【论文学习】:Multi-Person Pose Estimation for PoseTrack with Enhanced Part Affinity Fields
论文地址:https://posetrack.net/workshops/iccv2017/pdfs/ML_Lab.pdf
这篇文章,初见简直惊艳以及钦佩,加上参考文献才4面纸,效果竟然拿到了2017年ICCV Challenge 1: Single-Frame Person Pose Estimation的第一名。
ps:先简单看下论文说的什么。
本文给我最大的启示是:人体姿势估计和语义分割之间有着紧密联系。一些方法[[8] Newell A, Huang Z, Deng J. Associative Embedding: End-to-End Learning for Joint Detection and Grouping[J]. 2016. [9] He K, Gkioxari G, Dollár P, et al. Mask R-CNN[J]. 2017.9]可以完成这两种任务,并在COCO关键点基准上实现最先进的性能。或许姿势估计网络可以受益于语义分割中使用的算法。
1.介绍
Human pose estimation attracts increasing attentions, not only from researchers, but also from many corporations. One of the main applications is to understand human activity and interactions, which is mentioned frequently in existing literature. But now it comes to some specific scenarios. For example, self-driving car companies use it to understand the pedestrian’s action and intention. Elder care robot can detect the fall down events by analyzing user’s body pose. Some companies have already developed a prototype or demo using human pose estimation.
人体姿态估计不仅受到研究人员的关注,而且也受到许多公司的关注,其中一个主要的应用是了解人类的活动和相互作用,这在现有文献中经常提到。但是现在又到了一些特定的场景。例如,自动驾驶汽车公司利用它来了解行人的行为和意图。分析用户的身体位置。一些公司已经开发了一个原型或演示使用人体姿态估计。
In order to apply this technology to self-driving car or care robot, we need to address some challenging problems, such as human pose estimation for multi-person, due to multi-person interaction and occlusion. PoseTrack [1] dataset provides numerous images clipped from videos. In the images, multi-person interact with each other. This benchmark presents the common scene in daily life, and would act as a persuasive index for algorithm robustness.
为了将这一技术应用于无人驾驶汽车或护理机器人,我们需要解决一些具有挑战性的问题,如多人交互和遮挡造成的多人姿态估计等。PoeTrack[1]数据集提供了大量从视频中剪裁出来的图像。在图像中,多人之间进行交互,这一基准显示了日常生活中常见的场景,并可作为算法鲁棒性的一个有说服力的指标。
In this work, we present an improved approach based on Cao’s [2] framework, which is the champion of COCO 2016 keypoints challenge [3], and discuss some potential weakness of this method. First, to enjoy the benefits of more training data, we pre-train the model on COCO dataset. Second, we extend the original Part Affinity Fields (PAFs) mechanism to redundant PAFs, which reveals an essential defect of PAFs. Third, by rethinking the network structure
在本文中,我们提出了一种基于CaO[[2] Cao Z, Simon T, Wei S E, et al. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields[J]. 2016.]框架的改进方法,该框架是coco 2016关键点挑战[3]的倡导者,并讨论了该方法的一些潜在弱点:第一,为了享受更多训练数据的好处,我们对coco数据集进行了预训练;第二,将原有的部分亲和域(PAFs)机制扩展到冗余PAFS,揭示了PAFS的一个本质缺陷。通过对网络结构本身的重新思考,我们发现了一些微小的修改,可以导致显着的改进。提交是通过这三种修改来实现的。
Additionally, inspired by semantic segmentation, we design some experiments that exploit semantic segmentation framework, such as Deeplab [4] and SDN [5]. We also have tried DenseNet [6] and the holealgorithm. But limited to the deadline, we have not used this framework as the final version. Thus, the submission result is unrelated to these experiments. Although we have not obtained an outperforming result, some conclusions might be helpful for future work of multi-person pose estimation.
此外,在语义切分的启发下,我们设计了一些利用语义分割框架的实验,如Depplab[Chen L C, Papandreou G, Kokkinos I, et al. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):1-1.]和SDN[Fu J, Liu J, Wang Y, et al. Stacked Deconvolutional Network for Semantic Segmentation[J]. 2017.],我们还尝试了密度集[Huang G, Liu Z, Weinberger K Q, et al. Densely Connected Convolutional Networks[J]. 2016.]和HoleAlgorithm,但限于deadline,我们没有使用这个框架作为最终版本,因此提交结果与这些实验无关。虽然我们还没有得到一个好的结果,但一些结论可能会对未来的多人姿态估计工作有所帮助。
2. RELATED WORK
We briefly review the two categories of multi-person pose estimation approaches. Then the advantages and disadvantages of them are discussed.
