经网络的正向流动。2D检测的热图和偏移量也可用于定位3D目标中心和成对约束keypoint。
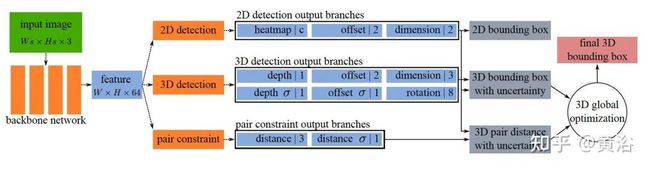
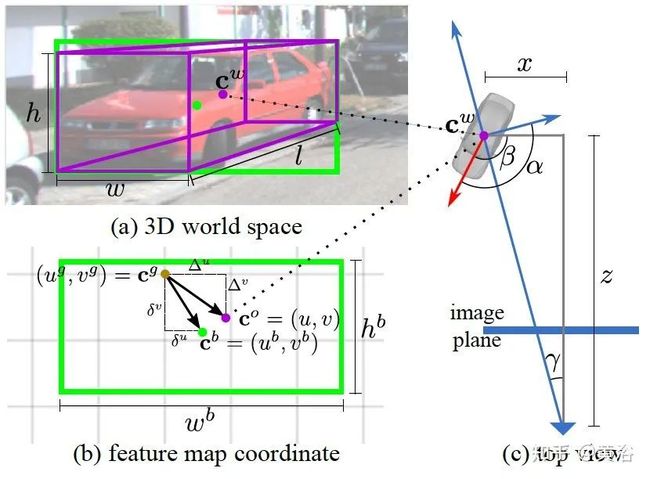
文章的特征图坐标-3D空间的几何关系如图所示:
2D检测来自CenterNet,3D中心推理来自摄像头内参数K:
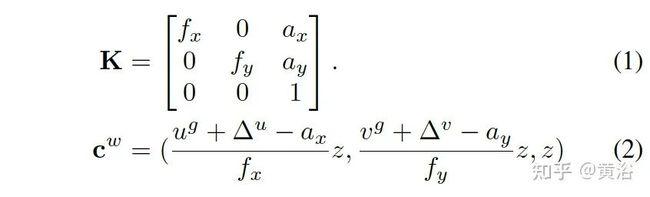
成对约束分支是一个回归,其中成对目标约束定义如图:3D距离在不同坐标下的显示。

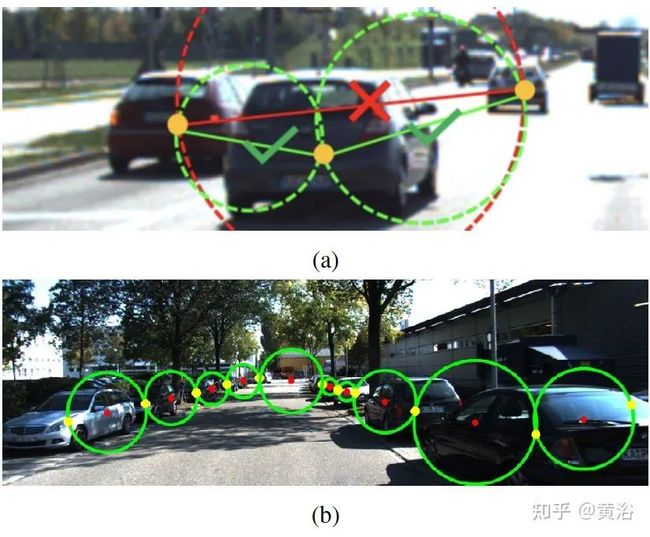
而成对匹配策略的训练和推理如图所示:
对不确定性估计(用于最后联合优化),附加定义一个regression L1 loss:

最后的后处理是基于图理论的空间约束优化,如图所示:
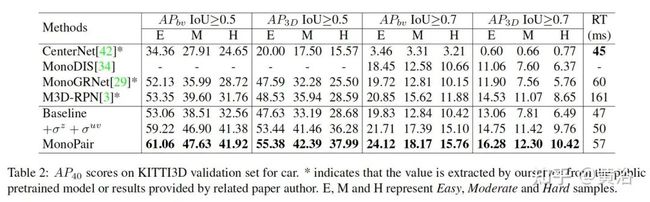
最后看实验结果比较:
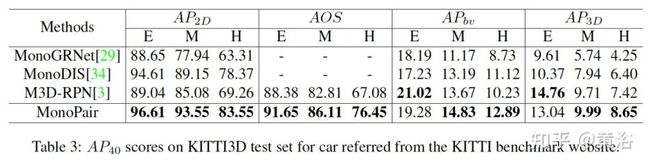

