MySQL数据库的约束

文章目录
- 一、约束是什么?
- 二、约束的具体操作
-
- Not NULL
- UNIQUE
- 约束的组合使用
- PRIMARY KEY
- DEFAULT
- FOREIGN KEY
一、约束是什么?
约束就是,在创建表的时候,对表设置一些规则,只有满足这些规则,才可以插入数据,我们把这些规则叫做约束
常见的约束有:
| 约束类型 | 规则 |
|---|---|
| Not Null | 指定某列不能存储NULL值 |
| UNIQUE | 保证某列的每行必须有唯一的值 |
| DEFAULT | 给没有赋值的列赋默认值 |
| PRIMARY KEY | Not NULL 与 UNIQUE的结合,一个表的特定记录 |
| FOREIGN KEY | 保证一个表匹配另一个表的值,遵守参照完整性 |
| CHECK | 保证列符合指定条件 |
数据库约束是数据库的一个重要功能,数据的 “完整性”(正确的数据)可以通过人工的方式进行确定,但人工还是有一点的缺陷,约束,就是让数据库帮助我们更好的检查数据是否正确
二、约束的具体操作
Not NULL
create table stu(
id int,
name varchar(50),
sex char(3)
);
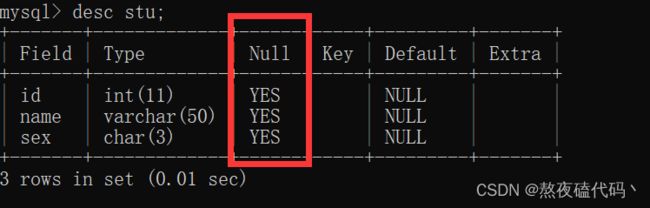
当我们建一个表时,是允许为NULL的,如果我们不允许这一列为空时,我们就需要加上Not NULL约束。
create table stu(
id int not null,
name varchar(50),
sex char(3)
);
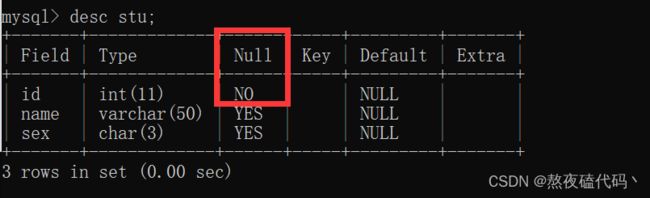
当我们加上约束时,可以发现id这一列不允许为空,我们试着插入一个为NULL的id试一下。

当我们插入的id为空时,系统会报id 这一列不能为空的错误。

当我们插入一个非NULL的数据时,可以成功插入。
UNIQUE
在我们某些业务需要中某些列的数据不能够重复,比如: 我们每个人的身份证号,大学生的学号,这些数据是唯一标识性的不能够重复。
create table stu(
id int unique,
name varchar(50),
sex char(3)
);
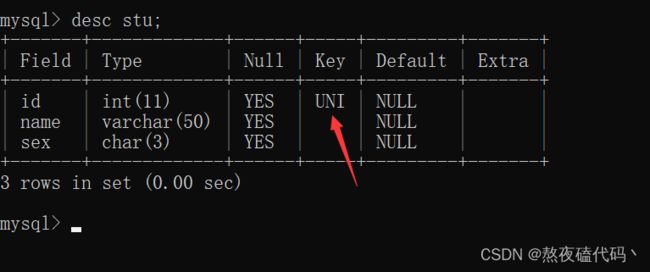
这里的UNI == unique.
我们试着插入一下数据看看。
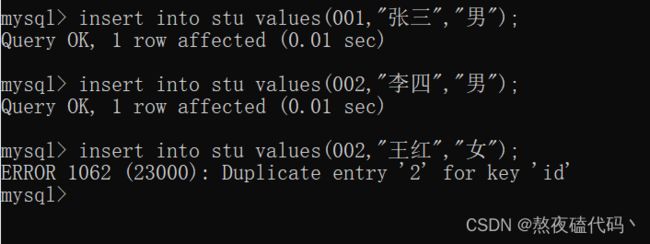
我们可以发现再插入不同的id数据时是可以正常插入的,当我们再次插入已经出现过的id时,系统会报一个重复条目的错误。
一个小小的思考,数据库是如何判断你当前这一条记录是否为重复的?
当然是先去查找,然后再去插入。
有的同学肯定会说,加上约束之后,数据库的执行速度不就大大的下降了,这里的查找是(借助索引进行查找的,效率相对比较高,后面我们会介绍索引的相关知识),执行效率确实受到了一定的影响,但比起手工去检查,代价小的很多。
约束的组合使用
约束不仅可以单独使用,而且可以多个组合起来对某一列进行约束。
比如同时加上: Not NULL 和 unique(这里注意的是多个约束之间用空格间隔开,而不是逗号).
![]()
我们可以发现约束之间用逗号间隔会报错。