我们简要回顾两类多人姿势估计方法。 然后讨论了它们的优缺点。
Most of the multi-person pose estimation approaches can be categorized into top-down approach and bottom-up approach. Top-down approachis the most common method, which uses person detector and performs single person estimation for each individual. Some methods [1, 7] concatenate detector and person estimation in sequence, and others [8, 9] predict person bounding box and joints simultaneously, in a unified network. Bottom-up approach [2, 10] first predicts individual body joints and then groups them into persons. Instead of person detector, these methods dig out some inner relation between individual joints, such as middle points and limb vectors.
大多数多人姿势估计方法可以分为自上而下方法和自下而上方法。 自上而下的方法是最常用的方法,它使用人物检测器并对每个人进行单人估计。 一些方法[Iqbal U, Milan A, Gall J. PoseTrack: Joint Multi-Person Pose Estimation and Tracking[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2017. ///,Fang H, Xie S, Tai Y, et al. RMPE: Regional Multi-person Pose Estimation[J]. 2016. ]按顺序级联检测器和人体估计,而其他方法[Newell A, Huang Z, Deng J. Associative Embedding: End-to-End Learning for Joint Detection and Grouping[J]. 2016. ///,He K, Gkioxari G, Dollár P, et al. Mask R-CNN[J]. 2017. ]在统一网络中同时预测人类边界框和关节。 自下而上的方法[Cao Z, Simon T, Wei S E, et al. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields[J]. 2016. ,///Pishchulin L, Insafutdinov E, Tang S, et al. DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation[J]. 2015, 2008(1):4929-4937.]首先预测个体关节,然后将它们分组为人。 这些方法不是人体探测器,而是挖掘出各个关节之间的一些内在关系,例如中间点和肢体向量。
The main advantage of top-down approach is obvious, it exploit high accuracy single person estimation. However, it heavily depends on the reliability of person detector. And once the number of person increases, the computation increases linearly. It will become extremely slow when numerous persons exist. On the contrary, bottom-up approach keep computation constant in this case. Whereas joints relation might fail to use context information and might not be as reliable as person detector. After all, person detector or pedestrian detection is becoming increasingly accurate, due to the breakthroughs in classification and detection.
自上而下方法的主要优点是显而易见的,它利用了高精度的单人估计。 但是,它在很大程度上取决于人体探测器的可靠性。 并且一旦人数增加,计算就会线性增加。 当许多人存在时,它将变得非常缓慢。 相反,在这种情况下,自下而上的方法保持计算不变。 关节关系可能无法使用上下文信息,可能不如人员检测器可靠。 毕竟,由于分类和检测的突破,人体检测器或行人检测变得越来越准确。
A. Baselinemethodpre-trained on COCO
Our approach is mainly based on Cao’s [2] framework, which is categorized as a bottom-up method. Unlike topdown method, computation and running time stay almost constant when the number of person increases.
我们的方法主要基于曹的[2]框架,它被归类为自下而上的方法,与自顶向下的方法不同,计算和运行时间随着人数的增加几乎保持不变。
The baseline framework is designed as multi-task network, predicting joints and PAFs simultaneously. The key insight of this work is to formulate limb vectors as a dense prediction task, similar to joints prediction. The author modified the data input layer, making it able to generate mask maps as ground-truth.
基线框架设计为多任务网络,同时预测关节和PAFs,其关键在于将肢体向量表示为密集的预测任务,类似于关节预测,对数据输入层进行了改进,使其能够生成掩码图作为地面真实图。
Another highlight of this work is using big kernel convolution layers in refinement stages [11]. In most networks, they only use a kernel size at 1 or 3. But in the baseline method, it adopts a big kernel size up to 7. Big kernel convolution layers extend effective receptive fields to 400 pixel, which make it possible to using context information. On the other hand, the two tasks enjoy mutual benefits from each other, either joints and PAFs task can benefit each other.
