【Datawhale】动手学数据分析
动手学数据分析
第一章:数据载入及初步观察
载入数据
任务一:导入numpy和pandas
import numpy as np
import pandas as pd
任务二:载入数据
train_data = pd.read_csv("train.csv")
train_data.head(5)
train_data = pd.read_table("train.csv")
train_data.head(5)
这两个读取方式的区别在于read_csv读取的是默认分割符为逗号,而read_csv读取默认分隔符为制表符。
任务三:每1000行为一个数据模块,逐块读取
chunker = pd.read_csv("train.csv", chunksize = 1000)
print(type(chunker))
【思考】什么是逐块读取?为什么要逐块读取呢?
答:比如后续遍历,像一个数据迭代器一样方便读取
【提示】大家可以chunker(数据块)是什么类型?用for循环打印出来出处具体的样子是什么?
答:
将表头改成中文
train_data = pd.read_csv("train.csv", names=['乘客ID','是否幸存','仓位等级','姓名','性别','年龄','兄弟姐妹个数','父母子女个数','船票信息','票价','客舱','登船港口'],index_col='乘客ID', header=0)
train_data.head(5)
【思考】所谓将表头改为中文其中一个思路是:将英文列名表头替换成中文。还有其他的方法吗?
答:可以读入后再进行修改
初步观察
任务一:查看数据的基本信息
train_data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 1 to 891
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 是否幸存 891 non-null int64
1 仓位等级 891 non-null int64
2 姓名 891 non-null object
3 性别 891 non-null object
4 年龄 714 non-null float64
5 兄弟姐妹个数 891 non-null int64
6 父母子女个数 891 non-null int64
7 船票信息 891 non-null object
8 票价 891 non-null float64
9 客舱 204 non-null object
10 登船港口 889 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 83.5+ KB
【提示】有多个函数可以这样做,你可以做一下总结
- df.info(): # 打印摘要
- df.describe(): # 描述性统计信息
- df.values: # 数据
- df.to_numpy() # 数据 (推荐)
- df.shape: # 形状 (行数, 列数)
- df.columns: # 列标签
- df.columns.values: # 列标签
- df.index: # 行标签
- df.index.values: # 行标签
- df.head(n): # 前n行
- df.tail(n): # 尾n行
- pd.options.display.max_columns=n: # 最多显示n列
- pd.options.display.max_rows=n: # 最多显示n行
- df.memory_usage(): # 占用内存(字节B)
任务二:观察表格前10行和后15行的数据
train_data.head(10)
train_data.tail(15)
任务三:判断数据是否为空,为空的地方返回true,否则返回false
train_data.isnull().head(10)
【思考】对于一个数据,还可以从哪些方面来观察?找找答案,这个将对下面的数据分析有很大的帮助
答:从分布方面
保存数据
任务一:将你加载并做出改变的数据,在工作目录下保存为一个新文件train_chinese.csv
# 注意:不同的操作系统保存下来可能会有乱码。大家可以加入`encoding='GBK' 或者 ’encoding = ’utf-8‘‘`
train_data.to_csv("train_chinese.csv",encoding='GBK')
知道你的数据叫什么
任务一:pandas中有两个数据类型DateFrame和Series,通过查找简单了解他们。然后自己写一个关于这两个数据类型的小例子
myself = {"name":"FavoriteStar",'age':18,"gender":"男性"}
example = pd.Series(myself)
example
myself2 = {"爱好":["打篮球",'唱歌','躺平'], "程度":[100, 90, 80]}
example2 = pd.Series(myself2)
example2
爱好 [打篮球, 唱歌, 躺平]
程度 [100, 90, 80]
dtype: object
任务二:根据上节课的方法载入"train.csv"文件
train_data = pd.read_csv("train_chinese.csv",encoding='GBK')
# 在保存的时候用了GBK,载入就也要用,否则会乱码
任务三:查看DataFrame数据的每列的名称
train_data.columns
Index(['乘客ID', '是否幸存', '仓位等级', '姓名', '性别', '年龄', '兄弟姐妹个数', '父母子女个数', '船票信息','票价', '客舱', '登船港口'],dtype='object')
任务四:查看"Cabin"这列的所有值
train_data['客舱'].unique()
train_data.客舱.unique()
任务五:加载文件"test_1.csv",然后对比"train.csv",看看有哪些多出的列,然后将多出的列删除
test_data = pd.read_csv("test_1.csv")
test_data_drop = test_data.drop('a',axis = 1)
test_data.head(5)
【思考】还有其他的删除多余的列的方式吗?