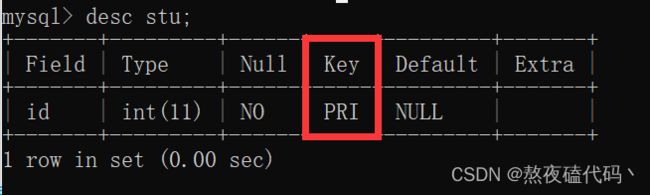
我们可以发现当我们同时使用 Not NULL 和 unique约束时,出现了一个PRI,PRI == primary key,这是什么我们往下看。
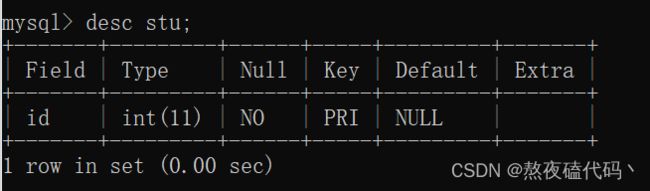
PRIMARY KEY
主键约束就是: not null + unique.
我们试着插入几组数据。

我们可以发现主键列不能插入NULL类型的数据。
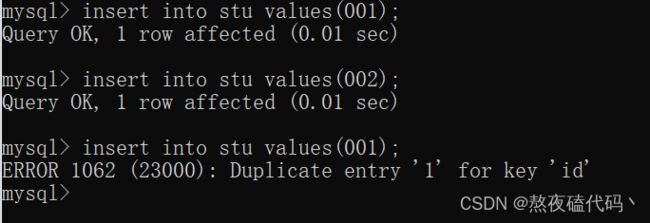
我们可以发现主键列插入不同的数据是OK的,如果插入相同的数据,就会报错。
主键也同样是在插入记录的时候,先查询,在插入:
正因为主键和unique都有先查询的过程,mysql就会默认给这些列添加索引,提高查询速度。

我们可以简单来验证一下,我们可以发现id列确实存在索引。
主键的注意事项:
1.在开发过程中,大部分的表都会存在一个主键,逐渐往往是一个整数类型的id.
2.在mysql中,一个表里,只能存在一个主键,不能多个。
3.mysql允许将多个列共同作为一个主键(联合主键)
4.mysql有自带的"自增主键"(主键需要保证不重复,如果我们手动生成的话比较困难,这时我们就可以让mysql自动帮我们生成。
-- 设置自增主键
create table stu(id int primary key auto_increment);
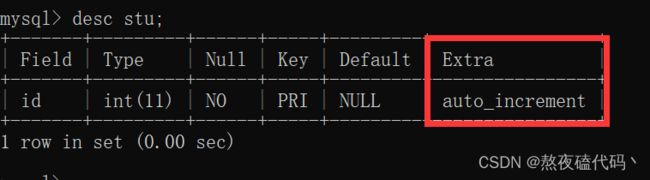

当我们将某一列设置为自增主键时,如果需要系统自动生成的话,我们插入null即可, 这里的null不是说把这个值设置为Null,而是交给数据库使用自增主键。
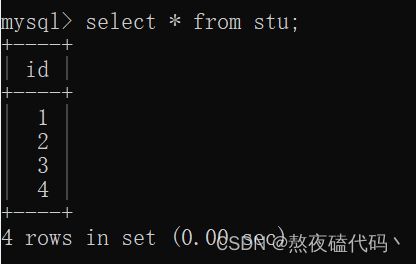
每一个插入数据时,mysql都会找到上一条记录,自增。

我们也可以插入指定值。
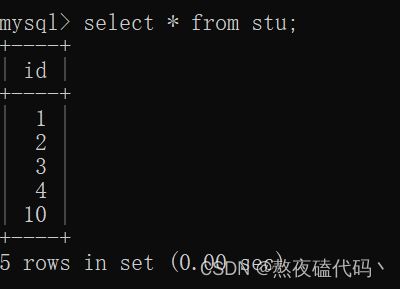
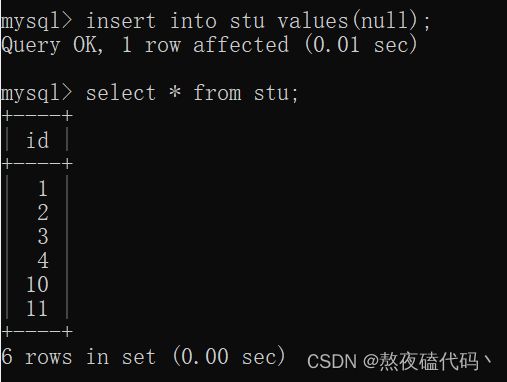
我们可以发现,当我们指定值插入后,在使用自增主键,并不会去利用中间空余的间隙,而是参照最大值进行自增。(这里其实是我们很常见的一个用空间换取时间的行为).
如果mysql的数据量非常大时,自增主键还可以使用吗?如果可以使用,又是如何分配呢?
当我们数据量较小时,所有的数据都在mysql服务器当中存储。
但是如果mysql的数据量很大时,一台主机可能放不下,就需要进行分库分表的操作。