这一工作的另一个亮点是在细化/优化阶段使用大内核卷积层[Wei S E, Ramakrishna V, Kanade T, et al. Convolutional Pose Machines[J]. 2016:4724-4732.]。在大多数网络中,它们只使用1或3级的内核大小,但在基线方法中,使用大内核卷积层最多可达到7。大核卷积层将有效的接受域扩展到400像素,这使得使用上下文信息成为可能。另一方面,这两个任务具有相互的优势。相互受益,关节和PAF任务都可以使彼此受益。
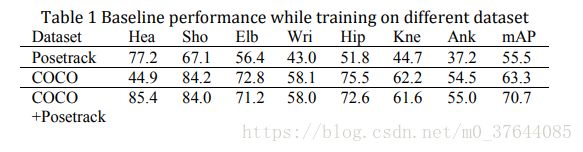
The following paragraphs illustrate the training strategy with baseline method. The baseline model is pre-trained on COCO and then finetuned on PoseTrack dataset. Table 1 shows the performance of every training step on validation dataset.
下面的段落用基线方法说明了训练策略,基线模型在coco上进行了预训练,然后在posepath数据集上进行了强化。表1显示了验证数据集上每个训练步骤的性能。
III. METHOD
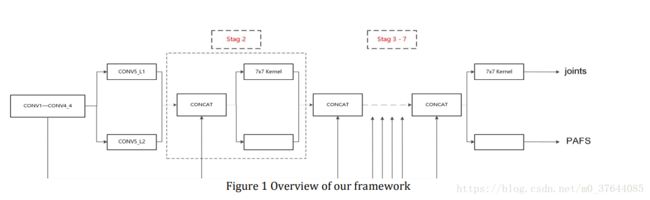
Figure 1 depicts the overview of our framework. Comparing with the baseline method, we make a few modifications, which are illustrated in Section B and Section C. We evaluate baseline method and modified framework on 100 images sampled from validation set. All the performances mentioned in this section are tested on the 100 images. In Section D, we carry out some experiments referring to semantic segmentation frameworks, which is not included in submission version.
图1描绘了我们框架的概述。 与基线方法相比,我们做了一些修改,这些修改在B部分和C部分中说明。我们评估从验证集中采样的100个图像的基线方法和修改的框架。 本节中提到的所有性能都在100张图像上进行了测试。 在D节中,我们进行了一些涉及语义分段框架的实验,这些实验未包含在提交版本中。
Train on Posetrack. Firstly, we train a baseline on PoseTrack dataset. We use the caffe implementations, which is an official project provided by the author. The performance of the baseline on validation set is 58% (mAP), about 15% (mAP) lower than final version.
首先,我们对POSSH数据集进行基线训练,使用作者提供的Caffe实现,验证集的基线性能为58%(MAP),比最终版本低15%(MAP)。
Train on COCO. Secondly, we train the model on COCO dataset. However, the keypoints annotated in COCO are not completely corresponding to PoseTrack’s. Head-top is not annotated in COCO dataset while eyes and ears are annotated. As a result,the model pre-trained on COCO does not predict head-top keypoint, leading to an extremely low score on head. Even though one keypoint is absent, baseline pre-trained on COCO achieves a much higher performance, about 65% on validation set.
其次,我们在COCO数据集上训练模型。 但是,COCO中注释的关键点并不完全对应于PoseTrack。 在COCO数据集中没有注释头顶,而眼睛和耳朵都是注释的。 因此,在COCO上预训练的模型不能预测头顶关键点,从而导致头部得分极低。尽管缺少一个关键点,但在COCO上预先训练的基线可以实现更高的性能,在验证集上达到约65%。
Finetune on Posetrack. Finally, to compensate the absence of head-top keypoint, we fine-tune the pre-trained model on PoseTrack dataset. Empirically, we find the finetune process must be controlled strictly. At the first 1000 to 2000 iterations, the performance increases stably. However, with more fine-tune iterations, the performance decreases rapidly
最后,为了补偿头顶关键点的缺失,我们在PoseTrack数据集上微调预训练模型。 根据经验,我们发现必须严格控制微调过程。 在前1000到2000次迭代中,性能稳定增加。 但是,随着更多的微调迭代,性能会迅速下降
B. Redundant Part Affinity Fields
The main function of Part Affinity Fields is to group the discrete joints into individual persons. It detects the vector or connection between joints. However, this mechanism has a fatal defect.PAFs connect N points with (N-1) lines, this is the minimum connection number to associate all the joints, shown in figure 1 (a). That means, in order to obtain a whole human skeleton, it is needed to make every connection prediction and joint prediction exactly correct. This characteristic weakens the robustness of the mechanism.