del test_data['a']
df.drop(columns='a')
df.drop(columns=['a'])
任务六: 将[‘PassengerId’,‘Name’,‘Age’,‘Ticket’]这几个列元素隐藏,只观察其他几个列元素
test_data_drop.drop(['PassengerId','Name','Age','Ticket'],axis=1).head(3)
# 这里隐藏后返回,并不是在原来的数据上进行修改
【思考】对比任务五和任务六,是不是使用了不一样的方法(函数),如果使用一样的函数如何完成上面的不同的要求呢?
【思考回答】如果想要完全的删除你的数据结构,使用inplace=True,因为使用inplace就将原数据覆盖了,所以这里没有用
筛选的逻辑
任务一: 我们以"Age"为筛选条件,显示年龄在10岁以下的乘客信息
train_data[train_data['年龄']<10].head(10)
任务二: 以"Age"为条件,将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage
midage = train_data[(train_data["年龄"] > 10) & (train_data["年龄"]< 50)]
任务三:将midage的数据中第100行的"Pclass"和"Sex"的数据显示出来
midage = midage.reset_index(drop=True)
# 用这个重置索引的目的是因为可能我们前面用了乘客ID作为索引,就达不到取出第100行的目的,就会取出乘客id为100的
midage.loc[[100],["仓位等级","性别"]]
任务四:使用loc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage.loc[[100,105,108],["仓位等级","性别"]]
任务五:使用iloc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
midage.iloc[[100,105,108],[2,3,4]]
【思考】对比iloc和loc的异同
答:iloc传入的列的索引为真正的索引,而loc传入的为列的名称
了解你的数据吗
任务一:利用Pandas对示例数据进行排序,要求升序
obj1 = pd.DataFrame({"a":[800,400,200],"c":[900,700,400],"b":[700,500,100]},index = ['A','C','B'])
bj1.sort_values(by=['a'])
【问题】:大多数时候我们都是想根据列的值来排序,所以将你构建的DataFrame中的数据根据某一列,升序排列
obj1 = pd.DataFrame({"a":[800,400,200],"c":[900,700,400],"b":[700,500,100]},index = ['A','C','B'])
obj1
obj1.sort_values(by='A',axis='columns')
【思考】通过书本你能说出Pandas对DataFrame数据的其他排序方式吗?
答:rank可能也有用,还有sort_index
【总结】下面将不同的排序方式做一个总结
1.让行索引升序排序
obj1 = pd.DataFrame({"a":[800,400,200],"c":[900,700,400],"b":[700,500,100]},index = ['A','C','B'])
obj1.sort_index(axis = 0)
2.让列索引升序排序
obj1 = pd.DataFrame({"a":[800,400,200],"c":[900,700,400],"b":[700,500,100]},index = ['A','C','B'])
obj1.sort_index(axis = 1)
3.让列索引降序排序
obj1 = pd.DataFrame({"a":[800,400,200],"c":[900,700,400],"b":[700,500,100]},index = ['A','C','B'])
obj1.sort_index(axis = 0, ascending=False)
4.让任选两列数据同时降序排序
obj1 = pd.DataFrame({"a":[800,400,200],"c":[900,700,400],"b":[700,500,100]},index = ['A','C','B'])
obj1.sort_values(by=['a','b'],ascending=False)
任务二:对泰坦尼克号数据(trian.csv)按票价和年龄两列进行综合排序(降序排列),从这个数据中你可以分析出什么
train_data.head(5)
