吐血整理的Hadoop最全开发指南【Hadoop集群搭建篇】
个人主页:个人主页
推荐专栏:大数据开发成神之路
作者简介:一个读研中创业、打工中学习的能搞全栈、也搞算法、目前在搞大数据的奋斗者。
⭐️关注我,持续分享干货!用实打实的经验来帮你少走弯路⭐️
文章目录
- 一、 Hadoop为何物
-
- 1.1 Hadoop的整体认识
- 1.2 Hadoop的架构
-
- 1.2.1 HDFS架构简介
- 1.2.2 YARN架构简介
- 1.2.3 MapReduce架构简介
- 1.2.4 Hdfs、Yarn和MapReduce三者关系
- 二、Hadoop的发行版本
-
- 2.1 Apache版本
- 2.2 Cloudera版本
- 2.3 Hortonworks版本
- 三、为Hadoop集群环境构造模板
-
- 3.1 安装模板机
- 3.2 设置静态IP地址
- 3.3 安装并配置JDK
- 3.4 安装并配置Hadoop
在上文我们通过VMWare软件已经搭建好了本地Hadoop的运行环境(详情见环境配置:吐血整理的Hadoop最全开发指南【环境准备篇】)

这一篇对Hadoop的版本和组件体系进行系统说明,把握Hadoop组件架构,是对其进行开发根本。
一、 Hadoop为何物
1.1 Hadoop的整体认识
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,它主要是用来解决海量数据的存储和分析计算的问题。从广义的角度来说,Hadoop通常是指Hadoop生态圈。

1.2 Hadoop的架构
现有的Hadoop发行版本囊括了1.x、 2.x 、 3.x。这三个版本在功能组件上存在着一定的差异。

-
在Hadoop 1.X时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性非常大。
-
在Hadoop 2.X时代,增加了Yarn, Yarn只负责资源的调度,而原来的MapReduce只负责运算,Hadoop 3.x 在组成上没有变化。
1.2.1 HDFS架构简介
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
其中有三个重要的节点:NameNode 和 DataNode 以及 SecondNameNode

-
(1)NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
-
(2)DataNode:在本地文件系统存储文件块数据,以及块数据的校验和。
-
(3)Secondary NameNode(2NN):每隔一段时间对NameNode进行备份。
1.2.2 YARN架构简介
Yet Another Resource Negotiator简称YARN ,另一种资源协调者,是Hadoop的资源管理器。
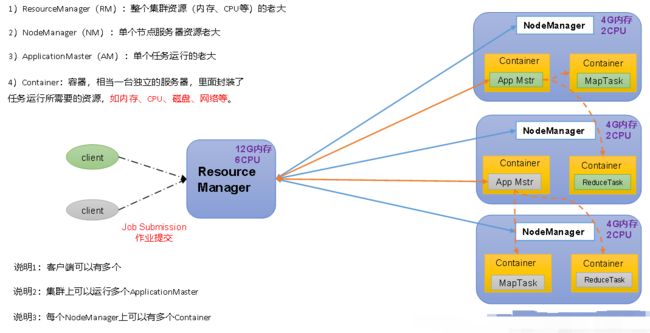
1.2.3 MapReduce架构简介
MapReduce将计算过程分为两个阶段:Map和Reduce
- 1)Map阶段并行处理输入数据
- 2)Reduce阶段对Map结果进行汇总

