无监督学习——自编码神经网络原理及其实现
一、自编码神经网络概述
1、信息处理问题
信息瓶颈
稠密信息转稀疏信息
稀疏信息转稠密信息
稠密信息转稠密信息
- 自编码神经网络介绍
自编码器是深度学习中的一种非常重要的无监督学习方法,能够从大量无标签的数据中自动学习,得到蕴含在数据中的有效特征.因此,自编码方法近年来受到了广泛的关注,已成功应用于很多领域,例如数据分类、模式识别、异常检测、数据生成等.它是一种生成模型。
- 自编码神经网络的结构
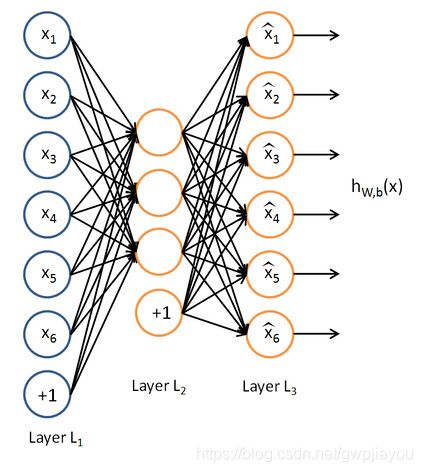
简单的理解,自编码网络其实就是通过从原始图片中不断的提取信息,再利用得到的特征图重新构建新的图片,构建的新图片中包含了原始图片中重要的特征信息,图片大小与原始图片是一样的。在图片数据的训练中,通常我们是直接对图片数据集进行训练的,但是这其实不是一种很好的方式,并不是图片中的所有信息都是我们需要的,利用自编码网络先提取出最有用的图片特征信息,然后再对图片训练,这样操作对图片的学习会更好一点。
二、自编码神经网络实现
自编码网络过程: 编码器 ————>解码器
下面对自编码网络进行实现,利用pytorch中手写数字识别这个例子进行效果说明。网络利用2828 大小的手写数字图片,经过特征提取得到3 * 3
的特征图,然后利用3 * 3 的特征图构建出大小为2828大小的手写数字图片。构建出来的图片虽然大小与原来图片一样,但是构建出来的图片并不是原来的图片。
利用自编码网络生成的图片:
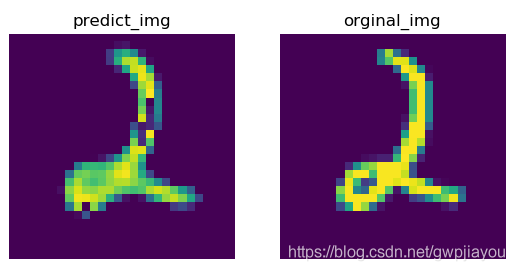 说明:由于用笔记本训练,只训练了5次,可以看出生成的图片效果有特在丢失。
说明:由于用笔记本训练,只训练了5次,可以看出生成的图片效果有特在丢失。
import torch.nn as nn
import torchvision.datasets as data
from torch.utils.data import DataLoader
import torch.optim as optimer
import torch
import matplotlib.pyplot as plt
from torchvision.transforms import ToPILImage
import torchvision.transforms as trans
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
# Encoder
self.encoder_layer = nn.Sequential(
nn.Conv2d(1, 32, 3, 1), # 28 * 28
nn.BatchNorm2d(32),
nn.ReLU(True),
nn.MaxPool2d(2, 2), # (26 -2)//2 + 1 = 13
nn.Conv2d(32, 64, 3, 1), # 13 -3 +1 = 11
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(2, 2), # (11 -2)//2 + 1 = 5
nn.Conv2d(64, 128, 3, 1), # 5-3 +1 =3
nn.BatchNorm2d(128),
nn.ReLU(True)
)
# decoder
# (img - k + 2 * p)//s + 1 = f_map
# img = (f_map -1)*s - 2 * p + k
self.decoder_layer = nn.Sequential(
nn.Conv2d(128, 128, 3, 1, 2), # 5
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128, 128, 3, 1), # 7
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.UpsamplingBilinear2d(scale_factor=2), # 14
nn.ReLU(True),
nn.Conv2d(128, 64, 3, 1, 1), # 14
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.UpsamplingBilinear2d(scale_factor=2), # 28
nn.Conv2d(64, 1, 3, 1, 1), # 28
nn.ReLU(True)
)
def forward(self, x):
feature = self.encoder_layer(x)
return self.decoder_layer(feature)
class Main(object):
def __init__(self, batch_size, epoch):
self.batch_size = batch_size
self.epoch = epoch
self.train_data = data.MNIST(root="datasets/", download=True, train=True, transform=trans.ToTensor())
self.train_data_loader = DataLoader(dataset=self.train_data, batch_size=self.batch_size, shuffle=True)
self.test_data = data.MNIST(root="datasets/", download=True, train=False, transform=trans.ToTensor())
self.test_data_loader = DataLoader(dataset=self.test_data, batch_size=self.batch_size, shuffle=True)
self.loss = nn.MSELoss()
self.net = AutoEncoder()
self.optim = optimer.Adam(self.net.parameters())
def train(self):
losses = []