train_data.sort_values(by=['票价','年龄'],ascending=False).head(20)
【思考】排序后,如果我们仅仅关注年龄和票价两列。根据常识我知道发现票价越高的应该客舱越好,所以我们会明显看出,票价前20的乘客中存活的有14人,这是相当高的一个比例
多做几个数据的排序
train_data.sort_values(by=['性别'],ascending=False).head(20)
按照年龄排序的话前20人只有5人存活,并且可以看到年龄最高人20人很多人的父母子女个数都为0
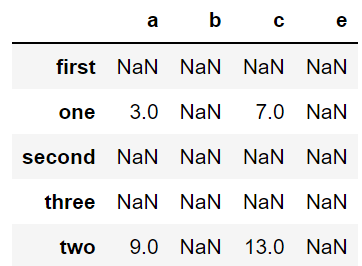
任务三:利用Pandas进行算术计算,计算两个DataFrame数据相加结果
frame_a = pd.DataFrame(np.arange(9.).reshape(3, 3),
columns=['a', 'b', 'c'],
index=['one', 'two', 'three'])
frame_b = pd.DataFrame(np.arange(12.).reshape(4, 3),
columns=['a', 'e', 'c'],
index=['first', 'one', 'two', 'second'])
frame_a + frame_b
任务四:通过泰坦尼克号数据如何计算出在船上最大的家族有多少人
(train_data['兄弟姐妹个数'] + train_data['父母子女个数']).max()
max(train_data['兄弟姐妹个数'] + train_data['父母子女个数'])
答案为10
任务五:学会使用Pandas describe()函数查看数据基本统计信息
frame2 = pd.DataFrame([[1.4, np.nan],
[7.1, -4.5],
[np.nan, np.nan],
[0.75, -1.3]
], index=['a', 'b', 'c', 'd'], columns=['one', 'two'])
frame2.describe()

任务六:分别看看泰坦尼克号数据集中 票价、父母子女 这列数据的基本统计数据,你能发现什么
train_data[['票价','父母子女个数']].describe()
数据清洗及特征清理
缺失值观察与处理
任务一:缺失值观察
(1) 请查看每个特征缺失值个数
(2) 请查看Age, Cabin, Embarked列的数据 以上方式都有多种方式
train_data.isnull().sum()
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
train_data[['Age','Cabin','Embarked']].head(10)
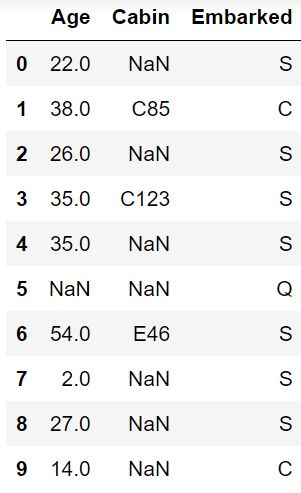
任务二:对缺失值进行处理
(1)处理缺失值一般有几种思路
(2) 请尝试对Age列的数据的缺失值进行处理
(3) 请尝试使用不同的方法直接对整张表的缺失值进行处理
train_data['Age'].dropna() # 丢弃
train_data['Age'].fillna(method='ffill') # 线性插值
train_data['Age'].fillna(value=20) # 全部按照20填充
【思考1】dropna和fillna有哪些参数,分别如何使用呢
- dropna()
- axis:为1或者index就删除含有缺失值的行,为0或者columns则删除列
- how:为all就删除全是缺失值的,any就删除任何含有缺失值的
- thresh=n:删除缺失值大于等于n的
- subset:定义在哪些列中查找缺失值
- inplace:是否原地修改
- fillna()
- inplace
- method:取值为pad、ffill、backfill、bfill、None
- limit:限制填充个数
- axis:修改填充方向
【思考】检索空缺值用np.nan,None以及.isnull()哪个更好,这是为什么?如果其中某个方式无法找到缺失值,原因又是为什么?
数值列读取数据后,空缺值的数据类型为float64,所以用None一般索引不到,比较的时候最好用np.nan
重复值观察与处理
任务一:请查看数据中的重复值
train_data.duplicated()
这个函数就是返回某一行的数据是否已经在之前的行中出现了,如果是就是重复数据就返回true。
任务二:对重复值进行处理
train_data = train_data.drop_duplicates()
train_data.head(5)
任务三:将前面清洗的数据保存为csv格式
train_data.to_csv('test_clear.csv')
特征观察与处理
任务一:对年龄进行分箱(离散化)处理
(1) 分箱操作是什么?