Monocular 3D Object Detection with Decoupled Structured Polygon Estimation and Height-Guided Depth Estimation
arXiv 2002.01619,2,2020

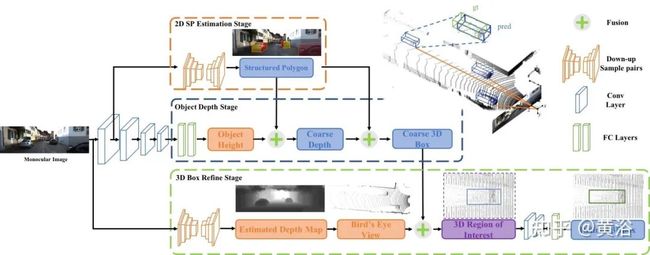
本文提出一种解耦方法,即分成结构化多边形预测和深度恢复两个任务。这里需要一个先验知识,目标高度和给定的摄像头姿态(内外参数)。还提供有一个BEV细化3D边框的方法。
如图是整个网络框架(Decoupled-3D):stacked hourglass network做2D结构化多边形产生;目标深度估计(高度作为先验知识);BEV特征做3D边框细化。
这图是结构化多边形估计的部分细节:
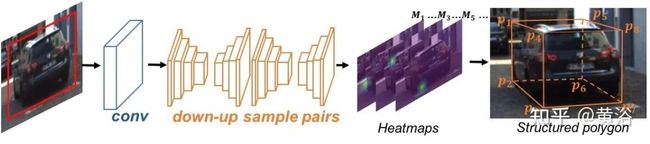
这是高度指导的深度估计:

其中各个顶点的深度表示为:

下图是3D框细化示意图:
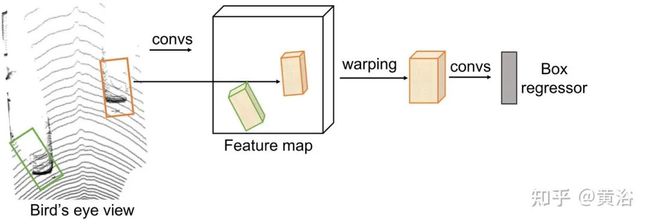
其中深度估计采用Depth Net:DOR (“Deep Ordinal Regression Network for Monocular Depth Estimation“)。
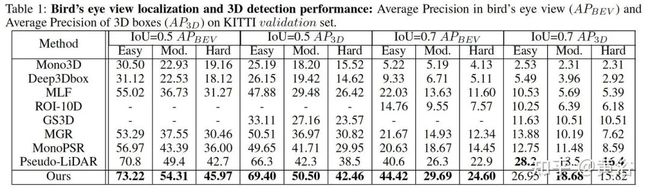
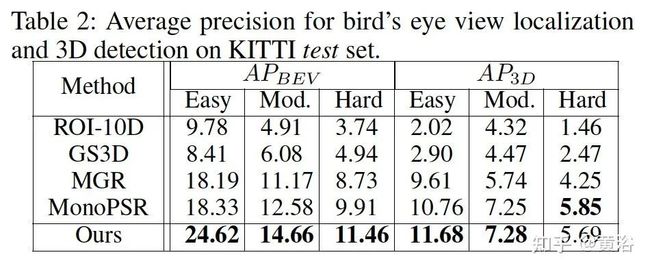
下面是实验结果比较:
定性结果展示:
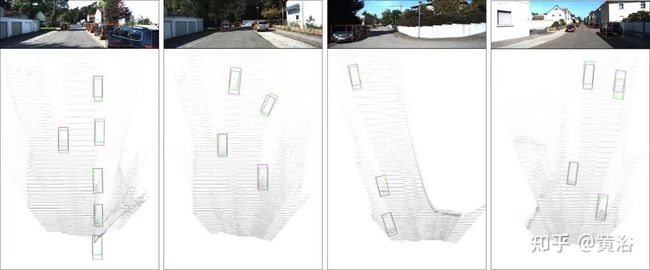
Exploring the Capabilities and Limits of 3D Monocular Object Detection - A Study on Simulation and Real World Data
arXiv 2005.07424,5,2020