1.2.4 Hdfs、Yarn和MapReduce三者关系
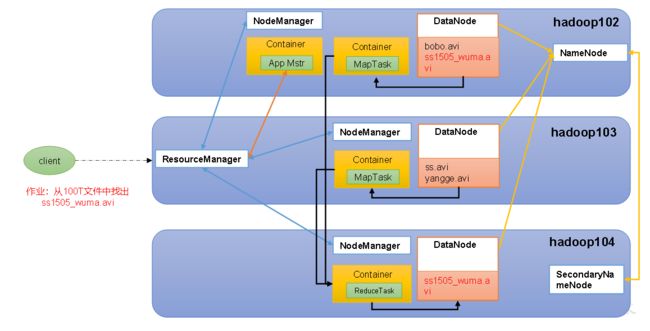
二、Hadoop的发行版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
- Apache版本最原始(最基础)的版本,对于入门学习最好。2006
- Cloudera内部集成了很多大数据框架,对应产品CDH。2008
- Hortonworks文档较好,对应产品HDP。2011
- Hortonworks现在已经被Cloudera公司收购,推出新的品牌CDP。
2.1 Apache版本
官网地址:http://hadoop.apache.org
下载地址:https://hadoop.apache.org/releases.html
2.2 Cloudera版本
官网地址:https://www.cloudera.com/downloads/cdh
下载地址:https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_6_download.html
(1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。Cloudera的标价为每年每个节点10000美元。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。
2.3 Hortonworks版本
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
(1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(4)2018年Hortonworks目前已经被Cloudera公司收购。
三、为Hadoop集群环境构造模板
为了实现快速搭建Hadoop集群环境,我们在本地最快的方式在于通过创建一个虚拟机模板然后进行复制粘贴即可!
3.1 安装模板机
-
0)安装模板虚拟机,IP地址192.168.10.100、主机名称
hadoop100、内存4G、硬盘50G -
1)hadoop100虚拟机配置要求如下(本文Linux系统全部以CentOS-7.5-x86-1804为例)
(1)使用yum安装需要虚拟机可以正常上网,yum安装前可以先测试下虚拟机联网情况
[root@hadoop100 ~]# ping www.baidu.com
PING www.baidu.com (14.215.177.39) 56(84) bytes of data.
64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=1 ttl=128 time=8.60 ms
64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=2 ttl=128 time=7.72 ms
(2)安装epel-release
注:Extra Packages for Enterprise Linux是为“红帽系”的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux。相当于是一个软件仓库,大多数rpm包在官方 repository 中是找不到的)
[root@hadoop100 ~]# yum install -y epel-release
(3)注意:如果Linux安装的是最小系统版,还需要安装如下工具;如果安装的是Linux桌面标准版,不需要执行如下操作
net-tool:工具包集合,包含ifconfig等命令
[root@hadoop100 ~]# yum install -y net-tools
vim:编辑器
[root@hadoop100 ~]# yum install -y vim
- 2)关闭防火墙,关闭防火墙开机自启
[root@hadoop100 ~]# systemctl stop firewalld
[root@hadoop100 ~]# systemctl disable firewalld.service
注意:在企业开发时,通常单个服务器的防火墙时关闭的。公司整体对外会设置非常安全的防火墙
- 3)创建taoren用户,并修改taoren用户的密码
[root@hadoop100 ~]# useradd taoren
[root@hadoop100 ~]# passwd taoren
- 4)配置taoren用户具有root权限,方便后期加sudo执行root权限的命令
[root@hadoop100 ~]# vim /etc/sudoers
修改/etc/sudoers文件,在%wheel这行下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
taoren ALL=(ALL) NOPASSWD:ALL
注意:taoren这一行不要直接放到root行下面,因为所有用户都属于wheel组,你先配置了taoren具有免密功能,但是程序执行到%wheel行时,该功能又被覆盖回需要密码。所以taoren要放到%wheel这行下面。
- 5)在/opt目录下创建文件夹,并修改所属主和所属组
(1)在/opt目录下创建module、software文件夹
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software
(2)修改module、software文件夹的所有者和所属组均为taoren用户
[root@hadoop100 ~]# chown taoren:taoren /opt/module
[root@hadoop100 ~]# chown taoren:taoren /opt/software
(3)查看module、software文件夹的所有者和所属组
[root@hadoop100 ~]# cd /opt/
[root@hadoop100 opt]# ll
总用量 12
drwxr-xr-x. 2 root root 4096 9月 7 2017 rh
drwxr-xr-x. 2 taoren taoren 4096 5月 28 17:18 software
drwxr-xr-x. 2 taoren taoren 4096 5月 28 17:18 module
-
6)卸载虚拟机自带的JDK