(2) 将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
(3) 将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示
(4) 将连续变量Age按10% 30% 50% 70% 90%五个年龄段,并用分类变量12345表示
(5) 将上面的获得的数据分别进行保存,保存为csv格式
【答】分箱操作就相当于将连续数据划分为几个离散值,再用离散值来替代连续数据。
train_data['newAge'] = pd.cut(train_data['Age'], 5, labels=[1,2,3,4,5])
train_data.head(5)
train_data.to_csv("test_avg.csv")
bins = [0,5,15,30,50,80]
train_data['newAge'] = pd.cut(train_data['Age'],bins, right=False, labels=[1,2,3,4,5])
train_data.head(5)
train_data.to_csv("test_cut.csv")
train_data['newAge'] = pd.qcut(train_data['Age'],[0,0.1,0.3,0.5,0.7,0.9],labels=[1,2,3,4,5])
train_data.head(5)
train_data.to_csv("test_pr.csv")
任务二:对文本变量进行转换
(1) 查看文本变量名及种类
(2) 将文本变量Sex, Cabin ,Embarked用数值变量12345表示
(3) 将文本变量Sex, Cabin, Embarked用one-hot编码表示
train_data['Embarked'].value_counts()
train_data['Sex'].unique()
train_data['Sex'].value_counts()
train_data['Sex_num'] = train_data['Sex'].replace(['male','female'],[1,2])
train_data.head(5)
train_data['Sex_num'] = train_data['Sex'].map({"male":1,'female':2})
train_data.head(5)
以上两种适用于性别这样离散值很少的,那么如果对于另外两种数据离散值很多就不行,用以下的方法:
from sklearn.preprocessing import LabelEncoder
for feat in ['Cabin', 'Ticket']:
lbl = LabelEncoder()
label_dict = dict(zip(train_data[feat].unique(), range(train_data[feat].nunique())))
train_data[feat + "_labelEncode"] = train_data[feat].map(label_dict)
train_data[feat + "_labelEncode"] = lbl.fit_transform(train_data[feat].astype(str))
train_data.head(5)
# 转换为ont-hot编码
for feat in ['Sex', 'Cabin','Embarked']:
x = pd.get_dummies(train_data[feat], prefix=feat)
# prefix就是让生成的列的名称为feat+取值
train_data = pd.concat([train_data,x],axis=1)
train_data.head(5)
任务三:从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
train_data['Title'] = train_data.Name.str.extract('([A-Za-z]+)\.', expand=False)
train_data.head()
train_data.to_csv('test_fin.csv')
数据的合并
任务一:将data文件夹里面的所有数据都载入,观察数据的之间的关系
train_left_up = pd.read_csv("data\\train-left-up.csv")
train_left_up.info()
train_left_down = pd.read_csv("data\\train-left-down.csv")
train_left_down.info()
train_right_up = pd.read_csv("data\\train-right-up.csv")
train_right_down = pd.read_csv("data\\train-right-down.csv")
任务二:使用concat方法:将数据train-left-up.csv和train-right-up.csv横向合并为一张表,并保存这张表为result_up
result_up = pd.concat([train_left_up, train_right_up],axis = 1)
result_up.head(5)
任务三:使用concat方法:将train-left-down和train-right-down横向合并为一张表,并保存这张表为result_down。然后将上边的result_up和result_down纵向合并为result
result_down = pd.concat([train_left_down, train_right_down],axis = 1)
result = pd.concat([result_up, result_down], axis=0)
result.head(5)
任务四:使用DataFrame自带的方法join方法和append:完成任务二和任务三的任务
result_up = train_left_up.join(train_right_up)
result_up.head(5)
result_down = train_left_down.join(train_right_down)
result = result_up.append(result_down)
result.head(4)
任务五:使用Panads的merge方法和DataFrame的append方法:完成任务二和任务三的任务
result_up = pd.merge(train_left_up,train_right_up,left_index=True,right_index=True)
result_up.head(5)
result_down = pd.merge(train_left_down,train_right_down,left_index=True,right_index=True)
result = result_up.append(result_down)
result.head(5)
任务六:完成的数据保存为result.csv
result.to_csv("data\\result.csv")
换一种角度看数据
任务一:将我们的数据变为Series类型的数据
train_data = pd.read_csv('result.csv')
train_data.head()
unit_result=train_data.stack().head(20)
# stack是转置,索引不变,然后内容转置。
unit_result.head()
unit_result.to_csv('unit_result.csv')
数据运用
任务一:通过教材《Python for Data Analysis》P303、Google or anything来学习了解GroupBy机制
这部分还是很推荐去看看书进行学习,很有用。
任务二:计算泰坦尼克号男性与女性的平均票价
result['Fare'].groupby(result['Sex']).mean()
Sex
female 44.479818
male 25.523893
Name: Fare, dtype: float64
任务三:统计泰坦尼克号中男女的存活人数
result['Survived'].groupby(result['Sex']).sum()
Sex
female 233
male 109
Name: Survived, dtype: int64
任务四:计算客舱不同等级的存活人数
result['Survived'].groupby(result['Pclass']).sum()
Pclass
1 136
2 87
3 119
Name: Survived, dtype: int64
【思考】从数据分析的角度,上面的统计结果可以得出那些结论
【答】女性平均票价高,生存人数高,1号客舱生存人数多
【思考】从任务二到任务三中,这些运算可以通过agg()函数来同时计算。并且可以使用rename函数修改列名。你可以按照提示写出这个过程吗?