部分亲和域的主要功能是将离散的关节分组成个体,检测关节之间的向量或连接。但是这种机制有一个致命的缺陷。pafs将n个点与(n-1)线连接,这是关联所有连接的最小连接数,如图1(A)所示。这意味着,为了获得整个人体骨骼,需要使每个连接预测和关节预测完全正确。 这种特性削弱了机制的稳健性,这就削弱了该机制的鲁棒性。
Moreover, since the joints are concatenated one by one in tree structure, once the parent-link is broken, the child connection and joints will be abandoned, even though detected correctly. For example, there are three joints concatenated in sequence, from shoulder, elbow to wrist. The connection between shoulder and elbow is missing. Thus, this algorithm fails to group wrist joint to individual person.
此外,由于关节在树形结构中逐个连接,一旦父链接断开,即使正确检测到子连接和关节也将被放弃。例如,从肩部,肘部到腕关节,三个关节依次连在一起,肩部和肘部之间的连接缺失,会使该算法无法将腕关节分组到单个人。
To address this problem, we develop a redundant Part Affinity Fields (PAFs). We increase the connection number between joints, making the connection redundant. Figure 2 shows the comparison between original PAFs and our redundant PAFs. By adding these redundant lines, faulttolerate-rate increases. It is not necessary to detect every connection correctly, since some joint involves multiply connections. The structure between joints is transformed from tree to graph.
为了解决这个问题,我们开发了一个冗余的部分亲和场(PAF)。 我们增加了关节之间的连接数,使连接变得多余。 图2显示了原始PAF与我们的冗余PAF之间的比较。 通过添加这些冗余线路,可以提高容错率。 ,因为某些连接涉及多个连接,不用一定正确检测每个连接。 关节之间的结构从树转换为图形。
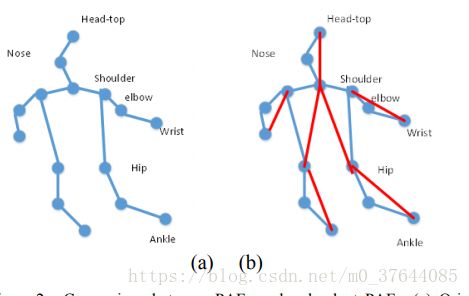
Figure.2. Comparison between PAFs and redundant PAFs. (a) Original PAFs (b) Redundant PAFs, red lines indicate redundant PAFs .(图2.比较PAF和冗余PAF。(A)原始PAF(B)冗余PAF,红线表示冗余PAF。)
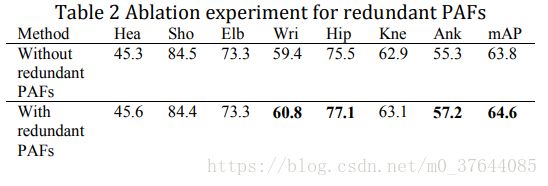
Limited to the time, we conduct the ablation experiment when pre-training on COCO dataset, shown in Table 2. We can observe a significant improvement at wrist, hip and ankle, about 1.5-2%, which proves the effectiveness of redundant PAFs. The ablation experiment uses the same model file, the only difference is using redundant PAFs information or not.
受限于时间,我们在COCO数据集的预训练时进行消融实验,如表2所示。我们可以观察到腕部,髋部和踝部的显着改善,约为1.5-2%,这证明了多余PAF的有效性。 消融实验使用相同的模型文件,唯一的区别是否使用冗余的PAF信息。
Apparently, this redundant PAFs is just a naïvecompensation for PAFs. The main contribution of this section is that it reveals the main weakness of PAFs.
显然,这个多余的PAF只是Paff的一个天真的方法。这一节的主要贡献是它揭示了PAF的主要弱点。
C. Rethinking the network structure
Feature extraction. Baseline method uses the first 10 layers of VGG-19 [12] and re-designs the following layers.There is a puzzle that they did not use the whole conv4 of VGG-16, instead they used the feature maps from intermediate layers. Huang et al.[13] have carried out an ablation experiment to analyze the performance when adding intermediate classifier to each convolution layer. The performance drops rapidly at intermediate layers in VGG-like networks. Thus, we simply change the output feature maps from intermediate layer conv4_2 to the whole bank conv4. To our surprise, this slight modification contributes more than 2% improvement to performance. Ablation experiments are shown in Table 3.
