Pytorch学习笔记7——自定义数据集
Pytorch学习笔记7——自定义数据集


1.读取数据
首先继承自torch.utils.data.Dataset
重写len与getitem
train就用train数据集,test就用test数据集。


自定义数据集的读取
import torch
import os,glob
import random,csv
import torchvision.datasets
from torch.utils.data import Dataset,DataLoader
from torchvision import transforms
from PIL import Image
from torchvision.transforms import InterpolationMode
class Pokemon(Dataset):
def __init__(self,root,resize,mode):
super(Pokemon, self).__init__()
self.root=root
self.resize=resize
self.name2label={}#字典表达映射关系label‘‘sq..’’:0
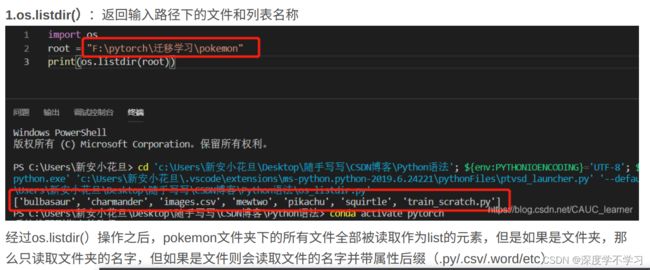
for name in sorted(os.listdir(os.path.join(root))):#遍历根目录下所有文件假
if not os.path.isdir(os.path.join(root,name)):#判断是否是文件夹
continue
self.name2label[name]=len(self.name2label.keys())
print(self.name2label)
self.images,self.labels=self.load_csv('images.csv')#得到的是images的路径,和对应的数字标签
if mode=='train':
self.images=self.images[:int(0.6*len(self.images))]
self.labels=self.labels[:int(0.6*len(self.labels))]
elif mode=='val':#20
self.images=self.images[int(0.6*len(self.images)):int(0.8*len(self.images))]
self.labels=self.labels[int(0.6*len(self.labels)):int(0.8*len(self.labels))]
else:
self.images=self.images[int(0.8*len(self.images)):]
self.labels=self.labels[int(0.8*len(self.labels)):]
#创建数据对:path+label
def load_csv(self,filename):
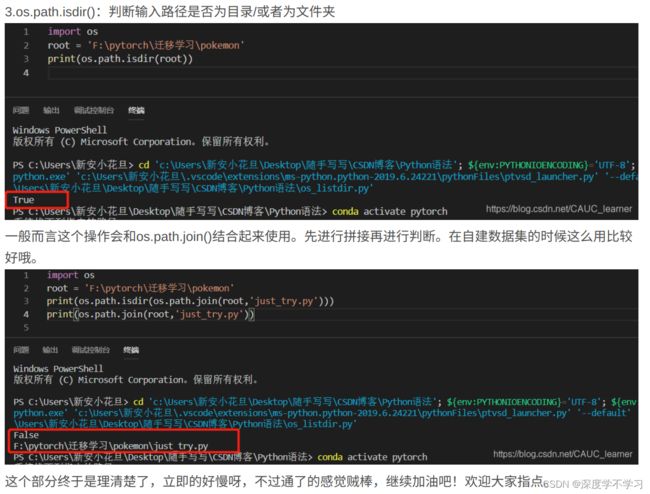
if not os.path.exists(os.path.join(self.root,filename)):#如果已经有了,不需要再创建
images=[]
for name in self.name2label.keys():#key:value
images+=glob.glob(os.path.join(self.root,name,'*.png'))#glob方法获取目录下所有满足的文件
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
#1165,pokeman/bulbasaur/00001.png
#对应关系保存到csv
random.shuffle(images)
with open(os.path.join(self.root,filename),mode='w',newline='') as f:
writer=csv.writer(f)
for img in images:#pokeman/bulbasaur/00001.png
name=img.split(os.sep)[-2]
label=self.name2label[name]#字典根据key找value存入label
writer.writerow([img,label])#pokeman/bulbasaur/00001.png,0
print('writen into csvfile:',filename)
#read from csv
images,labels=[],[]
with open(os.path.join(self.root,filename)) as f:
reader=csv.reader(f)
for row in reader:
img,label=row
label=int(label)
images.append(img)
labels.append(label)
assert len(images)==len(labels)
return images,labels
def __len__(self):
return len(self.images)
def denormalize(self,x_hat):#逆归一化已回复图片视觉效果
mean = [0.845, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
#x_hat=(x-mean)/std
#x=x_hat*std+mean
#x:[c,h,w]
#mean:[3]=>[3,1,1]
mean=torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
print(mean.shape,std.shape)
x=x_hat*std+mean
return x
def __getitem__(self, idx):
#self.images,self.labels
#idx-[0-len(images)]