result.groupby('Sex').agg({'Fare': 'mean', 'Pclass': 'count'}).rename(columns={'Fare': 'mean_fare', 'Pclass': 'count_pclass'})
任务五:统计在不同等级的票中的不同年龄的船票花费的平均值
result.groupby(['Pclass','Age'])['Fare'].mean()
Pclass Age
1 0.92 151.5500
2.00 151.5500
4.00 81.8583
11.00 120.0000
14.00 120.0000
...
3 61.00 6.2375
63.00 9.5875
65.00 7.7500
70.50 7.7500
74.00 7.7750
Name: Fare, Length: 182, dtype: float64
任务六:将任务二和任务三的数据合并,并保存到sex_fare_survived.csv
g1 = result['Fare'].groupby(result['Sex']).mean()
g2 = result['Survived'].groupby(result['Sex']).sum()
g_con = pd.concat([g1,g2],axis=1)
g_con.to_csv("data\\sex_fare_survived.csv")
任务七:得出不同年龄的总的存活人数,然后找出存活人数最多的年龄段,最后计算存活人数最高的存活率(存活人数/总人数)
survived_age = result.groupby('Age')['Survived'].sum()
Age
0.42 1
0.67 1
0.75 2
0.83 2
0.92 1
..
70.00 0
70.50 0
71.00 0
74.00 0
80.00 1
Name: Survived, Length: 88, dtype: int64
survived_age_max = survived_age[survived_age.values == survived_age.max()]
Age
24.0 15
Name: Survived, dtype: int64
survived_age_max_num = int(survived_age_max.values)
15
survived_age_max_num_rate =survived_age_max_num/ result['Survived'].sum()
0.043859649122807015
如何让人一眼看懂你的数据
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
result = pd.read_csv("data\\result.csv")
result.head(5)
任务一:跟着书本第九章,了解matplotlib,自己创建一个数据项,对其进行基本可视化
略
任务二:可视化展示泰坦尼克号数据集中男女中生存人数分布情况(用柱状图试试)
sex = result.groupby('Sex')['Survived'].sum()
sex.plot.bar()
plt.title('survived_count')
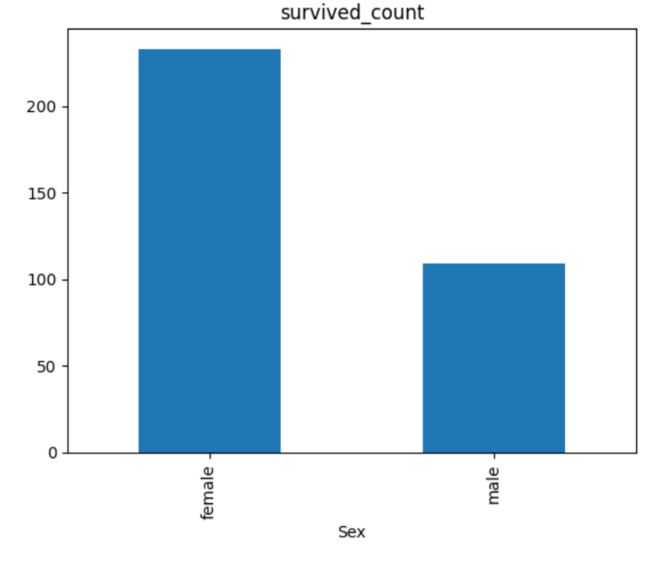
【思考】计算出泰坦尼克号数据集中男女中死亡人数,并可视化展示?如何和男女生存人数可视化柱状图结合到一起?看到你的数据可视化,说说你的第一感受(比如:你一眼看出男生存活人数更多,那么性别可能会影响存活率)。
sex_die = result.groupby('Sex')['Survived'].count() - result.groupby('Sex')['Survived'].sum()
sex_die.plot.bar()

任务三:可视化展示泰坦尼克号数据集中男女中生存人与死亡人数的比例图(用柱状图试试)
sex_sur_rate = result.groupby(['Sex','Survived'])['Survived'].count().unstack()
sex_sur_rate.plot(kind='bar',stacked=True)

任务四:可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况。(用折线图试试)(横轴是不同票价,纵轴是存活人数)