注意:如果你的虚拟机是最小化安装不需要执行这一步。
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
rpm -qa:查询所安装的所有rpm软件包
grep -i:忽略大小写
xargs -n1:表示每次只传递一个参数
rpm -e –nodeps:强制卸载软件
7)重启虚拟机
[root@hadoop100 ~]# reboot
3.2 设置静态IP地址
-(1)修改克隆虚拟机的静态IP
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
改成
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="ens33"
IPADDR=192.168.10.102
PREFIX=24
GATEWAY=192.168.10.2
DNS1=192.168.10.2
- (2)查看Linux虚拟机的虚拟网络编辑器,编辑->虚拟网络编辑器->VMnet8
- (3)查看Windows系统适配器VMware Network Adapter VMnet8的IP地址
- (4)保证Linux系统ifcfg-ens33文件中IP地址、虚拟网络编辑器地址和Windows系统VM8网络IP地址相同。
3.3 安装并配置JDK
- 1)卸载现有JDK
注意:安装JDK前,一定确保提前删除了虚拟机自带的JDK。
- 2)用XShell传输工具将JDK导入到opt目录下面的software文件夹下面
- 3)在Linux系统下的opt目录中查看软件包是否导入成功
[taoren@hadoop102 ~]$ ls /opt/software/
看到如下结果:
jdk-8u212-linux-x64.tar.gz
···
- 4)解压JDK到/opt/module目录下
```bash
[taoren@hadoop102 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
-
5)配置JDK环境变量
(1)新建/etc/profile.d/my_env.sh文件
[taoren@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
(2)保存后退出
:wq
(3)source一下/etc/profile文件,让新的环境变量PATH生效
[taoren@hadoop102 ~]$ source /etc/profile
- 6)测试JDK是否安装成功
[taoren@hadoop102 ~]$ java -version
如果能看到以下结果,则代表Java安装成功。
java version "1.8.0_212"
注意:重启(如果java -version可以用就不用重启)
[taoren@hadoop102 ~]$ sudo reboot
3.4 安装并配置Hadoop
Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
1)用XShell文件传输工具将hadoop-3.1.3.tar.gz导入到opt目录下面的software文件夹下面
2)进入到Hadoop安装包路径下
[taoren@hadoop102 ~]$ cd /opt/software/
3)解压安装文件到/opt/module下面
[taoren@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
4)查看是否解压成功
[taoren@hadoop102 software]$ ls /opt/module/
hadoop-3.1.3
5)将Hadoop添加到环境变量
(1)获取Hadoop安装路径
[taoren@hadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
(2)打开/etc/profile.d/my_env.sh文件
[taoren@hadoop102 hadoop-3.1.3]$ sudo vim /etc/profile.d/my_env.sh
在my_env.sh文件末尾添加如下内容:(shift+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存并退出: :wq
(3)让修改后的文件生效
[taoren@hadoop102 hadoop-3.1.3]$ source /etc/profile
6)测试是否安装成功
[taoren@hadoop102 hadoop-3.1.3]$ hadoop version
Hadoop 3.1.3
7)重启(如果Hadoop命令不能用再重启虚拟机)
[taoren@hadoop102 hadoop-3.1.3]$ sudo reboot
2.5 Hadoop目录结构
1)查看Hadoop目录结构
[taoren@hadoop102 hadoop-3.1.3]$ ll
总用量 52
drwxr-xr-x. 2 taoren taoren 4096 5月 22 2017 bin
drwxr-xr-x. 3 taoren taoren 4096 5月 22 2017 etc
drwxr-xr-x. 2 taoren taoren 4096 5月 22 2017 include
drwxr-xr-x. 3 taoren taoren 4096 5月 22 2017 lib
drwxr-xr-x. 2 taoren taoren 4096 5月 22 2017 libexec
-rw-r--r--. 1 taoren taoren 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 taoren taoren 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 taoren taoren 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 taoren taoren 4096 5月 22 2017 sbin
drwxr-xr-x. 4 taoren taoren 4096 5月 22 2017 share
2)重要目录
(1)bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例