for i in range(self.epoch):
print("start training.....\n epoch{}/{}".format(i, self.epoch))
for j, (data, target) in enumerate(self.train_data_loader):
# print(data.shape)
out = self.net(data)
# print(out.shape)
loss = self.loss(out, data)
losses.append(loss.item())
self.optim.zero_grad()
loss.backward()
self.optim.step()
if j % 10 == 0:
print("loss: %s" % loss.item())
plt.clf()
plt.ion()
plt.plot(losses)
plt.pause(0.1)
plt.show()
torch.save(self.net, "models/autoencoder.pth")
def test(self):
net = torch.load("models/autoencoder.pth")
for i, (data, target) in enumerate(self.test_data_loader):
out = net(data)
# print(out.shape)
plt.clf()
plt.ion()
plt.subplot(1, 2, 1)
pred_img = ToPILImage("L")(out[i, :])
plt.axis('off')
plt.title("predict_img")
plt.imshow(pred_img)
plt.pause(0.1)
plt.subplot(1, 2, 2)
orginal_img = ToPILImage("L")(data[i, :])
plt.axis('off')
plt.title("orginal_img")
plt.imshow(orginal_img)
plt.pause(0.1)
plt.savefig("fig.jpg")
plt.show()
if __name__ == '__main__':
t_net = Main(batch_size=300, epoch=5)
# t_net.train()
t_net.test()
三、利用自编码神经网络去噪
在手写数字图片中加入噪点,然后再利用自编码神经网络进行学习,生成原来的图片。
- 加噪后的图片和原始图片对比
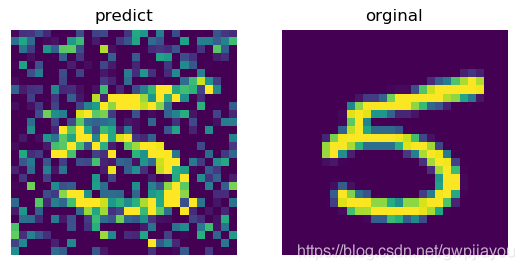 2. 测试图片的时候没有加激活函数得到的图片:
2. 测试图片的时候没有加激活函数得到的图片:
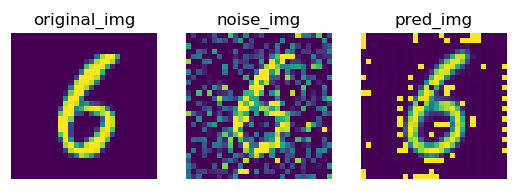 可以看出,生成的图片中有噪点,原因是由于图片底色为黑色,现在输出了其他值,而不是0,所以用sigmoid 激活函数将输出的值逼向两端,就会去掉噪点。
可以看出,生成的图片中有噪点,原因是由于图片底色为黑色,现在输出了其他值,而不是0,所以用sigmoid 激活函数将输出的值逼向两端,就会去掉噪点。 - 加入激活函数最终的测试效果,输出的图片(重新生成的图片)没有了噪点。:
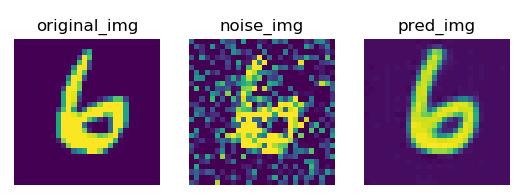
可以看出中间生成的图片效果明显比步加噪点之前的效果要好。
import torch.nn as nn
import torchvision.datasets as data
from torch.utils.data import DataLoader
import torch.optim as optimer
import torch
import matplotlib.pyplot as plt
from torchvision.transforms import ToPILImage
import torchvision.transforms as trans
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
# Encoder
self.encoder_layer = nn.Sequential(
nn.Conv2d(1, 32, 3, 1), # 28 * 28
nn.BatchNorm2d(32),
nn.ReLU(True),
nn.MaxPool2d(2, 2), # (26 -2)//2 + 1 = 13
nn.Conv2d(32, 64, 3, 1), # 13 -3 +1 = 11
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(2, 2), # (11 -2)//2 + 1 = 5
nn.Conv2d(64, 128, 3, 1), # 5-3 +1 =3
nn.BatchNorm2d(128),
nn.ReLU(True)
)
# decoder
# (img - k + 2 * p)//s + 1 = f_map
# img = (f_map -1)*s - 2 * p + k
self.decoder_layer = nn.Sequential(
nn.Conv2d(128, 128, 3, 1, 2), # 5
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128, 128, 3, 1), # 7
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.UpsamplingBilinear2d(scale_factor=2), # 14
nn.ReLU(True),
nn.Conv2d(128, 64, 3, 1, 1), # 14
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.UpsamplingBilinear2d(scale_factor=2), # 28
nn.Conv2d(64, 1, 3, 1, 1), # 28
nn.ReLU(True)
)