# 排序后绘折线图
fig = plt.figure(figsize=(20, 18))
fare_sur = text.groupby(['Fare'])['Survived'].value_counts().sort_values(ascending=False)
fare_sur.plot(grid=True)
plt.legend()
plt.show()
任务五:可视化展示泰坦尼克号数据集中不同仓位等级的人生存和死亡人员的分布情况。(用柱状图试试)
Pclass_sur = result.groupby(['Pclass','Survived'])['Survived'].value_counts()
import seaborn as sns
sns.countplot(x="Pclass", hue="Survived", data=result)
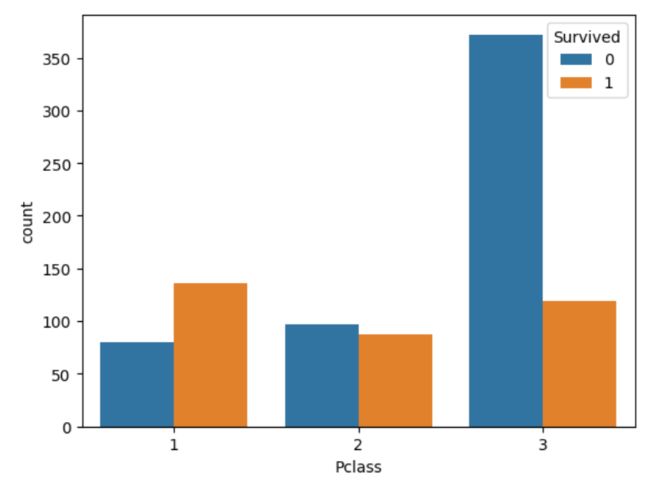
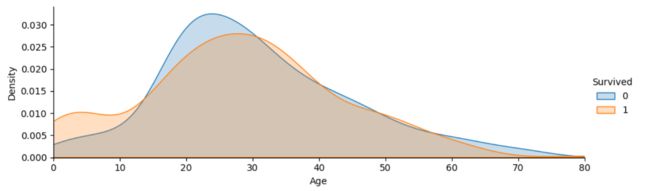
任务六:可视化展示泰坦尼克号数据集中不同年龄的人生存与死亡人数分布情况。(不限表达方式)
facet = sns.FacetGrid(result, hue="Survived",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, result['Age'].max()))
facet.add_legend()
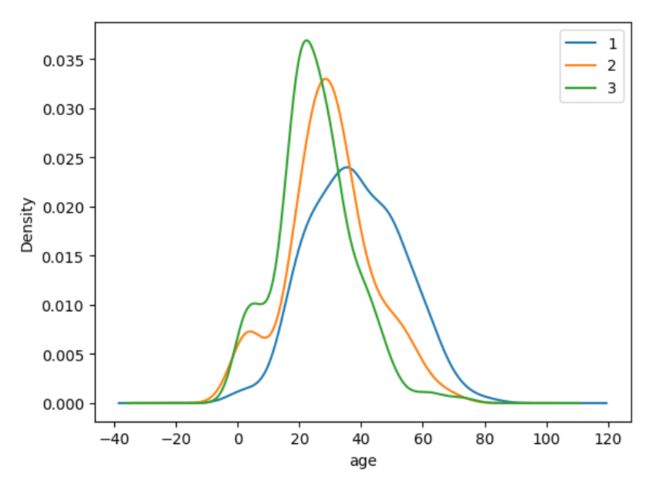
任务七:可视化展示泰坦尼克号数据集中不同仓位等级的人年龄分布情况。(用折线图试试)
result.Age[result.Pclass == 1].plot(kind='kde')
result.Age[result.Pclass == 2].plot(kind='kde')
result.Age[result.Pclass == 3].plot(kind='kde')
plt.xlabel("age")
plt.legend((1,2,3),loc="best") # best就是最不碍眼的位置
第三章 模型搭建和评估–建模
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import Image
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.figsize'] = (10, 6) # 设置输出图片大小
载入数据
clear_data = pd.read_csv("clear_data.csv")
train_data = pd.read_csv("train.csv)
模型搭建
任务一:切割训练集和测试集
- 将数据集分为自变量和因变量
- 按比例切割训练集和测试集(一般测试集的比例有30%、25%、20%、15%和10%)
- 使用分层抽样
- 设置随机种子以便结果能复现
from sklearn.model_selection import train_test_split
train_label = train_data['Survived'] # 作为标签,训练集就是我们的clear_data
x_train, x_test, y_train, y_test = train_test_split(clear_data, train_label, test_size=0.3, random_state=0, stratify = train_label)
x_train.shape # (623, 11)
x_test.shape # (268, 11)
【思考】什么情况下切割数据集的时候不用进行随机选取
【答】数据本身就是随机的
任务二:模型创建
- 创建基于线性模型的分类模型(逻辑回归)
- 创建基于树的分类模型(决策树、随机森林)
- 分别使用这些模型进行训练,分别的到训练集和测试集的得分
- 查看模型的参数,并更改参数值,观察模型变化
from sklearn.linear_model import LogisticRegression
lr_l1 = LogisticRegression(penalty="l1", C=0.5, solver="liblinear")