img,label=self.images[idx],self.labels[idx]#从csv获得的图片路径与label
tf=transforms.Compose([
lambda x:Image.open(x).convert('RGB'),#string path=>image data
transforms.Resize((int(self.resize*1.25),int(self.resize*1.25))),
transforms.RandomRotation(15),
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.845,0.456,0.406],
std=[0.229,0.224,0.225])
])
img=tf(img)
label=torch.tensor(label)
return img,label
if __name__=='__main__':
import visdom
import time
viz=visdom.Visdom()
# tf = transforms.Compose([
# transforms.Resize((64,64)),
# transforms.ToTensor(),
# ])
# db=torchvision.datasets.ImageFolder(root='/home/lizheng/Study/yolov5-5.0/pytorch1/pokemon/pokeman',transform=tf)
# loader=DataLoader(db,batch_size=32,shuffle=True)#一行代码完成数据集加载工作
# print(db.class_to_idx)
# for x,y in loader:
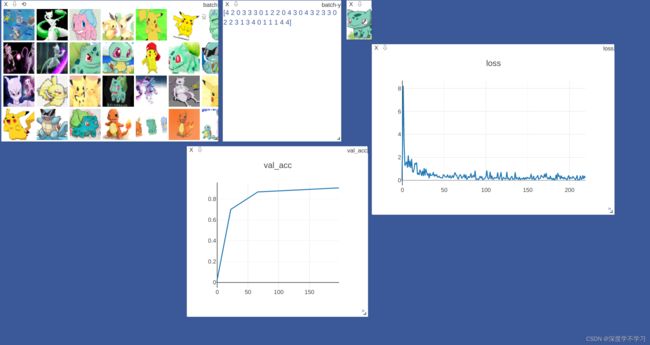
# viz.images(x,nrow=8,win='batch',opts=dict(title='batch'))
# viz.text(str(y.numpy()),win='label',opts=dict(title='batch-y'))
#
# time.sleep(10)
db=Pokemon('pokemon/pokeman',64,'train')
x,y=next(iter(db))#利用迭代器输入路径获得具体图像,得到第一个样本,调用时自动使用getitem函数,此时x是图像
print('sample:',x.shape,y.shape,y)
viz.image(db.denormalize(x),win='sample_x',opts=dict(title='sample_x'))
loader=DataLoader(db,batch_size=32,shuffle=True,num_workers=8)#不想一个一个取,想一个batch一个batch取
for x,y in loader:
viz.images(db.denormalize(x),nrow=8,win='batch',opts=dict(title='batch'))
viz.text(str(y.numpy()),win='label',opts=dict(title='batch-y'))
time.sleep(10)
自定义神经网络模型的搭建
import torch
from torch import nn
from torch.nn import functional as F
class ResBlk(nn.Module):
def __init__(self,ch_in,ch_out,stride=1):
'''
:param ch_in:
:param ch_out:
'''
super(ResBlk,self).__init__()#super方法避免父类的init函数被替换
self.conv1=nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=stride,padding=1)
self.bn1=nn.BatchNorm2d(ch_out)
self.conv2=nn.Conv2d(ch_out,ch_out,kernel_size=3,stride=1,padding=1)
self.bn2=nn.BatchNorm2d(ch_out)
self.extra=nn.Sequential()
if ch_out!=ch_in:
self.extra=nn.Sequential(
nn.Conv2d(ch_in,ch_out,kernel_size=1,stride=stride),#Sequential里面加入的都是类,因此可以自己写,然后加入
nn.BatchNorm2d(ch_out)#这些类在调用时会自动调用forward函数,记得要写return
)
def forward(self,x):
'''
:param x:[b,ch,h,w]
:return:
'''
out=F.relu(self.bn1(self.conv1(x)))
out=self.bn2(self.conv2(out))
#short cut
#extra module:[b,ch_in,h,w] with [b,ch_out,h,w]
#element-wise add:\
out=self.extra(x)+out
return out
class ResNet18(nn.Module):
def __init__(self,num_class):
super(ResNet18,self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(3,16,kernel_size=3,stride=3,padding=0),
nn.BatchNorm2d(16)
)
#followed 4 blocks
#[b,16,h,w]=>[b,32,h,w]
self.blk1=ResBlk(16,32,stride=3)#增多通道,减少长宽,避免数据量过大
#[b,32,h,w]=>[b,64,h,w]
self.blk2 = ResBlk(32, 64,stride=3)