当数据过多时,就需要分库分表,实际上就是把一个大的表分为多个小的表,每个服务器存取一部分数据。
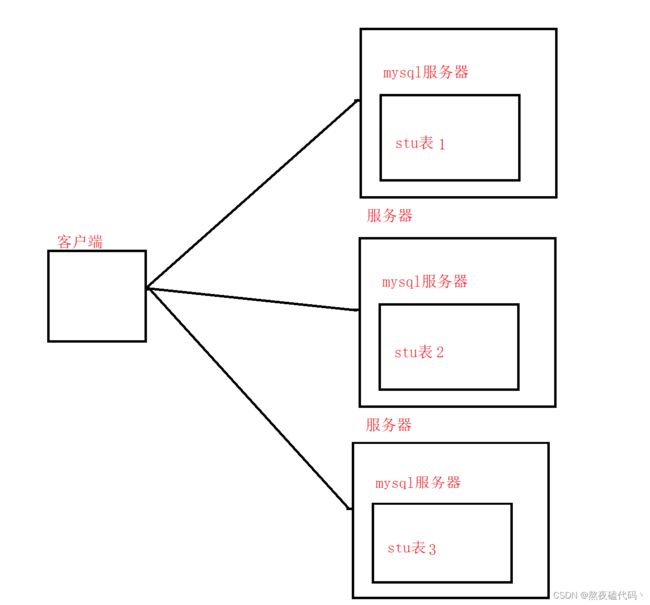
这里我们就分为三个服务器进行存储,每个服务器的表占各自的比例,三个服务器中的主键值是不能重复的。
三个服务器中的表的自增主键id是如何分配?
这里涉及到"分布式系统唯一id生成算法"
大概公式是: 时间戳 + 主机编号 + 随机因子 > 这三部分得到一个全局唯一的id
DEFAULT
在某些情况下,有些列的值大多数都是重复的,比如一个班的30个人,28个是男生,只有两个女生,那么我们就可以把性别列默认值设置为"男".
create table stu(id int primary key,name varchar(50),sex char(3) default '男');

我们可以看到性别这一列默认为男。
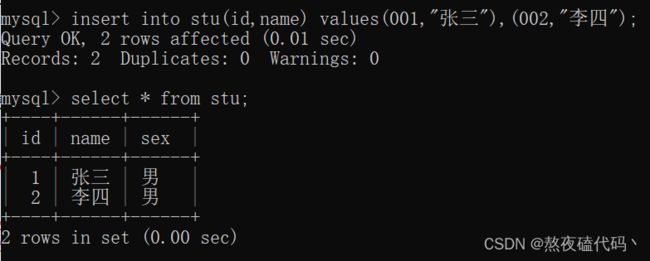
我们可以发现当我们没有插入sex这一列,自动为默认值’男’.
FOREIGN KEY
外键约束是建立在两张表之间的约束。
比如每个班的同学的班级号都是一样的,我们就可以用班级号来建立班级表和学生表之间的约束.
create table class(classId int primary key,name varchar(50));
我们先创建一个班级表,插入一组数据。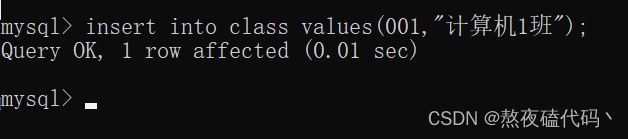
create table stu(id int primary key,name varchar(50),classId int,foreign key(classId) references class(classId));

这个是外键约束的语法。
外键约束的含义时,stu表中的classId必须在class表中是存在的。

当我们插入class存在的classid为001的数据可以成功插入。

当我们插入的classId在class中不存在时,就会插入失败。

此处起到约束的class表是"父表(parent)",被约束的表叫做"子表(child).
实则不然,我们子表对父表也产生了一定的约束。

我们可以发现,无法删除外键约束的父表。
这也很好理解,如果父表删除了,子表的数据去哪里参考,如果想删除,可以先删除子表,在删除父表。

我们可以发现当父表相应列不是主键时,无法建立外键约束,这是为什么呢?
因为每次再给子表插入时,都会先在父表先查询这个id是否存在,如果表的数据十分大时,效率十分地低,要使用索引。
要想创建外键,就要求父类相应的列,有primary 或者 unique约束