lr_l1.fit(x_train, y_train)
print("训练集得分为:",lr_l1.score(x_train,y_train))
print("测试集得分为:",lr_l1.score(x_test,y_test))
训练集得分为: 0.7897271268057785
测试集得分为: 0.8134328358208955
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
clf = DecisionTreeClassifier(random_state=0) # 设置随机数种子
rfc = RandomForestClassifier(random_state=0)
clf.fit(x_train, y_train)
rfc.fit(x_train, y_train)
clf_score = clf.score(x_test, y_test)
rfc_score = rfc.score(x_test, y_test)
print("决策树训练集得分为:",clf.score(x_train,y_train))
print("决策树测试集得分为:",clf.score(x_test,y_test))
print("随机森林训练集得分为:",rfc.score(x_train,y_train))
print("随机森林测试集得分为:",rfc.score(x_test,y_test))
# 可以看到决策树已经过拟合
决策树训练集得分为: 1.0
决策树测试集得分为: 0.7611940298507462
随机森林训练集得分为: 1.0
随机森林测试集得分为: 0.8283582089552238
任务三:输出模型预测结果
- 输出模型预测分类标签
- 输出不同分类标签的预测概率
一般监督模型在sklearn里面有个predict能输出预测标签,predict_proba则可以输出标签概率
pred_result = lr_l1.predict(x_train) # 输出为array
pred_result[:10]
array([0, 0, 0, 1, 0, 0, 0, 0, 1, 0], dtype=int64)
# 输出概率
pred_prob = lr_l1.predict_proba(x_train)
pred_prob[:10]
array([[0.89656205, 0.10343795],
[0.85447589, 0.14552411],
[0.91449841, 0.08550159],
[0.13699148, 0.86300852],
[0.9381094 , 0.0618906 ],
[0.81157396, 0.18842604],
[0.91822815, 0.08177185],
[0.72434838, 0.27565162],
[0.47558837, 0.52441163],
[0.86624392, 0.13375608]])
【思考】预测标签的概率对我们有什么帮助
【答】输出概率可以让我们知道该预测的信息分数
模型评估
- 模型评估是为了知道模型的泛化能力。
- 交叉验证(cross-validation)是一种评估泛化性能的统计学方法,它比单次划分训练集和测试集的方法更加稳定、全面。
- 在交叉验证中,数据被多次划分,并且需要训练多个模型。
- 最常用的交叉验证是 k 折交叉验证(k-fold cross-validation),其中 k 是由用户指定的数字,通常取 5 或 10。
- 准确率(precision)度量的是被预测为正例的样本中有多少是真正的正例
- 召回率(recall)度量的是正类样本中有多少被预测为正类
- f-分数是准确率与召回率的调和平均
任务一:交叉验证
from sklearn.model_selection import cross_val_score
lr_l1 = LogisticRegression(penalty="l1", C=0.5, solver="liblinear")
lr_l1.fit(x_train, y_train)
scores = cross_val_score(lr_l1, x_train, y_train,cv = 10)
print("score:",scores)
print("score.mean():",scores.mean())