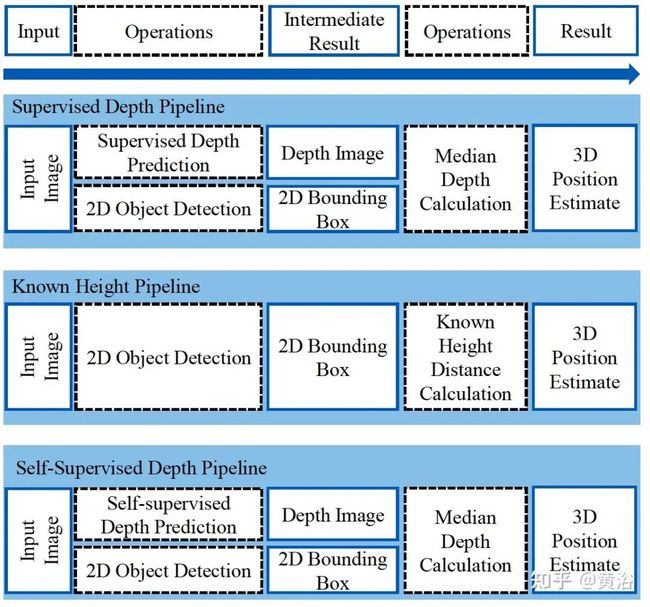
有趣的工作:3D 目标检测的深度估计设置比较。采用模拟数据进行比较,也用了一个真实数据。讨论了各种深度估计策略对3D目标检测的影响。
如图就是3种设置:
-
使用2D边框高度和真实世界赛车的已知高度作为几何约束的距离计算,该方法叫做“已知高度假设”。
-
使用监督的DenseDepth网络对整个图像进行深度估计。到每个目标的距离被计算为边框裁剪的深度估计中值。这种方法不需要有关目标的明确知识,例如高度信息。
-
使用自监督的struct2depth网络对整个图像进行深度估计。到每个目标的距离被计算为边框裁剪的深度估计中值。这种方法也不需要有关目标的明确知识,例如高度信息。
这是实验结果比较:
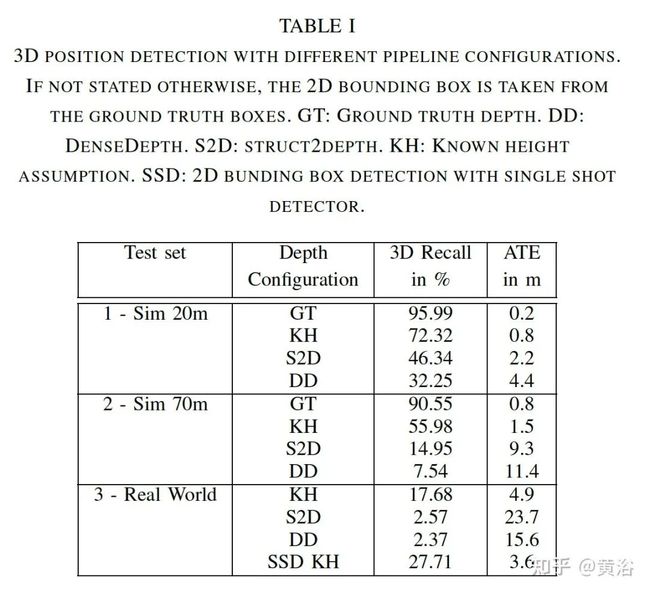
深度网络结果在有限的范围(例如一般的光学印象)在数据集进行泛化。如果更改了相机的固有特性或输入图像的分辨率,则泛化性会进一步降低。这个学习仅在特定条件下有效。当把结果推算到大量训练数据情况,结论是,对于20m距离的近距离场景,使用当前方法可以很好地执行3D目标检测。距离越远,检测性能越差。从理论上讲,通过更高的图像分辨率来补偿,但需要更高的整体数据速率。可选地,组合具有小和宽视野的摄像机,实现在额外期望距离下的精确检测。系统复杂性和包装要求更高。
目前将相机信息与测距传感器(如激光雷达和雷达)融合,似乎仍然是在3D模式下执行目标检测的最有效方法。
Object-Aware Centroid Voting for Monocular 3D Object Detection
arXiv 2007.09836",7,2020

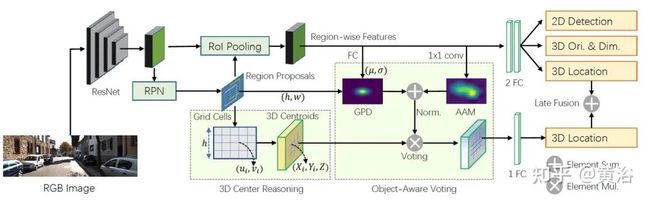
该方法无需学习深度图。2D 边框的格坐标反投到3D空间做3D目标中心提议。加一个object-aware voting和后融合得到3D边框。
如图是架构图:RPN模块提供2D region proposals,3D Center Reasoning (左边) 从2D ROI 格坐标估计多个 3D centroid proposals,接着是Object-Aware Voting (右边)包括 geometric projection distribution (GPD) 和 appearance attention map (AAM),投票 3D centroid proposals 得到3D 位置。另外,2D目标检测头、3D 大小 和 朝向一起估计得到。
对于行车道路上的目标,它们水平放置,没有相对于摄像机的偏航角和俯仰角。此外,每类目标(例如车辆)的3D尺寸方差都非常小。这些约束导致这样的想法,即当物体处于相同深度时,物体在图像上的视在高度近似不变。最近的调查还指出,KITTI数据集上图像目标的位置和表观大小可用于推断深度。
这里目标3D中心近似为