特征提取。 基线方法使用VGG-19的前10层[Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014. ]并重新设计以下层。有一个难题他们没有使用VGG-16的整个conv4,而是使用了中间层的特征图。 黄等人[13] 已经进行了消融实验来分析在向每个卷积层添加中间分类器时的性能。 在VGG类网络的中间层,性能迅速下降。 因此,我们只需将输出特征图从中间层的conv4_2改为bank conv4(也就是4*1卷积)。令我们惊讶的是,这种轻微的修改对性能的改善超过2%。消融实验如表3所示。
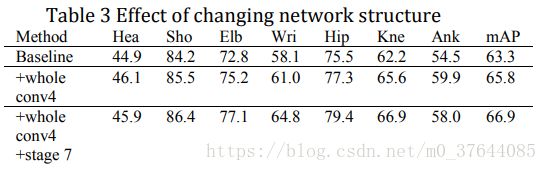
More refinement stage. Using big kernel convolution layer is another highlight of baseline method, which expands the receptive fields to 400 pixels.With more refinement stages, we can observe a remarkable decrease of loss in training process. Loss of Stage 7 is lower than Stage 6. In this work, we adopt 7 stage framework instead of 6 stage framework. It contributes approximately 1% to performance. Ablation experiments are shown in Table 3.
使用大核卷积层是基线方法的另一个亮点,它将感知域扩展到400像素。随着更多refinement阶段,我们可以观察到训练过程中损失的显着减少。 第7阶段的损失低于第6阶段。在这项工作中,我们采用7阶段框架而不是6阶段框架。 它对性能的贡献约为1%。 消融实验如表3所示。
D. Experiments inspired by semantic segmentation. 受语义分割启发的实验。
Almost all the human pose estimation methods could be summarized as dense prediction approach. It outputs heatmaps that reflect joints in pixel level. Similar to human pose estimation, semantic segmentation is also formulated as dense prediction problem, every pixel in the image would be classified. This similarity shows a strong connection between human pose estimation and semantic segmentation. In fact, some approaches [8, 9] could accomplish both of these two tasks and achieve the-state-of-art performance on COCO keypoint benchmark. Thus, we assume that pose estimation network can benefit from algorithm used in semantic segmentation. We carry out some experiment referring to semantic segmentation frameworks.
几乎所有的人体姿态估计方法都可以概括为密集预测方法。 它输出反映像素级关节的热图。 与人体姿态估计类似,语义分割也被表述为密集预测问题,图像中的每个像素将被分类。 这种相似性表明了人体姿势估计和语义分割之间的紧密联系。 事实上,一些方法[[8] Newell A, Huang Z, Deng J. Associative Embedding: End-to-End Learning for Joint Detection and Grouping[J]. 2016. [9] He K, Gkioxari G, Dollár P, et al. Mask R-CNN[J]. 2017.9]可以完成这两项任务,并在COCO关键点基准上实现最先进的性能。 因此,我们假设姿势估计网络可以受益于语义分割中使用的算法。 我们进行了一些涉及语义分割框架的实验。
VGG-19 with the hole algorithm. Baseline method only uses the first four blocks of VGG-19 due to stride, while the last fifth block is abandoned. DeeperCut [14] and other dense prediction frameworks prove that stride 8 might be a proper choice for dense prediction. We refer to the framework of DeepLab-v2 [4], adopt the whole VGG-19 structure, using the hole algorithm to recover resolution from stride 16 to 8. We train the model on COCO dataset and test it on a subset of 2644 images derived from validation set. The result shows the performance on large targets increases while the performance on medium targets decreases. A reasonable hypothesis is that the hole algorithm increases the receptive fields as well as the big kernel refine stages. The effective receptive fields become too large to fit the small object.
由于步幅的原因,基线方法仅使用VGG-19的前四个块,而最后五个块被放弃。 DeeperCut [[14] Insafutdinov E, Pishchulin L, Andres B, et al. DeeperCut: A Deeper, Stronger, and Faster Multi-person Pose Estimation Model[J]. 2016, 42(5):34-50. ]和其他密集预测框架证明了步幅8可能是密集预测的正确选择。 我们参考DeepLab-v2 [[4] Chen L C, Papandreou G, Kokkinos I, et al. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):1-1. 基于深卷积网、四角卷积和全连通CRFs的语义图像分割]的框架,采用整个VGG-19结构,使用hole算法【输出的score map变大了,即是dense的输出了,而且receptive field不会变小,而且可以变大。这对做分割、检测等工作非常重要。分析地址:(1)hole algorithm,(2)】从步幅16到8恢复分辨率。我们在coco数据集上对模型进行训练,并在来自验证集的2644幅图像上进行测试。 结果表明,大型目标的性能提高,而中型目标的性能下降。 一个合理的假设是,hole algorithm增加了感受域以及大核细化阶段。 有效的感受野变得太大而不适合小物体。
DenseNet with the hole algorithm. Referring to SDN [5], we use DenseNet with the hole algorithm to replace VGG-19 in this experiments. DenseNet-121 is adopted as backbone, while conv5 bank is abandoned and conv4 is adapted to 8 stride using the hole algorithm. This framework turns out to be a stable and easily converging method. We only use two stages instead of six stages. The performance is 63% on validation set, comparing to 61% using two stages baseline method. However, when adding more refinement stages, the performance does not increase remarkably. A 6 stages implementation gets 64%, with a small margin to 2 stages method.