score: [0.74603175 0.76190476 0.85714286 0.75806452 0.85483871 0.79032258
0.72580645 0.83870968 0.70967742 0.80645161]
score.mean(): 0.7848950332821301
clf = DecisionTreeClassifier(random_state=0) # 设置随机数种子
rfc = RandomForestClassifier(random_state=0)
clf.fit(x_train, y_train)
rfc.fit(x_train, y_train)
scores_clf = cross_val_score(clf, x_train, y_train,cv = 10)
scores_rfc = cross_val_score(rfc, x_train, y_train,cv = 10)
print("scores_clf.mean_10:",scores_clf.mean())
print("scores_rfc.mean_10:",scores_rfc.mean())
scores_clf = cross_val_score(clf, x_train, y_train,cv = 5)
scores_rfc = cross_val_score(rfc, x_train, y_train,cv = 5)
print("scores_clf.mean_5:",scores_clf.mean())
print("scores_rfc.mean_5:",scores_rfc.mean())
scores_clf.mean_10: 0.7397849462365592
scores_rfc.mean_10: 0.8186635944700461
scores_clf.mean_5: 0.7496129032258064
scores_rfc.mean_5: 0.8138322580645161
【思考】k折越多的情况下会带来什么样的影响?
【答】拟合效果不好
任务二:混淆矩阵
- 计算二分类问题的混淆矩阵
- 计算精确率、召回率以及f-分数
【思考】什么是二分类问题的混淆矩阵,理解这个概念,知道它主要是运算到什么任务中的
【答】这个可以很好的应用到任务为样本不太均衡的场景
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
pred = lr_l1.predict(x_train)
confusion_matrix(y_train, pred)
array([[328, 56],
[ 75, 164]], dtype=int64)
print(classification_report(y_train, pred))
precision recall f1-score support
0 0.81 0.85 0.83 384
1 0.75 0.69 0.71 239
accuracy 0.79 623
macro avg 0.78 0.77 0.77 623
weighted avg 0.79 0.79 0.79 623
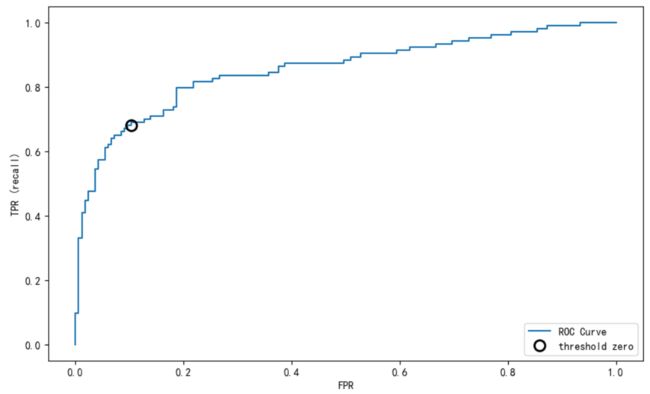
任务三:ROC曲线
【思考】什么是ROC曲线,OCR曲线的存在是为了解决什么问题?
【答】主要是用来确定一个模型的 阈值。同时在一定程度上也可以衡量这个模型的好坏
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_test, lr_l1.decision_function(x_test))
plt.plot(fpr, tpr, label="ROC Curve")
plt.xlabel("FPR")
plt.ylabel("TPR (recall)")# 找到最接近于0的阈值
close_zero = np.argmin(np.abs(thresholds))
plt.plot(fpr[close_zero], tpr[close_zero], 'o', markersize=10, label="threshold zero", fillstyle="none", c='k', mew=2)
plt.legend(loc=4)
【思考】对于多分类问题如何绘制ROC曲线
【答】对每一个类别画一条ROC曲线最后取平均