具体来说,将每个2D区域提议划分为s x s 网格单元,并将网格坐标投影回3D空间。由于每个网格点都给出相应3D目标中心的可能投影,因此获得多个3D中心提议,其中第i个中心提议由下式计算:
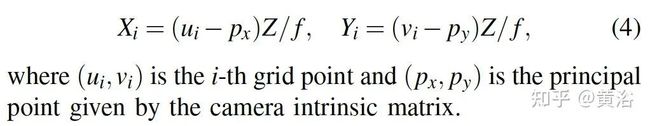
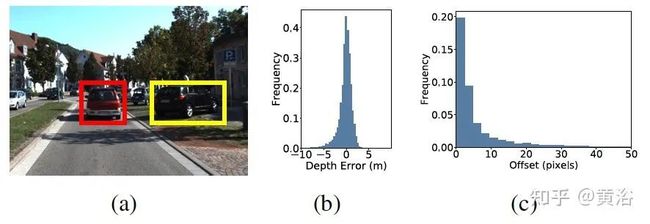
下图是在Kitti数据训练数据得到的中心偏差统计:
具体而言,使用单个1X1卷积,然后采用S-激活函数,从RoI池化层的特征图生成外观注意图(appearance attention map)。来自图像激活的卷积特征图,通过2D目标检测的分类监督,给出前景语义目标,从而得到对目标-觉察投票(object-ware voting)。
该投票成分来自投影3D中心和2D边框中心之间的偏移分布。已经有证明2D边框中心可以建模为高斯分布,并具有真值期望,为了动态学习该分布,将RoI的2D网格坐标和图像特征连接在一起作为全连接层的输入预测偏移量,以Kullback-Leibler(KL)散度作为损失函数来监督学习,即
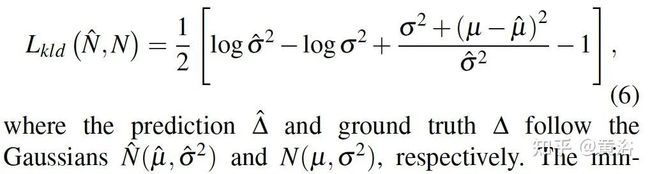
其中object-aware voting 定义为:

在训练中,3D定位流水线的损失函数是:

3D 大小的损失函数:

3D朝向的损失函数:

2D和3D目标检测的联合任务训练损失函数为:
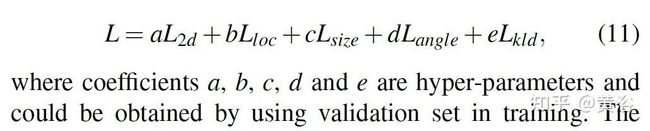
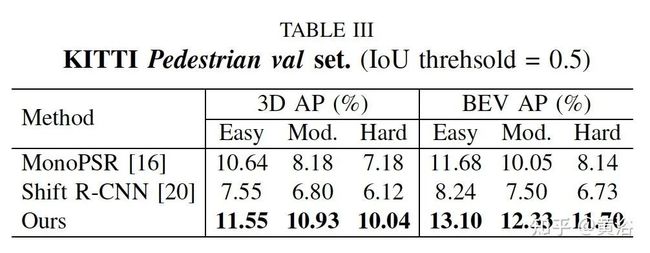
实验结果比较如下:

定性结果比较:红色: 检测框. 黄色: 真值. 右边小图: birds’ eye view (BEV) 。

未完,待续。。。
作者:黄浴
|关于深延科技|

深延科技成立于2018年,是深兰科技(DeepBlue)旗下的子公司,以“人工智能赋能企业与行业”为使命,助力合作伙伴降低成本、提升效率并挖掘更多商业机会,进一步开拓市场,服务民生。公司推出四款平台产品——深延智能数据标注平台、深延AI开发平台、深延自动化机器学习平台、深延AI开放平台,涵盖从数据标注及处理,到模型构建,再到行业应用和解决方案的全流程服务,一站式助力企业“AI”化。