def forward(self, x):
feature = self.encoder_layer(x)
return self.decoder_layer(feature)
class Main(object):
def __init__(self, batch_size, epoch):
self.batch_size = batch_size
self.epoch = epoch
self.train_data = data.MNIST(root="datasets/", download=True, train=True, transform=trans.ToTensor())
self.train_data_loader = DataLoader(dataset=self.train_data, batch_size=self.batch_size, shuffle=True)
self.test_data = data.MNIST(root="datasets/", download=True, train=False, transform=trans.ToTensor())
self.test_data_loader = DataLoader(dataset=self.test_data, batch_size=self.batch_size, shuffle=True)
self.loss = nn.MSELoss()
self.net = AutoEncoder()
self.optim = optimer.Adam(self.net.parameters())
def getTrain_set(self):
train_set = data.MNIST(root="datasets/", train=True)
origin_x = train_set.data.float()
train_x = torch.clamp(origin_x + torch.randn(60000, 28, 28) * 100, 0, 255) / 255.
train_y = origin_x / 255.
return train_x.unsqueeze(1), train_y.unsqueeze(1)
def getTest_set(self):
test_set = data.MNIST(root="datasets/", train=False)
origin_x = test_set.data.float()
#torch.clamp()函数将随机生成的10000个数中,小于0的取0,大于255的取255. 0--255中间的值不变。
test_x = torch.clamp(origin_x + torch.randn(10000, 28, 28) * 100, 0, 255) / 255.
test_y = origin_x / 255.
return test_x.unsqueeze(1), test_y.unsqueeze(1)
def train(self):
losses = []
train_x, train_y = self.getTrain_set()
# 打乱数据
index = torch.randperm(train_x.shape[0])
train_x = train_x[index]
train_y = train_y[index]
for i in range(self.epoch):
print("start training.....\n epoch{}/{}".format(i, self.epoch))
for j in range(0, train_x.shape[0], self.batch_size):
x = train_x[j:j + self.batch_size]
y = train_y[j:j + self.batch_size]
out = self.net(x)
# print(out.shape)
loss = self.loss(out, y)
losses.append(loss.item())
self.optim.zero_grad()
loss.backward()
self.optim.step()
if j % 10 == 0:
print("loss: %s" % loss.item())
plt.clf()
plt.ion()
plt.plot(losses)
plt.pause(0.1)
plt.show()
torch.save(self.net, "models/autoencoder.pth")
def predictModel(self):
net = torch.load("models/autoencoder.pth")
test_x, test_y = self.getTest_set()
# test_x = test_x.cuda()
toPIL = ToPILImage("L")
for i in range(0, test_x.shape[0], 3):
x = test_x[i: i + self.batch_size]
y = test_y[i: i + self.batch_size]
out = net(x)
out = torch.sigmoid(out)
for j in range(out.shape[0]):
plt.clf()
plt.subplot(1,3,1)
plt.title("Noise Image")
plt.axis("off")
plt.imshow(toPIL(x[j].cpu()))
plt.subplot(1,3,2)
plt.title("Out Image")
plt.axis("off")
plt.imshow(toPIL(out[j].cpu()))
plt.subplot(1,3,3)
plt.title("Origin Image")
plt.axis("off")
plt.imshow(toPIL(y[j]))
plt.pause(1)
if __name__ == '__main__':
t_net = Main(batch_size=100, epoch=5)
# t_net.train()
t_net.predictModel()