参考SDN [[5] Fu J, Liu J, Wang Y, et al. Stacked Deconvolutional Network for Semantic Segmentation[J]. 2017. ],我们在本实验中使用带有hole algorithm的DenseNet代替VGG-19。 采用DenseNet-121作为主干,废弃conv5 bank,采用hole algorithm,使conv4适应于8 stride。 该框架证明是一种稳定且易于收敛的方法。 我们只使用两个阶段而不是六个阶段。 验证集的性能为63%,而使用两阶段基线方法的性能为61%。 但是,当添加更多细化阶段时,性能不会显着提高。 6阶段实施得到64%,和2阶段方法只有一点差距。
Analysis. Both of the experiments above adopt the hole algorithm, which seems contradict with big kernel refinement stages. We will analyze thisphenomena carefully in the future.
以上两种实验都采用了hole algorithm,这似乎与big kernel refinement stages(大核细化阶段)相矛盾,今后我们将认真分析这一现象。
E. Training details
We use the official implementation from Cao [2] and initialize the VGG19 model from the ImageNet-pre-trained model. At first, we train our model on COCO dataset for 130000 iterations with lr=4e-5,stepsize= 40000, gamma = 0.333. This step costs 2 days using two P40 GPU. Then, we finetune the COCO pre-trained model on PoseTrack dataset for 3000 iterations, with lr=1e-5, stepsize=1000, gamma = 0.333. In finetuning process, we froze the weights of feature extraction layers, from conv1-conv4.
我们使用CaO[2]的正式实现,并从ImageNet-pre-trained模型中初始化VGG19模型,首先,我们在coco数据集上训练130000次迭代,LR=4e-5,步长=40000,伽马=0.333。这一步骤使用两个P40 GPU,花费2天时间。然后,我们在跟踪数据集上完成了3000次迭代的coco预训练模型,LR=1e-5,逐步大小=1000,γ=0.333。在细化过程中,我们固定了特征提取层(conv1-conv4)的权重,
IV. FINNAL PERFORMANCE ON POSETRACK 最后性能
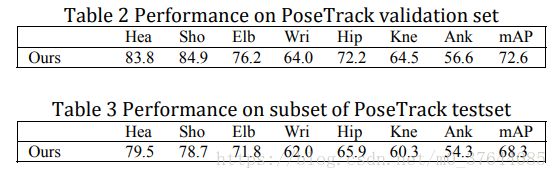
We evaluate our method on the whole validation set and subset of testset. All the results in Table 4 and Table 5 are obtained from the evaluation server. While our method performs well on head and shoulder, its performance on ankle and wrist is not so good. The reason is that ankle and wrist are easy to be hidden in multi-person pose estimation.
我们在整个验证集和测试子集上对我们的方法进行了评价,表4和表5中的所有结果都是从评估服务器中得到的,虽然我们的方法在头和肩上表现很好,但是它在踝关节和腕关节上的性能不太好,这是因为在多人姿态估计中,踝关节和腕关节很容易隐藏。
V. CONCLUSIONS
In this paper, we present an improved framework based on PAFsto achieve better performance on PoseTrack Challenge. We develop a redundant PAFs mechanism to compensate the defect of original PAFs. Additionally, we carry out some experiments referring to semantic segmentation frameworks. And our modifications on networks are proved to be quite effective. The paper is also a description of the method we used in PoseTrack competition.
在本文中,我们提出了一个基于PAF的改进框架,以在PoseTrack Challenge上实现更好的性能。 我们开发了一种冗余PAF机制来补偿原始PAF的缺陷。 另外,我们进行了一些涉及语义分割框架的实验。 我们对网络的修改证明是非常有效的。 本文还描述了我们在PoseTrack竞赛中使用的方法。