#[b,64,h,w]=>[b,128,h,w]
self.blk3 = ResBlk(64,128,stride=2)
# [b,128,h,w]=>[b,256,h,w]
self.blk4 = ResBlk(128,256,stride=2)
#[b,256,7,7]
self.outlayer=nn.Linear(256*3*3,num_class)#输入512通道,输出10通道
def forward(self,x):
'''
:param x:
:return:
'''
x=F.relu(self.conv1(x))
#[b,64,h,w]=>[b,1024,h,w]
x=self.blk1(x)
x=self.blk2(x)
x=self.blk3(x)
x=self.blk4(x)
# print('after conv:',x.shape)#[b,512,2,2]
# # [b,512,h,w]=>[b,512,2,2]
# x=F.adaptive_avg_pool2d(x,[1,1])
# # print('after pool:',x.shape)
x=x.view(x.size(0),-1)
x=self.outlayer(x)
return x
if __name__=='__main__':
blk=ResBlk(64,128)
tmp=torch.randn(2,64,224,224)
out=blk(tmp)
print('block',out.shape)
model=ResNet18(5)#5分类
tmp=torch.randn(2,3,224,224)
out=model(tmp)
print('resnet:',out.shape)
p=sum(map(lambda p:p.numel(),model.parameters()))
print('parameters size:',p)
自定义数据集的训练与测试:
import torch
from torch import optim,nn
import visdom
import torchvision
from torch.utils.data import DataLoader
from pytorch1.pt3 import Pokemon
from resnet import ResNet18
batchsz=32
lr=1e-3
epochs=10
device=torch.device('cuda')
torch.manual_seed(1234)
train_db=Pokemon('pokemon/pokeman',224,mode='train')#initial函数初始化训练集,
val_db=Pokemon('pokemon/pokeman',224,mode='val')
test_db=Pokemon('pokemon/pokeman',224,mode='test')
train_loader=DataLoader(train_db,batch_size=batchsz,shuffle=True,num_workers=4)#loader里获得的都是真正是图片
val_loader=DataLoader(val_db,batch_size=batchsz,num_workers=4)
test_loader=DataLoader(test_db,batch_size=batchsz,num_workers=4)
viz = visdom.Visdom()
def evaluate(model,loader):
correct=0
total=len(loader.dataset)
for x,y in loader:
x,y=x.to(device),y.to(device)
with torch.no_grad():
logits=model(x)
pred=logits.argmax(dim=1)
correct+=torch.eq(pred,y).sum().float().item()
return correct/total
if __name__=='__main__':
model=ResNet18(5).to(device)
optimizer=optim.Adam(model.parameters(),lr=lr)
criteon=nn.CrossEntropyLoss()
best_acc,best_epoch=0,0
global_step=0
viz.line([0],[-1],win='loss',opts=dict(title='loss'))
viz.line([0],[-1],win='val_acc',opts=dict(title='val_acc'))#清空操作
for epoch in range(epochs):
for step,(x,y) in enumerate(train_loader):
#x:[b,3,224,224],y:[b]
x,y=x.to(device),y.to(device)
logits=model(x)
loss=criteon(logits,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step+=1
if epoch%2==0:
val_acc=evaluate(model,val_loader)
if val_acc>best_acc:
best_epoch=epoch
best_acc=val_acc
torch.save(model.state_dict(),'best.mdl')
viz.line([val_acc], [global_step], win='val_acc',update='append')
print('best acc:',best_acc,'best_epoch:',best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt!')
test_acc=evaluate(model,test_loader)
print('test acc:',test_acc)
实验效果: