LSTM基础理论与实例
前言
关于深度学习的算法,主要有CNN卷积神经网络、RNN循环神经网络、CAN生成对抗网络三种。LSTM(Long Short-Term Memory)就是基于RNN而来。本文将主要介绍LSTM的基础理论与文字预测的实例。
LSTM基础理论
1.基础框架图
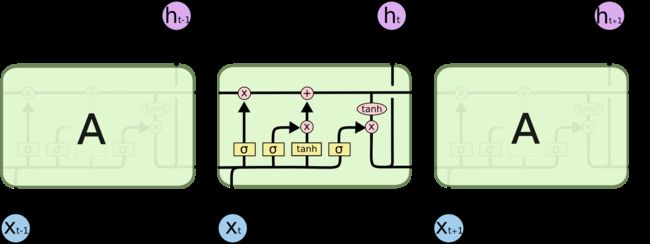
其中的符号含义如下图所示:

2.分步解析
第一步,处理单元通过遗忘门来决定我们需要丢弃的信息。该门会读取 时刻向量值与
时刻向量值与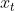 时刻的输入,然后通过激活层 σ 输出一个0-1之间数值(激活层函数一般为ReLU)。1表示“完全保留”,0表示“完全舍弃”。
时刻的输入,然后通过激活层 σ 输出一个0-1之间数值(激活层函数一般为ReLU)。1表示“完全保留”,0表示“完全舍弃”。
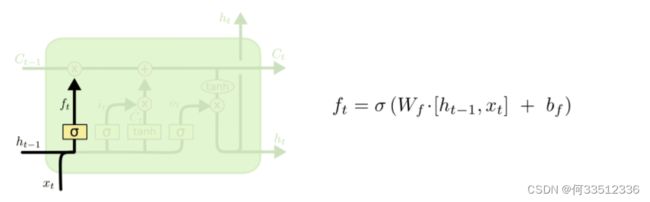
![]() 为 σ网络激活层;
为 σ网络激活层; ![]() 为 权重 ; ,为 输入;
为 权重 ; ,为 输入; ![]() 为 偏执量;
为 偏执量;
第二步,这一步要确定什么样信息放到处理单元中,包含两个处理步骤:
1.首先:通过时刻向量值与时刻的输入然后通过 σ 网络激活层 决定哪些信息要更新,最终放入传送带。
2. 然后:通过tanh层,通过tanh层生成一个向量,对输入端进行激活,对细胞进行更新将 更新为
更新为![]() 。
。
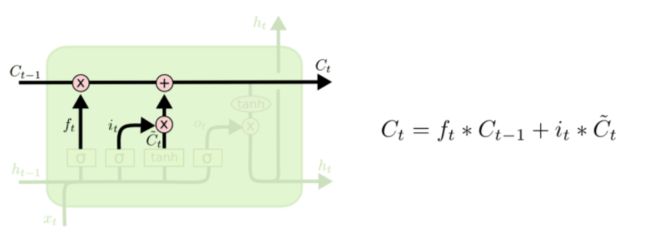
第三步:现在是更新旧处理单元的时间了, 更新为  。把旧状态与
。把旧状态与 ![]() 相乘,丢弃掉我们确定需要丢弃的信息。接着加上
相乘,丢弃掉我们确定需要丢弃的信息。接着加上 ![]() 。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
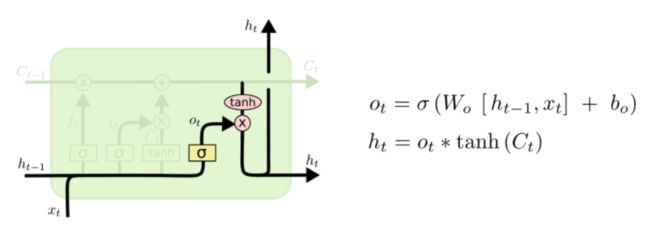
最后,需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
单词预测实例
基于pytorch
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import DataLoader, Dataset
class Net(nn.Module):
def __init__(self, features, hidden_size):
super(Net, self).__init__()
self.features = features # 输入特征维度
self.hidden_size = hidden_size # 输出特征维度
self.lstm = nn.LSTM(features, hidden_size)
self.fc = nn.Linear(hidden_size, features) # 全连接输出为语料库大小
self.criterion = torch.nn.CrossEntropyLoss()
def forward(self, x, y):
# x.shape = [batch_size , seq_len , embedding_size] -> [seq_len , batch_size , embedding_size]
# torch.nn.LSTM(input,(h_0,c_0)) API里面规定输入格式是(seq_len,batch,input_size)
x = x.permute(1, 0, 2) # [seq_len , batch_size , embedding_size]
output, (_, _) = self.lstm(x.float()) # output.size -> [seq_len,batch_size,hidden_size]
output = output[-1] # output[-1].size -> [batch_size,hidden_size]
output = self.fc(output)
pred = torch.argmax(output, 1) # 输出预测值
loss = self.criterion(output, y) # 输出损失值
return pred, loss
class my_dataset(Dataset):
def __init__(self, input_data, target_data):
self.input_data = input_data
self.target_data = target_data
def __getitem__(self, index):
return self.input_data[index], self.target_data[index]
def __len__(self):
return self.input_data.size(0)
def make_data():
vocab = [i for i in "abcdefghijklmnopqrstuvwxyz"]
idx2word = {i: j for i, j in enumerate(vocab)}
word2idx = {j: i for i, j in enumerate(vocab)}
seq_data = ['make', 'need', 'coal', 'word', 'love', 'hate', 'live', 'home', 'hash', 'star','keep']
V = len(word2idx)
input_data = []
target_data = []
for seq in seq_data:
input = [word2idx[n] for n in seq[:-1]] # 'm', 'a' , 'k' is input
target = word2idx[seq[-1]] # 'e' is target
input_data.append(np.eye(V)[input])
target_data.append(target)
return torch.tensor(input_data), torch.LongTensor(target_data)
def train():
vocab = [i for i in "abcdefghijklmnopqrstuvwxyz"]
idx2word = {i: j for i, j in enumerate(vocab)}
word2idx = {j: i for i, j in enumerate(vocab)}
input_data, target_data = make_data()
tensor_dataset = my_dataset(input_data, target_data)
batch_size = 4
train_iter = torch.utils.data.DataLoader(tensor_dataset, batch_size, shuffle=True)
n_hidden = 128
net = Net(features=len(word2idx), hidden_size=n_hidden)
optim = torch.optim.Adam(net.parameters(), lr=0.001)
net.train()
for i in range(1000):
for input_data, target_data in train_iter:
pred, loss = net(input_data, target_data)
optim.zero_grad()
loss.backward()
optim.step()
if i % 100 == 0:
print("step {0} loss {1}".format(i, loss.float()))
net.eval()
for input_data, target_data in train_iter:
pred, _ = net(input_data, target_data)
for j in range(0,batch_size-1):
pr_temp = ""
for i in range(0,3):
pr_temp += idx2word[np.argmax(input_data[j,i,:].numpy())]
print(pr_temp+" -> " + idx2word[pred.numpy()[j]])
break
if __name__ == '__main__':
train()